최신 분산 시스템에서는 고가용성, 재해 복구, 성능 최적화를 보장하기 위해 서로 다른 환경 간에 데이터를 복제하는 기능이 매우 중요합니다. Couchbase의 XDCR(데이터 센터 간 복제) 기능은 클러스터 간에 데이터를 원활하게 복제하여 지리적으로 또는 논리적으로 고립된 환경에서도 강력한 데이터 공유를 가능하게 합니다.
이 가이드는 서로 다른 VPC 내의 별도의 Amazon EKS(Elastic Kubernetes Service) 클러스터에서 호스팅되는 두 개의 Couchbase 클러스터 간에 XDCR을 설정하는 과정을 안내합니다. 인프라 설정부터 클러스터 간 통신을 위한 DNS 구성, 실시간 복제를 위한 Couchbase 배포에 이르기까지 각 단계를 자세히 살펴보겠습니다. 이 연습이 끝나면 사용자 환경에서 이를 복제할 수 있는 기술을 갖춘 프로덕션 준비된 설정을 갖추게 됩니다.
전제 조건
이 가이드를 따르려면 다음 사항을 확인하세요:
-
- AWS CLI 설치 및 구성
- VPC, EKS 클러스터 및 보안 그룹을 생성할 수 있는 권한이 있는 AWS 계정
- 쿠버네티스 및 kubectl, 헬름과 같은 도구에 익숙함
- 헬름을 설치하여 카우치베이스 배포
- CIDR 블록, 라우팅 테이블 및 DNS를 포함한 네트워킹 개념에 대한 기본 지식
1단계: 별도의 VPC에 EKS 클러스터 배포
지금 뭐하는 거죠?
다음을 사용하여 별도의 VPC에 두 개의 쿠버네티스 클러스터인 클러스터1과 클러스터2를 생성한다. eksctl. 각 클러스터는 독립적으로 작동하며 IP 충돌을 피하기 위해 자체 CIDR 블록을 갖습니다.
이것이 왜 중요한가요?
이러한 분리를 통해 보장됩니다:
-
- 더 나은 보안 및 관리를 위한 격리
- 워크로드 처리를 위한 확장성 및 유연성
- 클러스터 간 명확한 라우팅 규칙
클러스터를 생성하는 명령
클러스터 배포1
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster1 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.0.0.0/16 |
클러스터2 배포
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster2 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.1.0.0/16 |
예상 결과
-
- 클러스터1은 VPC 10.0.0.0/16에 상주합니다.
- 클러스터2는 VPC 10.1.0.0/16에 상주합니다.

2단계: 클러스터 간 통신을 위한 VPC 피어링
지금 뭐하는 거죠?
두 VPC 간에 VPC 피어링 연결을 만들고 클러스터 간 통신을 활성화하기 위해 라우팅 및 보안 규칙을 구성하고 있습니다.
단계
2.1 피어링 연결 만들기
-
- AWS 콘솔 > VPC > 피어링 연결
- 클릭 피어링 연결 만들기
- 를 선택하고 요청자 VPC (클러스터1 VPC) 및 수용자 VPC (클러스터2 VPC)
- 연결 이름 지정 eks-peer
- 클릭 피어링 연결 만들기
2.2 피어링 요청 수락
-
- 피어링 연결 선택
- 클릭 작업 > 요청 수락
2.3 경로 테이블 업데이트
-
- 클러스터1 VPC의 경우, 피어링 연결을 대상으로 10.1.0.0/16에 대한 경로를 추가합니다.
- 클러스터2 VPC의 경우, 피어링 연결을 대상으로 10.0.0.0/16에 대한 경로를 추가합니다.

2.4 보안 그룹 수정
이것이 왜 필요한가요?
보안 그룹은 방화벽 역할을 하며 클러스터 간의 트래픽을 명시적으로 허용해야 합니다.
수정하는 방법
-
- 다음으로 이동합니다. EC2 > 보안 그룹 AWS 콘솔에서
- 클러스터1 및 클러스터2와 연결된 보안 그룹을 식별합니다.
- 클러스터1의 보안 그룹의 경우:
- 클릭 인바운드 규칙 편집
- 규칙을 추가합니다:
- 유형: 모든 트래픽
- 출처: 클러스터2의 보안 그룹 ID
- 클러스터2에 대해 반복하여 클러스터1의 보안 그룹에서 트래픽을 허용합니다.



3단계: 클러스터2에 NGINX를 배포하여 연결성 테스트하기
지금 뭐하는 거죠?
클러스터1이 클러스터2와 통신할 수 있는지 확인하기 위해 클러스터2에 NGINX 포드를 배포하고 있습니다.
이것이 왜 중요한가요?
이 단계는 Couchbase를 배포하기 전에 클러스터 간의 네트워킹이 작동하는지 확인하는 단계입니다.
단계
3.1 클러스터1과 클러스터2에 네임스페이스 만들기
|
1 2 |
kubectl create ns dev #in cluster1 kubectl create ns prod #in cluster2 |
3.2 클러스터1과 클러스터2에 NGINX 배포하기
-
- nginx.yaml을 생성합니다:
12345678910111213141516171819202122232425262728293031apiVersion: apps/v1kind: Deploymentmetadata:name: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80---apiVersion: v1kind: Servicemetadata:name: nginxspec:clusterIP: Noneports:- port: 80targetPort: 80selector:app: nginx
- nginx.yaml을 생성합니다:
3.3 YAML 적용
|
1 |
kubectl apply -f nginx.yaml -n prod |
3.4 클러스터1에서 연결 확인
-
- Exec을 클러스터1의 파드에 설치합니다:
1kubectl exec -it -n dev <pod-name> -- /bin/bash
- Exec을 클러스터1의 파드에 설치합니다:
3.5 Cluster2에 대한 연결 테스트
|
1 |
curl nginx.prod |
예상 결과
그리고 curl 명령은 DNS 포워딩이 없으면 실패하므로 추가 DNS 구성이 필요하다는 점을 강조합니다.

4단계: DNS 포워딩 구성
지금 뭐하는 거죠?
클러스터2의 서비스가 클러스터1에서 확인될 수 있도록 DNS 전달을 구성하겠습니다. 이는 클러스터1의 애플리케이션이 DNS 이름을 사용하여 클러스터2의 서비스와 상호 작용할 수 있도록 하는 데 중요합니다.
이것이 왜 중요한가요?
쿠버네티스 서비스 검색은 DNS에 의존하며, 기본적으로 한 클러스터의 서비스에 대한 DNS 쿼리는 다른 클러스터에서 확인할 수 없다. 클러스터1의 CoreDNS는 클러스터2의 DNS 확인자에게 쿼리를 전달해야 합니다.
단계
4.1 클러스터2의 DNS 서비스 엔드포인트 가져오기
-
- Cluster2에서 다음 명령을 실행하여 DNS 서비스 엔드포인트를 가져옵니다:
1kubectl get endpoints -n kube-system - 검색 kube-dns 또는 coredns 서비스를 검색하고 해당 IP 주소를 기록합니다. 예를 들어
1234----------------------------------------NAME ENDPOINTS AGEkube-dns 10.1.20.116:53 3h----------------------------------------

- Cluster2에서 다음 명령을 실행하여 DNS 서비스 엔드포인트를 가져옵니다:
4.2 클러스터1에서 CoreDNS 컨피그맵 편집하기
-
- 편집을 위해 CoreDNS 컨피그맵을 엽니다:
1kubectl edit cm coredns -n kube-system
- 편집을 위해 CoreDNS 컨피그맵을 엽니다:
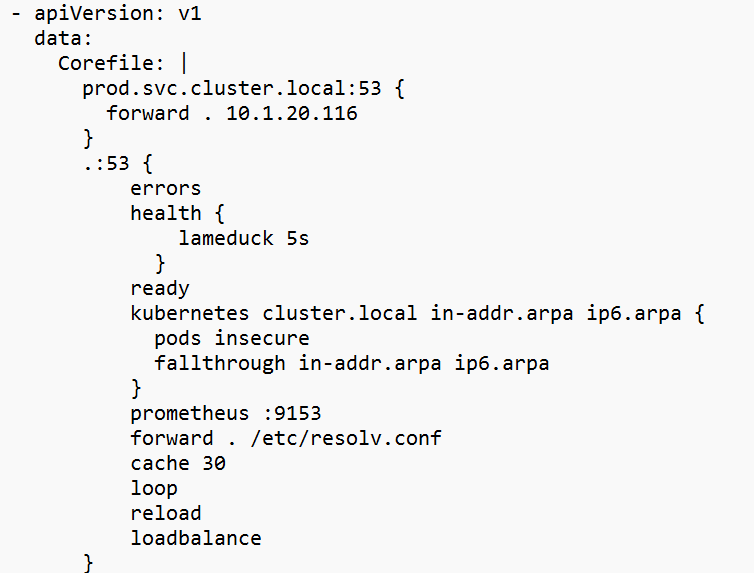
4.3 A다음 블록을 코어파일 섹션에 추가합니다.
|
1 2 3 |
prod.svc.cluster.local:53 { forward . 10.1.20.116 } |
10.1.20.116을 클러스터2의 실제 DNS 엔드포인트 IP로 바꿉니다.
참고: 이 컨피그맵에는 CoreDNS 엔드포인트 중 하나만 사용해야 합니다. CoreDNS 포드의 IP는 거의 변경되지 않지만 노드가 다운되면 변경될 수 있습니다. kube-dns ClusterIP 서비스를 사용할 수 있지만 EKS 노드에서 IP와 포트가 열려 있어야 합니다.
4.4 클러스터에서 CoreDNS 재시작1
-
- CoreDNS를 다시 시작하여 변경 사항을 적용합니다:
1kubectl rollout restart deployment coredns -n kube-system

- CoreDNS를 다시 시작하여 변경 사항을 적용합니다:
4.5 DNS 포워딩 확인
-
- Exec을 클러스터1의 모든 파드에 설치합니다:
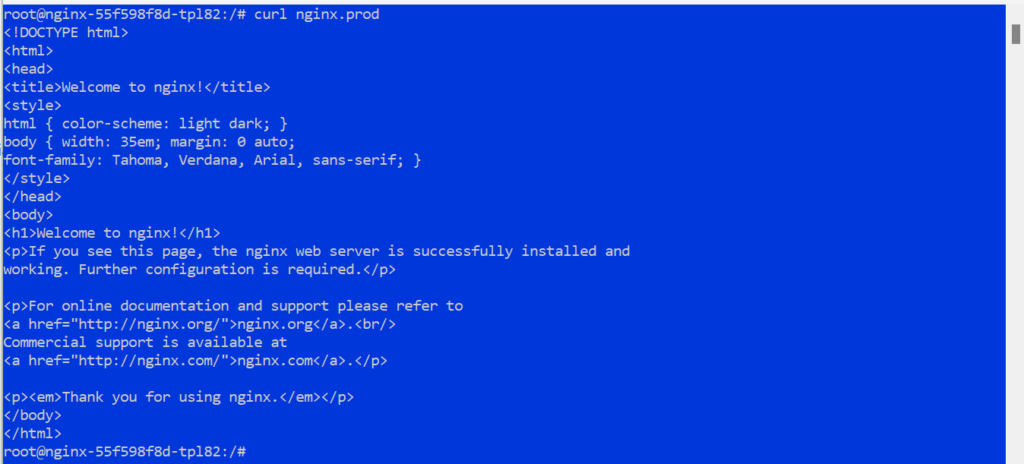
1kubectl exec -it -n default <pod-name> -- /bin/bash - 클러스터2에서 NGINX 서비스에 대한 DNS 확인을 테스트합니다:
1curl nginx.prod.svc.cluster.local - NGINX 서비스에서 응답이 표시되어야 합니다.
- Exec을 클러스터1의 모든 파드에 설치합니다:
예상 결과
클러스터1에서 클러스터2로의 DNS 쿼리가 성공적으로 해결되어야 합니다.
5단계: Couchbase 배포하기
지금 뭐하는 거죠?
Helm을 사용하여 두 Kubernetes 환경에 Couchbase 클러스터를 배포하겠습니다. 각 클러스터는 XDCR을 통해 연결되기 전에 자체 데이터를 독립적으로 관리합니다.
이것이 왜 중요한가요?
카우치베이스 클러스터는 XDCR 설정의 기초를 형성하며, 강력하고 확장 가능한 NoSQL 데이터베이스 플랫폼을 제공합니다.
단계
5.1 카우치베이스 헬름 차트 저장소 추가하기
|
1 2 |
helm repo add couchbase https://couchbase-partners.github.io/helm-charts/ helm repo update |
5.2 클러스터에 Couchbase 배포1
-
- 클러스터1로 전환합니다:
1kubectl config use-context <cluster1-context> - 카우치베이스를 배포합니다:
1helm install couchbase couchbase/couchbase-operator --namespace dev
- 클러스터1로 전환합니다:

5.3 클러스터2에 카우치베이스 배포하기
-
- 클러스터2로 전환합니다:
1kubectl config use-context <cluster2-context> - 카우치베이스를 배포합니다:
1helm install couchbase couchbase-operator --namespace prod
- 클러스터2로 전환합니다:
5.4 배포 확인
-
- 카우치베이스 포드를 확인합니다:
12kubectl get pods -n dev # For Cluster1kubectl get pods -n prod # For Cluster2

- 모든 파드가 실행 중인지 확인합니다.
- 카우치베이스 포드를 확인합니다:

참고: 배포 오류가 발생하면 호환되는 이미지 버전을 사용하도록 CouchbaseCluster CRD를 편집하세요:
|
1 |
kubectl edit couchbasecluster <cluster-name> -n <namespace> |
변경:
|
1 |
image: couchbase/server:7.2.0 |
To:
|
1 |
image: couchbase/server:7.2.4 |
예상 결과
카우치베이스 클러스터는 실행 중이어야 하며 각각의 UI를 통해 액세스할 수 있어야 합니다.
6단계: XDCR 설정
지금 뭐하는 거죠?
두 카우치베이스 클러스터 간에 데이터 복제를 활성화하도록 XDCR을 구성하겠습니다.
이것이 왜 중요한가요?
XDCR은 클러스터 전반에서 데이터 일관성을 보장하여 고가용성 및 재해 복구 시나리오를 지원합니다.
단계
6.1 Cluster2에서 서비스 이름 가져오기
-
- cluster2에서 다음 명령을 실행하여 포드 중 하나의 서비스 이름을 검색하여 포트 포워딩할 수 있도록 합니다.
1kubectl get services -n prod
- cluster2에서 다음 명령을 실행하여 포드 중 하나의 서비스 이름을 검색하여 포트 포워딩할 수 있도록 합니다.
6.2 Cluster2용 Couchbase UI에 액세스하기
-
-
- 카우치베이스 UI를 포트 포워딩합니다:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- 카우치베이스 UI를 포트 포워딩합니다:
-
-
- 브라우저를 열고 다음으로 이동합니다:
https://localhost:8091
- 브라우저를 열고 다음으로 이동합니다:
-
- 배포 중에 구성된 자격 증명을 사용하여 로그인합니다.
6.3 클러스터2에서 문서 보기
-
- Couchbase UI에서 다음과 같이 이동합니다. 버킷
- 문서가 없는 경우 기본값 버킷

6.4 클러스터용 Couchbase UI에 액세스1
-
- 카우치베이스 UI를 포트 포워딩합니다:
1kubectl port-forward -n dev cluster1-0000 8091:8091

- 브라우저를 열고 다음으로 이동합니다:
https://localhost:8091 - 배포 중에 구성된 자격 증명을 사용하여 로그인합니다.
- 카우치베이스 UI를 포트 포워딩합니다:
6.5 원격 클러스터 추가
-
- Couchbase UI에서 다음과 같이 이동합니다. XDCR > 원격 클러스터 추가
- 원격 클러스터를 구성합니다:
- 클러스터 이름: Cluster2
- IP/호스트명:.prod.svc.cluster.local
- 사용자 이름: 클러스터2의 관리자 사용자 이름
- 비밀번호: 클러스터2의 관리자 비밀번호
- 클릭 저장

6.6 복제 설정
-
- Cluster1용 Couchbase UI에서 다음으로 이동합니다. XDCR > 복제 추가
- 복제를 구성합니다:
- 버킷에서 복제: 클러스터1의 기본 버킷
- 버킷에 복제: 클러스터2의 기본 버킷
- 원격 클러스터: 클러스터2 선택
- 클릭 저장


6.7 테스트 복제
-
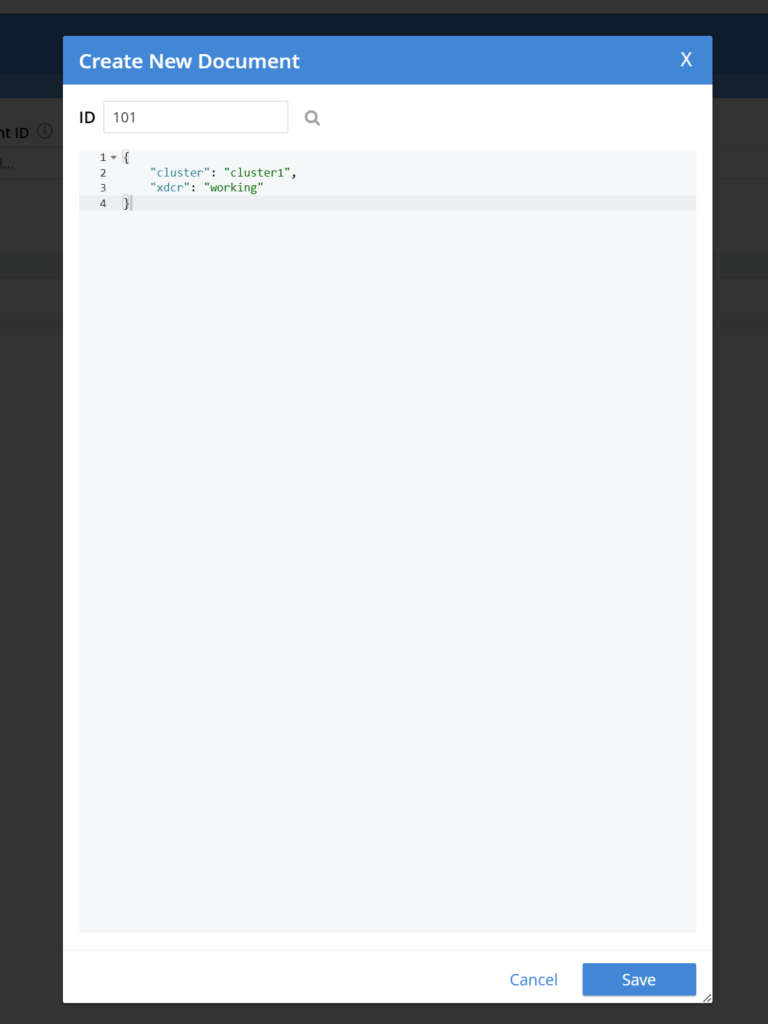
- 클러스터1의 기본 버킷에 샘플 문서를 추가합니다:
- Couchbase UI에서 다음 항목으로 이동합니다. 버킷 > 문서 > 문서 추가
- 제공 문서 독특한 ID 의 일부 데이터와 JSON 형식
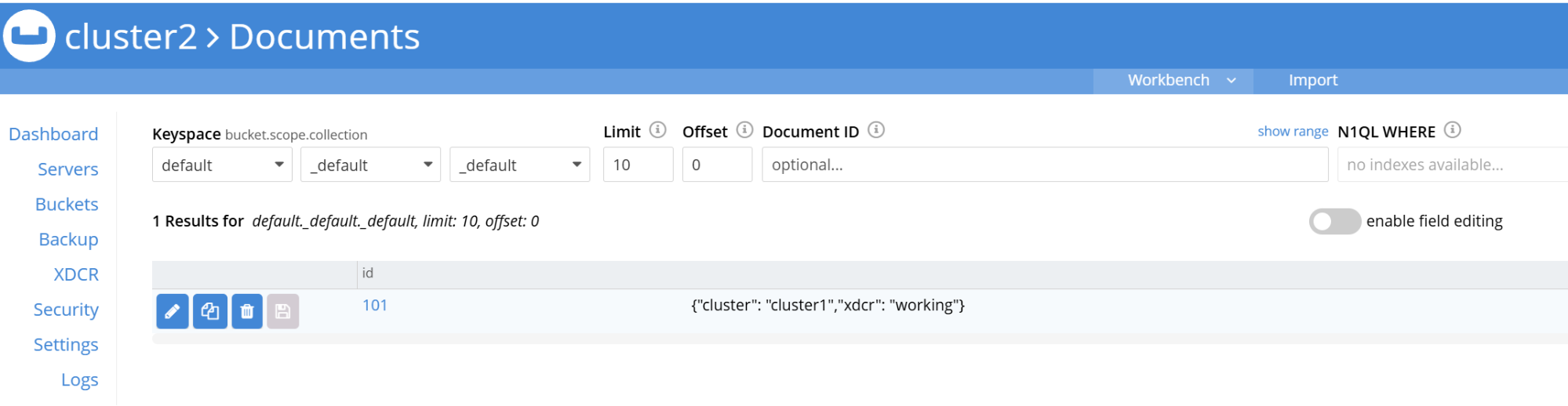
- 문서가 클러스터2의 기본 버킷에 표시되는지 확인합니다:
- Cluster2의 UI로 포트 포워딩하고 로그인합니다:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- Cluster2의 UI로 포트 포워딩하고 로그인합니다:
- 로 이동합니다: https://localhost:8091
- 클러스터1의 기본 버킷에 샘플 문서를 추가합니다:

예상 결과
클러스터1에 추가된 데이터는 클러스터2에 실시간으로 복제되어야 합니다.
7단계: 정리
지금 뭐하는 거죠?
AWS 환경을 정리하고 배포한 모든 리소스를 삭제합니다.
이것이 왜 중요한가요?
이렇게 하면 불필요한 요금이 부과되는 것을 방지할 수 있습니다.
단계
7.1 AWS 콘솔에 액세스
-
- AWS 콘솔 > VPC > 피어링 연결
- 피어링 연결 선택 및 삭제
- AWS 콘솔 > CloudFormation > 스택
- 두 개의 노드 그룹 스택을 선택하고 삭제합니다.
- 두 노드 그룹 스택의 삭제가 완료되면 클러스터 스택을 선택하고 삭제합니다.
예상 결과
이 튜토리얼을 위해 생성된 모든 리소스는 계정에서 삭제됩니다.
결론
이 가이드를 통해 AWS VPC에서 별도의 EKS 클러스터에서 실행되는 Couchbase 클러스터 간에 XDCR을 성공적으로 구축했습니다. 이 설정은 강력하고 확장 가능한 솔루션을 위해 AWS 네트워킹과 Kubernetes를 결합하는 것의 힘을 강조합니다. 클러스터 간 복제를 사용하면 애플리케이션의 복원력이 향상되고, 분산된 사용자의 대기 시간이 단축되며, 견고한 재해 복구 메커니즘을 확보할 수 있습니다.
여기에 설명된 단계를 이해하고 구현하면 멀티 클러스터 설정과 관련된 실제 문제를 해결하고 클라우드 네트워킹 및 분산 데이터베이스 관리에 대한 전문성을 확장할 수 있습니다.
-
- 자세히 알아보기 카우치베이스 크로스 데이터센터 복제(XDCR)
- 읽기 XDCR 문서
- 방법 읽기 전 세계에 분산된 데이터에 필수적인 XDCR재해 복구 및 고가용성

