이 블로그의 핵심은 관계형 데이터를 Couchbase로 쉽게 마이그레이션하여 TCO를 낮추고 데이터 플랫폼이 빠른 속도로 진행되는 릴리즈 주기에 대응할 수 있도록 하는 방법을 알려드리는 것입니다! 마이그레이션하는 동안 범위와 컬렉션을 사용해 이미 구성한 개별 이름/키스페이스를 그대로 유지할 수도 있습니다. 이 블로그는 다른 블로그에서 설명한 새로 출시된 기능과 최근 업데이트 내용을 다소 통합한 것이지만, 다른 블로그와 달리 관계형 데이터를 Couchbase로 마이그레이션하는 방법을 몇 가지 예시를 들어 설명합니다.
Couchbase의 훌륭한 점 중 하나는 커뮤니티의 요구에 진정으로 귀를 기울이고 고객에게 최상의 경험을 제공하기 위해 제품을 지속적으로 개발한다는 점입니다. 이 블로그는 따라 해보고 싶으신 분들을 위해 '실습'으로 작성했지만, 추출 단계를 건너뛰고 제가 제공한 TSV로 작업하실 수도 있습니다!
이 과정을 따라가려면 데이터를 추출할 RDBMS, 파이썬 인터프리터, Couchbase 서버(Docker, VM, 물리적 등)가 전제 조건이 필요합니다.
데모 데이터베이스에 온라인 예제를 사용하겠습니다. Linked 여기 는 고객, 상담원, 주문이라는 세 개의 테이블이 있는 샘플 데이터베이스입니다.
새로운 범위 및 컬렉션 기능을 사용하여 테이블 구조를 모방하여 데이터를 Couchbase로 마이그레이션하는 것은 정말 쉽습니다. 먼저 논리적 저장 공간이 필요한데, 이 예에서는 데이터베이스당 하나의 버킷을 사용하므로 버킷을 하나만 만들면 됩니다. 스키마는 스코프에 매핑되므로 하나의 스코프만 만들면 됩니다. 마지막으로, 테이블은 각각 같은 이름의 컬렉션에 매핑되므로 총 3개의 컬렉션이 생성됩니다.
버킷, 범위 및 컬렉션 만들기:
여기에는 다양한 옵션이 있습니다. SDK, REST API, Couchbase CLI(Couchbase 셸도 잊지 마세요), 웹 GUI가 있습니다. 저는 REST API를 사용하려고 하는데, 명령줄에서 액세스할 수 있고 아무것도 설치할 필요가 없다는 것이 장점입니다! REST 인터페이스에 익숙하지 않은 분들을 위해 문서 여기 에서 다른 대체 방법을 설명합니다.
아래 단계에서는 버킷, 범위 및 컬렉션을 설정하는 데 필요한 명령을 지정합니다:
다음 두 명령을 실행하여 데이터 버킷과 범위를 만드세요:
|
1 2 |
curl -X POST -u 관리자:비밀번호 http://127.0.0.1:8091/풀/기본값/버킷 -d 이름=마이그레이션 -d 버킷 유형=카우치베이스 -d 램쿼터MB=100 curl -X POST -u 관리자:비밀번호 <a href="http://127.0.0.1:8091/pools/default/buckets/migration/collections">http://127.0.0.1:8091/풀/기본값/버킷/마이그레이션/컬렉션</a> -d 이름=참조 |
이제 테이블 데이터를 매핑할 세 개의 컬렉션을 만듭니다:
|
1 |
curl -u 관리자:비밀번호 -X POST http://localhost:8091/풀/기본값/버킷/마이그레이션/컬렉션/참조 -d 이름=$TABLE_NAME |
필요에 따라 $TABLE_NAME 변수를 변경하여 상담원, 주문 및 고객 컬렉션을 각각 생성하기만 하면 됩니다.
(부록에 이러한 API에 대한 문서 페이지 링크가 있습니다).
모든 것이 생성되면 버킷 섹션으로 이동하여 생성한 버킷의 이름 옆에 있는 "범위 및 컬렉션" 링크를 클릭합니다(제 버킷의 이름은 마이그레이션입니다). 그런 다음 생성한 범위를 확장하면 생성한 세 개의 컬렉션을 볼 수 있습니다.
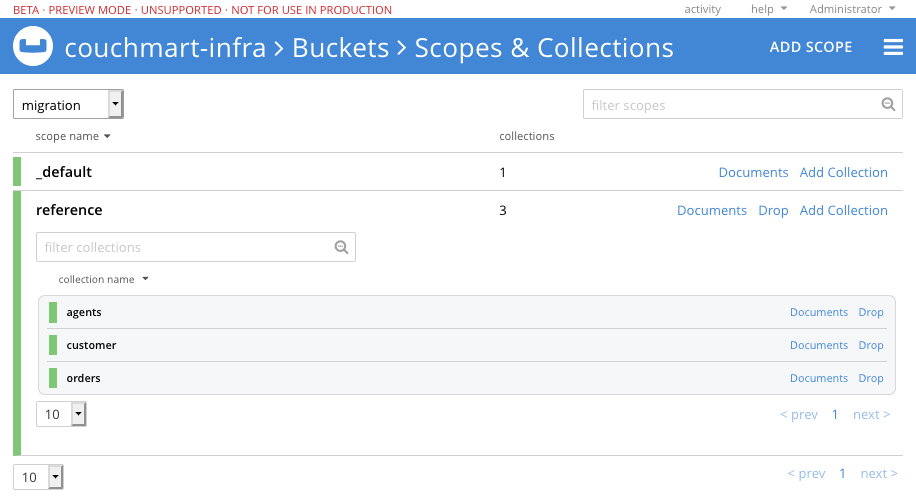
RDBMS에서 데이터 추출
이제 버킷, 범위 및 컬렉션이 준비되었으므로 관계형 데이터를 내보낼 준비가 되었습니다. 저는 짧은 스크립트 를 실행하여 샘플 MySQL 데이터베이스에 저장된 데이터를 가져오기 도구에서 지원하는 TSV로 추출하거나 직접 데이터를 내보낼 수 있습니다. 데이터베이스 설정이 완료되면 스크립트를 실행하고 구성한 사용자 아이디와 비밀번호를 사용하도록 변수를 변경하기만 하면 됩니다. 스크립트를 실행하면 샘플 데이터베이스의 각 테이블에 있는 데이터가 포함된 3개의 .tsv 파일이 생성됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/usr/bin/python3 가져오기 하위 프로세스 가져오기 json 가져오기 re sql_commands='{ "commands": { "agents": "SELECT * FROM agents;", "customer": "SELECT * FROM customer", "orders": "SELECT * FROM orders;" } }' db_name = "sample" 사용자 이름 = "root" 비밀번호 = "rootroot" sql_commands = json.로드(sql_commands) 에 대한 command_name in sql_commands["명령"]: 인쇄("명령 실행 중입니다: " + command_name) sql_statement = "--execute={0}".형식(sql_commands["명령"][command_name]) 명령 = 하위 프로세스.실행(["/usr/local/mysql/bin/mysql", db_name, "--user={0}".형식(사용자 이름), "--password={0}".형식(비밀번호), sql_statement], 캡처_출력=True) 와 함께 열기(command_name+"_out.tsv", 'w') as 명령_출력_파일: command_without_trailing_white_space = re.sub(b" +\\t", b'\\t', 명령.stdout) 명령_출력_파일.쓰기(command_without_trailing_white_space.디코딩('ascii')) |
가져오기 부분만 작업하는 경우에는 이 예제를 사용하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
에이전트 코드 에이전트_이름 WORKING_AREA 커미션 PHONE_NO 국가 A007 라마순다르 방갈로르 0.15 077-25814763 A003 Alex 런던 0.13 075-12458969 A008 Alford 신규 York 0.12 044-25874365 A011 Ravi Kumar 방갈로르 0.15 077-45625874 A010 산타쿠마르 첸나이 0.14 007-22388644 A012 Lucida San Jose 0.12 044-52981425 A005 Anderson 브리즈번 0.13 045-21447739 A001 서브바라오 방갈로르 0.14 077-12346674 A002 Mukesh 뭄바이 0.11 029-12358964 A006 McDen 런던 0.15 078-22255588 A004 Ivan 토렌토 0.15 008-22544166 A009 벤자민 햄스헤어 0.11 008-22536178 |
Couchbase로 데이터 가져오기
다양한 기능을 갖춘 가져오기 도구인 cbimport를 사용하면 다양한 형식의 데이터를 정말 쉽게 가져올 수 있습니다. 최근에는 일부 가져오기 기능을 웹 GUI에 구현하여 프로세스에 더욱 쉽게 접근할 수 있도록 했습니다. 아래는 웹 가이드 가져오기 도구의 스크린샷입니다. 여기로 이동하려면 Couchbase 웹 GUI에 로그인한 다음 "문서" -> "가져오기"로 이동합니다.
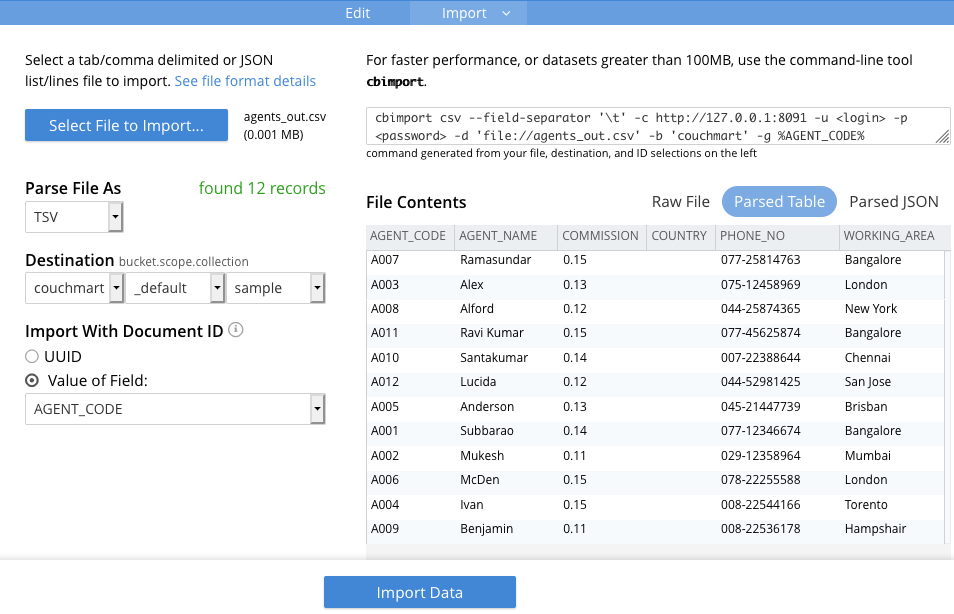
여기서는 '가져올 파일 선택' 버튼을 사용하여 TSV를 가져오려고 하는데, 파일을 업로드할 때 실제로 많은 필드가 자동으로 채워지는 것을 확인할 수 있습니다. 가져온 데이터를 살펴보고 이전 관계형 구조를 고려하여 예상한 것과 일치하는지 확인합니다. 데이터를 가져오기 위해 완료해야 할 몇 가지 간단한 단계만 남았습니다.
먼저, 데이터를 가져올 컬렉션을 지정합니다(예: agents_out.tsv는 'agents' 컬렉션에 매핑). 또한 이전 관계형 데이터베이스의 개별 행을 Couchbase의 문서 ID에 대응시킬 것입니다. 이 작업은 '문서 ID로 가져오기' 섹션을 사용하여 가져오기 도구로 쉽게 수행할 수 있습니다. 저는 데이터를 가져올 때마다 관계형 데이터의 기본 키를 Couchbase의 문서 ID로 사용했는데, 이는 컬렉션의 각 키가 고유해야 하므로 매우 유용합니다. 예를 들어 에이전트_out.tsv에서는 기본 키 "AGENT_CODE"를 사용했습니다. 상담원, 주문, 고객 등 각 .tsv에 대해 이 단계를 수행합니다.
요약하자면 다음과 같은 작업을 수행했습니다:
- 레거시 데이터베이스에서 TSV로 데이터 내보내기
- 가져오려는 테이블을 기반으로 범위 및 컬렉션을 만들었습니다.
- 데이터 마이그레이션 도구를 사용하여 범위 내에서 특정 컬렉션으로 데이터를 가져옵니다.
이제 Couchbase에 데이터를 가져왔으니 데이터를 쿼리하는 새로운 방법을 배워야 하나요? 그와는 정반대로, Couchbase 웹 GUI로 이동하여 새로 가져온 데이터 중 일부를 N1QL을 사용하여 쿼리해 보는 것은 어떨까요? SQL++와 호환되며 이전에 SQL 쿼리를 작성해 본 적이 있는 사용자라면 누구나 쉽게 사용할 수 있습니다.문이 열렸으니 들어오세요! 쿼리를 쉽게 작성할 수 있도록 도와드릴 뿐만 아니라, 저희의 인덱스 어드바이저 서비스를 클릭하고 수행하려는 쿼리를 입력하기만 하면 어드바이저가 인덱스를 제안합니다. JOIN도 지원합니다:
|
1 2 3 4 |
선택 주문.에이전트 코드, 주문.ORD_AMOUNT, 에이전트.에이전트_이름 FROM `빅 데이터`.참조.주문 as 주문 JOIN `빅 데이터`.참조.에이전트 as 에이전트 켜기 주문.에이전트 코드 = 메타(에이전트).id; |
Couchbase를 최대한 활용하기 위해 데이터를 모델링하는 방법에 대해 자세히 알아보려면 관계형에서 NoSQL로 전환하는 올바른 방향으로 나아가는 좋은 출발점이 될 것입니다, 데이터 모델링 가이드 확인.
범위와 컬렉션에 대해 자세히 알아보고 싶으신가요? Shivani의 블로그를 추천합니다.
부록:
- 다음 링크는 사용자에게 샘플 데이터베이스를 설정하는 방법을 정확하게 알려줍니다.
- 카우치베이스 도커 컨테이너
- 7.0 REST API - 범위 생성 문서
- 7.0 REST API 버킷 문서 만들기
- 7.0 REST API - 컬렉션 생성 문서