저는 4.5에서 제공되는 새로운 Couchbase의 검색 기능 대부분을 하나의 간단한 프로젝트에서 선보이고 싶었습니다. 그리고 최근 다음과 같은 기능에 대한 관심이 있었습니다. 파일 저장 또는 바이너리 를 사용할 수 있습니다. 일반적인 관점에서 볼 때 데이터베이스는 파일이나 바이너리를 저장하기 위해 만들어지지 않았습니다. 일반적으로 파일을 바이너리 저장소에 저장하고 관련 메타데이터를 DB에 저장하는 것이 일반적입니다. 관련 메타데이터는 바이너리 저장소에 있는 파일의 위치와 파일에서 최대한 많은 정보를 추출한 것입니다.
이것이 오늘 보여드릴 프로젝트입니다. 사용자가 파일을 업로드하고 바이너리 저장소에 저장하면 파일에서 관련 텍스트와 메타데이터가 추출되고 해당 메타데이터와 텍스트를 기반으로 파일을 검색할 수 있는 매우 간단한 Spring Boot 앱입니다. 마지막에는 모방 유형, 이미지 크기, 텍스트 콘텐츠, 기본적으로 파일에서 추출할 수 있는 모든 메타데이터를 기준으로 파일을 검색할 수 있습니다.
바이너리 스토어
자주 받는 질문입니다. 물론 바이너리 데이터를 DB에 저장할 수는 있지만 파일은 적절한 바이너리 저장소에 있어야 합니다. 이 예제에서는 아주 간단한 구현을 만들기로 했습니다. 기본적으로 파일 시스템에는 런타임에 선언된 폴더가 있는데, 이 폴더에는 업로드된 모든 파일이 들어 있습니다. 파일 내용에서 SHA1 다이제스트가 계산되어 해당 폴더의 파일 이름으로 사용됩니다. 물론 Joyent의 Manta나 Amazon S3와 같은 다른 고급 바이너리 저장소를 사용할 수도 있습니다. 하지만 이 글에서는 간단하게 설명하겠습니다.) 다음은 사용된 서비스에 대한 설명입니다.
SHA1Service
이것은 가장 간단한 방법으로, 기본적으로 파일 내용을 기반으로 SHA-1 다이제스트를 다시 전송하는 방법입니다. 코드를 더욱 단순화하기 위해 저는 Apache 커먼즈 코덱:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@Service public class SHA1Service { public String getSha1Digest(InputStream is) { try { return DigestUtils.sha1Hex(is); } catch (IOException e) { throw new RuntimeException(e); } } } |
데이터 추출 서비스
이 서비스는 업로드된 파일에서 메타데이터와 텍스트를 추출하기 위한 서비스입니다. 이를 수행하는 방법에는 여러 가지가 있습니다. 저는 다음을 사용하기로 했습니다. ExifTool 그리고 팝플러.
ExifTool은 파일 메타데이터를 읽고, 쓰고, 편집할 수 있는 훌륭한 명령줄 도구입니다. 또한 메타데이터를 JSON으로 직접 출력할 수도 있습니다. 물론 Exif 표준에만 국한되지 않습니다. 다양한 형식을 지원합니다. Poppler는 PDF의 텍스트 콘텐츠를 추출할 수 있는 PDF 유틸리티 라이브러리입니다. 명령줄 도구이므로 여기서는 플렉서스 도구 를 사용하여 CLI 호출을 쉽게 할 수 있습니다.
두 가지 방법이 있습니다. 첫 번째 방법은 추출 메타데이터 를 실행하고 ExifTool 메타데이터 추출을 담당합니다. 다음 명령을 실행하는 것과 같습니다:
|
1 2 |
exiftool -n -json somePDFFile |
그리고 -n 옵션은 모든 숫자 값이 문자열이 아닌 숫자로 제공되도록 하고 -json 를 입력하여 출력이 JSON 형식인지 확인합니다. 이렇게 하면 다음과 같은 출력이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[{ "SourceFile": "Desktop/someFile.pdf", "ExifToolVersion": 10.11, "FileName": "someFile.pdf", "Directory": "Desktop", "FileSize": 20468, "FileModifyDate": "2016:03:29 13:50:29+02:00", "FileAccessDate": "2016:03:29 13:50:33+02:00", "FileInodeChangeDate": "2016:03:29 13:50:33+02:00", "FilePermissions": 644, "FileType": "PDF", "FileTypeExtension": "PDF", "MIMEType": "application/pdf", "PDFVersion": 1.4, "Linearized": false, "ModifyDate": "2016:03:29 02:42:32-07:00", "CreateDate": "2016:03:29 02:42:32-07:00", "Producer": "iText 2.1.6 by 1T3XT", "PageCount": 1 }] |
마임 유형, 크기, 생성 날짜 등과 같은 몇 가지 흥미로운 정보가 있습니다. 파일의 마임 유형이 application/pdf 로 설정한 다음 팝플러를 사용하여 텍스트를 추출할 수 있는데, 이것이 서비스의 두 번째 방법입니다. 이는 다음 CLI 호출과 동일합니다:
|
1 2 |
pdftotext -raw somePDFFile - |
이 명령은 추출된 텍스트를 표준 출력으로 보냅니다. 이 텍스트를 검색하여 전체 텍스트 필드를 추가합니다. 아래는 서비스의 전체 코드입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
package org.couchbase.devex.service; import java.io.File; import org.codehaus.plexus.util.cli.CommandLineException; import org.codehaus.plexus.util.cli.CommandLineUtils; import org.codehaus.plexus.util.cli.Commandline; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Service; import com.couchbase.client.java.document.json.JsonArray; import com.couchbase.client.java.document.json.JsonObject; @Service public class DataExtractionService { private final Logger log = LoggerFactory.getLogger(DataExtractionService.class); public JsonObject extractMetadata(File file) { String command = "/usr/local/bin/exiftool"; String[] arguments = { "-json", "-n", file.getAbsolutePath() }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { JsonArray arr = JsonArray.fromJson(output); return arr.getObject(0); } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } public String extractText(File file) { String command = "/usr/local/bin/pdftotext"; String[] arguments = { "-raw", file.getAbsolutePath(), "-" }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { return output; } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } } |
plexus-utils를 사용하면 보시다시피 매우 간단합니다.
바이너리스토어서비스
이 서비스는 데이터 추출 및 파일 저장, 파일 삭제 또는 파일 검색을 실행하는 역할을 담당합니다. 저장 부분부터 시작하겠습니다. 모든 작업은 storeFile 메서드를 사용합니다. 가장 먼저 해야 할 일은 파일의 다이제스트를 검색한 다음 구성에 선언된 바이너리 저장 폴더에 파일을 쓰는 것입니다. 파일이 쓰여지면 데이터 추출 서비스가 호출되어 메타데이터를 JsonObject로 검색합니다. 그런 다음 바이너리 저장소 위치, 문서 유형, 다이제스트 및 파일 이름이 해당 JSON 객체에 추가됩니다. 업로드된 파일이 PDF인 경우, 데이터 추출 서비스가 다시 호출되어 텍스트 콘텐츠를 검색한 후 전체 텍스트 필드를 추가합니다. 그런 다음 다이제스트를 키로, JsonObject를 콘텐츠로 사용하여 JsonDocument를 생성합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void storeFile(String name, MultipartFile uploadedFile) { if (!uploadedFile.isEmpty()) { try { String digest = sha1Service.getSha1Digest(uploadedFile.getInputStream()); File file2 = new File(configuration.getBinaryStoreRoot() + File.separator + digest); BufferedOutputStream stream = new BufferedOutputStream(new FileOutputStream(file2)); FileCopyUtils.copy(uploadedFile.getInputStream(), stream); stream.close(); JsonObject metadata = dataExtractionService.extractMetadata(file2); metadata.put(StoredFileDocument.BINARY_STORE_DIGEST_PROPERTY, digest); metadata.put("type", StoredFileDocument.COUCHBASE_STORED_FILE_DOCUMENT_TYPE); metadata.put(StoredFileDocument.BINARY_STORE_LOCATION_PROPERTY, name); metadata.put(StoredFileDocument.BINARY_STORE_FILENAME_PROPERTY, uploadedFile.getOriginalFilename()); String mimeType = metadata.getString(StoredFileDocument.BINARY_STORE_METADATA_MIMETYPE_PROPERTY); if (MIME_TYPE_PDF.equals(mimeType)) { String fulltextContent = dataExtractionService.extractText(file2); metadata.put(StoredFileDocument.BINARY_STORE_METADATA_FULLTEXT_PROPERTY, fulltextContent); } JsonDocument doc = JsonDocument.create(digest, metadata); bucket.upsert(doc); } catch (Exception e) { throw new RuntimeException(e); } } else { throw new IllegalArgumentException("File empty"); } } |
이제 읽기 또는 삭제는 매우 간단하게 이해할 수 있을 것입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public StoredFile findFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { return null; } JsonDocument doc = bucket.get(digest); if (doc == null) return null; StoredFileDocument fileDoc = new StoredFileDocument(doc); return new StoredFile(f, fileDoc); } public void deleteFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { throw new IllegalArgumentException("Can't delete file that does not exist"); } f.delete(); bucket.remove(digest); } |
이것은 매우 순진한 구현이라는 점을 명심해 주세요!
파일 인덱싱 및 검색
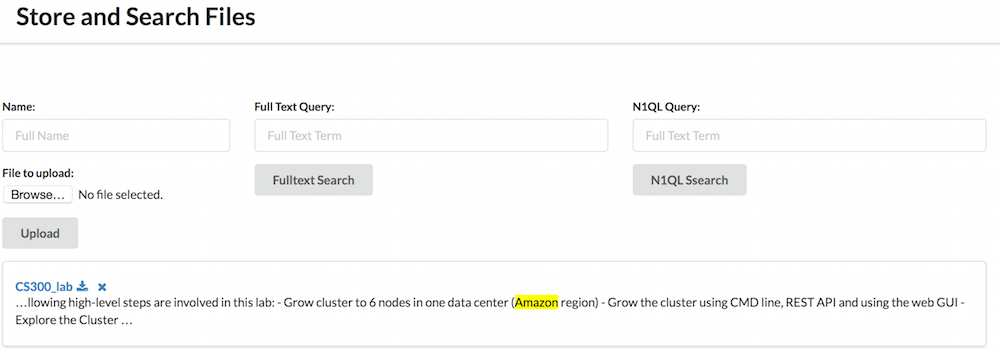
파일을 업로드한 후에는 파일을 검색하고 싶을 것입니다. 가장 기본적인 첫 번째 방법은 파일의 전체 목록을 표시하는 것입니다. 그런 다음 N1QL을 사용하여 메타데이터를 기반으로 검색하거나 FTS를 사용하여 콘텐츠를 기반으로 검색할 수 있습니다.
검색 서비스
getFiles 메서드는 단순히 다음 쿼리를 실행합니다: SELECT binaryStoreLocation, binaryStoreDigest FROM기본값WHERE 유형= '파일'. 그러면 업로드된 파일의 전체 목록과 다이제스트 및 바이너리 저장소 위치가 전송됩니다. 일관성 옵션이 statement_plus. 문서 애플리케이션이기 때문에 강력한 일관성을 선호합니다.
다음은 다음과 같습니다. 검색N1QL파일 를 추가하여 기본 N1QL 쿼리를 실행할 수 있습니다. 따라서 기본값은 위와 동일한 쿼리에 WHERE 부분이 추가되는 것입니다. 아직까지 이보다 더 긴밀한 통합은 없습니다. 사용자가 밈 유형, 크기 또는 ExifTool에서 제공하는 기타 필드를 기반으로 파일을 검색할 수 있는 멋진 검색 양식을 만들 수 있습니다.
그리고 마지막으로 검색전체파일 문자열을 입력으로 받고 이를 경기 쿼리를 입력합니다. 그러면 해당 용어가 발견된 텍스트 조각과 함께 결과가 다시 전송됩니다. 이 조각을 통해 문맥에서 해당 용어를 강조 표시할 수 있습니다. 또한 이진 저장소 다이제스트 그리고 바이너리 스토어 위치 필드. 사용자에게 결과를 표시하는 데 사용되는 필드입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
public List<Map<String, Object>> getFiles() { N1qlQuery query = N1qlQuery .simple("SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file'"); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchN1QLFiles(String whereClause) { N1qlQuery query = N1qlQuery.simple( "SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file' " + whereClause); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchFulltextFiles(String term) { SearchQuery ftq = MatchQuery.on("file_fulltext").match(term) .fields("binaryStoreDigest", "binaryStoreLocation").build(); SearchQueryResult result = bucket.query(ftq); List<Map<String, Object>> filenames = result.hits().stream().map(row -> { Map<String, Object> m = new HashMap<String, Object>(); m.put("binaryStoreDigest", row.fields().get("binaryStoreDigest")); m.put("binaryStoreLocation", row.fields().get("binaryStoreLocation")); m.put("fragment", row.fragments().get("fulltext")); return m; }).collect(Collectors.toList()); return filenames; } |
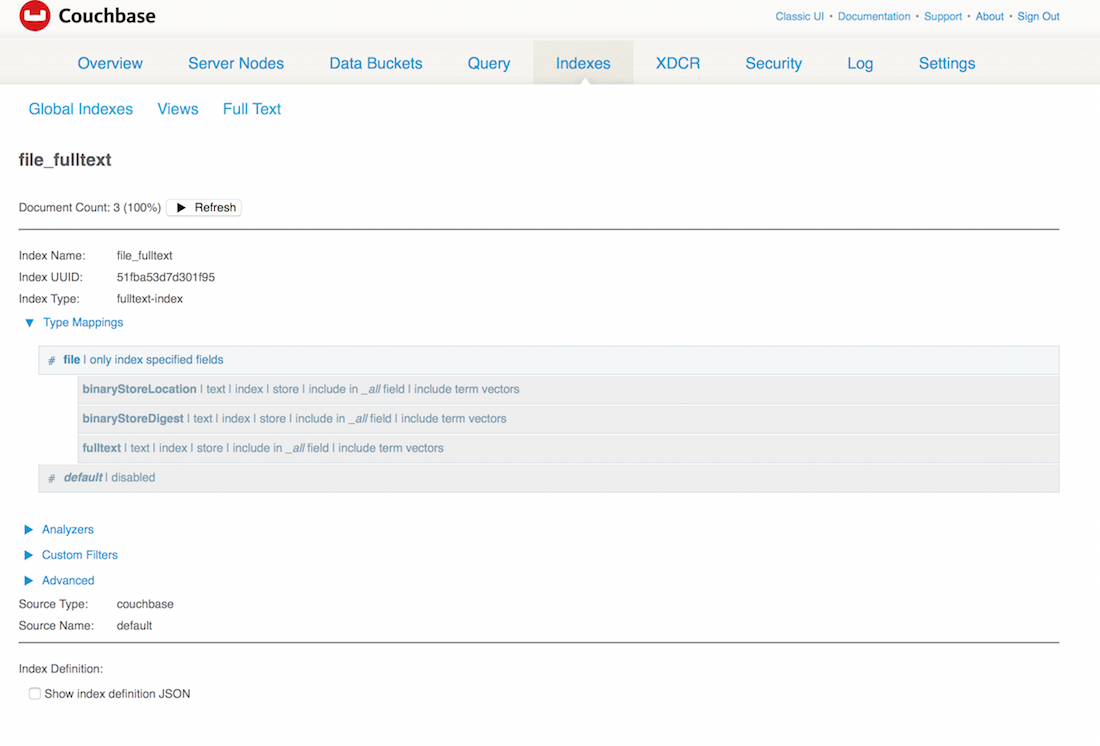
그리고 TermQuery.on 메서드는 쿼리할 인덱스를 정의합니다. 여기서는 'file_fulltext'로 설정되어 있습니다. 그 이름으로 전체 텍스트 인덱스를 만들었음을 의미합니다:
모든 것을 하나로 모으기
구성
먼저 구성에 대해 간단히 말씀드리겠습니다. 지금까지 구성할 수 있는 것은 바이너리 저장소 경로뿐입니다. 저는 Spring Boot를 사용하고 있으므로 다음 코드만 있으면 됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package org.couchbase.devex; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; @Configuration public class BinaryStoreConfiguration { @Value("${binaryStore.root:upload-dir}") private String binaryStoreRoot; public String getBinaryStoreRoot() { return binaryStoreRoot; } } |
이를 통해 간단히 다음을 추가할 수 있습니다. binaryStore.root=/Users/ldoguin/binaryStore 내 application.properties 파일을 업로드할 수 있습니다. 또한 최대 512MB 파일 업로드를 허용하고 싶습니다. 또한 스프링 부트 카우치베이스 자동 구성을 활용하려면 내 카우치베이스 서버의 주소를 추가해야 합니다. 결국 제 application.properties 는 다음과 같이 보입니다:
|
1 2 3 4 5 |
binaryStore.root=/Users/ldoguin/binaryStore multipart.maxFileSize: 512MB multipart.maxRequestSize: 512MB spring.couchbase.bootstrap-hosts=localhost |
Spring Boot 자동 구성을 사용하려면 스프링-부트-스타터-부모를 부모로 설정하고 클래스 경로에 Couchbase를 설정하기만 하면 됩니다. 따라서 Couchbase 자바 클라이언트 종속성을 추가하기만 하면 됩니다. 기본값은 2.2.3이고 FTS는 2.2.4에만 있기 때문에 여기서는 2.2.4 버전을 지정합니다. 전체 pom 파일은 다음 링크에서 확인할 수 있습니다. Github. 에 대한 찬사 스테판 니콜 피보탈과 사이먼 바슬레 이 멋진 Spring 통합을 위해 Couchbase에서 제공했습니다.
컨트롤러
이 응용 프로그램은 매우 간단하기 때문에 모든 것을 동일한 아래에 두었습니다. 컨트롤러. 가장 기본적인 엔드포인트는 /파일. 이미 업로드된 파일 목록을 표시합니다. searchService를 한 번만 호출하고 결과를 Model 페이지에 넣은 다음 페이지를 렌더링하면 됩니다.
|
1 2 3 4 5 6 7 |
@RequestMapping(method = RequestMethod.GET, value = "/files") public String provideUploadInfo(Model model) { List<Map<String, Object>> files = searchService.getFiles(); model.addAttribute("files", files); return "uploadForm"; } |
사용 타임 리프 렌더링 및 시맨틱 UI 를 CSS 프레임워크로 사용합니다. 사용된 템플릿을 살펴볼 수 있습니다. 여기. 애플리케이션에서 사용되는 유일한 템플릿입니다.
파일 목록이 있으면 다운로드하거나 삭제할 수 있습니다. 두 메서드 모두 바이너리 스토어 서비스 메서드를 호출하고 있으며, 나머지 코드는 전형적인 Spring MVC입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@RequestMapping(method = RequestMethod.GET, value = "/download/{digest}") public String download(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) throws IOException { StoredFile sf = binaryStoreService.findFile(digest); if (sf == null) { redirectAttributes.addFlashAttribute("message", "This file does not exist."); return "redirect:/files"; } response.setContentType(sf.getStoredFileDocument().getMimeType()); response.setHeader("Content-Disposition", String.format("inline; filename="" + sf.getStoredFileDocument().getBinaryStoreFilename() + """)); response.setContentLength(sf.getStoredFileDocument().getSize()); InputStream inputStream = new BufferedInputStream(new FileInputStream(sf.getFile())); FileCopyUtils.copy(inputStream, response.getOutputStream()); return null; } @RequestMapping(method = RequestMethod.GET, value = "/delete/{digest}") public String delete(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) { binaryStoreService.deleteFile(digest); redirectAttributes.addFlashAttribute("message", "File deleted successfuly."); return "redirect:/files"; } |
당연히 파일도 업로드하고 싶을 것입니다. 간단한 멀티파트 POST입니다. 바이너리 저장소 서비스를 호출하고 파일을 유지한 다음 적절한 데이터를 추출한 다음 /파일 엔드포인트.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@RequestMapping(method = RequestMethod.POST, value = "/upload") public String handleFileUpload(@RequestParam("name") String name, @RequestParam("file") MultipartFile file, RedirectAttributes redirectAttributes) { if (name.isEmpty()) { redirectAttributes.addFlashAttribute("message", "Name can't be empty!"); return "redirect:/files"; } binaryStoreService.storeFile(name, file); redirectAttributes.addFlashAttribute("message", "You successfully uploaded " + name + "!"); return "redirect:/files"; } |
마지막 두 가지 방법은 검색에 사용됩니다. 검색 서비스를 호출하고 결과를 모델 페이지에 추가하여 렌더링하기만 하면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RequestMapping(method = RequestMethod.POST, value = "/fulltext") public String fulltextQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchFulltextFiles(query); model.addAttribute("files", files); return "uploadForm"; } @RequestMapping(method = RequestMethod.POST, value = "/n1ql") public String n1qlQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchN1QLFiles(query); model.addAttribute("files", files); return "uploadForm"; } |
그리고 이것이 Couchbase와 Spring Boot로 파일을 저장, 색인 및 검색하는 데 필요한 대략적인 전부입니다. 이 앱은 간단한 앱이며 ExifTool에서 추출한 필드를 노출하는 적절한 검색 양식부터 시작하여 개선할 수 있는 다른 많은 것들이 있습니다. 여러 파일 업로드와 드래그 앤 드롭이 추가되면 좋을 것 같습니다. 또 어떤 개선이 필요하신가요? 아래 댓글로 알려주세요!