O básico
Antes de prosseguir com a leitura, reserve alguns minutos para ler a excelente postagem sobre pesquisa geoespacial no Couchbase, conforme publicado pelo meu amigo e colega Brian Kane: https://www.couchbase.com/blog/geospatial-search-how-do-i-use-thee-let-me-count-the-ways/
Vá em frente; eu espero.
Agora que você está de volta, sabe que uma ótima maneira de aproveitar o mecanismo de pesquisa de texto completo do Couchbase é passar para ele uma série de vértices que identificam um polígono (geralmente irregular) que descreve uma região geográfica. O exemplo de Brian usa dez pares de pontos lat/long:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"polygon_points": [ "35.987374, -83.658937", "35.971769, -83.654212", "35.887168, -83.793874", "35.686403, -83.678068", "35.704374, -83.505435", "35.769145, -83.275637", "35.868423, -83.290819", "35.919168, -83.350486", "35.948053, -83.510420", "35.990925, -83.568382" ] |
Esses pontos delimitam aproximadamente uma região no Tennessee, ao sul da rodovia, ao norte do limite do parque nacional e dentro de um único condado... bom o suficiente para a análise necessária e fácil de colar em sua solicitação. Com isso, o mecanismo de índice de pesquisa de texto completo (FTS) do Couchbase pode retornar facilmente todos os elementos de dados necessários associados a pontos dentro (ou fora) do perímetro. (Brian dá um ótimo exemplo disso em sua postagem).
A chave inglesa (ou talvez o distrito em forma de chave inglesa)
Mas e se sua região poligonal for extremamente detalhada e complexa, talvez exigindo milhares de pares de pontos lat/long para descrever? Temos exemplos prontos desses casos? Sim! Graças ao trabalho árduo das cinquenta Assembleias Legislativas Estaduais e/ou de seus substitutos, temos muitos exemplos de regiões como essa na forma de distritos do Congresso dos EUA. E graças ao Couchbase N1QL e à pesquisa geoespacial do FTS, temos os meios para gerenciar os dados com facilidade.
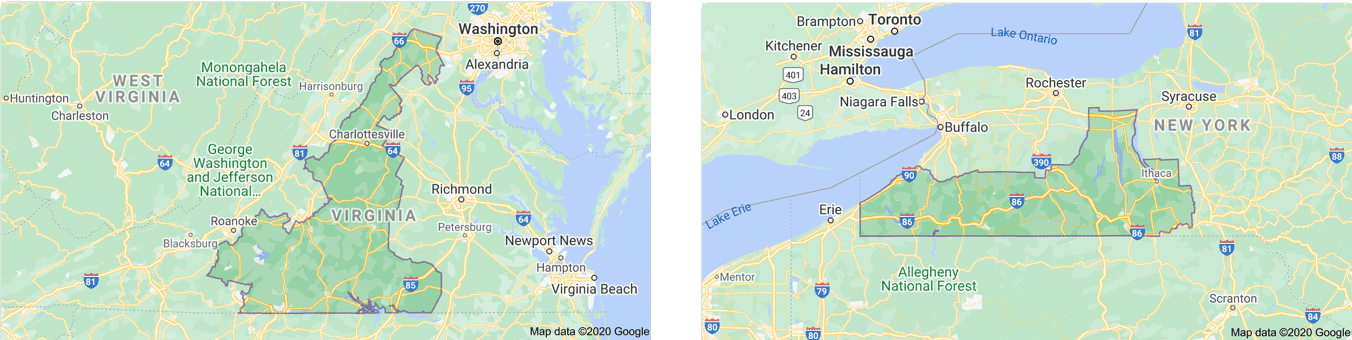
O distrito médio do Congresso dos EUA requer 8.694 vértices para ser definido. Os motivos para isso são práticos (espera-se que todos eles compreendam aproximadamente o mesmo número de cidadãos), políticos (os partidos no poder podem distorcer os limites dos distritos de forma que os eleitores os mantenham assim - isso é chamado de gerrymandering) e geográficos (muitos deles são baseados em parte em rios, lagos, costas oceânicas, montanhas e outros limites naturais). O distrito geograficamente mais complexo (ou seja, o que exige o maior número de vértices para ser descrito) é o 5º Distrito Congressional da Virgínia, que precisa de impressionantes 40.145 pares lat/long para ser descrito (e parece um T. Rex invertido desenfreado). O mais simples, com apenas 422, é o 36º Distrito Congressional de Nova York, que parece um submarino se esgueirando do Lago Erie.
Os dados
Portanto, é evidente que vamos querer armazenar e recuperar nossos pontos geográficos de um banco de dados se quisermos implementar consultas a eles em grande escala. E como é provável que os pontos sejam encontrados na forma de uma matriz incorporada, um documento JSON no Couchbase é a solução ideal. Abaixo está um exemplo de um documento desse tipo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
{ "geometry": { "type": "Polygon", "coordinates": [ { "geometry": { "type": "Polygon", "coordinates": [ [ [-93.911307,44.546513999999995], [-93.91024,44.548004999999996], [-93.909904,44.548300999999995], [-93.90922599999999,44.548843999999995], [etc., etc., for hundreds or thousands of pairs] [-93.911307,44.546513999999995] ] ] }, "type": "Feature", "properties": { "INTPTLAT": "+44.4789680", "FUNCSTAT": "N", "INTPTLON": "-092.8530418", "LSAD": "C2", "GEOID": "2702", "AWATER": 243358361, "CD116FP": "02", "CDSESSN": "116", "MTFCC": "G5200", "NAMELSAD": "Congressional District 2", "STATEFP": "27", "ALAND": 6314464923 } } |
Por que os dados têm esse formato, você pode se perguntar, com os pontos do polígono incorporados em uma matriz de elemento único sem nome, incorporada em outra matriz de "coordenadas", incorporada em um objeto de "geometria"? A resposta simples é que, às vezes, você simplesmente trabalha com os dados que tem. (Ela se baseia na fonte pública que consegui encontrar, que foi notavelmente fácil de importar para o Couchbase. Talvez eu escreva uma postagem separada descrevendo esse processo). E mesmo que os dados sejam um pouco complicados, a linguagem N1QL, como veremos a seguir, facilita a recuperação do que precisamos.
O outro conjunto de dados que nos interessa compreende a parte principal do nosso exemplo. É uma lista de milhões de eleitores registrados (não se preocupe; falsifiquei os nomes e endereços), juntamente com a afiliação partidária e o histórico de votação de cada um. Um documento de exemplo tem a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "City": "Adelanto", "doctype": "Voter", "Name": "Ryan Johnson", "County": "San Bernardino", "Party": "Democrat", "Reg": [{"Year": 2018}, {"Voted": "In person","Year": 2016}, {"Year": 2014}, {"Voted": "In person","Year": 2012}, {"Year": 2010}, {"Voted": "In person","Year": 2008}, {"Year": 2006}, {"Voted": "In person","Year": 2004}, {"Year": 2002}, {"Voted": "In person","Year": 2000}, {"Year": 1998}, {"Voted": "In person","Year": 1996}], "Addr": "221 Cindy Inlet Suite 064", "Zip": "92301", "Geo": {"lat": 34.6149071942612,"lon": -117.51442556265236} } |
O caso de uso e a configuração
Finalmente, nosso caso de uso: Dado um constituinte individual ao telefone, como um membro do Congresso determina rapidamente se a pessoa é ou não membro de seu distrito eleitoral? Resolveremos o problema com FTS e N1QL.
Primeiro, devemos preparar o índice FTS. Em nosso caso, indexaremos todos os documentos com base no campo de tipo _tipo. Vamos indexar o Nome como uma palavra-chave, e o campo Geo como um ponto geográfico. Esta é a aparência no meu console:
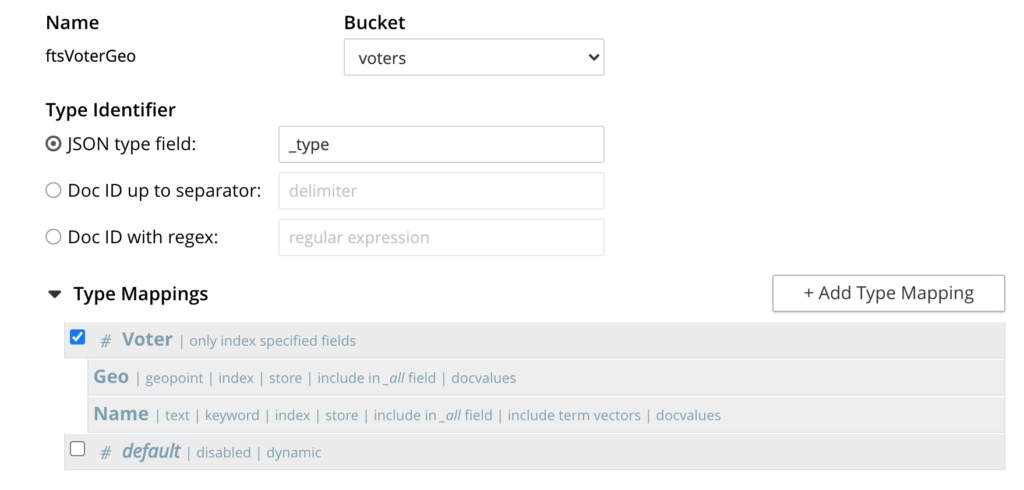
(A postagem de Brian apresenta mais detalhes sobre as etapas que você seguirá para criar um índice).
Depois que esse índice for criado, poderemos passar a ele uma série de pontos de polígono e receber uma série de resultados. Seguindo o exemplo de Brian, testei isso usando um curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
curl -s -XPOST -H "Content-Type: application/json" -u Administrator:password https://localhost:8094/api/index/ftsVoterGeo/query -d ' { "fields": ["Name"], "size": 50, "query": { "field": "Geo", "polygon_points": [ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] } }' | jq '("result_count: "+ (.total_hits | tostring)), (.hits[]| (.id + " " + .fields.Name))' |
Isso me mostra que uma pesquisa em uma região poligonal simples pode e retornará uma lista de nomes. Teoricamente, poderíamos parar por aí e deixar o aplicativo (ou mesmo o usuário) pesquisar os resultados para ver se encontra o nome do eleitor individual em questão. Mas podemos fazer melhor. Vamos deixar que o mecanismo de pesquisa reduza a busca. Fazemos isso por meio de uma pesquisa de "conjunção". (Pense em uma conjunção como um AND lógico e uma disjunção como um OR lógico):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
curl -s -XPOST -H "Content-Type: application/json" -u Administrator:password https://localhost:8094/api/index/ftsVoterGeo/query -d ' { "fields": ["Name"], "size": 50, "query": { "conjuncts": [ { "field": "Geo", "polygon_points": [ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] }, { "field": "Name", "match": "Anne Murray" } ] } }' | jq '("result_count: "+ (.total_hits | tostring)), (.hits[]| (.id + " " + .fields.Name))' |
Você pode ler isso como "Se o ponto geográfico estiver dentro dos limites do polígono e o nome corresponder ao nome do eleitor, retorne o resultado". Funciona perfeitamente, portanto sabemos que nosso índice FTS está definido corretamente.
A extração
Agora, então, precisamos testar a recuperação dos limites de um distrito individual no banco de dados. Nossa primeira tentativa envolve apenas uma inspeção simples dos dados que provavelmente usaremos, talvez apenas para um único distrito:
|
1 2 |
select properties.NAMELSAD, districts.geometry.coordinates from districts use keys 'district::87'; |
Isso retorna um resultado como este:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "NAMELSAD": "Congressional District 8", "coordinates": [ [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], |
...e assim por diante, para mais 1,3 MB de um conjunto de resultados. Não é de se admirar que não queiramos cortar e colar isso.
Nosso objetivo, lembre-se, é terminar com algo parecido com isto:
|
1 2 3 4 5 6 |
[ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] |
Veja como conseguimos isso:
|
1 2 3 4 5 |
select value concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87' )[0] c; |
Isso é bastante complicado, então vamos desvendá-lo. Lembre-se de que estamos trabalhando com os dados que temos, e não com o que poderíamos querer idealmente, e os pontos do polígono que procuramos estão embutidos em uma matriz de elemento único sem nome, embutida em outra matriz de "coordenadas", embutida em um objeto de "geometria". Precisamos desenrolá-los um a um. Primeiro, vamos eliminar o invólucro da matriz sem nome. Para isso, basta solicitar que apenas o único membro (primeiro, ou "zeroth") da matriz seja retornado:
|
1 2 |
select districts.geometry.coordinates[0] from districts use keys 'district::87' |
O objeto JSON retornado dessa consulta tem a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[ { "$1": [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], [ -119.650139, 38.287678 ], |
Podemos converter isso em uma matriz (em vez de um objeto JSON) usando select value:
|
1 2 |
select value districts.geometry.coordinates[0] from districts use keys 'district::87' |
Agora temos a matriz muito grande que buscamos, ainda envolvida em um único elemento de outra matriz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], [ -119.650139, 38.287678 ], [ -119.650154, 38.288041 |
Vamos selecionar a partir desse conjunto de retorno:
|
1 2 3 |
select * from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
Isso gera uma série de pequenos objetos que podemos dobrar à nossa vontade:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "c": [ -119.651375, 38.286637999999996 ] }, { "c": [ -119.650185, 38.287234 ] }, |
Agora que podemos abordá-los, vamos converter os tipos e realizar nossa concatenação:
|
1 2 3 |
select concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
Os objetos resultantes têm a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "points": "38.286637999999996, -119.651375" }, { "points": "38.287234, -119.650185" }, { "points": "38.287678, -119.650139" }, |
Agora, use o select value para recebê-los como uma matriz:
|
1 2 3 |
select value concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
E temos os resultados que estamos procurando:
|
1 2 3 4 5 6 |
[ "38.286637999999996, -119.651375", "38.287234, -119.650185", "38.287678, -119.650139", "38.288041, -119.650154", "38.288593999999996, -119.649699", |
A facilidade dos CTEs
O último truque que temos na manga para fazer tudo isso é bom. Precisamos de uma maneira de fazer referência à matriz que contém os geopontos como um componente de uma instrução SQL maior. Felizmente, o N1QL nos fornece os meios para fazer isso na forma de Common Table Expressions (CTE). As CTE, que são adicionadas a uma consulta por meio da função com são avaliadas uma vez por bloco de consulta e podem ser introduzidas antes de uma seleção. É exatamente isso que estamos procurando:
|
1 2 3 4 5 |
with geopoints as ( select value concat(tostring(c[1]),", ",tostring(c[0])) points from ((select value d.geometry.coordinates[0] from districts d use keys 'district::87')[0]) c ) |
Agora temos acesso a um conjunto de retorno avaliado "geopoints" que pode ser referenciado em instruções SQL subsequentes (ou múltiplas subsequentes). Perfeito. Aqui ele é usado na consulta final:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
with geopoints as ( select value concat(tostring(c[1]),", ",tostring(c[0])) points from ((select value d.geometry.coordinates[0] from districts d use keys 'district::87')[0]) c ) select Name from voters AS v where v._type = "Voter" AND search(v.Geo, { "query": { "conjuncts": [ { "field": "Geo", "polygon_points": geopoints }, { "field": "Name", "match": "Anne Murray" } ] } } ); |
Aqui está, então: Um bloco de código simples de tela única que recupera os limites complexos de um distrito e os utiliza como parte de uma pesquisa geoespacial orientada por N1QL. Experimente a técnica e vença seus próprios desafios geográficos.
Muito obrigado a Brian Kane por sua postagem original e a Dmitry Lychagin pela ajuda em desvendar as matrizes aninhadas.