El operador autónomo Couchbase es un operador de Kubernetes que proporciona integración nativa en la nube con Kubernetes de código abierto y Red Hat Openshift. Permite a un usuario utilizar la funcionalidad declarativa de Kubernetes para definir lo que será el clúster de Couchbase Server y gestionar los atributos de ese clúster. Esta funcionalidad declarativa es útil ya que permite almacenar las definiciones del entorno en el control de código fuente.
El objetivo del operador es gestionar completamente uno o más despliegues de Couchbase Server. Gestiona el ciclo de vida del cluster (aprovisionamiento, escalado, actualización, auto-recuperación) y la configuración (volúmenes persistentes, grupos de servidores, XDCR, TLS, RBAC, backup/restore). El operador es una potente herramienta en la gestión de un entorno Couchbase a gran escala y es muy recomendable que leas el documento Documentación del operador de Couchbase.
Guardar y restaurar: Cómo migrar una topología no gestionada
Añadimos el Guardar y Restaurar Característica en Couchbase Autonomous Operator v2.3. Esta característica permite a los usuarios migrar un no gestionado Couchbase Cluster y convertirlo en un gestionado cluster. Esta funcionalidad permite sondear un cluster Couchbase creado por el operador autónomo con topología de datos no gestionada y recuperar un archivo YAML de topología de datos que coincida con la topología de datos actual de ese cluster Couchbase. Un usuario puede tomar este archivo YAML de despliegue y aplicarlo al cluster existente para bloquear la topología o aplicarlo a un nuevo entorno de cluster para migrar el entorno.
Los casos de uso de esta función son numerosos. Aun así, en el que nos centraremos en este post es la migración de un entorno desde una topología de datos gestionada manualmente en un entorno R/D rápido/ágil a un entorno de producción más estable.
Tanto si eres nuevo en Couchbase como un profesional experimentado, el nuevo Guardar y restaurar de Couchbase Autonomous Operator simplifica significativamente tu proceso CI/CD. Ser capaz de pasar fácilmente de un clúster no gestionado a un clúster gestionado te permite continuar con el desarrollo a un ritmo rápido mientras mantienes el control de los entornos a lo largo del proceso.
Demostración de la migración del esquema de un clúster Couchbase
Para demostrar esta funcionalidad, primero tenemos que crear un clúster de servidores Couchbase en Kubernetes en un estado no gestionado. Usaremos este unmanaged.yaml file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: v1 kind: Secret metadata: name: cb-example-auth type: Opaque data: username: QWRtaW5pc3RyYXRvcg== password: cGFzc3dvcmQ= --- apiVersion: couchbase.com/v2 kind: CouchbaseCluster metadata: name: cb-example-unmanaged spec: image: couchbase/server:7.0.3 security: adminSecret: cb-example-auth rbac: managed: false buckets: managed: false servers: - size: 3 name: all_services services: - data - index - query - search - eventing - analytics |
Para crear este clúster, utilice el comando: Esto crea un cluster simple no gestionado con todos los servicios, pero desactiva la gestión de buckets y RBAC. También incluye un secreto para acceder al cluster con un nombre de usuario de Administrador y una contraseña de contraseña.
|
1 |
kubectl create -f ./unmanaged.yaml |
Para acceder a este cluster, port-forward el puerto 8091 para que podamos acceder al servidor Couchbase Admin UI sólo para el acceso rápido de desarrollo. Si quieres acceder al puerto de administración con regularidad, consulta la documentación sobre la configuración de un puerto balanceador de carga.
Para crear este reenvío de puertos, utilice el comando:
|
1 |
kubectl port-forward cb-example-0000 8091 |
Ahora podemos acceder a la interfaz web en el puerto 8091 utilizando las credenciales de administrador y, a continuación, crear algunos buckets, ámbitos y colecciones. En este ejemplo, creamos un BlogApp cubo, con un margen para es-US y algunas colecciones dentro de ese ámbito.
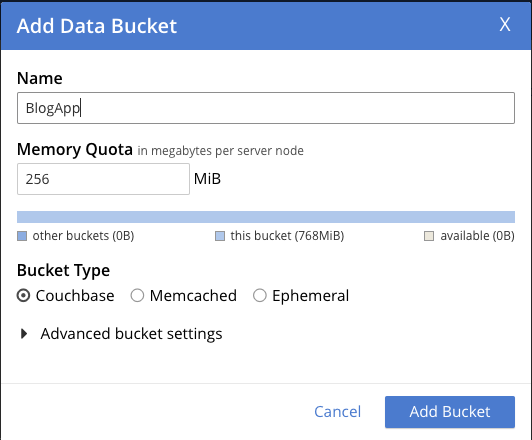
A continuación, añadimos el ámbito para es-US.
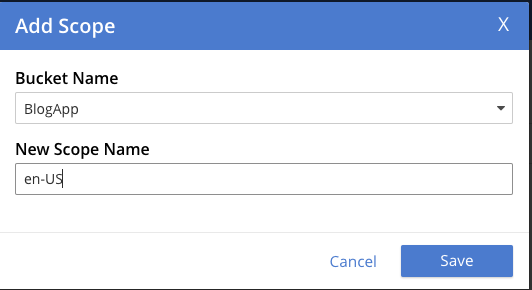
Por último, añadimos el Blogs colecciones.
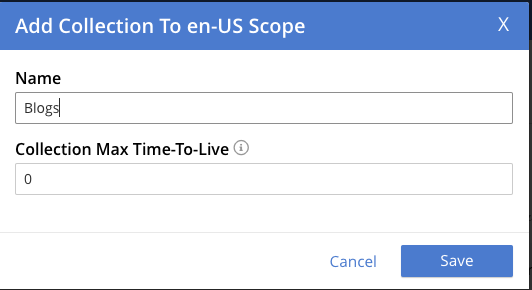
Ahora tenemos una estructura de árbol con este aspecto:
|
1 2 3 4 |
Bucket: BlogApp Scope: en-US Collection: Blogs Collection: Recipe |
Una vez que tenemos nuestra topología de datos, podemos generar un archivo YAML utilizando la función cao binario con el comando:
|
1 |
./cao save --couchbase-cluster cb-example-unmanaged --filename ./topology.yaml |
Esto mostrará nuestro topology.yaml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
--- apiVersion: couchbase.com/v2 kind: CouchbaseBucket metadata: creationTimestamp: null name: bucket-629f6ab0-d3ad-442e-b8e8-33e71412fae8 spec: compressionMode: passive conflictResolution: seqno evictionPolicy: valueOnly ioPriority: low maxTTL: 0s memoryQuota: 256Mi minimumDurability: none name: BlogApp replicas: 1 scopes: managed: true resources: - kind: CouchbaseScope name: scope-48d41118-fafd-48fa-a128-a539ffdb5efa - kind: CouchbaseScope name: scope-9807f3f5-f798-43f6-bab0-32c44fada0ef --- apiVersion: couchbase.com/v2 kind: CouchbaseScope metadata: creationTimestamp: null name: scope-48d41118-fafd-48fa-a128-a539ffdb5efa spec: collections: managed: true resources: - kind: CouchbaseCollection name: collection-80bf5988-85ed-47b0-986b-44d52dca3389 - kind: CouchbaseCollection name: collection-6da06d0d-c07c-4847-b2b6-0c46f5fed67a name: en-US --- apiVersion: couchbase.com/v2 kind: CouchbaseCollection metadata: creationTimestamp: null name: collection-80bf5988-85ed-47b0-986b-44d52dca3389 spec: maxTTL: 0s name: Recipes --- apiVersion: couchbase.com/v2 kind: CouchbaseCollection metadata: creationTimestamp: null name: collection-6da06d0d-c07c-4847-b2b6-0c46f5fed67a spec: maxTTL: 0s name: Blogs --- apiVersion: couchbase.com/v2 kind: CouchbaseScope metadata: creationTimestamp: null name: scope-9807f3f5-f798-43f6-bab0-32c44fada0ef spec: collections: managed: true preserveDefaultCollection: true defaultScope: true |
Clonación de una topología de clúster
Con el fichero de topología podemos ahora restaurarlo en otro cluster, clonando la estructura en un nuevo entorno. Para ello, cree un archivo managed.yaml con este contenido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
apiVersion: couchbase.com/v2 kind: CouchbaseCluster metadata: name: cb-example-managed spec: image: couchbase/server:7.0.3 security: adminSecret: cb-example-auth rbac: managed: false buckets: managed: true servers: - size: 3 name: all_services services: - data - index - query - search - eventing - analytics |
A continuación, creamos el clúster gestionado mediante: Esto es similar a nuestro unmanaged.yamlpero, en su lugar, los cubos son gestionado y reutilizamos nuestro secreto del clúster no gestionado.
|
1 |
kubectl create -f managed.yaml |
Restauración de la topología en el clúster gestionado
Una vez que el clúster se haya puesto en marcha, puede utilizar la función cao binario para restaurar la topología YAML en el clúster gestionado recién creado:
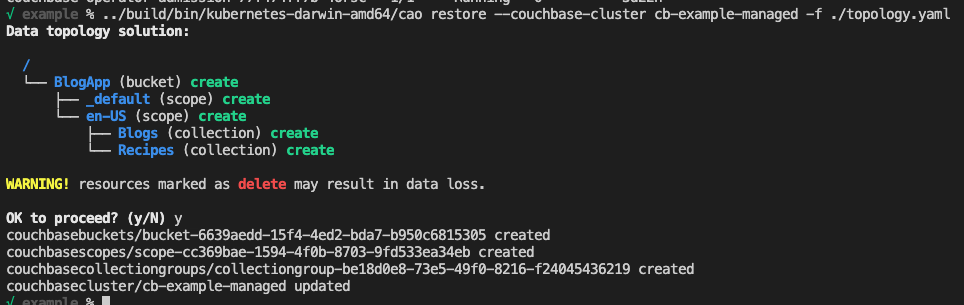
Por último, para verificar, crearemos un simple port-forward al nuevo cluster gestionado y verificaremos la topología de datos. Utilice el siguiente comando para crear el port-forward y abra su navegador a https://127.0.0.1:8091.
|
1 |
kubectl port-forward cb-example-managed-0000 8091 |
Debería aparecer la topología de datos adecuada.
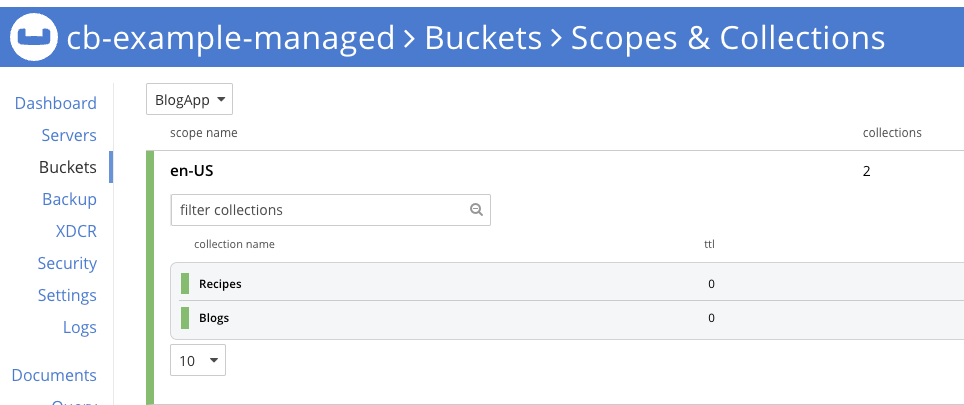
Ahora que hemos migrado la topología de datos, es posible que queramos migrar los datos de un entorno a otro. Recomiendo utilizar Replicación entre centros de datos (XDCR) para facilitar el movimiento de datos de un cluster a otro. Puede encontrar más información sobre la configuración de XDCR en la página Documentación del operador Couchbase.
Próximos pasos y recursos
Algunas cosas a tener en cuenta:
-
- Guardar no guarda los roles/grupos RBAC. Tendrá que migrarlos por su cuenta.
- En cao le informará de todos los cambios que debe realizar en el clúster de destino. Cualquier elemento marcado como borrar se borrará, lo que puede provocar la pérdida de datos.
En este post se trataron los siguientes temas: