Couchbase 7.2의 일부로 새로운 시계열 기능을 출시하게 되어 기쁘게 발표합니다. 이 기능은 데이터 증가에 따라 수평적으로 확장하도록 설계된 강력한 Couchbase 분산 데이터베이스 아키텍처를 기반으로 구축되었으며, 기본 제공되는 이중화 및 고가용성을 제공합니다. 즉, 비즈니스가 성장하고 시계열 데이터 요구가 증가함에 따라 Couchbase는 이러한 요구를 충족하기 위해 손쉽게 확장할 수 있으므로 모든 규모의 비즈니스에 이상적인 솔루션이 될 수 있습니다.
시계열 데이터를 관리하는 이 혁신적인 새 기술은 Couchbase 사용자에게 완전히 새로운 가능성의 세계를 열어줍니다. Couchbase SQL++와 SDK를 사용해 방대한 양의 시계열 데이터를 저장하고 분석할 수 있습니다. 이를 통해 사용자는 기존의 지식과 인프라를 활용할 수 있으므로 데이터 추세를 쉽게 탐색할 수 있는 강력한 인사이트를 쉽게 설정하고 활용할 수 있습니다.
시계열의 주요 이점
시계열 데이터는 Couchbase 멀티 모델 데이터베이스의 JSON 문서에 저장됩니다. 빠른 데이터 검색과 짧은 지연 시간을 위해 동일한 고성능의 고급 캐싱을 제공합니다. Couchbase 쿼리 SQL++ 및 인덱스 서비스는 데이터 검색 기능을 향상시켜 복잡한 분석 쿼리 사용 사례를 가능하게 합니다.
Couchbase의 시계열 데이터 지원은 이러한 추가적인 이점을 제공합니다:
-
- 대량의 시계열 데이터 포인트를 위한 효율적인 저장 공간
- 타임스탬프 데이터 포인트에 최적화된 데이터 구조 저장소
- 새로운 고급 시계열 쿼리 기능
- 낮은 인덱스 스토리지 요구 사항
시계열 사용 사례의 예
금융 트레이딩 - 금융 트레이딩은 주가, 환율, 원자재 가격 등 대량의 실시간 데이터를 분석하는 데 의존합니다. 시계열 데이터 분석은 트레이더가 추세를 파악하고 매매에 대한 정보에 입각한 결정을 내리는 데 도움이 될 수 있습니다.
사물 인터넷(IoT) 모니터링 - IoT 디바이스는 온도 판독값, 에너지 소비량, 센서 데이터 등 대량의 시계열 데이터를 생성합니다. 이 데이터를 실시간으로 분석하여 이상 징후를 감지하고 장비 고장이 발생하기 전에 예측할 수 있습니다.
예측적 유지 관리 - 많은 산업에서 고가의 장비와 기계에 의존하고 있으며, 다운타임은 많은 비용을 초래할 수 있습니다. 조직은 센서 및 기타 소스의 시계열 데이터를 분석하여 장비가 고장날 가능성이 있는 시기를 예측하고 유지보수 일정을 사전에 예약하여 다운타임을 최소화하고 효율성을 극대화할 수 있습니다.
카우치베이스 시계열의 주요 기능
카우치베이스에 시계열 데이터를 저장하고, SDK/SQL++를 사용해 로드하고, 글로벌 보조 인덱스의 고급 분석 쿼리 기능을 통해 일반 JSON 문서와 동일한 방식으로 데이터를 쿼리/분석할 수 있습니다.
스토리지 효율성
시계열 데이터 세트는 일반적으로 매우 크며, 각 데이터 요소는 타임스탬프, 값, 세분성 및 기타 관련 정보와 같은 속성으로 구성됩니다. 효율적인 스토리지는 분석을 위해 데이터를 얼마나 빨리 쿼리할 수 있는지를 결정할 수 있기 때문에 매우 중요합니다.
카우치베이스 시계열은 스토리지 효율성을 개선하기 위해 두 가지 사양을 사용합니다.
데이터 요소에 배열 사용 - 시계열 데이터는 본질적으로 일련의 데이터 포인트입니다. 이러한 데이터 요소는 시간 및 값 또는 데이터 요소가 수집된 시간과 관련된 기타 속성과 같은 공통 구조를 공유합니다.
배열을 사용하여 주어진 범위에 대한 데이터 포인트 집합을 저장하면 각 개별 데이터 포인트를 데이터베이스에 별도의 문서로 저장하는 것보다 저장 비용을 크게 절감할 수 있습니다.
배열 위치 사용 - 또한 데이터 포인트 배열 요소에는 연결된 필드 이름이 없으며 대신 배열에서 요소의 위치에 따라 달라집니다. 이 예에서 배열의 세 요소는 관찰 날짜, 시초가, 종가입니다.
|
1 2 3 4 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] } |
EPOCH 시간 사용 - 에포크 시간 를 ISO 날짜 문자열 대신 사용하여 각 데이터 요소의 크기를 줄이고 처리 시간을 개선합니다.
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
새로운 _timeseries 함수로 쿼리 최적화
카우치베이스 시계열 기능에는 새로운 _timeseries 함수입니다. 이 기능은 여러 가지 용도로 사용됩니다:
-
- 에서 시계열 개체를 동적으로 생성합니다. ts_data 배열 배열
- UNNEST와 함께 사용할 때 결과를 효율적으로 스트리밍하고 응답 시간과 메모리 사용량을 최적화합니다.
- ts_interval 매개변수를 사용하면 각 데이터 포인트에 대한 타임스탬프를 자동으로 생성할 수 있습니다.
- 타임스탬프당 여러 데이터 포인트 세트 대신 불규칙한 시계열 데이터 포인트 간격에 대한 고급 시계열 사용 사례를 지원합니다.
참고하세요. 카우치베이스 시계열 문서 에서 자세한 내용을 확인하세요.
최적화된 인덱스 스토리지
각 데이터 포인트가 JSON 문서 내의 배열에 요소로 저장되는 Couchbase의 시계열 데이터 저장 방식 덕분에 데이터베이스 인덱싱 전략을 최적화할 수 있습니다. 특히, 각 문서에는 배열에 있는 모든 데이터 포인트의 시작 시간과 종료 시간이 모두 포함되어 있으므로 각 문서에 대해 단일 인덱스 정의를 만들 수 있습니다. 즉, 수백만 개의 데이터 포인트가 포함된 대규모 시계열 데이터 세트의 경우에도 데이터 포인트당 하나의 문서가 아닌 몇 개의 문서에 데이터를 저장할 수 있습니다.
예를 들어, 100만 개의 데이터 포인트가 있는 시계열 데이터 집합은 각각 1,000개의 문서에 저장할 수 있다고 가정합니다. ts_data 배열은 최대 1,000개의 데이터 요소를 저장할 수 있으며, 문서 크기는 20MB Couchbase JSON 문서 제한 이하로 유지됩니다. 이렇게 하면 데이터를 저장하는 데 필요한 문서 수가 줄어들 뿐만 아니라 인덱스 크기도 작아져 데이터베이스 성능이 향상되고 디스크 공간 요구 사항도 줄어듭니다.
즉, 시계열 데이터를 JSON 문서 내에 배열로 저장하는 Couchbase의 기능을 활용하면 인덱싱 전략을 최적화하여 필요한 문서 수를 크게 줄이고 인덱스 크기를 줄여 쿼리 성능을 높이고 스토리지 리소스를 보다 효율적으로 사용할 수 있습니다.
|
1 |
CREATE INDEX ix1 ON docs(ticker, ts_end, ts_start); |
데이터 보존
시계열 문서는 Couchbase에서 표준 JSON 문서로 저장됩니다. 따라서 데이터 로드 프로세스 중에 동일한 TTL(Time-To-Live)을 설정할 수 있습니다.
|
1 2 3 4 5 |
/* The document will be automatically removed in 30 days */ INSERT INTO coll1 (KEY, VALUE) VALUES ("stock:XYZ:d1", {"ticker":"XYZ",..}, {"expiration":60*60*24*30}); |
연습 예시
이제 기능에서 정의한 대로 시계열 데이터 모델을 사용하여 실제 주가 데이터 집합을 Couchbase에 로드하는 과정을 살펴보겠습니다.
위에서 설명한 것처럼 Couchbase 시계열 기능을 사용하려면 이 특정 형식의 JSON 문서가 필요합니다:
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
자체 시계열 데이터를 위 형식으로 변환해야 하는 경우 아래 단계를 따르세요.
여기에 사용된 데이터 세트는 2013~2015년 XYZ Inc 주가에 대한 것입니다.
XYZ_data.csv
|
1 2 3 4 |
date,open,high,low,close,volume,Name 2013-02-08,27.285,27.595,27.24,27.295,5100734,XYZ 2013-02-11,27.64,27.95,27.365,27.61,8916290,XYZ 2013-02-12,27.45,27.605,27.395,27.545,3866508,XYZ |
Couchbase 시계열 데이터 구조로 데이터 마이그레이션
- CSV 파일을 Couchbase 컬렉션에 로드합니다:
|
1 |
cbimport csv --infer-types -c https://<cluster>:8091 -u <login> -p <password> -d 'file://XYZ_data.csv' -b 'ts' --scope-collection-exp "s1.c1" -g "#UUID#" |
가져오기는 컬렉션에 JSON 문서를 생성합니다. c1 를 입력합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "c1": { "Name": "XYZ", "close": 55.99, "date": "2016-05-25T00:00:00.000Z", "high": 56.69, "low": 55.7699, "open": 56.47, "volume": 9921707 } }, { "c1": { "Name": "XYZ", "close": 31.075, "date": "2013-06-11T00:00:00.000Z", "high": 31.47, "low": 30.985, "open": 31.15, "volume": 5540312 } }, … |
2. SQL++를 사용하여 컬렉션 변환 c1 를 시계열 데이터 구조에 삽입한 다음 컬렉션에 삽입합니다. c3:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO ts.s1.c3 (KEY _k, VALUE _v) SELECT "stock:XYZ:2013" _k, {"ticker": a.Name , "ts_start" : MIN(STR_TO_MILLIS(a.date)), "ts_end" : MAX(STR_TO_MILLIS(a.date)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.date), a.close]) } _v FROM ts.s1.c1 a WHERE a.date BETWEEN "2013-01-01" AND "2013-12-31" GROUP BY a.Name; |
SQL++는 선택 항목 삽입 를 호출하여 Couchbase 시계열 처리에 필요한 구조를 가진 단일 문서를 생성합니다. 참고로 ts_data 배열에는 2013년 일일 종가 데이터 포인트 전체가 포함됩니다.
3. 2014년과 2015년에 대해 삽입/선택을 반복합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[ { "id": "stock:XYZ:2013", "ticker": "XYZ", "ts_start": 1387497600000, "ts_end": 1365465600000, "ts_data": [ [ 1387497600000, 38.67 ], [ 1380585600000, 36.21 ], ...] }, { "id": "stock:XYZ:2014", "ticker": "XYZ", "ts_start": 1413331200000, "ts_end": 1402444800000, "ts_data": [ [ 1413331200000, 42.59 ], [ 1399507200000, 36.525], ...] }, { "id": "stock:XYZ:2015", "ticker": "XYZ", "ts_start": 1444780800000, "ts_end": 1436313600000, "ts_data": [ [ 1444780800000, 62.92 ], [ 1421280000000, 46.405], ...] } ] |
데이터 수집 전략
시계열 JSON 문서의 증분 로딩에는 몇 가지 시나리오가 있을 수 있습니다.
-
- 데이터 포인트 범위를 새 JSON 문서로 추가하기 - 이 시나리오에서는 위의 SQL++ INSERT를 사용할 수 있습니다. 데이터 포인트 범위가 기존 문서와 겹치지 않는지 확인하기만 하면 됩니다.
- 다음에 다양한 데이터 포인트 추가 기존 JSON 문서 - 여기에는 두 가지 옵션이 있습니다:
- 삽입/선택에서와 같이 UPSERT/SELECT를 사용하여 전체 문서를 교체합니다.
- 새 항목 데이터 포인트만 추가하려면 Couchbase SDK를 사용하세요.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Initialize the Couchbase cluster and bucket objects Cluster cluster = CouchbaseCluster.create("<cluster>"); Bucket bucket = cluster.openBucket("<your_bucket>"); // Specify the document ID and the sub-document path to update String docId = "<doc_id>"; // eg. "stock:XYZ:2015" String path = "a.ts_data[-1]"; // -1 specifies the last element of the array // Create a JSON object representing the new array element to add JsonObject newElement = JsonObject.create() .put("0", "2015-12-31") .put("1", 300); // Use the sub-document API to update the array JsonDocument doc = bucket.get(docId); if (doc != null) { bucket.mutateIn(docId) .arrayAppend(path, newElement) .execute(); } |
시계열 데이터 쿼리
데이터를 쿼리하기 전에 인덱스를 만들어야 합니다. 문서가 몇 개 밖에 없으므로 반드시 필요한 것은 아니지만, 각 문서가 일일 주가의 전체 연도로 구성되어 있더라도 인덱스를 만들어야 합니다.
|
1 |
CREATE INDEX ix1 ON c3(ticker, ts_end, ts_start); |
다음으로 쿼리를 실행할 데이터 범위를 정의합니다. 여기에서는 2013-01-01과 2015-12-31의 시작 및 종료 에포크 시간, 두 개의 요소로 구성된 배열을 정의합니다.
|
1 |
\set -$ts_ranges [1682947800000,1685563200000]; |
시계열 데이터 요소 보기
사용 _timeseries 함수는 위에서 설명한 대로 작동합니다:
|
1 2 3 |
SELECT t.* FROM c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND (d.ts_start <= $ts_ranges[1] AND d.ts_end >= $ts_ranges[0]); |
결과:
|
1 2 3 4 5 6 |
[ { "_t": 1413331200000, "_v0": 42.59 }, { "_t": 1399507200000, "_v0": 36.525}, { "_t": 1392854400000, "_v0": 37.79 }, { "_t": 1395100800000, "_v0": 39.82 }, { "_t": 1410307200000, "_v0": 41.235}, … ] |
SQL++ 창 함수로 시계열 데이터 보기
이제 전체 데이터 집합에 액세스할 수 있게 되었으므로 Couchbase SQL++ 윈도우 함수를 사용하여 몇 가지 고급 집계 함수를 실행할 수 있습니다. 이 쿼리는 주식의 일평균과 7일 이동 평균을 반환합니다.
|
결과:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
[ { "day": "2014-01-02T00:00:00Z", "dayavg": 39.12, "sevendaymovavg": 39.12 }, { "day": "2014-01-03T00:00:00Z", "dayavg": 39.015, "sevendaymovavg": 39.067499999999995 }, { "day": "2014-01-06T00:00:00Z", "dayavg": 38.715, "sevendaymovavg": 38.949999999999996 }, { "day": "2014-01-07T00:00:00Z", "dayavg": 38.745, "sevendaymovavg": 38.89875 }, { "day": "2014-01-08T00:00:00Z", "dayavg": 38.545, "sevendaymovavg": 38.827999999999996 }, .. ] |
시계열 데이터에 SQL++ 차트 사용
이 예에서는 카우치베이스 시계열 기능과 차트 기능을 사용하여 빠른(5일) 이동 평균과 느린(30일) 이동 평균을 추적하여 인기 있는 트레이딩 전략을 추적합니다.
|
1 2 3 4 5 6 7 8 9 |
SELECT MILLIS_TO_TZ(day*86400000,"UTC") AS day, dayavg , AVG(dayavg) OVER (ORDER BY day ROWS 5 PRECEDING) AS fma, AVG(dayavg) OVER (ORDER BY day ROWS 30 PRECEDING) AS sma FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' <span style="font-weight: 400"> AND (d.ts_start <= $ts_ranges[</span><span style="font-weight: 400">1</span><span style="font-weight: 400">] AND d.ts_end >= $ts_ranges[</span><span style="font-weight: 400">0</span><span style="font-weight: 400">])</span> GROUP BY IDIV(t._t,86400000) AS day LETTING dayavg = AVG(t._v0); |
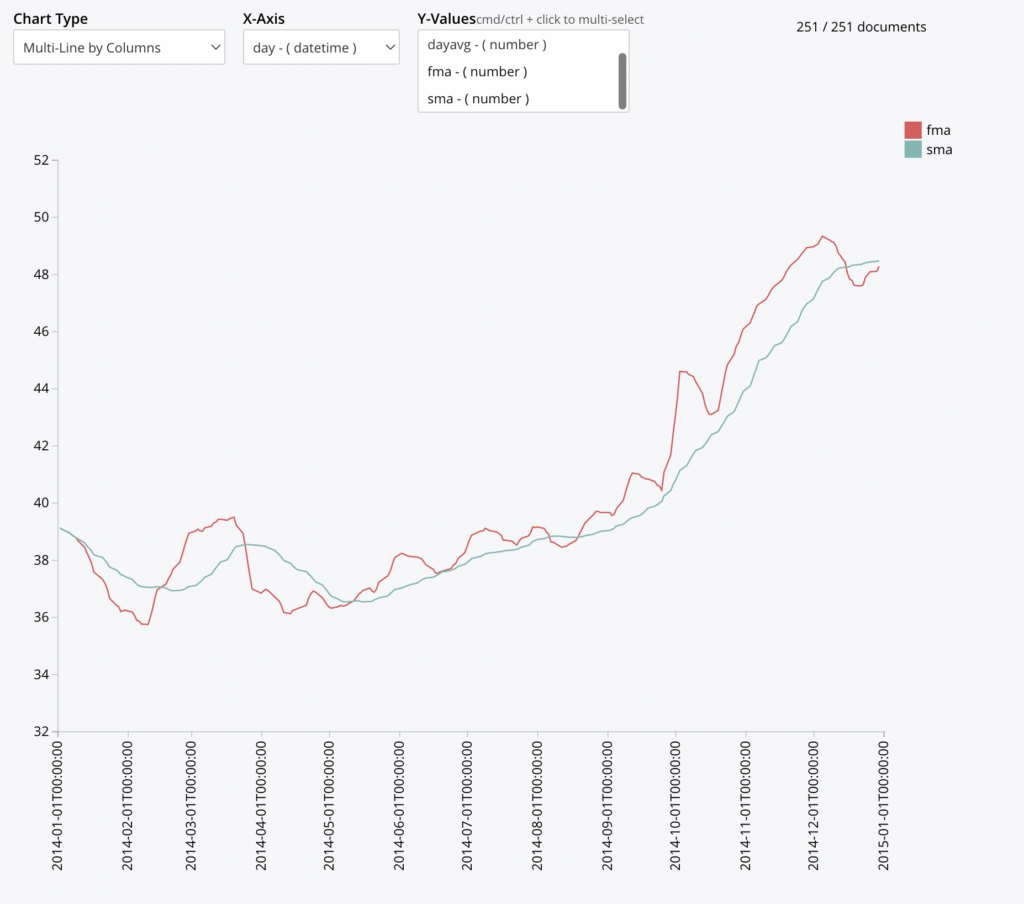
이 전략의 기본 개념은 단기 추세(FMA)가 장기 추세(SMA)의 위 또는 아래를 교차하는 시점을 파악하는 것입니다. FMA가 SMA를 넘으면 매수 신호로 간주하고, 반대로 FMA가 SMA를 밑돌면 매도 신호로 간주합니다.
시계열 데이터에 SQL++ 일반 테이블 표현식 사용
이 분석은 상대 강도 지수, 즉 주가 움직임의 속도와 변화를 계산하여 주식이 과매수 또는 매도된 시점을 식별합니다. RSI 값이 70을 초과하면 주식이 과매수되어 조정이 필요하다는 의미일 수 있습니다. 반대로 RSI가 30 미만이면 주식이 과매도 상태이며 반등할 때임을 나타낼 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
WITH price_change AS ( SELECT t._t as date, t._v0 AS price, LAG(t._v0, 1) OVER (ORDER BY t._t) AS prev_price, ROW_NUMBER() OVER (ORDER BY t._t) AS rn FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND ( $ts_ranges[0] BETWEEN d.ts_start AND d.ts_end OR (d.ts_start BETWEEN $ts_ranges[0] AND $ts_ranges[1] AND d.ts_end BETWEEN $ts_ranges[0] AND $ts_ranges[1] ) OR $ts_ranges[1] BETWEEN d.ts_start AND d.ts_end ) ), gain_loss AS ( SELECT pc.date, pc.price, pc.prev_price, CASE WHEN pc.price > pc.prev_price THEN pc.price - pc.prev_price ELSE 0 END AS gain, CASE WHEN pc.price < pc.prev_price THEN pc.prev_price - pc.price ELSE 0 END AS loss, pc.rn FROM price_change pc ), avg_gain_loss AS ( SELECT gl.date, AVG(gl.gain) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_gain, AVG(gl.loss) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_loss, gl.rn FROM gain_loss gl ), rsi AS ( SELECT agl.date, 100 - (100 / (1 + (agl.avg_gain / agl.avg_loss))) AS rsi_val FROM avg_gain_loss agl WHERE agl.rn >= 14 ), buy_sell_signals AS ( SELECT rsi.date, rsi.rsi_val, CASE WHEN rsi.rsi_val < 30 THEN 'buy' WHEN rsi.rsi_val > 70 THEN 'sell' END AS signal FROM rsi ) SELECT * FROM buy_sell_signals bss WHERE bss.signal IS NOT NULL; |
결과:
|
||
주요 내용
데이터 스토리지 - 카우치베이스 시계열의 전체 데이터 저장량은 배열에 패킹할 데이터 포인트의 수에 따라 달라집니다. 시간, 일, 월 단위로 분석하는 경우 기간에 따라 데이터 요소를 패킹합니다. 시계열의 시간 요소를 도출할 수 있는 일반 시계열을 사용하는 경우, 따라서 에포크 시간 요소를 저장할 필요가 없는 경우에도 저장 공간을 더 줄일 수 있습니다.
TTL을 사용한 데이터 요소 및 데이터 보존 - Couchbase에서 JSON 문서의 최대 크기는 20MB입니다. 이는 많은 수의 데이터 요소를 시계열 배열에 담을 수 있음을 의미할 수 있지만, Time To Live 설정은 배열 요소 수준이 아니라 문서 수준이라는 점에 유의해야 합니다.
데이터 수집 - 데이터 수집 전략은 애플리케이션이 담당합니다. 시계열 데이터 요소를 배열에 패킹하는 방법과 배열 크기입니다. 즉, 기존 문서에 추가할지 아니면 새 문서를 시작할지 결정해야 합니다.
자세한 내용은 카우치베이스 시계열 문서.