이제 Couchbase 7.0을 통해 Python UDF를 Couchbase Analytics와 통합할 수 있습니다. In 이 블로그 시리즈의 1부에서 Couchbase와 머신 러닝용 분석(ML)을 설정하는 데 필요한 필수 사항을 다루었습니다.
ML은 조직이 고객의 니즈를 이해하는 방식을 근본적으로 변화시켰습니다. 예측 분석(고객 이탈, 고객 감정 등) 및 재무 모델링과 같은 고급 분석 영역에서는 실시간에 가까운 대규모 데이터 처리와 그로부터 가치 있는 인사이트를 추출하는 것에 대한 의존도가 점점 더 커지고 있습니다.
고객이 실시간으로 분석 인사이트를 얻을 수 있도록 Python 기반 머신 러닝 모델에서 Couchbase 분석에 이르는 원활한 파이프라인을 만들었습니다. 이 게시물에서는 다음 단계를 통해 Couchbase에 상주하는 데이터에 외부 알고리즘을 적용하는 방법을 보여드립니다.
NoSQL 데이터에 ML 모델을 적용하는 6가지 단계:
- 모델 훈련
- 모델 코드화
- 코드 패키징 및 배포
- 이 프로젝트에 필요한 데이터 가져오기
- UDF 작성
- 인스턴스에서 CB(DP 모드)에 UDF 사용
자세히 알아보기 전에 우리가 구축 중인 기능을 흥미롭게 보여줄 수 있는 데이터 세트를 찾아보겠습니다. 여러 웹사이트에 영화 리뷰가 있지만, 평론가들의 리뷰를 전체적으로 이해하려면 Rotten Tomatoes보다 더 좋은 곳은 없습니다. 이 웹사이트에서는 일반 사용자가 부여한 평점(관객 점수)과 비평가가 부여한 평점 또는 리뷰를 비교할 수 있습니다(토마토미터) 다양한 글쓰기 길드 또는 영화 비평가 협회의 인증된 회원입니다.
이 블로그에 사용된 두 데이터 세트는 다음에서 확인할 수 있습니다. kaggle.com. 다소 용량이 큰 파일이므로 링크를 통해 다운로드할 수 있습니다.
에서 영화 데이터 세트에서 각 레코드는 영화 제목, 설명, 장르, 상영 시간, 감독, 배우, 사용자 평점, 비평가 평점을 스크랩하는 데 사용된 URL과 함께 Rotten Tomatoes에서 사용할 수 있는 영화를 나타냅니다. 데이터 세트의 영화_리뷰 데이터 세트에서 각 레코드는 비평가 이름, 리뷰 게시글, 날짜, 점수 및 내용을 스크랩하는 데 사용된 URL과 함께 Rotten Tomatoes에 게시된 비평가 리뷰를 나타냅니다.
ML 모델 학습
ML과 NoSQL 간의 통합 기능을 살펴보기 전에 먼저 Python에서 머신 러닝 모델을 개발하고 학습해야 합니다.
이 블로그에서는 scikit-learn 라이브러리를 활용하는 간단한 로지스틱 회귀 모델을 사용하겠습니다. 이 모델의 핵심은 데이터를 가져와 영화 리뷰에 대한 감정을 분석하는 것입니다. 아래에 설명된 단계를 따르거나 다음에서 필요한 모든 파일을 다운로드할 수 있습니다. GitHub 리포지토리.
이 블로그에서는 영화 리뷰 데이터 세트에 오픈 소스 예측 알고리즘을 사용하여 감성을 결정합니다. 즉, 리뷰가 특정 영화에 대해 긍정적인지 부정적인지 판단하는 것입니다. 오늘 예제에서는 이전에 다운로드한 파일의 하위 집합을 사용하여 모델을 이미 학습시켰습니다. 이 블로그에서는 데이터를 가져오기 위해 쉼표로 구분된 CSV(쉼표로 구분된 값) 파일을 활용합니다.
아래는 모델 자체에 대한 코드 샘플입니다:
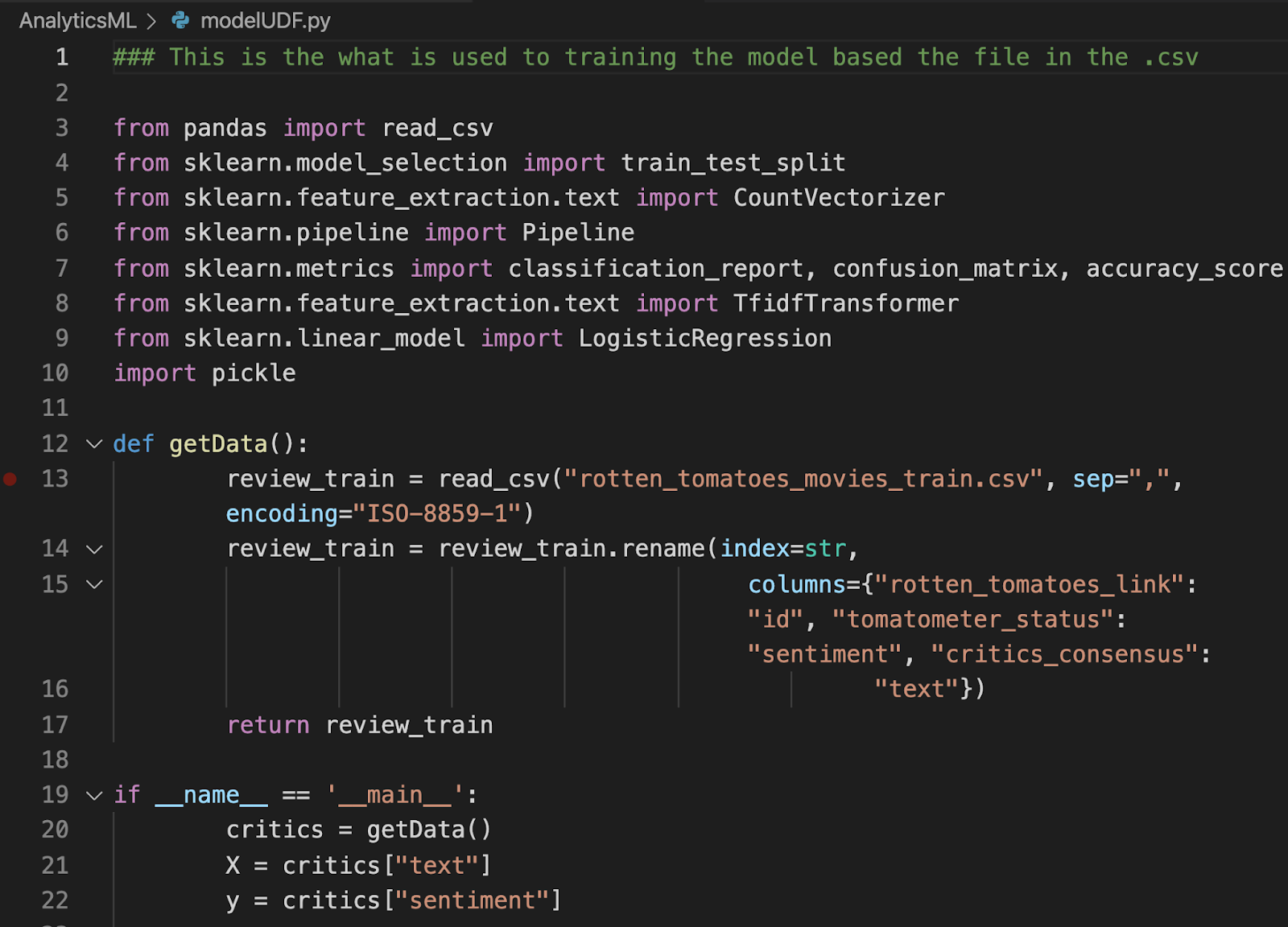
코드 샘플 전체는 다음 문서에서 확인할 수 있습니다. GitHub 리포지토리.
위에 표시된 모델 파이썬 스크립트를 실행하면 다음과 같은 결과가 표시됩니다:

정확도, 리콜, F1 점수, 지원과 같은 Scikit-Learn 메트릭에 대해 자세히 알아보세요. 여기. 이제 파이썬으로 완전히 학습된 기능적이고 성능이 우수한 머신 러닝 모델을 갖게 되었습니다.
Python 라이브러리 만들기
머신 러닝 모델을 참조하려면 Python 라이브러리를 만들어야 합니다. 아래는 이 특정 예제의 라이브러리입니다:
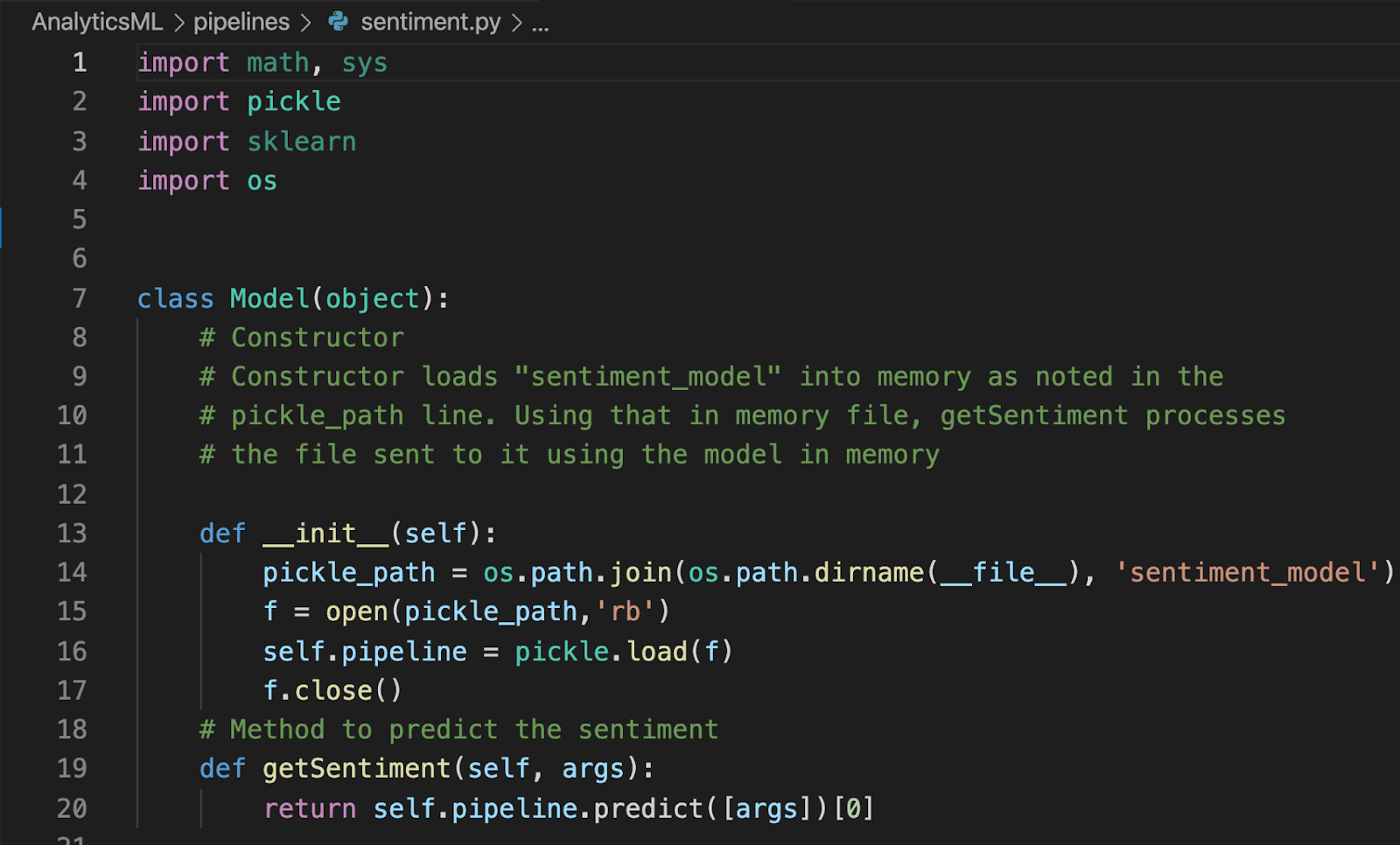
라이브러리에는 두 가지 주요 구성 요소가 있습니다:
모델 생성자-이 생성자는 다음과 같은 파일을 생성합니다. 감정_모델 에서 파이프라인 폴더에 있습니다.
getSentiment 메서드-이 메서드는 전달된 매개 변수(또는 인수)와 관련된 고객 감성을 예측합니다.
파일을 다음 이름으로 저장합니다. sentiment.py 내에서 파이프라인 폴더에 파일 감정_모델.
라이브러리 패키징 및 배포
이것은 앞으로 이어질 파이썬 사용자 정의 함수의 강력한 기능을 활용하는 데 있어 중요한 단계입니다! 다른 어떤 함수보다 구문에 따라 달라지므로 세부 사항에 주의하세요. 해당 설명서를 자세히 읽어보세요. 링크 따라가기 사용자 정의 함수에 대해 자세히 알아보세요..
이전 단계에서 만든 모델과 라이브러리를 패키징하기 위해 shiv 유틸리티를 사용합니다. shiv가 아직 설치되어 있지 않은 경우 다음 명령을 사용합니다. pip 설치 시브 (또는 pip3 설치 shiv 로 변경할 수 있습니다.) 또한 이 명령줄 유틸리티에 대한 설명서를 읽고 싶다면 다음에서 찾을 수 있습니다. 여기.
모델을 패키징하는 단계:
- 노트북에서 감정 모델과 모델 코드를 패키징합니다. 이렇게 하면 자체 실행이 가능하고 라이브러리 종속성이 제거됩니다:
-
- shiv -사이트-패키지 파이프라인/ -o pipeline.pyz -플랫폼 manylinux1_x86_64 -python-version 39 -only-binary=:all: scikit-learn
-플랫폼 manylinux1_x86_64 는 Linux를 실행하는 가상 머신을 사용할 때만 필요합니다.
- 필요한 종속성이 포함된 독립형 Python 패키지를 분석 서버에 복사합니다:
- 도커 cp 파이프라인.pyz cb-analytics:/tmp/
- 의 셸에 액세스합니다. CB-분석 도커 컨테이너:
- 도커 실행 -it cb-analytics bash
- Docker 셸 내부에서 tmp 폴더에 zip 파일을 넣고 두 버킷에 필요한 데이터를 가져옵니다:
- cd /tmp
- curl -v -X POST -F "data=@./pipeline.pyz" -F "type=python" "localhost:8095/analytics/library/Default/sentimentlibrary" -u Administrator:password;
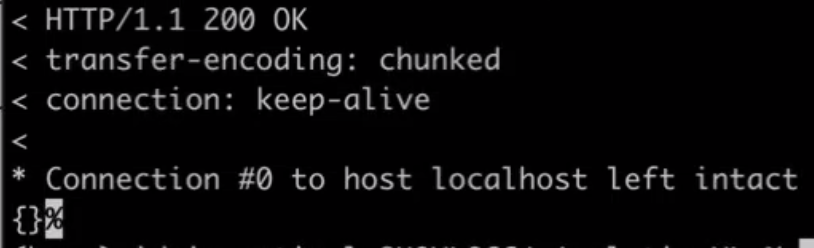
- 시스템이 완료되면 업데이트되며 이 HTTP 200 응답이 표시되면 성공입니다:
분석할 UDF용 버킷 문서 가져오기
로컬 머신에서 수행해야 할 두 가지 단계와 Docker 인스턴스에서 실행해야 할 세 가지 명령이 있습니다.
로컬 머신
0. 버킷 만들기 영화 또는 영화_리뷰 에서 웹 콘솔 또는 couchbase-cli 명령
- 실행: 도커 cp rotten_tomatoes_critic_reviews.csv cb:/tmp/ 이 파일은 GUI 가져오기 유틸리티의 100Mb 제한을 초과하므로 직접 가져와야 합니다.
도커 인스턴스
2. docker exec -it cb bash
3. cbimport csv -infer-types -c https://localhost:8091 -u 관리자 -p 비밀번호 -d 'file://rotten_tomatoes_critic_reviews.csv' -b 'movie_reviews' -scope-collection-exp "_default._기본값" -g "%rotten_tomatoes_link%"
cbimport csv -infer-types -c https://localhost:8091 -u 관리자 -p 비밀번호 -d 'file://rotten_tomatoes_movies.csv' -b 'movies' -scope-collection-exp "_default._default" -g "%rotten_tomatoes_link%"
마지막 파일(rotten_tomatoes_movies.csv)를 위와 같이 명령줄에서 실행하거나 Couchbase 웹 콘솔 > 문서 > 가져오기 스크린샷과 같이 Couchbase 포털의 화면으로 이동합니다:
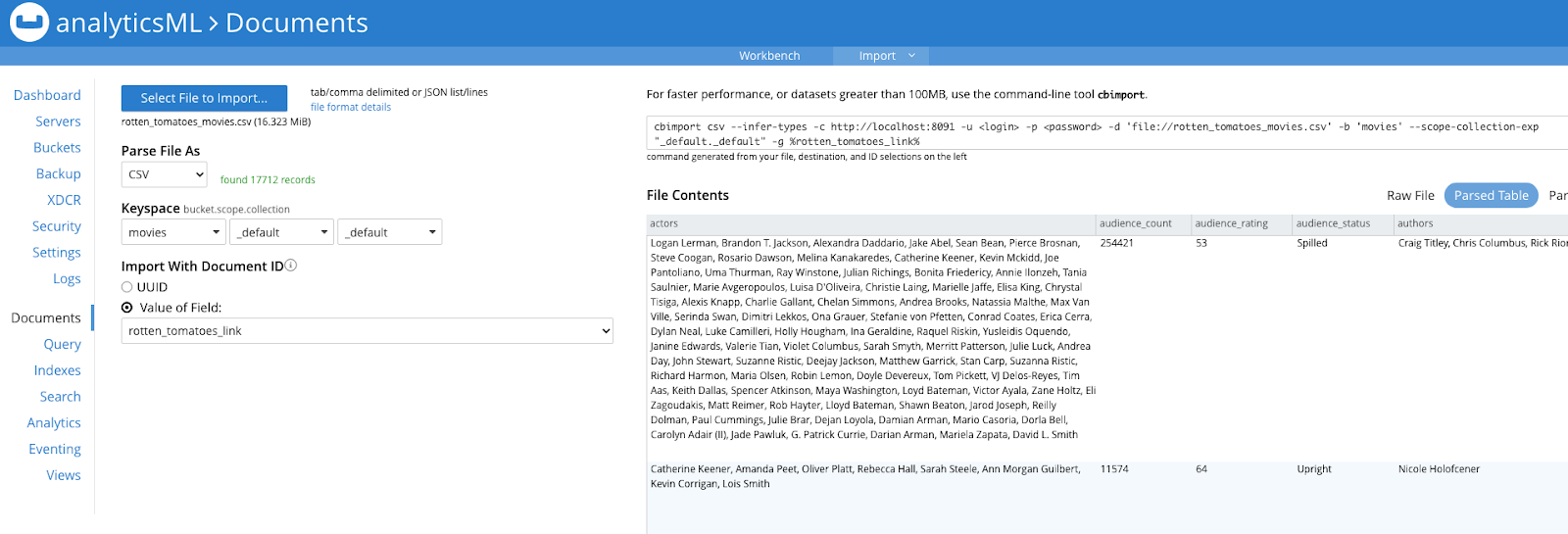
이제 두 개의 버킷에 문서가 있으며, 여기에는 감정 분석을 실행할 Couchbase의 리뷰와 영화 요약이 포함되어 있습니다.
UDF 작성
이제 카우치베이스 애널리틱스에서 사용자 정의 함수를 직접 작성해 볼 차례입니다. 다시 한 번 복습이 필요한 경우 다음 문서에 대한 링크를 참조하세요. 사용자 정의 기능. 라이브러리( 모델 생성자 및 getSentiment 메서드)를 2단계에서 생성한 다음 3단계에서 애널리틱스 서버에 업로드했습니다. 이제 다음 사용자 정의 함수에서 참조됩니다:
|
1 2 |
CREATE ANALYTICS FUNCTION getReviewSentiment(text) AS "sentiment", "Model.getSentiment" AT sentimentlibrary; |
같은 위치에 Analytics UDF를 만듭니다(감정 라이브러리)에 지정된 대로 curl 함수입니다.
UDF 호출하기
이제 N1QL의 기능을 활용하여 Couchbase Analytics 내에서 예측 쿼리를 작성하여 UDF에서 강력한 인사이트를 도출할 수 있습니다. 내부적으로, 이 UDF를 호출할 때 이 쿼리는 기본 모델 메서드를 사용하여 각 행을 반복하여 감성 분석을 수행할 수 있습니다. 다음은 이러한 쿼리의 기본 예시이지만, 그 가능성은 정말 무궁무진합니다.
|
1 2 3 4 5 6 |
USE Default; SELECT getReviewSentiment(r.review_content) AS sentiment, COUNT(*) AS sentimentCount FROM movie_reviews r, movies m WHERE m.rotten_tomatoes_link = r.rotten_tomatoes_link GROUP BY getReviewSentiment(r.review_content) ORDER BY sentimentCount DESC; |
이러한 쿼리를 사용하면 다음과 같은 결과를 얻을 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "sentimentCount": 10105, "sentiment": "Fresh" }, { "sentimentCount": 7601, "sentiment": "Rotten" } ] |
이제 학습된 모델에 의해 정의된 긍정적, 중립적, 부정적 감성이 순서대로 집계됩니다.
결론
축하합니다. 방금 Docker에서 필요한 Couchbase Server 환경을 설정하고 Couchbase Analytics에서 첫 번째 사용자 정의 함수를 성공적으로 실행했습니다. 보시다시피, Python ML 모델과 UDF 및 Couchbase Analytics의 통합은 성능이나 효율성을 저하시키지 않으면서 데이터에서 가치 있는 정보를 추출하는 효과적인 방법이 될 것입니다.
질문이나 피드백이 있으면 아래 댓글이나 다음 게시물을 통해 언제든지 공유해 주세요. 카우치베이스 포럼. 귀사에서 ML과 NoSQL의 강력한 기능을 엔터프라이즈에 어떻게 결합할지 기대가 됩니다.
카우치베이스 애널리틱스에 대해 자세히 알아보려면 연결 세션을 시청하세요: 머신 러닝과 NoSQL의 만남: Python UDF.
다음은 이 게시물에 언급된 링크와 주제를 요약한 내용입니다:
- 1부 - ML과 NoSQL의 만남: 분석을 위한 Python 사용자 정의 함수와 N1QL의 통합
- 카우치베이스 애널리틱스ML GitHub 리포지토리
- 로튼 토마토 리뷰의 Kaggle 데이터 세트
- 카우치베이스 사용자 정의 함수 문서
감사
덕분에 아누즈 코타리, 지난 여름에 이 서비스를 처음 시작하고 시작하게 해준 Couchbase 애널리틱스 서비스의 여름 제품 관리 인턴이었습니다. 덕분에 이드리스 모티왈라, 카우치베이스 애널리틱스 서비스 수석 제품 관리자, 그리고 이안 맥슨보다 기능적인 블로그를 만들기 위해 편집 작업을 해준 Couchbase 분석 서비스의 소프트웨어 엔지니어에게 감사를 표합니다.
