Couchbase에 N1QL 기능이 개선되었습니다. N1QL은 Couchbase Server의 주요 기능 중 하나입니다. 이번 릴리스에서는 카우치베이스 서버 5.0 는 다양한 개선 사항으로 N1QL을 더욱 강화합니다.
이러한 개선 사항 중 상당수는 이전 블로그 게시물에서 다룬 바 있습니다(예 성능 향상에 관한 Nic Raboy의 글). 이 게시물에서는 N1QL의 모든 개선 사항을 다루지는 않습니다. 다음을 확인하세요. 새로운 기능 소개 에서 자세한 내용을 확인하세요.
중요 참고 사항: 따라 하려면 다음을 설치하면 됩니다. 카우치베이스 서버 5.0 를 클릭하세요. 다음을 탐색할 수도 있습니다. 일부 카우치베이스 서버를 설치하지 않고도 이러한 N1QL 개선 사항을 확인할 수 있습니다. 10분 온라인 튜토리얼. 또한 이 블로그는 실제 릴리스와 약간 다를 수 있는 Couchbase Server의 릴리스 후보 빌드로 작성되었습니다.
RBAC를 위한 N1QL 개선 사항
Couchbase Server 5.0의 가장 큰 새로운 기능 중 하나는 내장된 역할 기반 액세스 제어(RBAC)입니다. 자세한 내용은 다음에서 확인할 수 있습니다. RBAC에 대한 이전 블로그 게시물.
문서에 잘 설명되어 있지만 여기 간단한 예가 있습니다. "myuser" 사용자를 만들고 이 사용자에게 하나의 역할만 부여하겠습니다: "travel-sample" 버킷의 데이터 리더입니다.
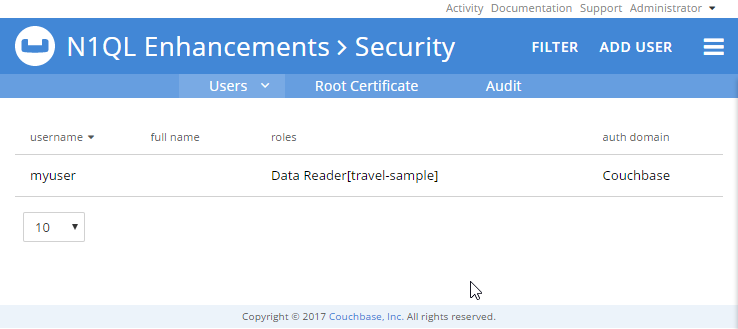
UI에서 해당 사용자를 편집하여 데이터 작성기를 제공할 수 있습니다.
부여 및 취소
하지만 다음과 같은 방법을 사용하면 됩니다. 부여 N1QL 명령:
|
1 2 3 |
부여 데이터_라이터 켜기 `여행-샘플` TO myuser; |
그런 다음 Couchbase 콘솔의 "보안" 섹션으로 이동하여 "myuser"에 새 권한이 있는지 확인할 수 있습니다.
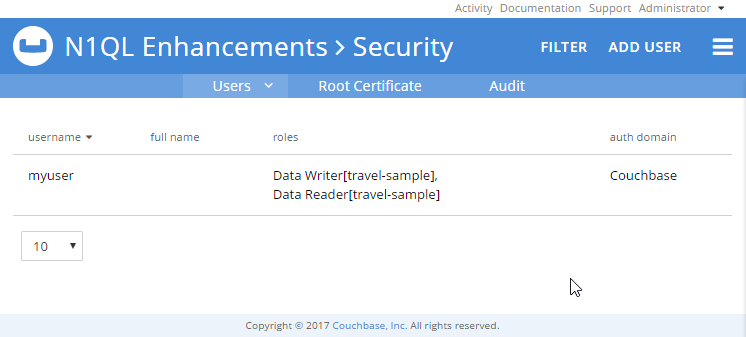
모든 역할 이름(예: "data_writer")은 다음에서 찾을 수 있습니다. 5.0 문서.
취소 는 같은 방식으로 작동하지만 그 반대입니다.
시스템 RBAC용 키 공간
몇 가지 새로운 시스템 키 공간 5.0 N1QL 개선 사항의 일부입니다. SELECT * FROM system:user_info 는 각 사용자 및 역할에 대한 정보를 반환합니다.
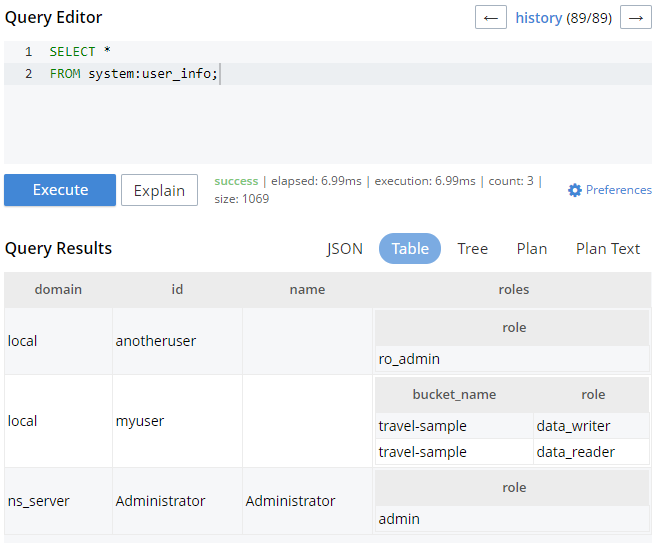
다음을 사용할 수 있습니다. SELECT * FROM system:applicable_roles 키스페이스를 입력하면 모든 역할 정보 목록을 확인할 수 있습니다.
관리자와 '시스템 카탈로그 쿼리' 역할이 있는 사용자만 이러한 키 공간에 액세스할 수 있습니다.
curl
As Isha는 앞서 블로그에서이제 N1QL의 CURL 함수를 사용하여 외부 JSON 데이터를 쿼리할 수 있습니다. CURL을 사용할 때는 분명 보안에 영향을 미칠 수 있으므로 전체 내용을 읽어보세요. N1QL CURL 문서 이 N1QL 개선 사항을 사용하기로 결정하기 전에 확인하세요.
CURL을 사용하려면 먼저 화이트리스트에 URL을 추가해야 합니다. Windows에서는 /var/lib/couchbase/n1qlcerts 폴더(저도 n1qlcerts 폴더를 직접 만들어야 했습니다)에 curl_whitelist.json이라는 파일을 생성하여 이 작업을 수행합니다. 참조할 수 있는 전체 기본 경로는 다음과 같습니다: C:\Program Files\Couchbase\Server\var\lib\couchbase\n1qlcerts\curl_whitelist.json입니다.
단일 URL 항목으로 파일을 만들었습니다(swapi.co는 스타 워즈 API입니다):
|
1 2 3 4 |
{ "all_access": false, "allowed_urls": ["https://swapi.co"] } |
그런 다음 CURL 함수를 사용하여 N1QL 쿼리로 JSON 데이터를 검색할 수 있습니다. 예를 들어 다음과 같이 단일 행성을 검색할 수 있습니다. https://swapi.co/api/planets/3/를 클릭하거나 모든 행성을 검색할 수도 있습니다(제가 한 것처럼요):
|
1 2 |
선택 p.이름, p.기후, p.거주자 FROM CURL("https://swapi.co/api/planets/").결과 as p; |
이 엔드포인트는 한 번에 10개의 행성을 반환합니다. 범위를 좁혀서 결과 필드에 이름, 기후, 거주자를 추가할 수 있습니다.
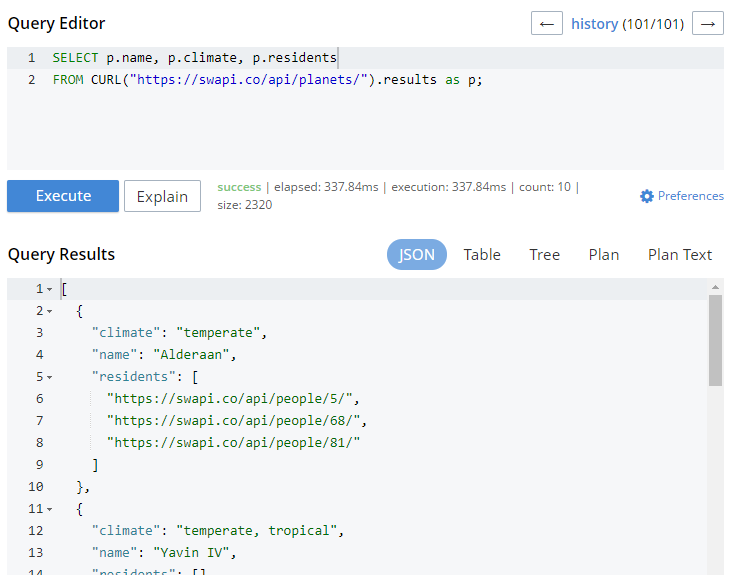
쿼리에 대한 CURL은 외부 데이터 소스에 대한 성능과 안정성을 포기하는 다른 문제도 발생한다는 점에 유의하세요. 또한 Couchbase Server의 자체 REST API에서 CURL을 사용할 수 있으므로 흥미로운 가능성이 많이 열립니다.
색인
항상 그렇듯이, 좋은 인덱싱은 N1QL 쿼리에서 최적의 성능을 얻는데 필수적입니다. 이 블로그 게시물에서는 다루지 않겠지만 Couchbase Server에는 많은 인덱스 옵션이 있습니다. 확실히 프라사드 바라쿠르의 블로그 게시물을 확인하세요. 또한 최적화 버전 5.0에서 Couchbase에 추가되었습니다.
이 글에서는 새로 도입된 적응형 인덱스 그리고 등가 인덱스.
적응형 인덱스
이전 버전의 Couchbase에서는 필드 조합을 색인하려면 각 조합에 대해 색인을 만들어야 했습니다. 예를 들어, 'type' 및 'name' 필드를 함께 확인하거나 'type' 및 'age' 필드를 함께 확인하는 쿼리를 작성하려는 경우, 두 개의 복합 인덱스가 필요합니다. 유형, 이름 그리고 하나는 유형, 상태.
이 쿼리를 생각해 보세요:
|
1 2 3 4 |
선택 l.* FROM `여행-샘플` l 어디 l.유형='랜드마크' AND l.상태='캘리포니아'; |
기본값에서 여행 샘플 버킷의 유형 필드는 인덱싱되지만 상태는 인덱싱되지 않습니다. 이 쿼리는 작동하지만 쿼리 계획이 얼마나 평평한지 알 수 있습니다:
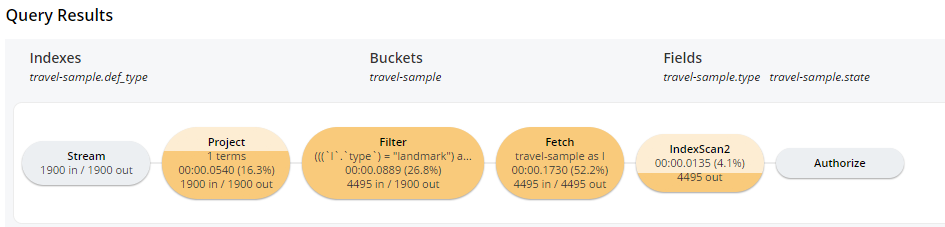
또한 '가져오기' 및 '필터링' 단계에서는 약 4500개의 문서를 처리해야 한다는 점에 유의하세요.
적응형 인덱스를 사용하면 애드혹 쿼리를 더 잘 지원하는 인덱스를 더 쉽게 작성할 수 있습니다. 지정된 필드 또는 문서의 모든 필드를 색인하는 데 사용할 수 있습니다.
이번 N1QL 개선 사항에서 새롭게 도입된 키워드는 다음과 같습니다. SELF. 다음과 같이 여행 샘플 버킷에 있는 모든 '랜드마크' 문서의 모든 필드에 적응형 인덱스를 생성할 수 있습니다:
|
1 2 3 |
만들기 INDEX `AI_N1Q_ENHANCED` 켜기 `여행-샘플`(DISTINCT PAIRS(SELF)) 어디 유형 = '랜드마크'; |
대신 인덱싱할 개별 필드를 지정할 수도 있습니다. SELF.
이 인덱스를 생성한 후 위의 선택 다시 쿼리합니다.
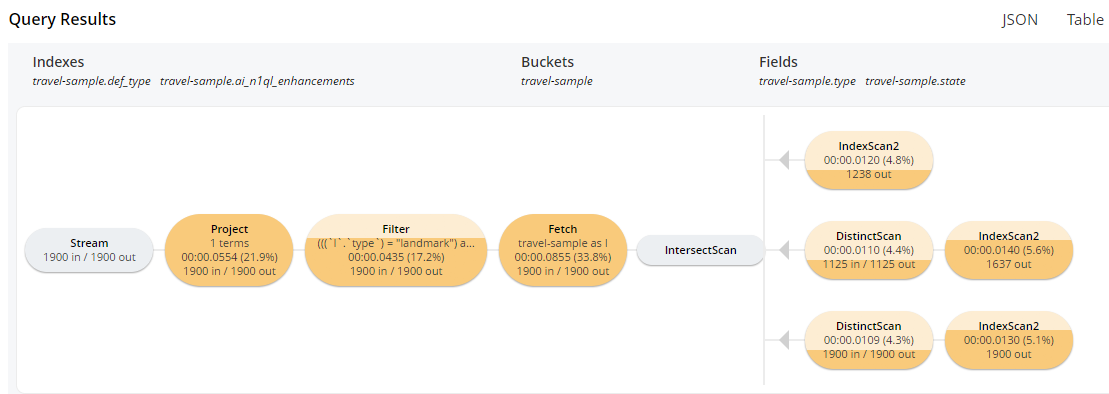
인덱스 스캔이 추가로 발생하는 것을 확인할 수 있습니다. 상태 필드에 쿼리하고 있습니다. 또한 '필터'와 '가져오기'는 1900개에 불과한 더 적은 수의 문서를 처리하고 있다는 점도 주목하세요. "여행 샘플" 버킷의 크기가 상대적으로 작기 때문에 전체적으로 적은 비용 절감 효과가 있습니다. 그리고 real 버킷에 수백만 개의 문서가 들어있는 경우 시간을 크게 절약할 수 있습니다.
또한 쿼리가 더 복잡해지면 더욱 그렇습니다, 적응형 인덱스 를 사용하면 작업량을 줄이면서도 성능을 향상시킬 수 있습니다.
인덱스 복제본
애플리케이션에서 N1QL을 많이 사용하는 경우, 클러스터 전체에 분산되는 여러 인덱스를 생성할 수 있습니다. 이러한 N1QL 개선 사항은 성능, 로드 밸런싱 및 가용성을 향상시킬 수 있습니다.
Couchbase Server 5 이전까지는 이름이 다른 여러 개의 동일한 인덱스를 만드는 것이 이 작업을 수행하는 방식이었습니다. Venkat이 이 글에서 다룬 것처럼 인덱스 복제본에 대한 이전 블로그 게시물하지만 여기에는 몇 가지 단점이 있습니다.
따라서 Couchbase Server 5에서는 인덱스 복제본이 도입되었습니다. 인덱스를 생성할 때 num_replica 설정을 사용하여 생성할 복제본 인덱스의 수를 지정할 수 있습니다.
다음은 상태 필드를 "travel-sample" 버킷에서 사용하고 있었습니다. 이 경우에는 두 번 복제하겠습니다.
|
1 2 3 4 |
만들기 INDEX `ix_state` 켜기 `여행-샘플`(상태) 어디 상태 IS NOT 누락 WITH {"num_replica":2}; |
이 기능을 사용하려면 인덱스 서비스를 실행하는 노드가 최소 3개(인덱스용 1개, 복제본용 2개)가 필요합니다.
위의 쿼리를 실행한 후(3노드 클러스터에서) "인덱스"를 클릭합니다. 3개의 노드에서 "ix_state"가 3번 표시되는 것을 볼 수 있습니다. 그 중 2개는 "복제본"으로 표시됩니다.

다음에서 IP 주소를 지정하여 복제본을 원하는 정확한 노드를 지정할 수도 있습니다. 인덱스 생성.
나머지는 Couchbase가 알아서 처리합니다. 인덱스 복제본은 들어오는 쿼리에 사용됩니다.
Couchbase를 처음 사용하는 경우 다음을 확인하세요. "동등한 인덱스"에서 인덱스 복제본으로 전환하는 방법에 대한 가이드.
자세한 내용은 다음을 확인하세요. 인덱스 복제본에 대한 Venkat의 블로그 게시물 및 인덱스 복제에 대한 Couchbase Server 5.0 문서.
모니터링
N1QL 쿼리를 작성할 때 가장 어려운 작업은 쿼리의 효율성과 성능을 확인하는 것입니다. 이를 위해 Couchbase Server 5.0에는 쿼리를 모니터링하고 프로파일링하는 데 도움이 되는 여러 가지 기능이 도입되었습니다.
지난 3월에 제가 새로 도입한 쿼리 계획 시각화. 또한 새로운 시스템 키 공간 를 사용하여 쿼리를 모니터링합니다.
전체 스토리는 다음 링크에서 확인할 수 있습니다. N1QL 쿼리 모니터링 문서 페이지로 이동합니다.
이 글에서는 간단히 다시 한 번 정리해 보겠습니다. 쿼리 워크벤치에서 '계획' 버튼을 클릭하면 쿼리 계획의 그래픽 표현을 볼 수 있습니다. 쿼리에서 어느 부분에 가장 많은 시간이 걸리는지 시각적으로 확인할 수 있습니다. 예를 들어, 위의 쿼리 계획은 다음과 같습니다. 선택 쿼리:
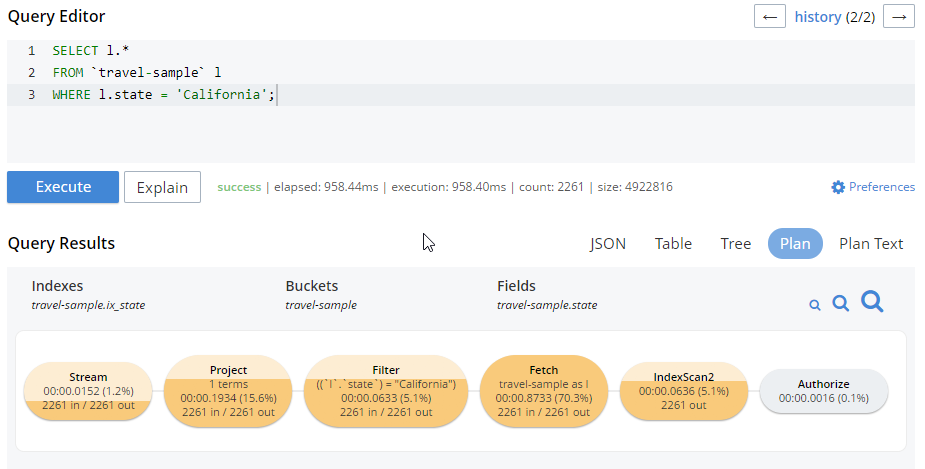
이 외에도 몇 가지 N1QL 개선 사항이 더 있습니다. 두 개의 새로운 시스템 키 공간: 시스템:완료_요청 그리고 시스템:활성_요청. 이러한 키 공간에는 실행되었거나 현재 실행 중인 쿼리에 대한 정보(쿼리에 걸린 시간, 오류, 실행 중인 노드 등)가 포함되어 있습니다. 간단한 예시입니다:
|
1 2 |
선택 r.노드 FROM 시스템:완료_요청 r; |
인덱스 복제본이 있기 때문에 이 쿼리는 다른 노드에서 실행되었을 수 있습니다. 결과는 그들이 실행했음을 보여줍니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[ { "node": "10.142.173.101:8091" }, { "node": "10.142.173.101:8091" }, { "node": "10.142.173.103:8091" }, { "node": "10.142.173.103:8091" }, // ... 등 ... ] |
다른 툴링 업데이트 을 지원합니다. N1QL만 개선되는 것이 아닙니다.
요약
N1QL은 Couchbase Server의 주요 강점 중 하나이며, Couchbase는 가치 있는 N1QL 개선 사항을 만들기 위해 최선을 다하고 있습니다.
아직 N1QL을 사용해 보지 않았다면 10분 온라인 튜토리얼 오늘?
질문이나 의견이 있으신가요? 저를 찾아주세요 트위터 @mgroves 또는 이메일을 보내주세요. matthew.groves@couchbase.com.