카우치베이스 자율 운영자 는 오픈 소스 Kubernetes 및 Red Hat Openshift와 클라우드 네이티브 통합을 제공하는 Kubernetes 운영자입니다. 사용자는 Kubernetes의 선언적 기능을 사용하여 Couchbase 서버 클러스터를 정의하고 해당 클러스터의 속성을 관리할 수 있습니다. 이 선언적 기능은 환경 정의를 소스 제어에 저장할 수 있기 때문에 유용합니다.
운영자의 목표는 하나 이상의 Couchbase Server 배포를 완벽하게 관리하는 것입니다. 클러스터 수명 주기(프로비저닝, 확장, 업그레이드, 자동 복구) 및 구성(영구 볼륨, 서버 그룹, XDCR, TLS, RBAC, 백업/복원)을 관리합니다. 운영자는 대규모 Couchbase 환경을 관리하는 데 강력한 도구이며, 이를 위해 카우치베이스 운영자 문서.
저장 및 복원: 관리되지 않는 토폴로지를 마이그레이션하는 방법
우리는 저장 및 복원 기능을 추가했습니다. 이 기능을 사용하면 사용자가 비관리형 카우치베이스 클러스터로 전환하여 관리 클러스터. 이 기능을 사용하면 관리되지 않는 데이터 토폴로지로 Autonomous 운영자가 생성한 Couchbase 클러스터를 프로브하고 해당 Couchbase 클러스터의 현재 데이터 토폴로지와 일치하는 데이터 토폴로지 YAML 파일을 검색할 수 있습니다. 사용자는 이 배포 YAML 파일을 가져와서 기존 클러스터에 적용하여 토폴로지를 잠그거나 새 클러스터 환경에 적용하여 환경을 마이그레이션할 수 있습니다.
이 기능의 사용 사례는 무궁무진합니다! 하지만 이 글에서는 신속하고 민첩한 R/D 환경에서 수동으로 관리되는 데이터 토폴로지에서 보다 안정적인 프로덕션 환경으로 환경을 마이그레이션하는 데 초점을 맞추고자 합니다.
Couchbase를 처음 사용하든 노련한 전문가든 상관없이 새로운 저장 및 복원 기능을 사용하면 CI/CD 파이프라인이 크게 간소화됩니다. 관리되지 않는 클러스터에서 관리되는 클러스터로 쉽게 전환할 수 있으므로 파이프라인의 환경 제어를 유지하면서 빠른 속도로 개발을 계속할 수 있습니다.
Couchbase 클러스터 스키마 마이그레이션 데모 보기
이 기능을 시연하려면 먼저 관리되지 않는 상태로 Kubernetes에서 Couchbase 서버 클러스터를 만들어야 합니다. 이를 위해 unmanaged.yaml file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: v1 종류: 비밀 메타데이터: 이름: cb-example-auth 유형: 불투명 데이터: 사용자 이름: QWRtaW5pc3RyYXRvcg== 비밀번호: cGFzc3dvcmQ= --- apiVersion: couchbase.com/v2 종류: 카우치베이스클러스터 메타데이터: 이름: cb-example-unmanaged 사양: 이미지: 카우치베이스/서버:7.0.3 보안: 관리자 비밀: cb-example-auth rbac: 관리: false 버킷: 관리: false 서버: - 크기: 3 이름모든 서비스 서비스: - 데이터 - 색인 - 쿼리 - 검색 - 이벤트 - 분석 |
이 클러스터를 만들려면 다음 명령을 사용합니다: 이렇게 하면 모든 서비스가 포함된 간단한 비관리형 클러스터가 생성되지만 버킷 및 RBAC 관리는 해제됩니다. 또한 다음과 같은 사용자 이름으로 클러스터에 액세스할 수 있는 비밀도 포함됩니다. 관리자 의 비밀번호와 비밀번호.
|
1 |
kubectl create -f ./관리되지 않음.yaml |
이 클러스터에 액세스하기 위해 포트 8091을 포트 포워딩하여 빠른 개발 액세스를 위해 Couchbase 서버 관리자 UI에 액세스할 수 있도록 합니다. 관리자 포트에 정기적으로 액세스하려면 로드 밸런서 포트 설정에 대한 문서를 참조하세요.
이 포트 포워딩을 만들려면 다음 명령을 사용합니다:
|
1 |
kubectl 포트-앞으로 cb-예제-0000 8091 |
이제 관리자 자격 증명을 사용하여 8091 포트의 웹 UI에 액세스한 다음 버킷, 범위 및 컬렉션을 만들 수 있습니다. 이 예제에서는 블로그 앱 버킷, 범위는 en-US 및 해당 범위 내의 일부 컬렉션.
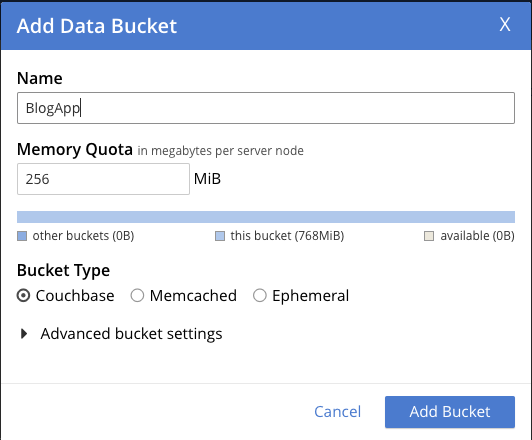
다음으로, 다음에 대한 범위를 추가합니다. en-US.
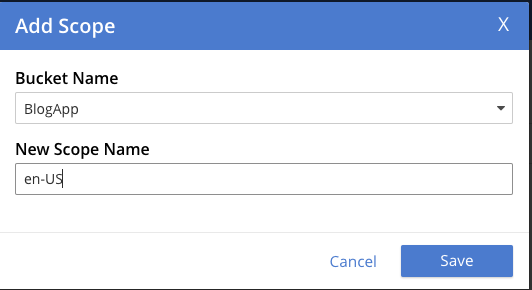
마지막으로, 마지막으로 블로그 컬렉션.
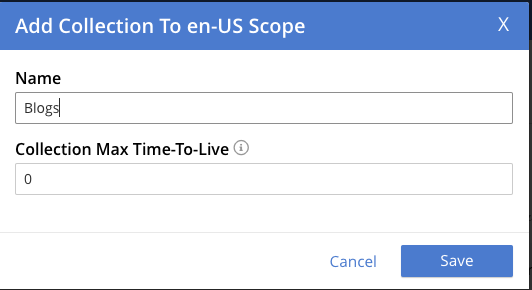
이제 다음과 같은 트리 구조가 생겼습니다:
|
1 2 3 4 |
버킷: 블로그 앱 범위: en-US 컬렉션: 블로그 컬렉션: 레시피 |
데이터 토폴로지가 완성되면, 데이터 토폴로지를 생성하기 위해 cao 명령으로 바이너리를 입력합니다:
|
1 |
./cao 저장 --카우치베이스-클러스터 cb-예제-관리되지 않음 --파일 이름 ./토폴로지.yaml |
이렇게 하면 topology.yaml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
--- apiVersion: couchbase.com/v2 종류: 카우치베이스버킷 메타데이터: 생성 타임스탬프: null 이름: bucket-629f6ab0-d3ad-442e-b8e8-33e71412fae8 사양: 압축모드패시브 충돌 해결: seqno 퇴거 정책: valueOnly ioPriority낮음 maxTTL: 0s 메모리 쿼터: 256Mi 최소 내구성없음 이름: 블로그앱 복제본: 1 범위: 관리true 리소스: - 종류: 카우치베이스 범위 이름: scope-48d41118-fafd-48fa-a128-a539ffdb5efa - 종류: 카우치베이스 범위 이름: scope-9807f3f5-f798-43f6-bab0-32c44fada0ef --- apiVersion: couchbase.com/v2 종류: 카우치베이스 범위 메타데이터: 생성 타임스탬프: null 이름: scope-48d41118-fafd-48fa-a128-a539ffdb5efa 사양: 컬렉션: 관리true 리소스: - 종류: 카우치베이스 컬렉션 이름: collection-80bf5988-85ed-47b0-986b-44d52dca3389 - 종류: 카우치베이스 컬렉션 이름: collection-6da06d0d-c07c-4847-b2b6-0c46f5fed67a 이름: en-US --- apiVersion: couchbase.com/v2 종류: 카우치베이스 컬렉션 메타데이터: 생성 타임스탬프: null 이름: collection-80bf5988-85ed-47b0-986b-44d52dca3389 사양: maxTTL: 0s 이름: 레시피 --- apiVersion: couchbase.com/v2 종류: 카우치베이스 컬렉션 메타데이터: 생성 타임스탬프: null 이름: collection-6da06d0d-c07c-4847-b2b6-0c46f5fed67a 사양: maxTTL: 0s 이름: 블로그 --- apiVersion: couchbase.com/v2 종류: 카우치베이스 범위 메타데이터: 생성 타임스탬프: null 이름: scope-9807f3f5-f798-43f6-bab0-32c44fada0ef 사양: 컬렉션: 관리true 보존 기본 컬렉션true 기본 범위true |
클러스터 토폴로지 복제
이제 토폴로지 파일을 사용하여 다른 클러스터로 복원하여 구조를 새 환경에 복제할 수 있습니다. 이렇게 하려면 managed.yaml 이 콘텐츠가 포함되어 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
apiVersion: couchbase.com/v2 종류: 카우치베이스클러스터 메타데이터: 이름: cb-example-managed 사양: 이미지: 카우치베이스/서버:7.0.3 보안: 관리자 비밀: cb-example-auth rbac: 관리: false 버킷: 관리true 서버: - 크기: 3 이름모든 서비스 서비스: - 데이터 - 색인 - 쿼리 - 검색 - 이벤트 - 분석 |
다음으로 다음을 사용하여 관리되는 클러스터를 만듭니다: 이것은 우리의 unmanaged.yaml대신 버킷은 관리 그리고 관리되지 않는 클러스터의 비밀을 다시 사용했습니다.
|
1 |
kubectl create -f 관리.yaml |
관리형 클러스터로 토폴로지 복원하기
해당 클러스터가 스핀업된 후에는 cao 바이너리를 사용하여 새로 생성된 관리형 클러스터에 토폴로지 YAML을 복원합니다:
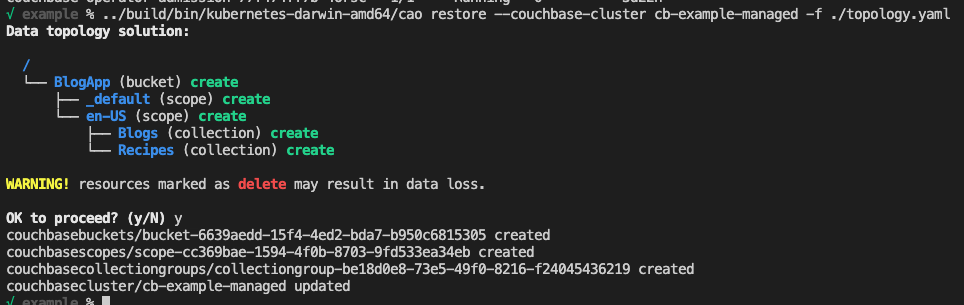
마지막으로, 검증을 위해 새 관리형 클러스터에 대한 간단한 포트 포워드를 만들고 데이터 토폴로지를 확인합니다. 다음 명령을 사용하여 포트 포워드를 만들고 브라우저를 다음 주소로 엽니다. http://127.0.0.1:8091.
|
1 |
kubectl 포트-앞으로 cb-예제-관리-0000 8091 |
적절한 데이터 토폴로지가 표시되어야 합니다.
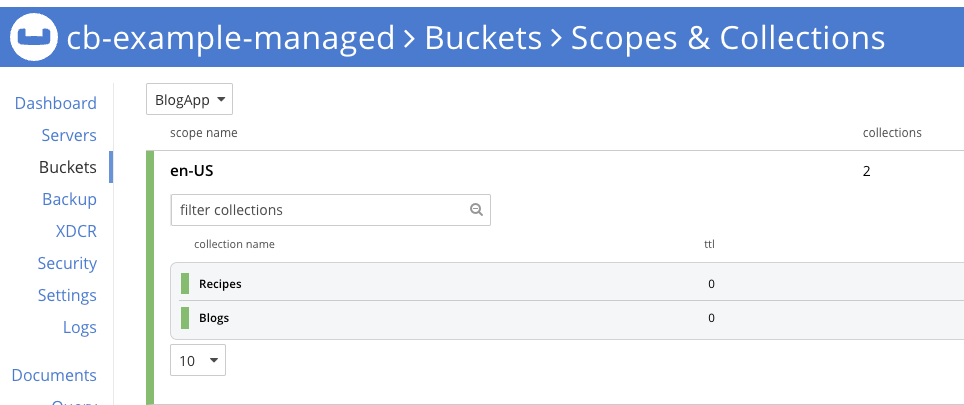
이제 데이터 토폴로지를 마이그레이션했으므로 한 환경에서 다른 환경으로 데이터를 마이그레이션할 수 있습니다. 다음과 같은 방법을 사용하는 것이 좋습니다. 데이터 센터 간 복제(XDCR) 을 사용하여 한 클러스터에서 다른 클러스터로 데이터를 쉽게 이동할 수 있습니다. XDCR 설정에 대한 자세한 내용은 다음에서 확인할 수 있습니다. 카우치베이스 운영자 문서.
다음 단계 및 리소스
몇 가지 유의해야 할 사항이 있습니다:
-
- 저장은 RBAC 역할/그룹을 저장하지 않습니다. 직접 마이그레이션해야 합니다.
- 그리고 cao 도구는 대상 클러스터에 대한 모든 변경 사항을 알려줍니다. 다음과 같이 표시된 모든 항목은 삭제 가 삭제되어 데이터가 손실될 수 있습니다.
이 게시물에서는 다음 주제를 다루었습니다: