여러분 반가운 소식입니다, Spring 데이터 카우치베이스 2 가 지난 주에 출시되었으며 이제 멋진 Spring Initializr에서 사용할 수 있습니다. 이 멋진 웹사이트를 통해 Spring/Couchbase 프로젝트를 매우 빠르게 시작할 수 있습니다. 프로젝트에 원하는 종속성을 선택하고 프로젝트 생성 버튼을 누르기만 하면 프로젝트를 가져올 준비가 된 아카이브가 생성됩니다. 이 마법사는 스프링 도구 제품군.
1/ 이동 https://start.spring.io/
2/ 현재는 Spring Boot 1.4.0-SNAPSHOT에서만 사용할 수 있으므로 올바른 SpringBoot 버전을 선택하여 시작해야 합니다.
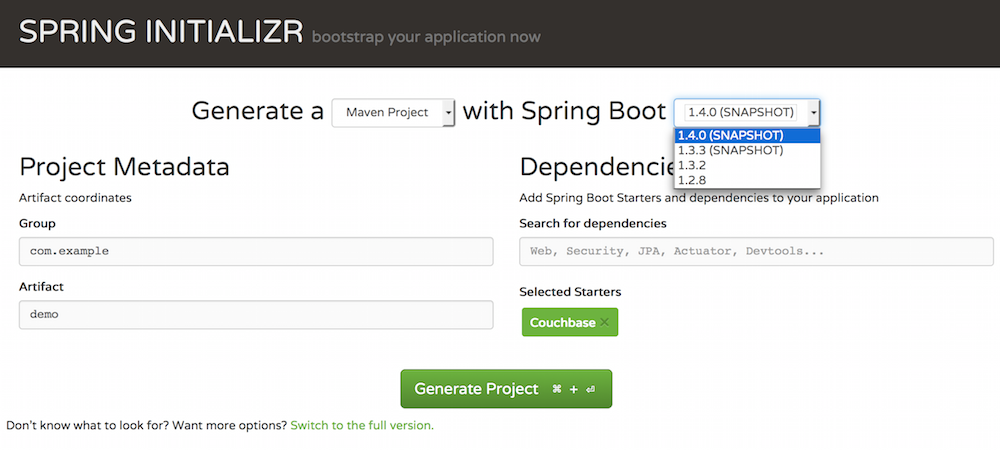
3/ 카우치베이스 선택
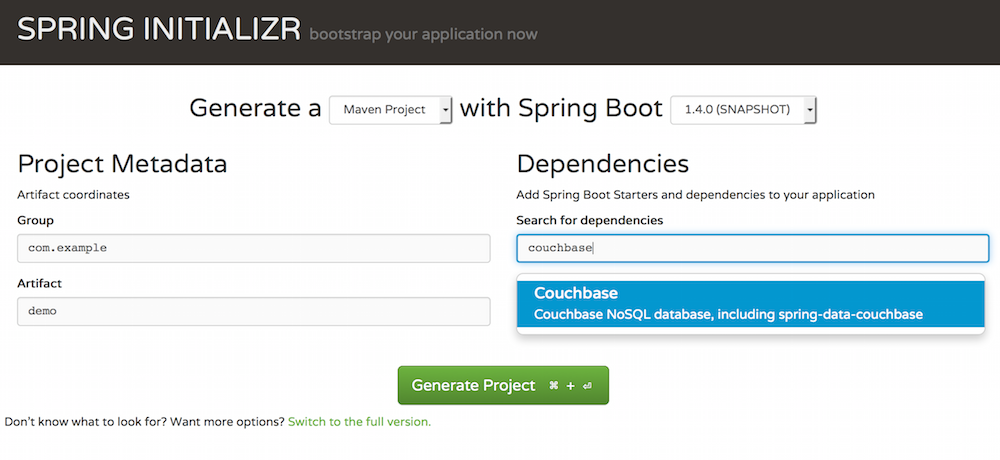
4/ 프로젝트에 필요한 다른 종속성을 추가하세요.
5/ 프로젝트 생성
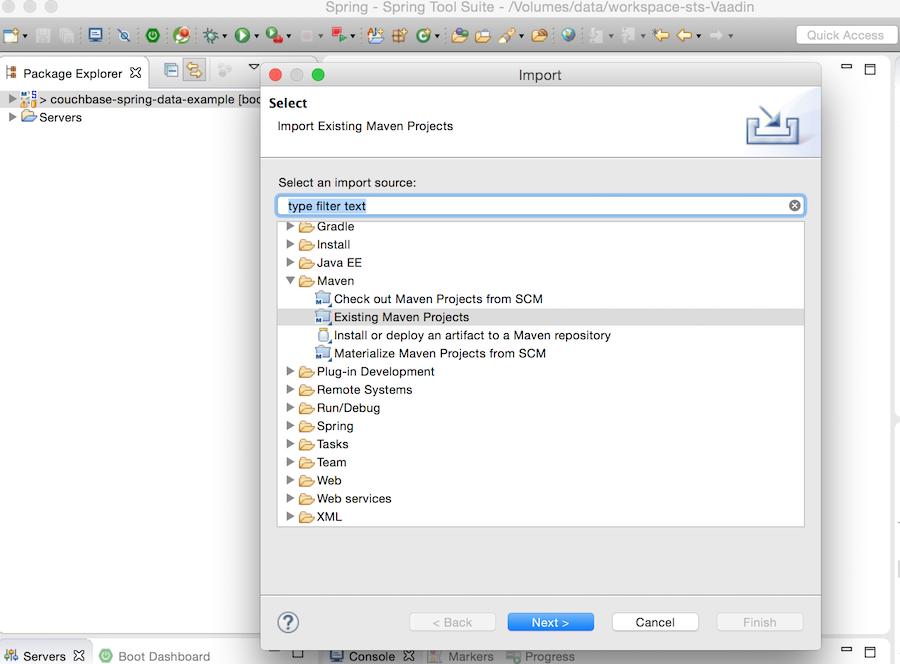
이제 원하는 편집기에서 아카이브를 가져올 준비가 되었습니다. 저는 Spring 작업을 할 때 기본 도구 세트를 사용하는 편입니다. 기본적으로 올바른 플러그인 세트로 사전 구성된 Eclipse를 사용하죠.
6/ 생성 마법사에서 Maven을 계속 사용하므로 기존 Maven 프로젝트로 간단히 가져올 수 있습니다.
기본 구성을 활성화하려면 application.properties 파일에 다음을 추가해야 합니다:
|
1 2 |
spring.data.couchbase.bucket.name=default |
또는 AbstractCouchbaseConfiguration을 확장하는 @Configuration Bean을 만들 수도 있습니다. 이제 시작할 준비가 되었습니다. 다음은 스프링 부트 카우치베이스 자동 구성이 제공하는 기능에 대한 간략한 목록입니다.
속성
여러 속성을 정의하여 Couchbase에 대한 액세스를 구성할 수 있으며, 기본값은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
# the name of the bucket to connect to, it's mandatory to enable the auto-config spring.data.couchbase.bucket.name=default # the password of the bucket to connect to spring.data.couchbase.bucket.password= # adress of the Couchbase Cluster nodes spring.data.couchbase.bootstrap-hosts=127.0.0.1 # Automatic index creation based only annotations (@ViewIndexed, @N1qlPrimaryIndexed, @N1qlSecondaryIndexed) spring.data.couchbase.auto-index=false # Default level of consistency (read-your-own-writes|eventually-consistent|strongly-consistent|update-after) spring.data.couchbase.consistency=read-your-own-writes |
- 읽기-자신의-쓰기는 stale=false이고 ScanConsistency=statement_plus입니다.
- 강력하게 일관성은 stale=false이고 ScanConsistency=request_plus입니다.
- 업데이트 후가 오래된 경우 업데이트 후 및 스캔 일관성=not_bounded입니다.
- 결국-일관성은 stale=true이고 ScanConsistency=not_bounded입니다.
부실 수준
stale=true로 설정하면 뷰가 오래되어도 Couchbase는 뷰를 새로 고치지 않습니다. 이렇게 하면 쿼리 지연 시간이 개선됩니다. stale=update_after를 설정하면 오래된 결과가 반환된 후 Couchbase가 뷰를 업데이트합니다. stale=false로 설정하면 Couchbase는 뷰를 새로 고치고 가장 최근에 업데이트된 결과를 반환합니다.
스캔 일관성 수준
not_bounded
이것이 기본값입니다(단일 문 요청의 경우). 인덱스 스캔에 타임스탬프 벡터가 사용되지 않습니다. 이 모드는 벡터를 구하는 데 드는 비용을 피하고 인덱스가 벡터를 따라잡을 때까지 기다릴 필요도 없기 때문에 가장 빠른 모드이기도 합니다.
요청_플러스
이는 요청당 강력한 일관성을 구현합니다. 요청을 처리하기 전에 현재 벡터를 얻습니다. 이 벡터는 요청의 문에 대한 하한으로 사용됩니다. 요청에 DML 문이 있는 경우 요청 내에 RYOW도 적용됩니다.
statement_plus
이는 문마다 강력한 일관성을 구현합니다. 각 문을 처리하기 전에 현재 벡터를 구하여 해당 문에 대한 하한으로 사용합니다.
색인 주석
다음은 자동 리포지토리의 예입니다. 인덱스 생성. 리포지토리 빈이 초기화되면 어노테이션에 정의된 인덱스가 존재하는지 확인하고 없는 경우 생성합니다.
|
1 2 3 4 5 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "customer") @N1qlSecondaryIndexed(indexName = "customerSecondaryIndex") public interface CustomerRepository extends CouchbasePagingAndSortingRepository<Customer, String> {} |
인덱스는 개발용으로만 사용해야 합니다. 프로덕션 환경에서는 자동 인덱스 생성을 끄고 배포 프로세스 중에 올바른 노드에 올바른 인덱스를 생성하는 것이 좋습니다.
인덱싱된 보기
이 주석 를 사용하면 디자인 문서의 이름과 보기 이름은 물론 사용자 지정 맵과 축소 기능을 정의할 수 있습니다.
N1qlPrimaryIndexed
이 주석 는 현재 리포지토리에 연결된 버킷에 N1QL 기본 인덱스가 있는지 확인합니다.
N1qlSecondaryIndexed
이 주석 는 엔티티 유형에 보조 인덱스가 존재하는지 확인합니다.
사용 가능한 원두
자동 구성을 활성화한 경우 여러 Bean에 액세스할 수 있으며, 가장 유용한 Bean 목록은 다음과 같습니다:
- 카우치베이스템플릿 카우치베이스템플릿
- 로우레벨 Spring 데이터 카우치베이스 API에 대한 액세스를 제공합니다.
- 카우치베이스 이벤트 리스너 유효성 검사 이벤트 리스너 유효성 검사
- javax.validation 종속 엔티티 유효성 검사기. Spring 컴포넌트로 등록되면 엔티티가 데이터베이스에 저장되기 전에 자동으로 호출됩니다.
- 맞춤전환 맞춤전환
- 사용자 지정 JSON 유형 변환을 캡처하는 데 사용됩니다.
- 버킷 카우치베이스클라이언트
- 구성된 버킷에 직접 액세스
결론
이제 스프링 부트 스타터 데이터 카우치베이스로 새 프로젝트를 시작할 때 사용할 수 있는 기능에 대한 좋은 개요를 얻으셨을 것입니다. Spring 데이터 카우치베이스 2에 대한 자세한 내용은 다음을 참조하세요. 문서 를 방문하거나 이 블로그를 정기적으로 확인하여 더 많은 Spring/Couchbase 관련 정보를 확인하세요.