다른 케이스의 로스는 달콤한 냄새가 납니다. 윌리엄 셰익스피어
다음을 배웠어야 합니다. 대문자 규칙 를 사용하지만 실제 검색에서는 대소문자에 그렇게 민감하지 않습니다. 샤를 드골은 가운데 '드'에 소문자를, 토니 라 루사는 '라'에 대문자를 사용하는데, 어원적인 이유가 있을 수 있지만 고객 서비스 상담원이 이를 기억할 가능성은 거의 없습니다. 데이터베이스에는 다양한 민감도가 있습니다. 기본적으로 SQL은 식별자 및 키워드에는 대소문자를 구분하지 않지만 데이터에는 대소문자를 구분합니다. JSON은 필드 이름과 데이터 모두 대소문자를 구분합니다. N1QL도 마찬가지입니다. JSON에는 다음이 포함될 수 있습니다. N1QL은 각 필드와 값을 별개의 필드와 값으로 선택-조인-프로젝트합니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT {"City": "San Francisco", "city": "san francisco", "citY": "saN fanciscO"} [ { "$1": { "City": "San Francisco", "citY": "saN fanciscO", "city": "san francisco" } } ] |
이 문서에서는 다음을 처리하는 방법에 대해 설명합니다. 데이터 대/소문자 민감도. 필드 참조는 여전히 대소문자 구분. 필드 이름에 잘못된 대/소문자를 사용하는 경우 N1QL은 누락된 필드로 간주하고 해당 필드에 MISSING 값을 할당합니다.
모든 대소문자 순열을 조회하는 N1QL의 간단한 술어를 고려해 보겠습니다.
|
1 |
WHERE name in [“joe”, “joE”, “jOe”, “Joe”, “JoE”, “JOe”, “JOE”] |
이렇게 하려면 인덱스에 대해 7개의 다른 조회가 필요합니다. "John"은 더 많은 인덱스 조회가 필요하고 "Fitzerald"는 더 많은 인덱스 조회가 필요합니다. 이를 수행하는 표준 방법이 있습니다. 필드와 리터럴의 대소문자를 낮추어 인덱스를 생성하기만 하면 됩니다.
|
1 |
WHERE LOWER(name) = “joe” |
올바른 표현식으로 인덱스를 생성하면 이 조회를 더 빠르게 수행할 수 있습니다.
|
1 |
CREATE INDEX i1 ON customer(LOWER(name)); |
쿼리가 올바른 인덱스를 선택하고 있는지 확인하고 술어를 인덱스 스캔으로 푸시합니다. 이것이 바로 아이디어입니다. 인덱스 스캔으로 푸시된 술어가 있는 쿼리는 그렇지 않은 쿼리보다 훨씬 빠르게 실행됩니다. 이는 술어와 참 집계 푸시다운 도 마찬가지입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
EXPLAIN SELECT * FROM `customer` WHERE LOWER(name) = "joe"; { "#operator": "IndexScan3", "index": "i1", "index_id": "c117bdf583c2e276", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"joe\"", "inclusion": 3, "low": "\"joe\"" } ] } ], |
복합 인덱스 시나리오에서의 대소문자 무감지.
|
1 2 3 4 5 |
WHERE LOWER(name) = “joe” AND zip = 94821 AND salary > 500 AND join_date <= “2017-01-01” AND LOWER(county) LIKE “san%” |
|
1 2 3 4 5 |
CREATE INDEX i2 ON customer(LOWER(name), zip, LOWER(county), join_date, salary) |
배열 함수에서 대소문자를 구분하지 않습니다.
문자열 함수 분할(), 접미사()와 같은 많은 배열 함수 그리고 객체 함수 는 배열을 반환합니다. 그렇다면 대소문자를 구분하지 않는 방식으로 어떻게 사용할 수 있을까요?
이전과 동일한 원칙을 따릅니다. 이러한 함수를 통해 값을 처리하기 전에 먼저 값을 소문자로 처리하는 표현식을 만듭니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SPLIT("Good Morning, Joe") as splitresult; "splitresult": [ "Good", "Morning,", "Joe" ] SELECT SPLIT(LOWER(“Good Morning, Joe”)); "splitresult": [ "good", "morning,", "joe" ] |
이제 실제로 원하는 것은 문자열 내의 값을 기준으로 필터링하는 것입니다.
|
1 |
WHERE LOWER(xyz) LIKE “%good%”; |
이것은 아마도 성능 측면에서 SQL에서 최악의 술어일 것입니다.
|
1 2 |
SELECT * FROM customer WHERE x IN SPLIT(LOWER(xyz)) SATISFIES x = “good” END |
이제 이를 위해 어떤 인덱스를 만들까요? 조언 가 유용합니다.
|
1 2 |
CREATE INDEX adv_DISTINCT_split_lower_xyz ON `customer` (DISTINCT ARRAY `x` FOR x in split(lower((`xyz`))) END) |
평소와 마찬가지로 설명을 확인합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "index": "adv_DISTINCT_split_lower_xyz", "index_id": "552ab6c643616fbc", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"good\"", "inclusion": 3, "low": "\"good\"" } ] } ], |
중첩을 해제하고 간단한 WHERE 절을 사용하려면 이 쿼리를 사용하세요. 항상 설명을 확인하여 술어가 인덱스 스캔으로 푸시되는지 확인하세요.
|
1 2 3 |
SELECT * FROM customer UNNEST SPLIT(LOWER(xyz)) AS x WHERE x = "good" |
토큰 사용
TOKENS() 함수를 사용하면 해당 옵션을 인수로 받아 소문자를 간단하게 가져올 수 있습니다. 문서 참조 좋아요 그 이상: N1QL을 사용한 효율적인 JSON 검색 자세한 내용 및 예시
복잡한 표현.
|
1 2 3 4 |
SELECT * FROM customer WHERE lower(fname) || lower(mname) || lower(lname) = “JoeMSmith” |
어떻게 최적화할 수 있을까요? 인덱스 어드바이저가 구출했습니다. 또다시.
|
1 2 |
CREATE INDEX adv_lower_fname_concat_lower_mname_concat_lower_lname ON `customer`(lower((`fname`))||lower((`mname`))||lower((`lname`))) |
계획을 확인하기 위해 설명합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "IndexScan3", "index": "adv_lower_fname_concat_lower_mname_concat_lower_lname", "index_id": "aaa14cbdf14e9cd8", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"JoeMSmith\"", "inclusion": 3, "low": "\"JoeMSmith\"" } ] } ], "using": "gsi" }, |
거물급 인사 영입: 전체 텍스트 검색
아시다시피 이것은 텍스트 처리 및 쿼리 문제입니다. FTS는 다양한 방식으로 텍스트를 스캔, 저장, 검색할 수 있습니다. 대소문자를 구분하지 않는 검색도 그중 하나입니다. 간단한 검색 쿼리에 대한 계획을 살펴보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
select * from customer where search (name, "joe") "~children": [ { "#operator": "PrimaryScan3", "index": "#primary", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "keyspace": "customer", "namespace": "default" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "search((`customer`.`name`), \"joe\")" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "self", "star": true } ] } ] } } ] } |
이것은 원하는 플랜이 아닙니다... 이것은 기본 스캔을 사용하는 것입니다!
버킷 고객에 텍스트 인덱스를 생성한 후에는 상황이 훨씬 더 좋아집니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
select * from customer where search (name, "joe") { "#operator": "Sequence", "~children": [ { "#operator": "IndexFtsSearch", "index": "trname", "index_id": "3bdb61e5010e8838", "keyspace": "customer", "namespace": "default", "search_info": { "field": "\"`name`\"", "outname": "out", "query": "\"joe\"" }, "using": "fts" }, |
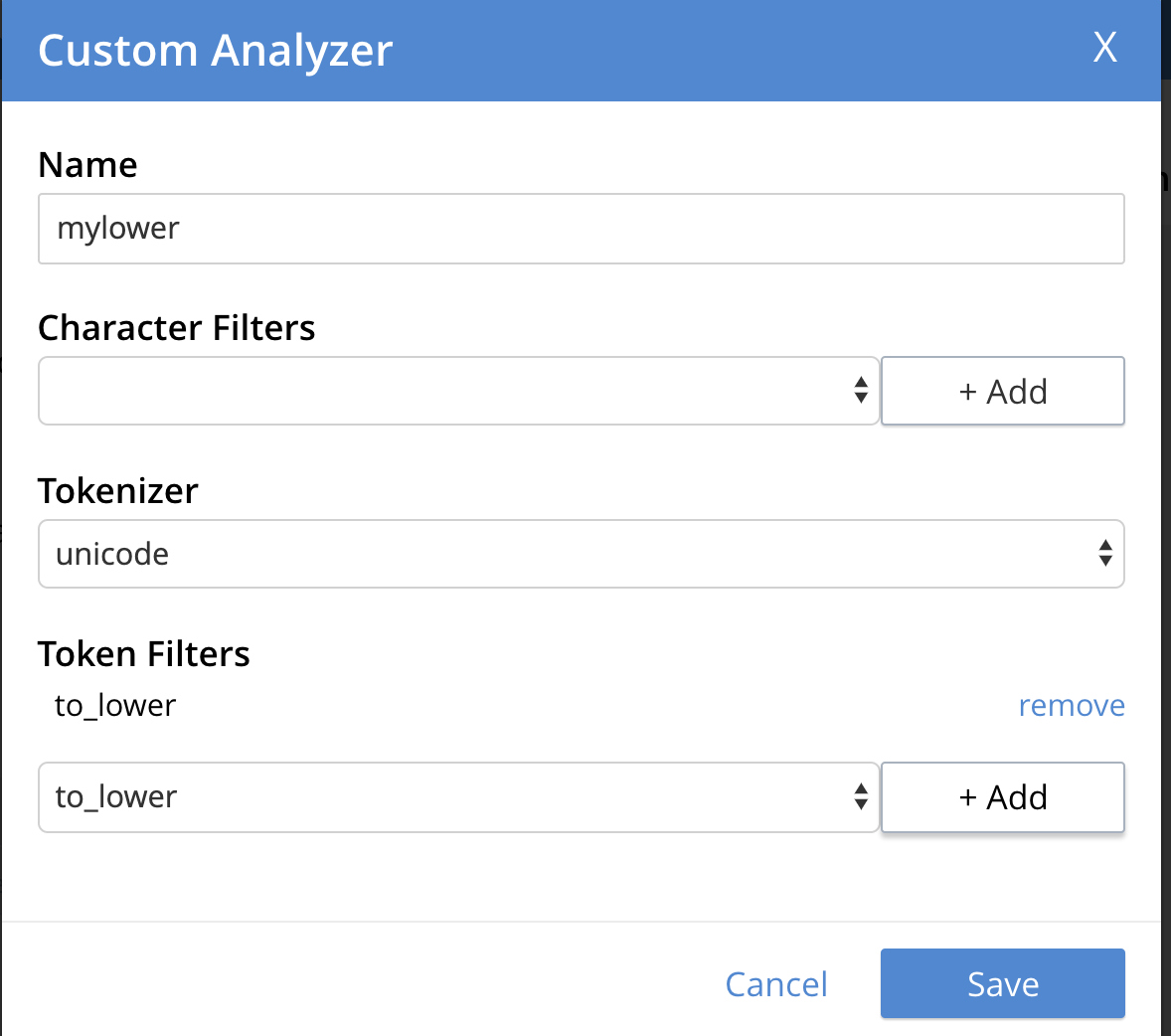
기본 표준 분석기는 모든 토큰을 낮추므로 모든 "joe"를 찾을 수 있습니다: JOE, joe, Joe, JOe 등입니다. 사용자 정의 분석기를 정의하고 토큰을 소문자로 바꾸도록 특정 지침을 제공할 수 있습니다. 다음은 예시입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"mapping": { "analysis": { "analyzers": { "mylower": { "token_filters": [ "to_lower" ], "tokenizer": "unicode", "type": "custom" } } }, |
UI에서 추가하는 방법은 다음과 같습니다. 자세한 블로그 보기 Couchbase 전체 텍스트 검색 색인을 사용자 정의하는 8가지 방법 를 참조하여 FTS 지수를 사용자 지정하는 다양한 방법에 대해 자세히 알아보세요.