이전 블로그에서 다음과 같은 접근 방식에 대한 이해를 높였습니다. 실시간 관찰 가능성 (RTO)는 일반적으로 분산 시스템 문제 해결에 도움이 되며, 왜 우리가 오픈트레이싱 를 기초 및 공개 API로 사용하고 있습니다. 아직 읽어보지 않으셨다면 다음 블로그에서 확인하세요. 여기 그리고 여기.
이 블로그에서는 RTO가 어떻게 작동하는지 알아봅니다. Java SDK 그리고 지금 당장 이를 활용해 이익을 얻을 수 있는 방법을 알아보세요.
시작하기
Java SDK 2.6.0(또는 그 이상) 버전이 출시되는 즉시 설명된 대로 일반적인 방법을 통해 다운로드할 수 있습니다. 여기. 이 버전은 현재 프리뷰 릴리스 상태이므로 자체 maven 리포지토리에서 액세스해야 합니다. 메이븐을 통해 pom.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<dependencies> <dependency> <groupId>com.couchbase.client</groupId> <artifactId>자바 클라이언트</artifactId> <version>2.6.0-dp1</version> </dependency> </dependencies> <repositories> <repository> <id>cb-pre</id> <name>카우치베이스 프리리스 리포지토리</name> <url>http://files.couchbase.com/maven2</url> |
눈에 띄는 유일한 차이점은 다음과 같은 새로운 종속성입니다. 오픈트레이싱 API 에 대한 자세한 내용은 잠시 후에 설명하겠습니다. 주요 릴리스가 아니므로 모든 이전 코드는 이전과 동일하게 작동하며 개선된 기능을 즉시 활용할 수 있습니다.
트레이서 자체 또는 일부 구성을 사용자 지정해야 하는 경우, 트레이서의 CouchbaseEnvironment.Builder 를 설정할 수 있습니다. 다음은 정보가 기록되는 시간 간격을 줄이기 위해 기본 추적기를 사용자 지정하는 방법에 대한 예시입니다:
|
1 2 3 4 5 6 7 |
트레이서 추적자 = 임계값 로그 추적기.create(임계값 로그 리포터.빌더() .로그 간격(10, 시간 단위.초) // 10초마다 로그 .빌드()); 카우치베이스 환경 환경 = 기본 카우치 기반 환경.빌더() .추적자(추적자) .빌드(); |
임계값 로깅 설명
임계값 로깅 추적기(기본적으로 켜져 있음)를 사용해보기 위해 설정을 약간 사용자 정의하고 임계값을 낮추어 거의 모든 요청과 응답을 처리할 수 있도록 해보겠습니다. 물론 이것은 프로덕션 환경에서는 좋은 아이디어가 아니지만 원하는 로그 출력을 빠르게 얻고 그 기능을 확인하는 데 도움이 될 것입니다.
위에 설명된 대로 다음 구성을 적용합니다:
|
1 2 3 4 5 6 |
트레이서 추적자 = 임계값 로그 추적기.create(임계값 로그 리포터.빌더() .kvThreshold(1) // 1 마이크로 .로그 간격(1, 시간 단위.초) // 매초마다 로그 .샘플 크기(정수.MAX_VALUE) .예쁜(true) // 로그에 json 출력을 예쁘게 인쇄합니다. .빌드()); |
이렇게 하면 키/값 연산에 대한 임계값을 1마이크로초로 설정하고, 발견된 연산을 매초마다 기록하고, 샘플 크기를 매우 큰 값으로 설정하여 모든 연산이 기록되도록 합니다. 기본적으로 1분마다(무언가가 발견되면) 로깅하고 가장 느린 상위 10개 연산만 샘플링합니다. 키/값 연산의 기본 임계값은 500밀리초입니다.
이러한 구성이 완료되면 몇 가지 작업을 실행할 준비가 된 것입니다. 다음 구성을 자유롭게 조정하여 서버를 가리키고 적절한 자격 증명을 적용하도록 하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// 연결 카우치베이스 환경 환경 = 기본 카우치 기반 환경.빌더() .추적자(추적자) .빌드(); 클러스터 클러스터 = 카우치베이스클러스터.create(환경, "127.0.0.1"); 버킷 버킷 = 클러스터.오픈버킷("travel-sample"); // 몇 개의 문서를 로드하고 다시 작성합니다. 에 대한(int i = 0; i < 5; i++) { JsonDocument doc = 버킷.get("airline_1" + i); 만약 (doc != null) { 버킷.업서트(doc); } } 스레드.수면(시간 단위.분.toMillis(1)); |
이 간단한 코드에서 우리는 여행 샘플 버킷에 넣고, 발견되면 다시 업서트. 이를 통해 간단한 방법으로 읽기 및 쓰기 작업을 모두 수행할 수 있습니다. 코드가 실행되면 로그에서 (유사한) 출력을 볼 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
4월 04, 2018 9:42:57 AM com.카우치베이스.클라이언트.핵심.추적.임계값 로그 리포터 로그 오버 임계값 경고: 운영 over 임계값: [ { "top" : [ { "서버_미국" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x6", "dispatch_us" : 315, "remote_address" : "127.0.0.1:11210", "total_us" : 576 }, { "서버_미국" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x5", "dispatch_us" : 319, "remote_address" : "127.0.0.1:11210", "total_us" : 599 }, { "서버_미국" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x4", "dispatch_us" : 332, "remote_address" : "127.0.0.1:11210", "total_us" : 632 }, { "서버_미국" : 11, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x3", "dispatch_us" : 392, "remote_address" : "127.0.0.1:11210", "total_us" : 762 }, { "서버_미국" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 9579, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 16533 }, { "서버_미국" : 56, "encode_us" : 12296, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "upsert:0x2", "dispatch_us" : 1280, "remote_address" : "127.0.0.1:11210", "total_us" : 20935 } ], "서비스" : "kv", "count" : 6 } ] |
임계값 로그 리포터가 활동 중입니다! 각 서비스에 대해 (오직 kv 이 워크로드에 따라) 기록된 작업의 총량을 표시합니다( 카운트)을 클릭해 지연 시간 순으로 가장 느린 작업 순위를 확인하세요. 오직 airline_10 버킷에 5개의 문서 가져오기가 있지만 변이가 한 번만 발생하는 것을 볼 수 있습니다.
특정 작업 하나를 살펴보고 각 필드에 대해 좀 더 자세히 논의해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 |
{ "서버_미국" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 1203, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 1525 } |
이를 통해 다음과 같은 사실을 알 수 있습니다:
total_us: 전체 작업을 수행하는 데 걸린 총 시간: 여기서는 약 1.5밀리초입니다.서버_미국: 서버가 수행한 작업에 23마이크로초가 걸렸다고 보고했습니다(여기에는 네트워크 시간이나 클러스터에서 픽업되기 전 버퍼에 있는 시간은 포함되지 않음).decode_us: 클라이언트가 응답을 디코딩하는 데 걸린 시간 1.2밀리초dispatch_us: 클라이언트가 요청을 보내고 응답을 받는 데 걸리는 시간은 약 1밀리초입니다.local_address: 이 작업에 사용되는 로컬 소켓입니다.원격_주소: 이 작업에 사용된 서버의 원격 소켓입니다. 영향을 받는 노드를 파악하는 데 유용합니다.operation_id: 작업 유형과 ID(이 경우 불투명 값)의 조합으로, 진단 및 문제 해결에 유용합니다.local_id.local_id: 서버 5.5 이상에서는 이 ID가 서버와 협상되며 보다 간단한 방식으로 양쪽의 로깅 정보를 상호 연관시키는 데 사용할 수 있습니다.
이 로그의 정확한 형식은 아직 유동적이며 dp1과 베타/GA 릴리스 사이에 변경될 예정입니다.
생산 요구 사항에 따라 임계값을 올바르게 설정하면 많은 노력 없이도 느린 작업을 이전보다 더 쉽게 기록하고 정확히 찾아낼 수 있음을 알 수 있습니다.
하지만 퍼즐에 빠진 한 가지 조각이 있는데, 바로 이것이 다음에서 다룰 무서운 타임아웃 예외.
타임아웃 가시성
이전에는 지정된 시간 초과가 허용하는 시간보다 작업이 오래 걸리는 경우 타임아웃 예외 가 던져집니다. 일반적으로 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 |
예외 in 스레드 "main" 자바.lang.런타임 예외: 자바.활용.동시.타임아웃 예외 에서 com.카우치베이스.클라이언트.자바.활용.차단.블록포싱(차단.자바:77) 에서 com.카우치베이스.클라이언트.자바.카우치베이스버킷.get(카우치베이스버킷.자바:131) 에서 메인.메인(메인.자바:34) 원인 by: 자바.활용.동시.타임아웃 예외 ... 3 더 보기 |
이 스택 추적을 보면 몇 가지를 유추할 수 있는데, 예를 들어 시간 초과된 작업이 GetRequest. 런타임에 더 많은 정보가 필요한 경우, 기존에는 컨텍스트에 따라 래핑해야 했습니다. 예를 들어
|
1 2 3 4 5 6 7 |
시도 { 버킷.get("foo", 1, 시간 단위.마이크로세컨드); } catch (런타임 예외 ex) { 만약 (ex.getCause() 인스턴스 오브 타임아웃 예외) { throw new 런타임 예외(new 타임아웃 예외("ID: FOO, TIMEOUT: 1ms")); } } |
이 방법은 매우 지루하고 필요한 내부 동작에 대한 통찰력을 제공하지 못합니다.
이 상황을 해결하기 위해 새 클라이언트는 위의 작업을 (대략적으로) 투명하게 수행하지만 아무것도 할 필요 없이 더 많은 정보를 추가합니다. 새 SDK에서 동일한 시간 초과가 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 |
예외 in 스레드 "main" 자바.lang.런타임 예외: 자바.활용.동시.타임아웃 예외: localId: 2C12AAA6637FB4FF/00000000147b092f, opId: 0x1, local: 127.0.0.1:60389, 원격: 127.0.0.1:11210, 시간 초과: 1000us 에서 rx.예외.예외.전파(예외.자바:57) 에서 rx.관찰 가능 항목.차단 관찰 가능.블록포싱(차단 관찰 가능.자바:463) 에서 rx.관찰 가능 항목.차단 관찰 가능.단일 또는 기본값(차단 관찰 가능.자바:372) 에서 com.카우치베이스.클라이언트.자바.카우치베이스버킷.get(카우치베이스버킷.자바:131) 에서 SimpleReadWrite.메인(SimpleReadWrite.자바:64) 원인 by: 자바.활용.동시.타임아웃 예외: localId: 2C12AAA6637FB4FF/00000000147b092f, opId: 0x1, local: 127.0.0.1:60389, 원격: 127.0.0.1:11210, 시간 초과: 1000us 에서 com.카우치베이스.클라이언트.자바.버킷.api.Utils$1.call(Utils.자바:75) 에서 com.카우치베이스.클라이언트.자바.버킷.api.Utils$1.call(Utils.자바:71) *snip* |
위의 로그 설명에서 일부 필드를 기억하실 수 있는데, 이는 의도된 것입니다. 이제 시간 초과 자체가 로컬 및 원격 소켓, 작업 ID, 시간 초과 설정, 문제 해결에 사용된 로컬 ID와 같은 중요한 정보를 제공합니다. 별도의 노력 없이도 이 정보를 임계값 로그에서 가장 느린 작업과 연관시킬 수 있습니다.
그리고 타임아웃 예외 이제 '무엇이' 잘못되었는지에 대한 자세한 정보를 제공하고 로그를 확인하여 '왜' 속도가 느려졌는지 파악할 수 있습니다.
트레이서 교체하기
마지막으로, 여기에는 한 가지 기능이 더 추가되었습니다. 앞서 언급했듯이 새로운 오픈트레이싱 API 는 번들로 제공되는 데에는 이유가 있습니다. 인터페이스 설명만 제공하지만, 이 정도면 모든 메트릭과 통계를 OpenTracing 호환 트레이서 구현의 전체 유니버스에 개방하기에 충분합니다. 다음과 같은 오픈 소스 중 하나를 선택할 수 있습니다. jaeger를 사용하거나 APM 공급업체에서 제공하는 것을 사용하거나 직접 작성할 수도 있습니다. 여기서 중요한 점은 SDK가 유용하고 기본적인 추적기를 포함하면서 다른 것들을 연결할 수 있는 개방적이고 표준화된 인터페이스를 사용한다는 점입니다.
예를 들어, 기본 트레이서를 예거의 트레이서로 교체하는 방법은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 |
트레이서 추적자 = new 구성( "my_app", new 구성.샘플러 구성("const", 1), new 구성.리포터 구성( true, "localhost", 5775, 1000, 10000) ).getTracer(); 카우치베이스 환경 환경 = 기본 카우치 기반 환경.빌더() .추적자(추적자) .빌드(); |
이제 실제 앱을 변경하지 않고도 모든 추적과 스팬이 분산 추적 엔진으로 전달되어 애플리케이션 환경의 동작을 시각화할 수 있는 멋진 UI가 제공됩니다.
위의 샘플과 같은 get 작업은 예거 개요 페이지에서 다음과 같이 표시될 수 있습니다:
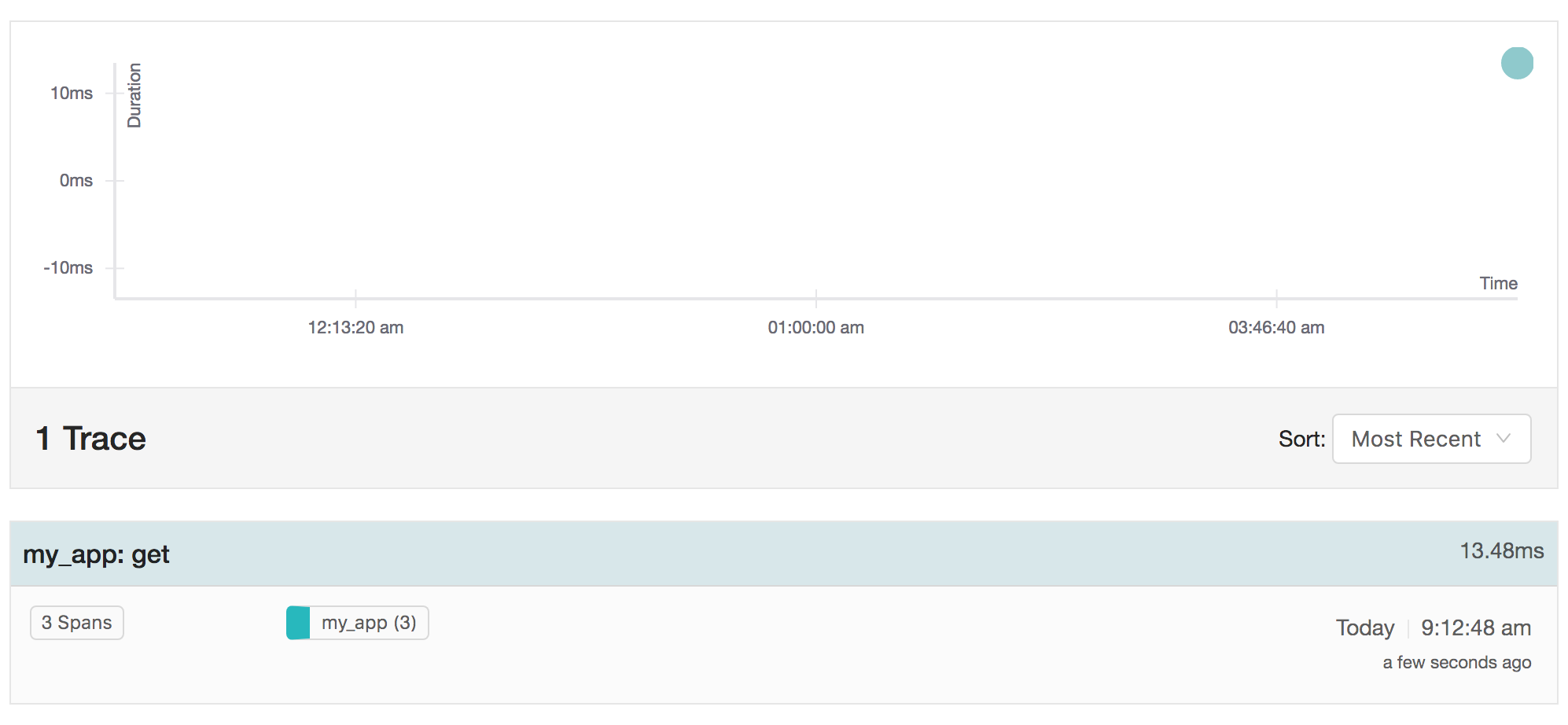
특정 트레이스를 드릴다운하면 개별 스팬 및 하위 스팬 타이밍이 표시됩니다:
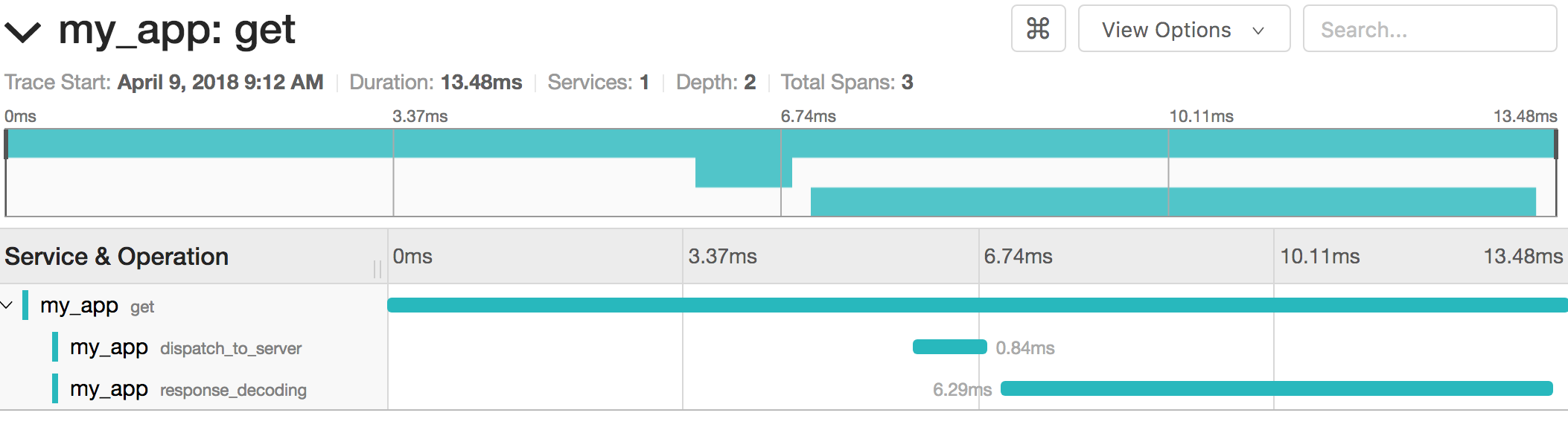
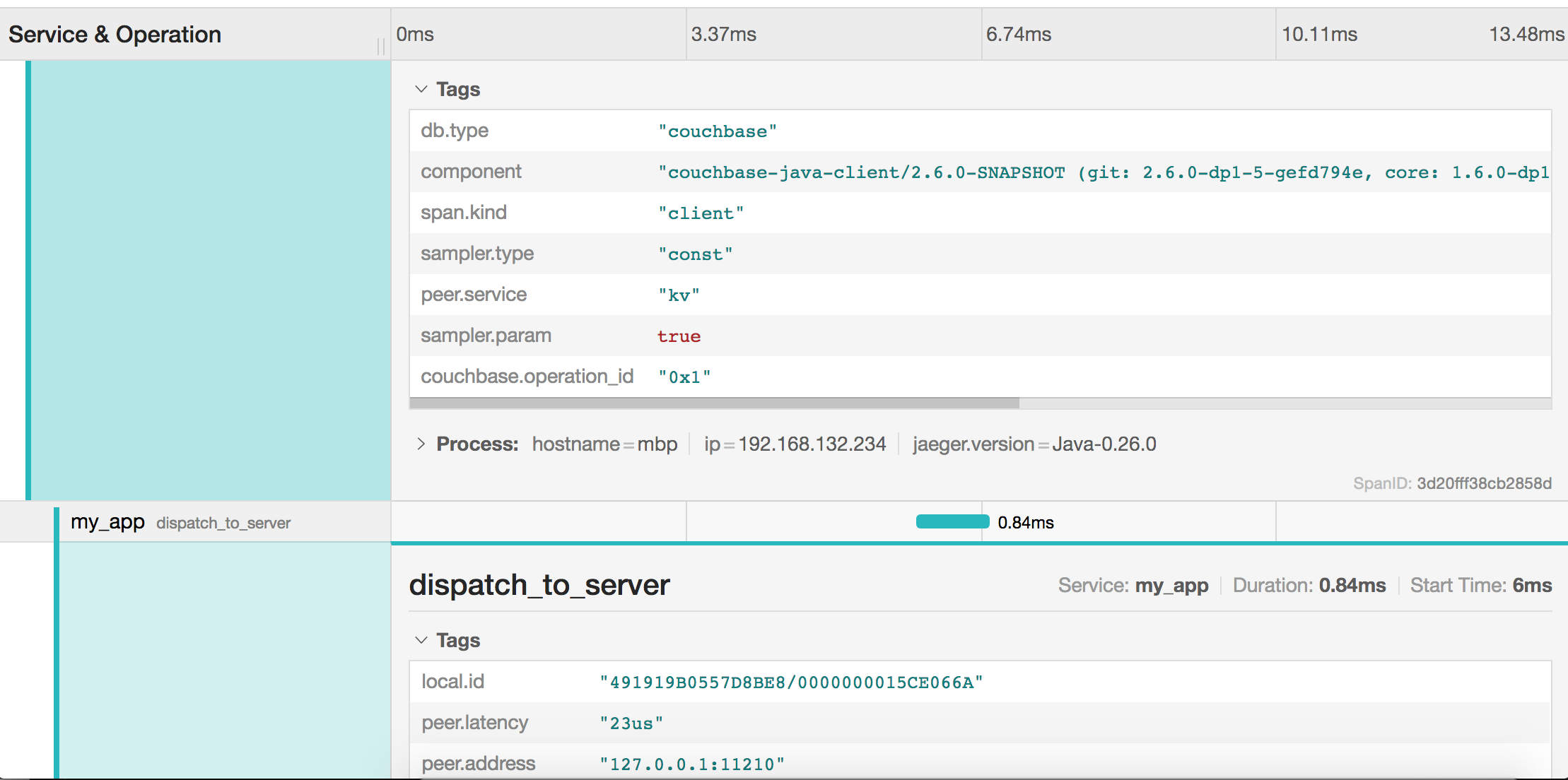
각 스팬에는 고급 필터링 및 분석을 위해 SDK가 첨부하는 태그도 포함되어 있습니다:
요약
응답 시간 관찰 기능으로 SDK를 개선하여 이제 무엇이, 왜 예상대로 작동하지 않거나 성능이 저하되는지에 대한 심층적인 인사이트를 제공할 수 있게 되었습니다. 또한 OpenTracing을 인터페이스로 사용함으로써 공급업체에 구애받지 않고 호환 가능한 APM/트래킹 도구가 필요한 경우 이를 연결할 수 있는 가능성을 열어두었습니다.