이 글은 제임스 포웬스키와 안드레아 바스코가 Couchbase Connect Online 2020에서 발표한 '실시간 AI 기반 데이터 분석 플랫폼, Couchbase와 Splunk의 만남'이라는 세션을 기반으로 작성되었습니다.
혼란의 벽
대학생 시절부터 저는 항상 데이터 과학에 매료되어 있었습니다. 당시에는 아직 자랑할 만한 분야는 아니었지만, 추정 이론을 처음 접했을 때의 느낌을 아직도 기억합니다.
우리는 지금 데이터 세트가 기하급수적으로 증가하여 공개적으로 이용 가능한 데이터의 황금기에 살고 있으며, 오늘날 많은 훌륭한 플랫폼이 머신러닝과 딥러닝 기술을 활용하여 의사 결정 과정을 초인적인 수준으로 끌어올릴 수 있는 간소화된 방법을 제공하고 있습니다.
다차원 스케일링 (MDS)는 인덱싱, 쿼리 및 분석 워크로드 격리를 위해 제가 선호하는 Couchbase 기능 중 하나입니다: 저는 몇 년 동안 관계형 데이터베이스에서 대규모 데이터 세트의 패턴과 상관관계를 찾기 위해 데이터를 마이닝했는데, 말할 필요도 없이 잠금, 성능 저하 등으로 인해 DBA와 마찰을 빚는 복잡한 쿼리를 실행하는 경우가 많았습니다.
저는 소위 혼란의 벽라고 생각합니다. 이 문제는 저에게 너무도 소중한 문제였기 때문에 2013년에 우리는 논문 작성 오라클 워크로드 특성화의 이해에 대해 설명합니다.
현장 설정: ACME에 지속적인 인텔리전스 제공
2019년에 가트너는 다음과 같은 사실을 확인했습니다. 지속적인 인텔리전스 로서 상위 10가지 분석 트렌드2022년까지 "모든 비즈니스 이니셔티브의 50% 이상은 실시간 의사 결정을 강화하기 위해 스트리밍 데이터를 활용하는 지속적인 인텔리전스를 필요로 할 것입니다."
이 글과 시리즈에서는 일상 업무에 큰 영향을 주지 않으면서 디지털 트랜스포메이션을 향해 비즈니스를 혁신하는 것을 목표로 Couchbase를 사용하여 지속적 인텔리전스를 시작하는 실용적인 방법을 안내해 드리겠습니다. 사이트 안정성 엔지니어(SRE) 에서 ACME의 온라인 스토어에 지속적인 인텔리전스를 구현하는 임무를 맡고 있습니다.
다음 사항에 대해 기본적으로 잘 알고 있다고 가정합니다. 카우치베이스 애널리틱스. 아래 그림에서 볼 수 있듯이, 카우치베이스 애널리틱스는 대규모 병렬 처리(MPP) 아키텍처 내에서 KV 엔진에 저장된 데이터의 섀도 복사본을 실시간으로 생성하여, SQL 유사 언어(SQL++)를 사용하여 섀도 데이터를 쿼리하거나 추가 처리를 위해 미리 집계된 대규모 데이터 세트를 타사 솔루션에 노출하는 데 사용할 수 있습니다.
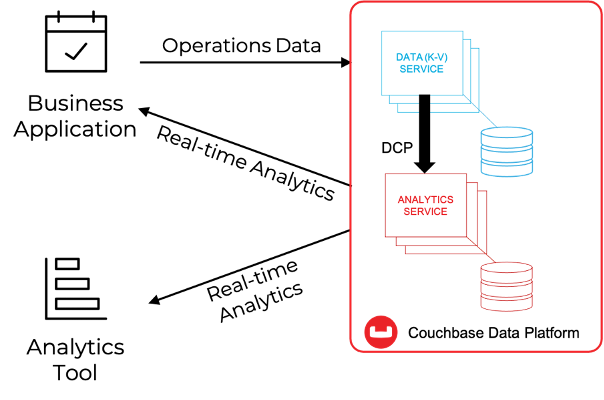
Couchbase는 밀리초 미만의 작업이 가능한 플랫폼에 구축된 NoSQL의 유연성, 워크로드 격리, 다차원 선형 확장성, 타사 솔루션과의 통합을 모두 멀티 클라우드에서 에지에 이르는 하나의 우아한 플랫폼에 결합하여 ACME의 지속적 인텔리전스를 향한 여정을 시작하는 데 필요한 기본 기술을 제공합니다.
ACME의 SRE인 저희는 Couchbase가 어떻게 차세대 온라인 스토어를 위한 세계적 수준의 엔터프라이즈 데이터 플레인을 제공할 수 있는지 쉽게 이해할 수 있습니다. 하지만 비즈니스 로직은 어떨까요?
비즈니스에서 어떤 종류의 비즈니스 로직이 필요한지에 따라 다릅니다: Couchbase는 개별 문서를 프로그래밍 방식으로 검색하거나 임시/선험적 쿼리를 실행하는 데 필요한 모든 기능을 기본으로 제공합니다(쿼리 또는 분석). 하지만 ACME의 차세대 온라인 스토어의 경우 데이터 탐색, 통합 가시성, 데이터 탐색, 실시간 대시보드, 머신 러닝, AI 등 모든 분석 기능을 제공하는 오늘날 시장의 많은 엔터프라이즈 솔루션과 함께 시너지를 발휘할 수 있을 것입니다.
말할 필요도 없이 Couchbase는 이들과 통합되도록 설계되었으며, 오늘의 예제에서는 다음을 사용할 것입니다. 카우치베이스 애널리틱스 REST API 와 통합하려면 Splunk.
왜 Splunk일까요? 너무 자세히 설명하지 않고 몇 가지 강력한 이유를 소개합니다:
- 채택 및 성숙도 수준: Splunk는 ITOM 분야의 시장 리더따라서 조직에서 이미 실험할 수 있는 기술과 환경을 갖추고 있을 가능성이 높습니다.
- 로컬 평가판예산이 부족한 경우, 로컬에 Splunk를 설치하고 60일 평가판 기간 동안 무료로 사용할 수 있습니다.
- 사용 편의성: Splunk 검색 처리 언어(SPL) 는 배우기 매우 쉬우면서도 강력하며, 시작하는 데 도움이 되는 수많은 리소스가 있습니다.
- Splunk 앱: Splunk는 다음과 같은 원클릭 설치 애플리케이션의 활발한 에코시스템과 함께 제공됩니다. 머신러닝 툴킷 코딩 없이도 ML 모델의 잠금을 해제할 수 있는 도구로, 초보자나 Pytorch, Pandas, TensorFlow와 같은 라이브러리에 익숙하지 않은 사용자에게 이상적입니다.
ACME SRE로서 우리는 스스로에게 물어볼 수 있습니다: 간단한 구현으로 유의미한 결과를 얻을 수 있을까요? 데이터 과학자들은 현재 업계 현황을 볼 때, 시장의 AI에 대한 요구가 반드시 최신의 최첨단 알고리즘을 필요로 하는 것은 아니며 회귀, 이상값 탐지, 클러스터링, 정서 분석과 같은 전통적인 기법이 오늘날 조직이 디지털 혁신을 추진하는 데 가장 효과적인 도구라는 사실을 확인하게 될 것입니다.
물론 이러한 기술의 기초가 되는 이론을 기본적으로 이해하는 것은 좋은 습관입니다. 반대로 컨볼루션 네트워크, 강화 학습, 생성적 적대 신경망, 블렌더 등에 대해 알 필요는 없습니다.
그럼, 계획이 세워진 것 같네요 - 이제 본격적인 시작을 할 시간입니다! 다음 단락에서는 그렇게 하도록 하겠습니다:
- 온라인 스토어에서 수행된 거래를 나타내는 일련의 JSON 문서를 생성하여 Couchbase로 가져옵니다;
- 이 정보를 Analytics 데이터 집합에 복제합니다.
- SQL++를 사용하여 이 데이터 세트에서 쿼리를 실행하고, Analytics REST API를 통해 결과를 Splunk로 수집합니다.
- Splunk를 사용하여 운영 데이터 및 기계 학습 예측을 실시간으로 보여주는 대시보드 만들기[1]
차 한 잔 마시고 준비하세요. 이제 곧 출발합니다. 출발!
지속적인 인텔리전스를 위한 6단계
1단계 #1: 데이터 생성
데이터 규정을 준수하기 위해 다음과 같은 온라인 도구를 사용할 것입니다. JSON 생성기[2] 를 사용하여 ACME 온라인 스토어에서 거래를 대표하는 JSON 문서를 생성합니다. 생성 매개변수를 구성한 방법은 다음과 같습니다.[3]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[ '{{repeat(120 ,2000 )}}', { _id: 'order_{{objectId()}}', orderId:'{{integer(90000,1256748321)}}', transaction:'{{random("declined","approved")}}', name: '{{firstName()}} {{surname()}}', gender: '{{gender()}}', email: '{{email()}}', country: '{{country()}}', city: '{{city()}}', phone: '{{phone()}}', ts: Date.now()+600000, product: [ '{{repeat(1,9)}}', 'product: {{random("apples", "tea bags", "butter", "milk", "kale", "wine", "cookies", "hamburgers", "sweet potatoes", "brown rice", "barley" ) }}' ] } ] |
'생성'을 클릭하면 아래 스크린샷과 같이 도구가 120개에서 2000개 사이의 다양한 JSON 문서 집합으로 응답합니다.
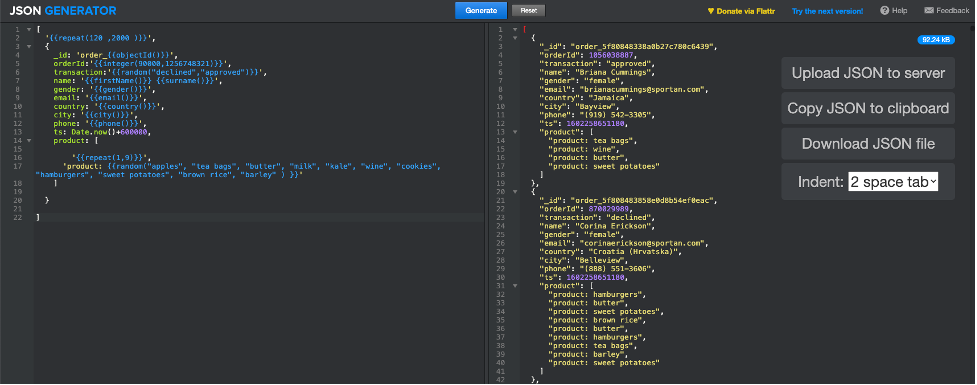
기준선이 정해졌으니 이제 Couchbase로 이동할 차례입니다!
1단계TP5T2: Couchbase에서 데이터 가져오기
최소한 데이터와 분석 서비스를 실행하는 Couchbase 클러스터가 이미 사용 가능하다고 가정합니다.
첫 번째 단계로 다음을 수행합니다. 버킷 만들기 명명된 카우치마트 (원하는 이름을 자유롭게 지정하세요.) JSON 문서가 로드됩니다.
그런 다음 Couchbase 클러스터에 JSON 파일을 업로드합니다.를 실행하는 노드를 선택합니다. 데이터 서비스를 클릭하고 파일을 /tmp 폴더를 선택합니다(원하는 폴더를 사용해도 됩니다). SCP를 사용할 수 있는 경우 로컬 컴퓨터의 터미널에서 이 명령을 실행합니다:
|
1 |
Scp <jsonfile> <couchbaseuser>@<couchbaseserver>:/tmp |
사용자 환경에 따라 , , 를 설정하기만 하면 됩니다.
마지막으로, 다음을 수행합니다. JSON 파일을 카우치마트 버킷으로 가져옵니다.를 사용하여 cbimport 명령(자세한 정보 여기); 먼저 SSH를 통해 이전에 파일을 업로드한 데이터 노드에 로그인합니다:
|
1 |
ssh <couchbaseuser>@<couchbaseserver> |
로그인에 성공하면 cbimport 명령어를 사용하여 환경에 따라 사이의 필드를 설정하세요:
|
1 2 |
$CBHOME/bin/cbimport json -c couchbase://localhost -b <bucketname> -u <user> - p <password> -f list -d file:///tmp/<jsonfile> -g %_id% -t 4 |
Couchbase는 훨씬 더 많은 작업을 처리할 수 있으므로 가져오기는 눈 깜짝할 사이에 완료됩니다. 이제 버킷 섹션의 Couchbase 관리자 UI에서 버킷에 일부 문서가 있는지 확인해야 합니다(아래 스크린샷 참조).
데이터가 있으니 이제 분석할 차례입니다!
1단계TP5T3: 분석 데이터 세트 만들기 및 테스트
첫 번째 단계로 다음을 수행합니다. acmeorders라는 데이터 집합을 만듭니다. (원하는 대로 이름을 지을 수 있습니다!) 카우치마트 버킷의 그림자 복제품으로이 데이터 세트에는 Splunk에 다운스트림으로 노출되는 모든 정보가 포함됩니다.
데이터 집합을 만드는 데 익숙하지 않은 경우 다음을 확인하는 것이 좋습니다. 문서 그리고 이 튜토리얼. SQL++ 명령 두 개만 있으면 couchmart 버킷의 전체 복제본을 만들 수 있습니다:
|
1 |
CREATE DATASET acmeorders ON couchmart; |
다음에
|
1 |
CONNECT LINK Local; |
이보다 더 쉬울 수는 없습니다!
나머지 API를 사용할 예정이므로 이제 아래의 편리한 curl 명령을 사용하여 테스트해 보세요. 항상 그렇듯이 내의 값과 분석 서비스에 대해 구성된 포트를 다시 한 번 확인하시기 바랍니다:
|
1 |
curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders;" https://<couchbaseserver>:8095/analytics/service |
이 명령이 작동하면 Couchbase를 실행할 준비가 된 것입니다. Splunk로 넘어가기 전에 이 점을 기억하세요:
- 카우치베이스 애널리틱스 서비스는 다음을 기반으로 합니다. 대규모 병렬 처리 아키텍처(MPP) 선형적으로 확장되므로 성능을 두 배로 늘려야 한다면 노드를 두 배로 늘리면 됩니다.
- 버전 6.6에서는 애널리틱스 서비스에 많은 훌륭한 기능을 도입했습니다. 꼭 확인해보세요.!
이제 카우치베이스가 도와드리겠습니다. 이제 실행 가능한 인텔리전스를 보여드릴 차례입니다!
1단계TP5T4: Splunk 설정 및 구성
이 문서의 나머지 부분에서는 Linux에서 Splunk를 실행하는 것으로 가정하므로 Mac 또는 Windows를 사용하는 경우 경로가 변경될 수 있습니다.
사용 가능한 Splunk 인스턴스가 없는 경우 다음을 수행할 수 있습니다. 로컬 인스턴스 설치 60일 무료 평가판을 활용하세요. 새로운 로컬 설치를 완료하는 데 10분 이상 걸리지 않습니다.
다음 사항을 확인하세요. 설치 Splunk 머신 러닝 툴킷를 참조하세요. Splunk 앱을 설치하는 방법에 대해 자세히 알고 싶으시면 여기를 참조하세요, 여기를 클릭하세요 - 매우 간단합니다!
Couchbase(또는 다른 소스)와의 통합을 효과적으로 설정하려면 다음을 수행하는 것이 기본입니다. Couchbase에서 REST 호출의 출력을 올바르게 해석하도록 Splunk를 구성합니다. 를 사용하여 SPL에 효과적인 형식으로 정보를 저장합니다. 이를 위해 새로운 소스 유형간단히 말해, 소스 유형은 입력에서 데이터를 구문 분석하는 방법을 정의합니다. 소스 유형을 만드는 방법에 대해 자세히 알아보지는 않고 실행 가능한 솔루션을 제공하겠습니다.
SSH를 통해 Splunk 서버에 연결한 다음 다음을 찾아봅니다:
|
1 |
Cd $SPLUNKBASE/etc/system/local |
라는 새 파일을 만듭니다. props.conf 를 다음과 같이 설정합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[couchbase] SEDCMD-remove_header = s/(.+\"results\":\s\[\s)//g SEDCMD-remove_trailing_commas = s/\},/}/g SEDCMD-remove_footer = s/(\],\s\"plans\".+)//g TIME_PREFIX = \" ts\":\s+ category = Structure disabled = false pulldown_type = 1 BREAK_ONLY_BEFORE_DATE = DATETIME_CONFIG = LINE_BREAKER = (,)\s\{ NO_BINARY_CHECK = true SHOULD_LINEMERGE = false |
저장한 후 Splunk 다시 시작. 이제 다음과 같은 새 소스 유형을 사용할 수 있습니다. 카우치베이스설정 > 소스 유형으로 이동하여 모든 것이 정상적으로 보이는지 다시 확인하세요:
이제 다음을 수행할 차례입니다. 새 Splunk 이벤트 인덱스 만들기 를 생성하고, Splunk에서 설정 > 인덱스에서 새로 만들기를 클릭한 다음 다음과 같이 새 인덱스를 구성합니다:
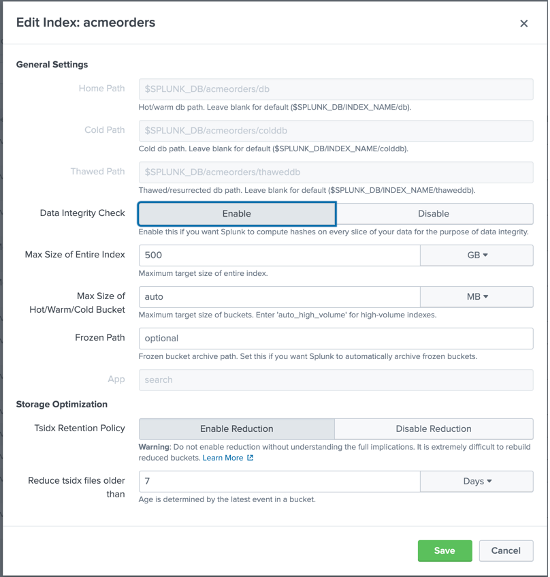
인덱스의 이름을 acmeorders원하는 대로 이름을 지정할 수 있습니다, 동일한 이름을 유지할 것을 강력히 권장합니다. - 따라서 기본 SPL 코드를 수정하지 않고도 저희가 공유해드릴 파일을 사용할 수 있습니다.
Splunk가 준비되었습니다. 이제 문을 열고 Couchbase에 데이터를 공급해 보겠습니다!
1단계TP5T5: Splunk로 데이터 가져오기
Splunk로 데이터를 가져오려면 다음과 같이 정의해야 합니다. 새로운 데이터 입력. REST 입력을 처리하기 위해 많은 Splunk 확장 프로그램을 사용할 수 있지만, 단순화를 위해 여기서는 스크립트 기반 로컬 입력[4].
첫째, 스크립트를 만들어야 합니다.를 클릭하고, SSH를 통해 Splunk 서버에 연결한 다음 다음을 찾아봅니다:
|
1 |
Cd $SPLUNKBASE/bin/scripts |
라는 새 파일을 만듭니다. acmeorders.sh 를 다음과 같이 설정하고, 스플렁크 사용자에게 실행 권한을 부여해야 합니다:
|
1 2 |
#!/bin/bash curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000;" https:// <couchbasenode>:8095/analytics/service |
눈치채셨겠지만, 이 스크립트에는 앞서 acmeorders 데이터 집합을 테스트할 때 사용한 것과 동일한 curl 명령이 사용됩니다: 어디 조건. 30초마다 카우치베이스를 폴링할 것이므로 대량의 데이터 중복을 피하기 위해 각 실행 시 가져오는 데이터의 양을 제한하는 것이 중요합니다.
SQL++ where 조건:
|
1 |
Where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000 |
는 타임스탬프가 적어도 90초; 즉, 데이터 손실 없이 2번의 투표 실패를 견뎌낼 수 있습니다.
계속 진행하기 전에 이 접근 방식이 개념 증명을 실행하는 데 얼마나 효과적인지 강조하는 것이 중요하며, 프로덕션에서는 플레이스홀더와 북마크를 사용하여 주어진 시간에 새 데이터만 읽도록 하는 더 효율적인 방법을 고려해야 합니다. 이벤트-기반 전략 해당되는 경우.
터미널에서 프롬프트를 표시하여 스크립트를 테스트합니다:
|
1 |
$SPLUNKBASE/bin/scripts/acmescript.sh |
이 테스트가 성공하면 다음을 수행해야 합니다. 새 데이터 입력 설정. Splunk에서 설정 > 데이터 입력으로 이동하여 스크립트를 기반으로 하는 새 로컬 입력을 선택합니다.
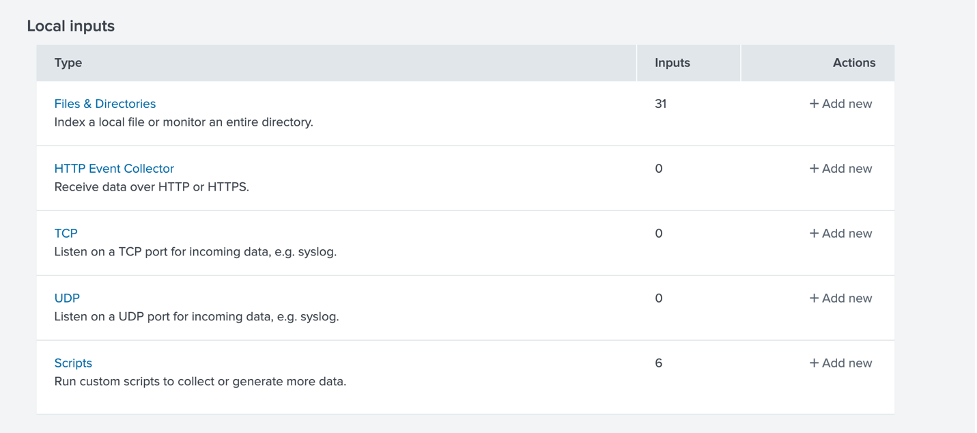
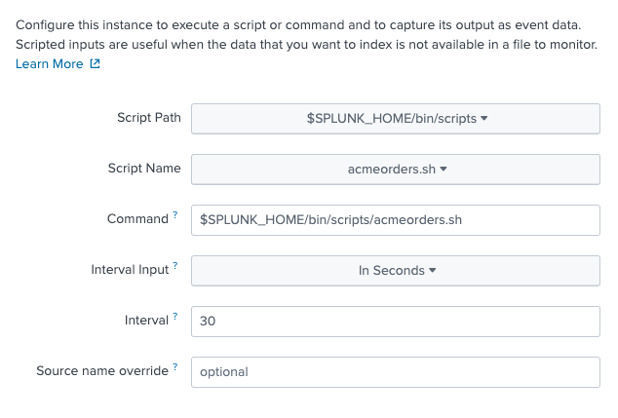
스크립트, 새 로컬 스크립트를 차례로 클릭한 다음 다음과 같이 새 스크립트를 구성합니다. 먼저 스크립트 경로와 폴링 빈도를 구성합니다:
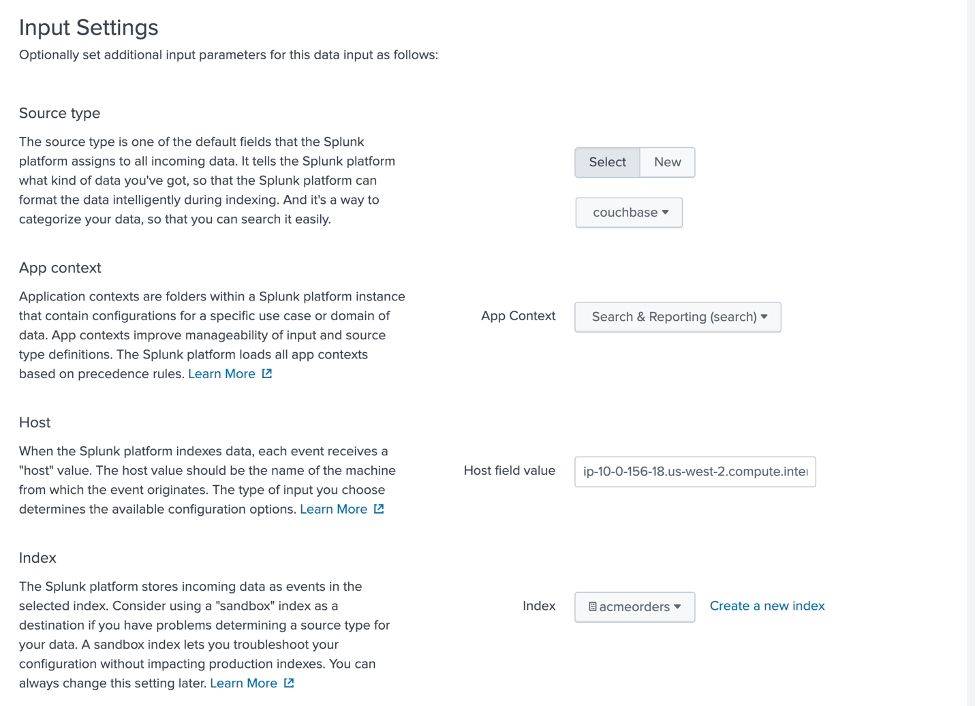
그런 다음 아래 그림과 같이 입력 설정을 구성합니다. 카우치베이스 로서 소스 유형, 검색 및 보고 as 앱 컨텍스트및 acmeorders 로서 색인.
검토 후 제출하여 저장합니다. 데이터가 Splunk로 올바르게 유입되고 있는지 확인하려면 다음과 같이 하세요.를 클릭하고 검색 및 신고 앱에 액세스합니다:
을 클릭하고 다음 SPL 쿼리를 시도합니다. 모든 시간 대신 지난 24시간 를 시간 필터 콤보 상자에서 선택합니다:
|
1 |
index="acmeorders" sourcetype="couchbase" | dedup acmeorders.orderId | search acmeorders.product{}=* | table _time, acmeorders.name, acmeorders.gender, acmeorders.country, acmeorders.gender, acmeorders.city, acmeorders.orderId, acmeorders.product{} , acmeorders.transaction | rename acmeorders.product{} as product | rename acmeorders.gender as gender | rename "acmeorders.transaction" as approval | rename acmeorders.orderId as orderId | rename acmeorders.name as name | rename acmeorders.country as country | rename acmeorders.city as city |
아래 그림과 비슷한 내용이 표시될 것입니다:
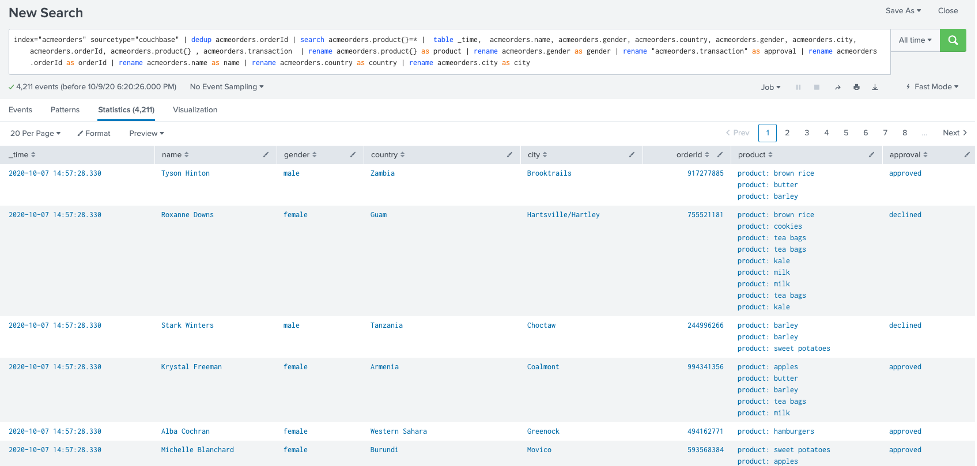
이 테스트가 성공하면... 축하드립니다! Splunk와 Couchbase를 통합하셨습니다!
마지막 단계입니다: 지속적인 인텔리전스 활용!
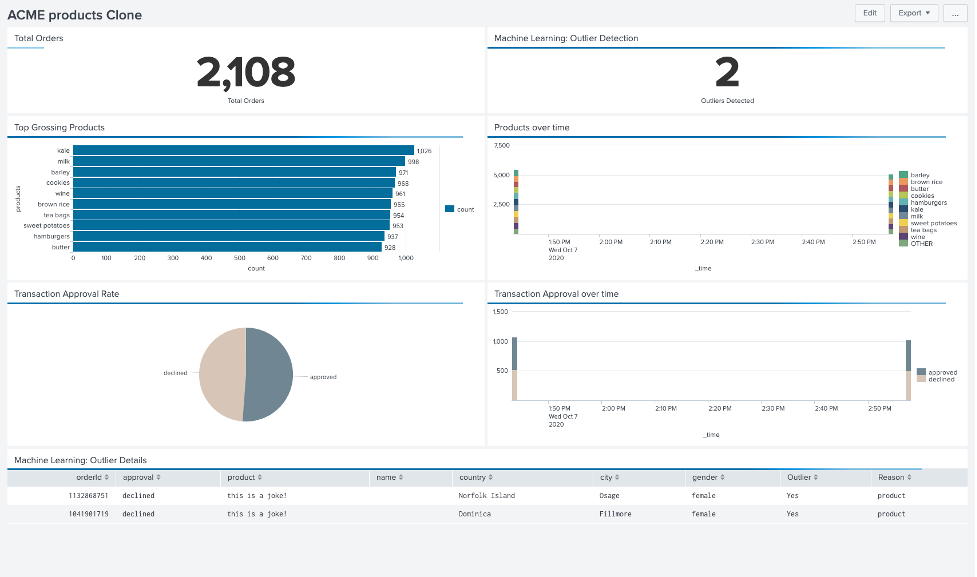
#6 단계: ML 기반 이상 징후 탐색 기능을 갖춘 Splunk 대시보드 배포
시간을 배려하기 위해, 여기서는 Splunk에서 대시보드와 머신 러닝 모델을 만드는 방법에 대해 자세히 알아보지는 않고, 대신 30초마다 새로 고쳐지도록 구성된 완전한 기능의 대시보드를 제공하겠습니다. 간단한 XML 참조 Splunk에 소개되었습니다.
템플릿 대시보드를 가져오려면 다음과 같이 하세요.검색 및 보고 앱에서 대시보드를 클릭한 다음 "새 대시보드 만들기"를 클릭하고, 원하는 이름을 지정한 다음 "대시보드 만들기"를 클릭합니다.
이제 화면 상단에 '소스' 버튼이 표시되면 클릭합니다:

포함된 XML 코드를 붙여넣기만 하면 됩니다. 이 파일에서. 완료되면 저장을 클릭하고 다시... 끝났습니다!
아래 그림과 같이 이제 수집된 총 주문, 제품 및 거래 승인에 대한 정보, 머신 러닝을 사용하여 감지된 이상값을 보여주는 대시보드에 액세스할 수 있습니다. 업데이트 실시간으로!
행동 유도: 병에서 지니를 꺼내세요!
여러분의 잠재력을 발휘하기 전에 지속적인 인텔리전스 조직에 있는 분들을 위한 행동 지침을 알려드립니다:
- 세션 검토 제임스 포우에스엔키와 저는 Couchbase Connect 2020에서 호스트했습니다, "카우치베이스와 실시간 AI 기반 데이터 분석 플랫폼인 Splunk의 만남."
- 여러 개의 새 데이터 가져오기 실행 사용 JSON 생성기 이전에 사용한 것과 동일한 절차(또는 이와 동등한 솔루션)를 사용하여 더 나은 변경 사항이 얼마나 빠르게 다운스트림으로 전파되는지 파악합니다.
- 이상값으로 실험하기를 실행하는 예제에서 JSON 생성기 를 사용하면 아래 표시된 구성으로 최대 2개의 문서를 생성할 수 있습니다. null 이름 속성과 이상값 감지를 트리거할 더미 제품 이름을 지정합니다:
123456789101112131415161718['{{repeat(1,2)}}',{_id: 'order_{{objectId()}}',orderId:'{{integer(90000,1256748321)}}',transaction:'{{random("declined","approved")}}',name: '',gender: '{{gender()}}',email: '{{email()}}',country: '{{country()}}',city: '{{city()}}',phone: '{{phone()}}',ts: Date.now()+600000,product: ['this is a joke']}] - 다른 ML 기반 인사이트로 실험해 보세요! 이 글에서는 XML로 쉽게 내보낼 수 있는 유일한 분석이기 때문에 이상값 탐지에 초점을 맞췄지만, 살펴볼 만한 다른 가치 경로도 많이 있습니다:
- 클러스터링: 고객층을 세분화하기 위해
- 예측: 계절성을 고려하여 상품 수요를 예측합니다.
- 카테고리 예측: 고객의 니즈를 예측하고 고객 유지율을 높이기 위해
- 분석 데이터 세트 향상 를 활용하여 새로운 원격 링크 및 외부 데이터 기능 카우치베이스 6.6에 도입
전체 게시물을 읽어주셔서 감사드리며, 도움이 되셨기를 바랍니다. 궁금한 점이 있으시면 언제든지 문의해 주세요. 내게 연락하기 또는 가장 가까운 카우치베이스 담당자에게 문의하세요!
이제 밖으로 나가서 비즈니스를 한 단계 더 발전시키세요!
[1] 30초마다 새로 고침
[2] FakeIt 는 더 강력하지만 약간 더 복잡한 또 다른 훌륭한 옵션이 될 것입니다.
[3] 타임스탬프를 조정했습니다. ts 를 사용하여 Couchbase 클러스터의 시계와 일치하도록 설정하고 필요에 따라 자유롭게 수정할 수 있습니다.
[4] 필요에 따라 가장 효율적인 솔루션이 아닐 수도 있지만, 쉽게 시작할 수 있는 방법입니다.