A maneira como pesquisamos e interagimos com as informações mudou radicalmente na última década. Os mecanismos de pesquisa tradicionais baseados em palavras-chave já nos serviram bem para encontrar documentos ou respostas, mas os desafios comerciais atuais exigem muito mais do que correspondências exatas de palavras-chave. Os usuários modernos, sejam consumidores ou empresas, esperam sistemas que entender intenção, interpretar contexto e entregar os insights mais relevantes instantaneamente.
É aqui que pesquisa vetorial entra em cena. Ao transformar dados em representações matemáticas de alta dimensão (embeddings), a pesquisa vetorial permite que os sistemas capturem o significado semântico em vez de apenas a sobreposição lexical. As implicações vão muito além dos mecanismos de pesquisa. Aplicativos agênticos - sistemas que podem perceber, raciocinar e agir de forma autônoma - dependem muito da pesquisa vetorial como sua espinha dorsal de conhecimento. Sem ela, os agentes de IA correm o risco de serem respondedores superficiais em vez de solucionadores de problemas com consciência do contexto.
Neste blog, exploraremos por que a pesquisa vetorial se tornou essencial, os domínios de negócios que ela está remodelando e como o Couchbase está possibilitando essa transformação com a Pesquisa de Texto Completo (FTS) e o Eventing. Vamos nos aprofundar em um estudo de caso do mundo real no setor de telecomunicações e preparar o terreno para a orientação prática.
Por que a pesquisa vetorial é importante
No centro da pesquisa vetorial estão incorporações - representações numéricas de palavras, documentos ou até mesmo arquivos multimídia. Ao contrário das palavras-chave, os embeddings codificam relações semânticas. Por exemplo, "queda de rede" e "queda de chamadas" podem não compartilhar muitas palavras-chave, mas semanticamente apontam para problemas semelhantes. Com a incorporação de vetores, tanto as consultas quanto os dados são projetados no mesmo espaço multidimensional, onde a similaridade é determinada por métricas de distância (similaridade de cosseno, produto escalar etc.).
Essa mudança tem implicações profundas:
-
- Do literal ao contextual: Os sistemas de pesquisa não correspondem mais apenas a palavras; eles captam o significado.
- De estático a dinâmico: Os espaços vetoriais se adaptam à medida que os dados crescem e os contextos evoluem.
- Da pesquisa ao raciocínio: Os aplicativos agênticos dependem de embeddings não apenas para recuperar dados, mas para interpretar a intenção e tomar decisões.
Simplificando, a pesquisa vetorial não é uma atualização de recurso para a pesquisa de palavras-chave - é um mudança de paradigma possibilitando a próxima geração de sistemas inteligentes e autônomos.
Casos de uso comercial que impulsionam a adoção da pesquisa vetorial
Telecom (análise PCAP)
As redes de telecomunicações geram enormes volumes de dados de captura de pacotes (PCAP). A análise tradicional envolve filtros de palavras-chave, pesquisas de regex e correlação manual em gigabytes de registros, o que geralmente é muito lento para a solução de problemas em tempo real. A pesquisa vetorial muda esse jogo. Ao incorporar os rastros PCAP, as anomalias e os padrões podem ser agrupados e recuperados semanticamente, permitindo que os engenheiros identifiquem problemas (como degradação da qualidade da chamada ou perda de pacotes) instantaneamente.
Copilotos de suporte ao cliente
Os centros de contato estão migrando de bots de FAQ com script para copilotos inteligentes que auxiliam os agentes humanos. A pesquisa vetorial garante que as consultas dos usuários sejam mapeadas para as respostas corretas da base de conhecimento, mesmo que formuladas de forma diferente. Por exemplo, "Meu telefone está sempre perdendo chamadas" pode ser mapeado para a documentação sobre "problemas de congestionamento de rede", algo que a pesquisa por palavra-chave provavelmente deixaria passar.
Detecção de fraudes em finanças
A fraude financeira é sutil - os padrões nem sempre seguem as palavras-chave. Com os embeddings, o comportamento transacional pode ser representado em vetores, permitindo que os sistemas detectem exceções que se desviam dos padrões "normais". Isso permite que as instituições sinalizem anomalias incomuns, mas invisíveis por palavras-chave.
Assistência médica
Pesquisas médicas e registros de pacientes contêm diversas terminologias. A pesquisa vetorial pode conectar "dor no peito" com "angina" ou "desconforto cardíaco", tornando os sistemas de suporte à decisão clínica mais eficazes. Ela acelera a pesquisa, o diagnóstico e a descoberta de medicamentos.
Mecanismos de varejo e recomendação
Os sistemas de recomendação prosperam com a similaridade semântica. A pesquisa vetorial permite que as recomendações do tipo "as pessoas que compraram isso também gostaram daquilo" funcionem em um nível mais profundo, não apenas combinando tags de produtos, mas alinhando padrões de intenção, estilo ou comportamento do usuário.
Gerenciamento do conhecimento empresarial
As organizações sofrem com os silos de dados. Os funcionários perdem horas procurando insights relevantes em vários sistemas. A pesquisa vetorial potencializa os sistemas de conhecimento unificados que trazem à tona as informações contextualmente mais relevantes, independentemente do formato ou da fraseologia.
Estudo de caso: Análise PCAP em Telecom com pesquisa vetorial
O desafio
As operadoras de telecomunicações capturam bilhões de pacotes diariamente. A análise tradicional de pacotes envolve filtragem manual, pesquisas de strings ou regras estáticas para detectar anomalias. Essas abordagens:
-
- Não capturar a similaridade semântica (por exemplo, diferentes manifestações do mesmo problema principal)
- Dificuldade em escala devido ao grande volume de dados
- Leva a uma solução de problemas lenta e a clientes frustrados
A vantagem da pesquisa vetorial
Ao incorporar dados PCAP em vetores:
-
- As anomalias se agrupam naturalmente no espaço vetorial (por exemplo, todos os traços de chamadas perdidas ficam próximos uns dos outros).
- Consultas semânticas se tornem possíveis (procure por "picos de latência" e descubra registros com jitter de pacotes ou retransmissões).
- A análise da causa raiz acelerauma vez que os problemas relacionados podem ser identificados automaticamente, em vez de serem reunidos manualmente.
O resultado
Os engenheiros de telecomunicações passam da análise reativa de registros para a detecção proativa de anomalias. Os problemas dos clientes são identificados em tempo real, aumentando a satisfação e reduzindo a rotatividade. O que antes levava horas de análise manual pode ser realizado em minutos.
Como o Couchbase permite a pesquisa vetorial para aplicativos semânticos e agênticos
Recapitulação da pesquisa de texto completo (FTS)
O FTS do Couchbase há muito tempo permite que as empresas vão além das consultas estruturadas, oferecendo suporte à linguagem natural e aos recursos de texto completo. No entanto, o FTS por si só ainda está enraizado na pesquisa lexical.
Adição de pesquisa vetorial
O Couchbase estende o FTS com indexação de vetores e pesquisa de similaridade. Isso significa que as empresas podem incorporar dados (logs, documentos, consultas etc.) em vetores e armazená-los no Couchbase para recuperação semântica. Em vez de retornar correspondências de palavras-chave, o FTS agora pode apresentar resultados contextualmente relevantes.
Pesquisa híbrida
O verdadeiro poder está em pesquisa híbrida - combinando palavra-chave e similaridade vetorial. Por exemplo, um engenheiro de telecomunicações pode pesquisar "quedas de chamadas em Nova York" e obter resultados que combinam correspondências de local exato (palavra-chave) com anomalias de PCAP semanticamente semelhantes (vetor).
Eventos em ação
O Couchbase Eventing adiciona acionadores em tempo real a esse ecossistema. Imagine uma função de eventos que:
-
- Procura anomalias em embeddings de pacotes.
- Emite alertas automaticamente quando os limites de similaridade são ultrapassados.
- Inicia fluxos de trabalho (por exemplo, abrindo um tíquete do Jira ou notificando a equipe de operações).
Essa combinação - FTS + Busca de Vetores + Eventos - transforma a pesquisa de recuperação passiva de informações em fornecimento de inteligência ativa.
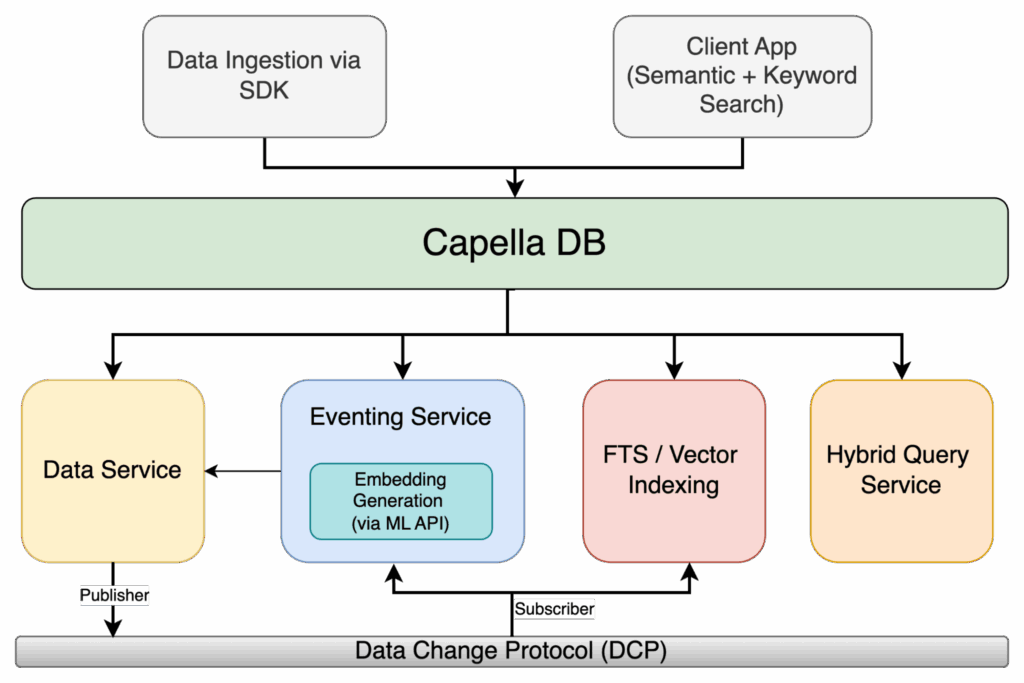
Figura 1: Arquitetura de pesquisa híbrida Capella com Eventing, ML Embeddings e FTS/indexação vetorial
Passo a passo prático: pesquisa vetorial com o Couchbase
Até agora, falamos sobre por que a pesquisa vetorial é importante e como o Couchbase a potencializa. Agora vamos juntar tudo isso em um exemplo prático.
Nosso cenário é análise de PCAP (captura de pacotes) de telecomunicações. Imagine um fluxo maciço de resumos de sessões de pacotes fluindo para o Couchbase. Em vez de armazenar esses dados de forma passiva, queremos que o Couchbase:
-
- Automaticamente incorporar cada resumo de sessão em um vetor usando Incorporações da OpenAI.
- Armazene essas incorporações junto com os metadados brutos.
- Indexá-los em Couchbase FTS para consultas rápidas de similaridade de vetores.
- Permita-nos detectar anomalias ou "sessões que parecem incomuns" em tempo real.
A melhor parte? Não faremos isso manualmente. Eventos automatizará todo o pipeline - no momento em que um novo documento de sessão PCAP chegar, o Couchbase o enriquecerá com uma incorporação e o enviará diretamente para o índice de vetores.
Pré-requisitos
Antes de mergulhar na compilação, vamos nos certificar de que nosso ambiente está pronto. Não se trata apenas de marcar caixas, mas de preparar o cenário para uma experiência de desenvolvedor tranquila.
Couchbase Server ou Capella
Você precisará de um ambiente do Couchbase em execução com o Eventos e FTS (Pesquisa de texto completo) serviços habilitados. Esses são os mecanismos que impulsionarão a automação e a pesquisa.
Um balde para armazenar os dados da sessão PCAP
Para este passo a passo, chamaremos o bucket de pcap. Dentro dele, organizaremos os dados em escopos e coleções para manter tudo limpo.
Serviço de eventos ativado
As funções de eventos são nossa "cola reativa". Assim que um novo resumo de sessão de PCAP for ingerido, a Eventing entrará em ação, enriquecerá o documento com embeddings e, opcionalmente, acionará alertas de anomalia.
Serviço FTS ativado
Isso nos permitirá criar um índice vetorial mais tarde, para que possamos realizar uma pesquisa de similaridade em embeddings de sessão. Sem isso, os embeddings são apenas números armazenados em JSON.
Ponto de extremidade da API de incorporação
Você precisará acessar um modelo de embeddings e uma chave de API. Neste blog, assumiremos o text-embedding-3-small ou text-embedding-3-large da OpenAI, mas você pode apontar para qualquer API que retorne um vetor de dimensão fixa. Eventing usará curl() para chamar esse endpoint.
Ingestão de sessões PCAP - modelo de dados
Toda captura PCAP gera uma enxurrada de pacotes. Para nossa demonstração, em vez de armazenar pacotes brutos (muito grandes, muito barulhentos), trabalharemos com resumos das sessões. Esses resumos destilam os fatos importantes: IPs de origem/destino, protocolo, jitter, perda de pacotes, retransmissões e uma breve descrição em linguagem natural de como foi a sessão.
Um documento de sessão única pode ter a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "tipo": "pcap_session", "sessionId": "sess-2025-08-21-001", "ts": "2025-08-21T09:10:11Z", "srcIP": "10.1.2.3", "dstIP": "34.201.10.45", "srcPort": 5060, "dstPort": 5060, "proto": "SIP", "region" (região): "us-east-1", "transportadora": "cb-telecom", "durationMs": 17890, "pacotes": 3412, "lossPct": 0.7, "jitterMs": 35.2, "retransmits" (retransmissões): 21, "summaryText": "Chamada SIP com perda intermitente de RTP e jitter elevado, quedas de chamadas relatadas pelo usuário", "embedding_vector" (vetor de incorporação): nulo, // <-- O evento preencherá isso "qualityLabel": "desconhecido" // <-- Eventos/alertas atualizarão isso } |
Principais campos:
-
- summaryText → uma sinopse de linguagem natural que as incorporações capturarão.
- qualityLabel → rótulo de saúde heurístico (saudável, degradado) que o Eventing pode atribuir.
Nesse estágio, o embedding_vector está vazio. É aí que entrará o Eventing.
Criar bucket/scope/coleção
Organizaremos o pipeline em contêineres lógicos:
-
- Balde: pcap
- Escopo: telecomunicações
- Coleções:
- sessões (resumos brutos de sessões PCAP ingeridas)
- alertas (para alertas de anomalia emitidos por Eventing)
- metadados (para escrever informações de metadados de eventos)
Exemplo N1QL:
|
1 2 3 |
CRIAR ESCOPO `pcap`.`telecomunicações`; CRIAR COLEÇÃO `pcap`.`telecomunicações`.`sessões`; CRIAR COLEÇÃO `pcap`.`telecomunicações`.`alertas`; |
Veja alguns exemplos de documentos de sessão do PCAP
Vamos inserir algumas sessões íntegras e degradadas para testar o pipeline:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INSERIR PARA `pcap`.`telco`.`sessões` (CHAVE, VALOR) VALORES ("sess::1", { "tipo":"pcap_session","sessionId":"sess::1","ts":"2025-08-21T09:00:00Z", "srcIP":"10.0.0.1","dstIP":"52.0.0.5","srcPort":16384,"dstPort":16384, "proto":"RTP","region" (região):"us-east-1","transportadora":"cb-telecom","durationMs":600000, "pacotes":100000,"lossPct":0.05,"jitterMs":2.5,"retransmits" (retransmissões):0, "summaryText":"Fluxo de mídia RTP estável, perda insignificante de pacotes e baixo jitter", "embedding_vector" (vetor de incorporação):nulo,"qualityLabel":"desconhecido" }), ("sess::2", { "tipo":"pcap_session","sessionId":"sess::2","ts":"2025-08-21T09:05:00Z", "srcIP":"10.0.0.2","dstIP":"52.0.0.5","srcPort":5060,"dstPort":5060, "proto":"SIP","region" (região):"us-east-1","transportadora":"cb-telecom","durationMs":120000, "pacotes":12000,"lossPct":0.7,"jitterMs":35.2,"retransmits" (retransmissões):21, "summaryText":"Negociação SIP com perda de mídia intermitente e jitter elevado, várias retransmissões", "embedding_vector" (vetor de incorporação):nulo,"qualityLabel":"desconhecido" }); |
Esta é a aparência se você visualizar os documentos na coleção sessão:
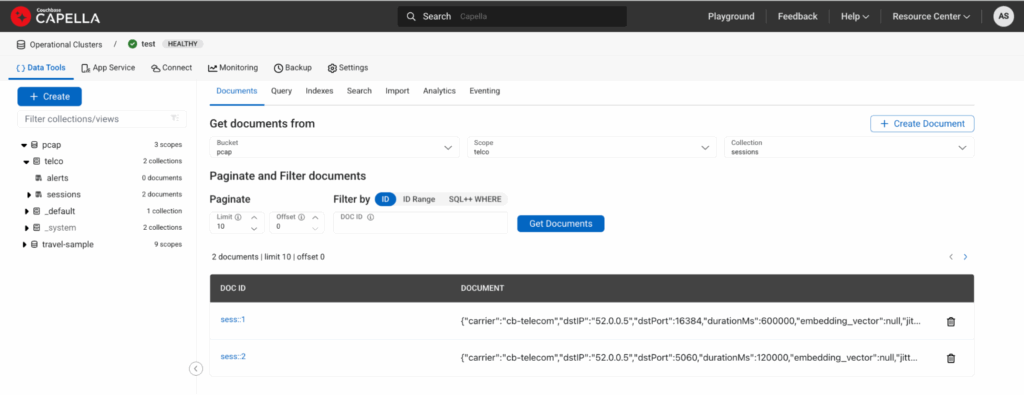
Figura 2: UI do Capella mostrando dois documentos ingeridos por meio do DML acima.
Eventos: incorporação automática na ingestão
É aqui que a mágica acontece. Toda vez que um documento é gravado em pcap.telco.sessionsNossa função de eventos será:
-
- Chame a API de incorporação da OpenAI com summaryText + recursos estruturados como proto, perda, jitter, região, portadora.
- Armazene o vetor retornado em vetor_de_incorporação.
- Marque a sessão como saudável ou degradado.
- Copiar o documento enriquecido de volta para sessões.
- Emitir alertas de anomalia para alertas.
Definiremos os vínculos da seguinte forma:
-
- Nome: pcapEmbedding
- Fonte: pcap.telco.sessions
- Metadados: pcap.telco.metadata
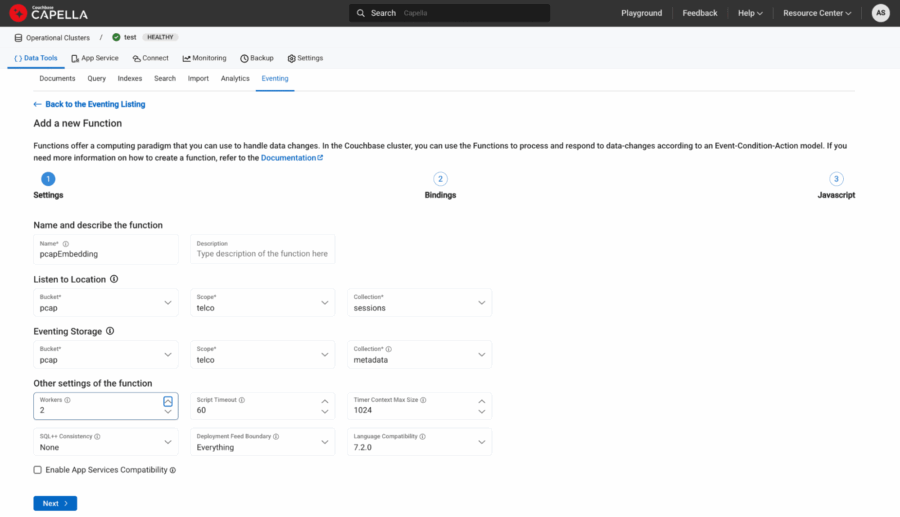
Figura 3: Vinculação de fontes e metadados.
-
- Aliases de balde:
- dst → pcap.telco.sessions com Ler e escrever Permissão
- alertas → pcap.telco.alerts com Ler e escrever Permissão
- Aliases de URL:
- EMBEDDING_API → "https://api.openai.com/v1/embeddings“
- Aliases constantes:
- MODELO_DE_INCORPORAÇÃO → "text-embedding-3-small"
- Aliases de balde:
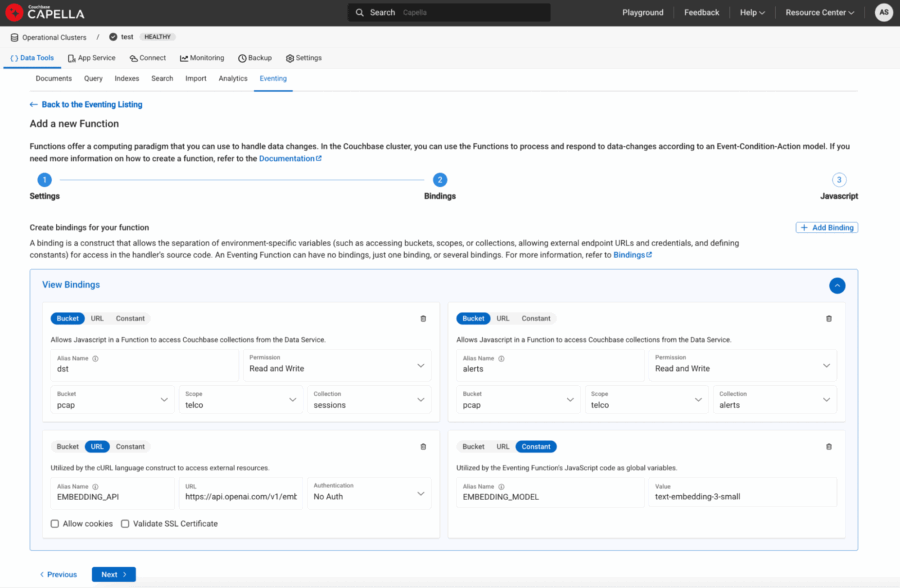
Figura 4: URL e constantes definidas como associações à função de eventos.
Automatização do enriquecimento com Eventing
Aqui está o momento mágico. Na maioria dos bancos de dados, o enriquecimento de dados com embeddings requer pipelines ETL externos ou trabalhadores personalizados. Com o Couchbase Eventing, o próprio banco de dados se torna inteligente.
A ideia é simples:
-
- Assim que um novo documento de sessão chega ao sessões Eventing será acionado.
- Ele chamará o API de incorporação da OpenAI (incorporação de texto-3-pequeno ou incorporação de texto-3-grande são ótimos modelos para isso).
- O vetor retornado será anexado novamente ao mesmo documento.
O resultado? Seu balde agora contém Sessões PCAP e sua impressão digital semânticapronto para ser indexado.
Aqui está o manipulador de eventos atualizado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
função Sobre a atualização(doc, meta) { registro("Função de evento iniciada para o documento id:", meta.id); tentar { se (doc.tipo !== "pcap_session") { registro("Ignorando documento: o tipo é", doc.tipo); retorno; } var OPENAI_KEY = "YZX"; // <-- sua chave OpenAI // 1) Criar texto de entrada enriquecido para incorporação // Combinar texto livre + contexto estruturado para que os embeddings capturem uma semântica mais rica var texto = doc.summaryText || ""; texto += " Proto:" + (doc.proto || ""); texto += " Percentual de perda:" + (doc.perdaPct || 0); texto += " JitterMs:" + (doc.jitterMs || 0); texto += " Retransmissões:" + (doc.retransmite || 0); texto += " Região:" + (doc.região || ""); texto += " Transportadora:" + (doc.transportadora || ""); registro("O texto emriturado antes da incorporação é: " + texto); // 2) Chamar a API de Embeddings da OpenAI var solicitação = { cabeçalhos: { "Authorization" (Autorização): "Portador" + OPENAI_KEY, "Content-Type": "application/json" }, corpo: JSON.stringify({ "input" (entrada): texto, "model" (modelo): EMBEDAGEM_MODELO }) }; tentar { var resposta = enrolar("POST", EMBEDDING_API, solicitação); var corpo = resposta.corpo; registro("Corpo da resposta analisado"); se (tipo de corpo === "string") { var resultado = JSON.analisar(corpo); } mais se (tipo de corpo === "objeto") { // Se já tiver sido analisado, basta atribuir var resultado = corpo; } mais { registro("Tipo de resposta.corpo inesperado:", tipo de corpo); } // Extrair o vetor de incorporação do primeiro elemento de dados se (resultado && resultado.dados && resultado.dados.comprimento > 0 && resultado.dados[0].incorporação) { var embeddingVector = resultado.dados[0].incorporação; registro("Comprimento do vetor de incorporação:", embeddingVector.comprimento); // 3) Write back embedding + heurística de qualidade doc.vetor_de_incorporação = embeddingVector; doc.modelo_de_incorporação = MODELO_DE_INCORPORAÇÃO; doc.qualityLabel = (doc.perdaPct > 0.5 || doc.jitterMs > 30 || doc.retransmite > 10) ? "degradado" : "saudável"; // Atualização da coleção de destino dst[meta.id] = doc; } mais { registro("Incorporação não encontrada na resposta:", JSON.stringify(resultado)); } } captura (e) { registro("O Curl lançou uma exceção:", e); } // 4) Emitir alerta de anomalia se estiver degradado se (doc.qualityLabel === "degradado") { var alertDoc = { tipo: "pcap_alert", sessionId: doc.sessionId, ts: novo Data().toISOString(), razão: "Limite heurístico excedido", perdaPct: doc.perdaPct, jitterMs: doc.jitterMs, retransmite: doc.retransmite, região: doc.região, transportadora: doc.transportadora }; var alertKey = "alert::" + doc.sessionId; alertas[alertKey] = alertDoc; } registro("Documento enriquecido com incorporação + rótulo de qualidade:", meta.id); } captura (e) { registro(" Exceção de eventos", e); } } função OnDelete(meta, opções) { // Sem opção para exclusões } |
Cada novo resumo de sessão do PCAP agora enriquece-se a si mesmo em tempo real.
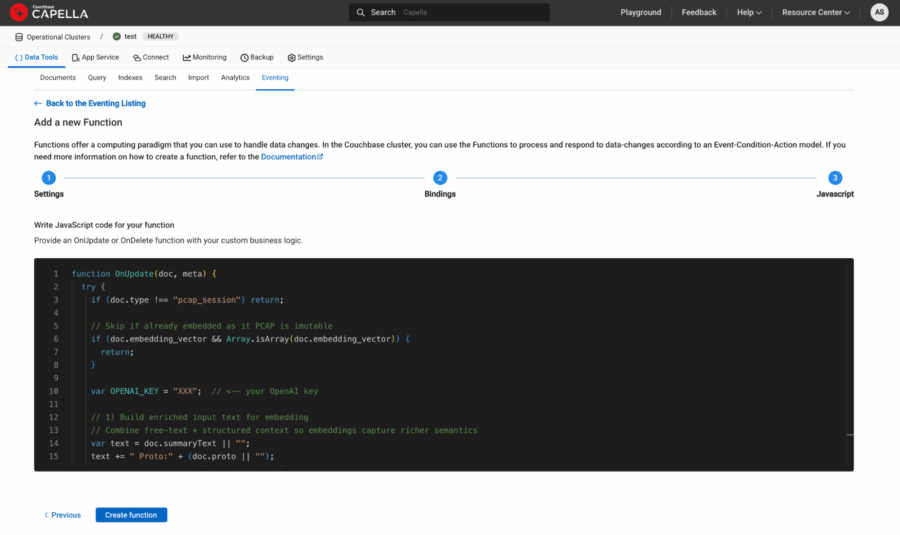
Figura 5: javascript da Eventing Function copiado/colado na última etapa da definição da função.
Finalmente, implemente a função e ela deverá ficar verde quando estiver pronta.
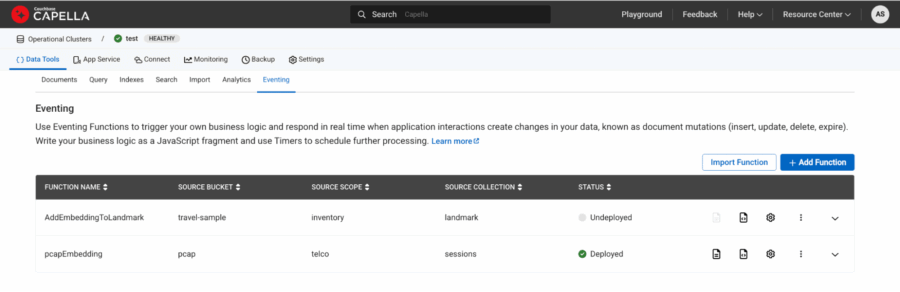
Figura 6: pcapEmbedding A função foi implantada e apareceu como verde no status.
Verifique o documento e agora ele deverá ter mais vetor_de_incorporação e modelo_de_incorporação com os outros campos da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "transportadora": "cb-telecom", "dstIP": "52.0.0.5", "dstPort": 16384, "durationMs": 600000, "jitterMs": 2.5, "lossPct": 0.05, "pacotes": 100000, "proto": "RTP", "qualityLabel": "saudável", "region" (região): "us-east-1", "retransmits" (retransmissões): 0, "sessionId": "sess::1", "srcIP": "10.0.0.1", "srcPort": 16384, "summaryText": "Fluxo de mídia RTP estável, perda insignificante de pacotes e baixo jitter", "ts": "2025-08-21T09:00:00Z", "tipo": "pcap_session", "embedding_model" (modelo de incorporação)": "text-embedding-3-small", "embedding_vector" (vetor de incorporação): [-0.004560039, -0.0018385303, 0.033093546, 0.0023359614, ...] } |
Criação de um índice FTS com reconhecimento de vetor no Couchbase
Agora que cada documento de sessão do PCAP contém um vetor de incorporação e metadados enriquecidos (região, proto, operadora, jitter, perda, retransmissões), a próxima etapa é tornar esses campos pesquisáveis. O mecanismo de pesquisa de texto completo (FTS) do Couchbase agora suporta indexação de vetores, ou seja, podemos armazenar essas incorporações de alta dimensão junto com os campos numéricos e de palavras-chave tradicionais.
Por que isso é importante?
Porque ele nos permite executar consultas semânticas como “Encontrar sessões semelhantes a essa chamada degradada na Ásia realizadas por LTE” - combinando similaridade semântica (via pesquisa vetorial) com filtragem estruturada (região, proto, portadora).
Aqui está uma definição JSON simples de um índice desse tipo (no console do FTS, você criaria um novo índice e colaria isso):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 |
{ "tipo": "fulltext-index", "name" (nome): "pcap.telco.pcapEmbeddingIndex", "uuid": "2fd519311de37177", "sourceType": "gocbcore", "sourceName": "pcap", "sourceUUID": "a576b1ee361c33974e47371d03098b72", "planParams": { "maxPartitionsPerPIndex": 1024, "indexPartitions": 1 }, "params": { "doc_config": { "docid_prefix_delim": "", "docid_regexp": "", "mode" (modo): "scope.collection.type_field", "type_field": "tipo" }, "mapeamento": { "análise": {}, "default_analyzer": "padrão", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "dinâmico": falso, "habilitado": falso }, "default_type": "_default", "docvalues_dynamic": falso, "index_dynamic": verdadeiro, "store_dynamic": verdadeiro, "type_field": "_type", "tipos": { "telco.sessions": { "dinâmico": falso, "habilitado": verdadeiro, "propriedades": { "transportadora": { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "analisador": "en", "índice": verdadeiro, "name" (nome): "transportadora", "loja": verdadeiro, "tipo": "texto" } ] }, "embedding_vector" (vetor de incorporação): { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "dims": 1536, "índice": verdadeiro, "name" (nome): "embedding_vector" (vetor de incorporação), "similaridade": "dot_product", "tipo": "vetor", "vector_index_optimized_for": "recall" } ] }, "jitterMs": { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "índice": verdadeiro, "name" (nome): "jitterMs", "loja": verdadeiro, "tipo": "número" } ] }, "lossPct": { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "índice": verdadeiro, "name" (nome): "lossPct", "loja": verdadeiro, "tipo": "número" } ] }, "proto": { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "analisador": "en", "índice": verdadeiro, "name" (nome): "proto", "loja": verdadeiro, "tipo": "texto" } ] }, "qualityLabel": { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "analisador": "en", "índice": verdadeiro, "name" (nome): "qualityLabel", "loja": verdadeiro, "tipo": "texto" } ] }, "region" (região): { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "analisador": "en", "índice": verdadeiro, "name" (nome): "region" (região), "loja": verdadeiro, "tipo": "texto" } ] }, "retransmits" (retransmissões): { "dinâmico": falso, "habilitado": verdadeiro, "campos": [ { "índice": verdadeiro, "name" (nome): "retransmits" (retransmissões), "loja": verdadeiro, "tipo": "número" } ] } } } } }, "loja": { "indexType": "scorch" (queimar), "segmentVersion": 16 } }, "sourceParams": {} } |
Vamos explicar isso em linguagem simples:
-
- vetor_de_incorporação → Essa é a espinha dorsal semântica, um campo vetorial onde ocorrem as consultas de similaridade. Nós escolhemos produto escalar como a métrica de similaridade, pois ela funciona bem com as incorporações da OpenAI.
- região, proto, transportadora → Indexados como campos de texto para que possamos filtrar por região de telecomunicações, protocolo de pacotes ou operadora.
- perdaPct, jitterMs, retransmite → Campos numéricos que permitem consultas de intervalo (por exemplo, “sessões com jitter > 50ms”).
- qualityLabel → Nossa função Eventing já marcava as chamadas como “saudáveis” ou “degradadas”, o que agora se torna um campo pesquisável.
Essa estrutura dupla - vetor + metadados - é o que torna a solução poderosa. Você não é obrigado a escolher entre a similaridade semântica e a filtragem estruturada; é possível combinar ambas em uma única consulta.
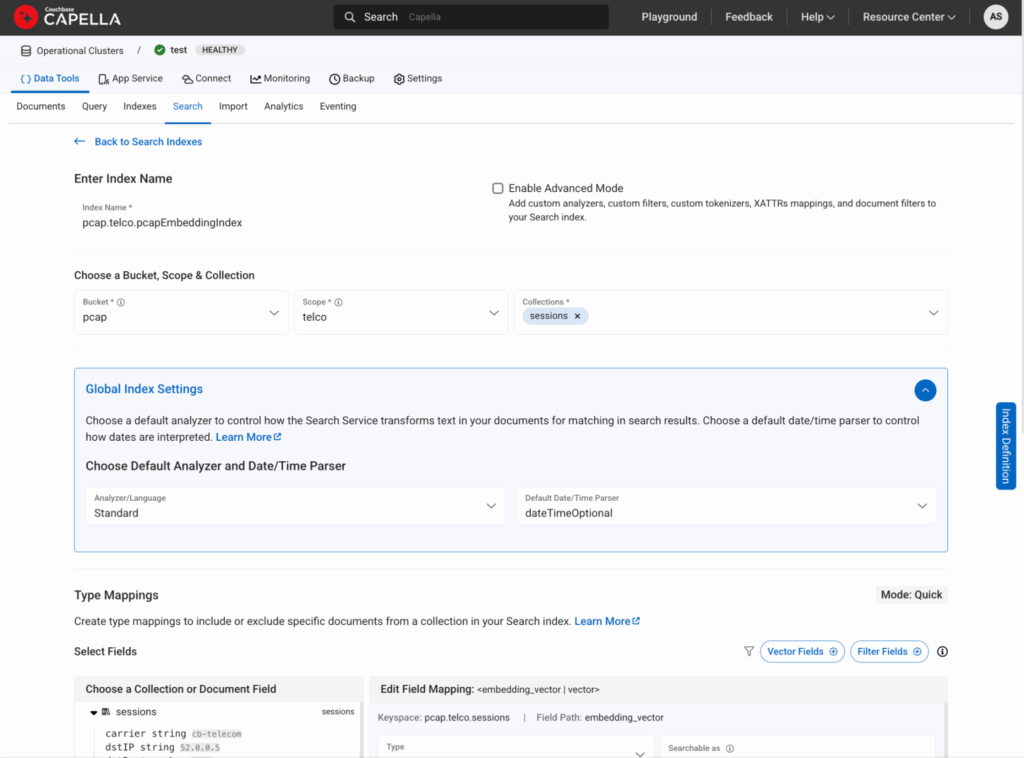
Figura 7: É assim que você criaria um índice vetorial na guia Search
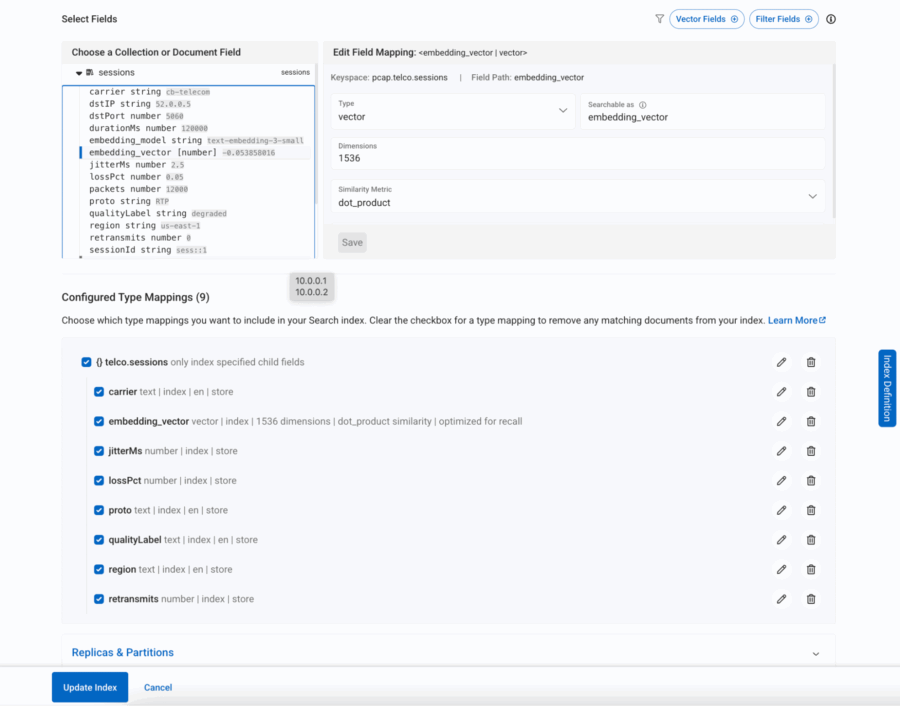
Figura 8: Todos os campos obrigatórios no sessão são incluídos na pesquisa
Destacando a detecção de anomalias com pesquisa híbrida
Por fim, vamos ver a verdadeira recompensa: detecção de anomalias com a tecnologia pesquisa vetorial híbrida.
Imagine que você tenha recebido uma série de reclamações sobre quedas de chamadas em Nova York. Você poderia executar uma consulta como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECIONAR META(s).id, s.sessionId, s.summaryText, s.qualityLabel, s.região, s.proto, s.transportadora DE `pcap`.`telecomunicações`.`sessões` AS s ONDE PESQUISA(s, { "campos": ["*"], "knn": [ { "k": 10, "campo": "embedding_vector" (vetor de incorporação), "vetor": [/* ... preencha com sua incorporação real ... */], "filtro": { "conjuncts": [ { "match": "degradado", "campo": "qualityLabel" }, { "match": "us-east-1", "campo": "region" (região) }, { "match": "SIP", "campo": "proto" }, { "match": "cb-telecom", "campo": "transportadora" } ] } } ] }); |
Essa consulta diz:
-
- Encontre 10 sessões mais semelhantes a uma degradado Chamada SIP (similaridade semântica)
- Mas somente se elas ocorrerem em us-east-1, eram chamadas SIP
O que você recebe de volta não é apenas uma lista de “chamadas ruins” - é uma grupo de anomalias semanticamente relacionadas que o ajuda a identificar a causa principal. Se todos eles estiverem ocorrendo em uma única operadora, você acabou de isolar um problema do provedor. Se eles aumentam em determinados horários, talvez seja um gargalo de roteamento.
É nesse ponto que a pesquisa vetorial deixa de ser uma “matemática legal” e começa a oferecer insight operacional real.
Pesquisa vetorial como a espinha dorsal dos aplicativos agênticos
Os aplicativos agênticos são projetados não apenas para recuperar informações, mas também para interpretá-las e agir com base nelas. Quer seja um copiloto de suporte ao cliente, um mecanismo de detecção de fraudes ou um detector de anomalias em telecomunicações, esses sistemas precisam:
-
- Recuperação contextual: Recuperar o direito informações, não apenas correspondências literais.
- Recursos de raciocínio: Compreender relacionamentos e intenções.
- Autonomia: Acione fluxos de trabalho e decisões sem intervenção humana.
Todos os três pilares se baseiam em pesquisa vetorial. Sem embeddings, os agentes não têm memória. Sem a pesquisa de similaridade, eles não têm raciocínio. Sem contexto semântico, eles não podem agir de forma eficaz.
É por isso que a pesquisa vetorial é mais do que apenas um novo método de pesquisa - ela é o espinha dorsal do conhecimento da era agêntica.
Conclusão e o que vem a seguir
A pesquisa vetorial está transformando os setores ao mudar a pesquisa de palavras-chave para contexto. Ela potencializa tudo, desde a detecção de anomalias em telecomunicações até copilotos de suporte ao cliente e detecção de fraudes. Em sua essência, ela estabelece a base para aplicativos autênticos - sistemas inteligentes que podem se lembrar, raciocinar e agir.
O Couchbase dá vida a isso com sua combinação de Pesquisa de texto completo, indexação de vetores e eventos, permitindo que as empresas operacionalizem a pesquisa semântica em tempo real.
Na próxima parte, daremos um passo adiante: exploraremos como LLMs + pesquisa vetorial convergem para a criação de aplicativos agênticos verdadeiramente autônomos que não apenas entendem o contexto, mas também geram insights e tomam ações proativas.