이 블로그는 원래 세실 르 파페의 개인 블로그에 게시되었습니다. 블로그 게시물 원본을 보려면 여기.
내 이전 게시물에서 아파치 케미스트리 서버 위에 Couchbase를 메타데이터 저장소로 사용하여 유연한 콘텐츠 관리 서비스를 설정하는 방법에 대해 설명한 적이 있습니다. 블롭 자체(pdf, pptx, docx 등)는 별도의 파일 시스템이나 블롭 스토어에 저장됩니다. 오늘은 사용자 정의 청크 관리자를 사용하여 Couchbase를 사용하여 블롭 자체를 저장하는 방법을 보여드리고자 합니다. 문서의 메타데이터(생성 날짜, 작성자, 이름 등)뿐만 아니라 블롭 자체도 저장하는 것입니다.
이 새로운 아키텍처의 목적은 다양한 시스템(및 지불해야 하는 라이선스)의 수를 줄이고 Couchbase에서 제공하는 복제 기능의 이점을 직접 활용하는 것입니다.
먼저, Couchbase는 블롭 저장소가 아니라는 점을 기억하세요. 이것은 메모리 기반 문서 저장소이며, 빠른 쿼리를 위해 대부분의 데이터가 RAM에 저장되도록 애드혹 캐시 관리가 조정되어 있습니다. 또한 데이터는 클러스터 내부의 노드(복제가 활성화된 경우) 간에 복제되며, XDCR을 사용하는 경우 클러스터 외부의 노드(옵션)에도 복제됩니다. 그렇기 때문에 카우치베이스에 저장된 데이터는 20MB를 초과할 수 없습니다. 이것은 엄격한 제한이며, 실제로 1MB는 이미 저장하기에 큰 문서입니다.
그렇다면 중요한 것은 어떻게 하면 Couchbase에 대용량 바이너리 데이터를 저장할 수 있을까요? 간단한 대답: 청크하세요!
이제 새로운 아키텍처는 다음과 같습니다:
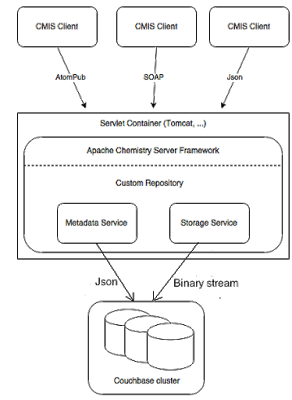
이제 카우치베이스에 2개의 버킷이 있습니다:
- cmismeta 메타데이터 저장에 사용
- cmisstore 블롭 저장에 사용
폴더가 생성되면 당연히 폴더는 어떤 블롭과도 연결되지 않기 때문에 버킷 씨미스메타만 새 항목으로 수정됩니다. 폴더는 단순히 사용자가 문서를 정리하고 폴더 트리에서 탐색하는 데 사용하는 구조일 뿐입니다. 폴더는 가상의 구조입니다. 구조의 시작점은 다음과 같이 루트 폴더입니다. 이전.
문서(예: PDF 또는 PPTX)를 폴더에 삽입하면 세 가지 일이 일어납니다:
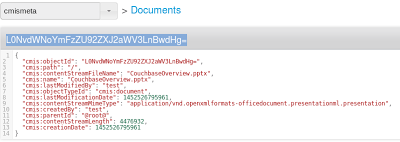
- 모든 메타데이터가 포함된 json 문서가 고유 키와 함께 cmismeta 버킷에 삽입됩니다. 예를 들어 문서에 다음과 같은 키가 있다고 가정해 보겠습니다. L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=.
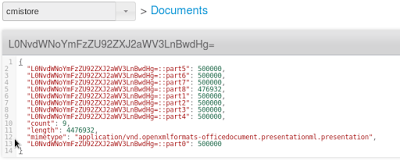
- 동일한 키를 가진 새 json 문서가 cmisstore 버킷에 생성됩니다. 이 문서에는 청크 수, 각 청크의 최대 크기(더 작을 수 있는 마지막 청크를 제외한 모든 청크에 대해 동일) 및 애플리케이션 마임 유형이 포함되어 있습니다.
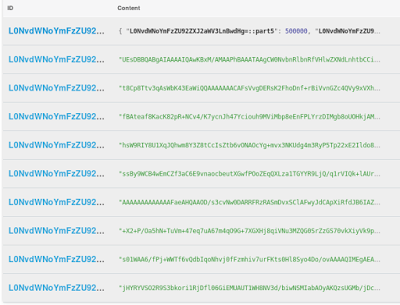
- 문서에 첨부된 블롭은 바이너리 조각으로 청크됩니다(크기는 프로젝트 속성에서 설정할 수 있는 매개변수에 따라 달라집니다). 기본적으로 청크의 크기는 500KB입니다. 각 청크는 cmisstore 버킷에 바이너리 문서로 저장되며 동일한 키 "L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg="를 접두사로, 접미사 "::partxxx"를 추가합니다. 여기서 xxx는 청크의 번호(0, 1, 2, ...)입니다.
예를 들어 크기가 4476932바이트인 CouchbaseOverview.pptx라는 pptx를 Couchbase에 삽입하면 다음과 같은 결과가 표시됩니다:
- 버킷 cmismeta에서 다음과 같은 json 문서가 있습니다. L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
- 버킷 cmisstore에서 json 문서라고도 하는 L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
-
바이너리 데이터를 포함하는 9개의 청크와 호출되는 L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part0, L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part1, ... , L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part8
CouchbaseStorageService는 로컬 스토리지 또는 S3 스토리지에 이미 사용된 StorageService 인터페이스를 구현하는 클래스입니다. 내 이전 블로그. 첫 번째 차이점은 많은 리소스(RAM, CPU, 네트워크 등)를 절약하기 위해 하나의 Couchbase 환경만 인스턴스화해야 하므로 메타데이터서비스에 사용된 것과 동일한 CouchbaseCluster 인스턴스를 재사용한다는 점입니다.
이제 writeContent 메서드 자체를 살펴보겠습니다:
*/
public void writeContent(String dataId, 콘텐츠스트림 콘텐츠 스트림)
JsonDocument jsondoc = JsonDocument.create(dataId, doc);
이제 Couchbase에서 파일을 검색하려면 어떻게 해야 할까요? 주요 아이디어는 각 부분을 가져와서 잘라낸 순서대로 서로 연결하고 바이트 배열을 스트림으로 보내는 것입니다. 이를 수행하는 방법은 여러 가지가 있을 수 있지만, 저는 각 바이트를 쓰는 단일 바이트 배열을 사용하여 간단한 방법을 구현했습니다.
던지기 StorageException {
JsonDocument doc = 버킷.get(dataId);
JsonObject json = doc.content();
정수 nbparts = json.getInt("count");
정수 길이 = json.getInt("길이");
버킷.get(dataId + PART_SUFFIX + i,BinaryDocument.클래스);
마지막으로 Apache Chemistry에서 제공하는 워크벤치 도구에서 어떤 일이 일어나는지 살펴볼까요? 루트 폴더에서 문서를 볼 수 있고 더블 클릭하면 콘텐츠가 Couchbase에서 스트리밍되어 마임 유형에 따라 연결된 뷰어(여기서는 파워포인트)에 표시됩니다.
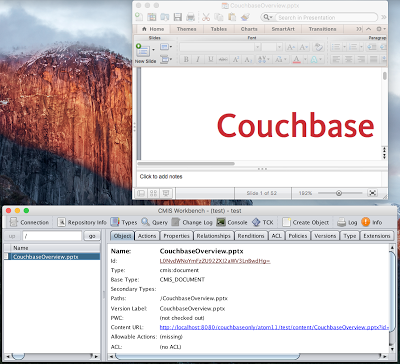
더블 클릭 후 워크벤치 및 파워포인트에서 문서 열기
동영상 형식에도 적용될 수 있을지 궁금한 훌륭한 기사입니다.