수많은 LLM이 출시되면서 많은 회사들이 이러한 모델의 추론 기능을 확장할 수 있도록 특수 하드웨어와 최적화를 통해 대규모 언어 모델의 추론 속도를 향상시키는 데 주력하고 있습니다. 이 분야에서 큰 성과를 거두고 있는 회사 중 하나는 다음과 같습니다. Groq.
이 블로그 포스팅에서는 Groq에 대해 알아보고, Groq의 빠른 LLM 추론 기능을 Couchbase Vector Search와 통합하여 빠르고 효율적인 RAG 애플리케이션을 만드는 방법을 살펴봅니다. 또한 OpenAI, Gemini와 같은 다양한 LLM 솔루션의 성능과 Groq의 추론 속도를 비교하는 방법도 살펴봅니다.
Groq이란 무엇인가요?
는 인공지능 추론 작업을 가속화하도록 설계된 애플리케이션별 집적 회로(ASIC)인 언어 처리 장치(LPU)의 개발로 유명한 미국의 인공지능 전문 기술 회사입니다. 특히 다음을 향상하도록 설계되었습니다. 대규모 언어 모델(LLM) 초저지연 추론 기능을 제공합니다. 개발자는 Groq Cloud API를 통해 Llama3 및 Mixtral 8x7B와 같은 최신 LLM을 애플리케이션에 통합할 수 있습니다.
이는 개발자에게 어떤 의미일까요? 빠른 추론이 필요한 실시간 AI 처리를 필요로 하는 애플리케이션에 Groq API를 원활하게 통합할 수 있다는 뜻입니다.
Groq API를 시작하는 방법
Groq API의 강력한 기능을 활용하려면 첫 번째 단계는 API 키를 생성하는 것입니다. 이는 Groq Cloud 콘솔에 가입하는 것으로 시작되는 간단한 프로세스입니다.
가입한 후, 가입을 완료하면 API 키 섹션으로 이동합니다. 여기에는 다음과 같은 옵션이 있습니다. 새 API 키 생성.

API 키를 사용하면 다음과 같은 최첨단 대규모 언어 모델을 통합할 수 있습니다. Llama3 그리고 믹스트랄 를 애플리케이션에 추가할 수 있습니다. 다음으로 Groq 채팅 모델을 다음과 통합할 예정입니다. LangChain 를 입력하세요.
Groq을 LLM으로 사용
LangChain의 LLM 공급자 중 하나로 Groq API를 활용할 수 있습니다:
|
1 2 3 4 5 6 |
from langchain_groq import ChatGroq llm = ChatGroq( temperature=0.3, model_name="mixtral-8x7b-32768", ) |
인스턴스화할 때 ChatGroq 객체에 온도와 모델 이름을 전달할 수 있습니다. 온도와 모델 이름은 현재 Groq에서 지원되는 모델.
Couchbase 및 Groq으로 RAG 애플리케이션 구축하기
목표는 사용자가 PDF를 업로드하고 채팅할 수 있는 채팅 애플리케이션을 만드는 것입니다. Couchbase Python SDK와 Streamlit을 사용하여 Couchbase VectorStore에 PDF 업로드를 용이하게 할 것입니다. 또한 Groq에서 제공하는 RAG를 사용하여 PDF에서 컨텍스트 기반 질문에 답변하는 방법을 살펴봅니다.
에 언급된 단계를 따를 수 있습니다. 이 튜토리얼 를 통해 Couchbase 벡터 검색으로 구동되는 Streamlit RAG 애플리케이션을 설정하는 방법에 대해 설명합니다. 이 튜토리얼에서는 Gemini를 LLM으로 활용합니다. Gemini의 구현은 Groq으로 대체하겠습니다.
Groq의 성능 비교
이 블로그에서는 다양한 LLM 제공업체의 성능도 비교합니다. 이를 위해 사용자가 RAG 애플리케이션에 사용할 LLM 제공업체를 선택할 수 있는 드롭다운을 만들었습니다. 이 예제에서는 Gemini, OpenAI, Ollama 및 Groq을 다양한 LLM 제공업체로 사용하고 있습니다. 이 경우 LangChain에서 지원하는 대규모 LLM 공급자 목록.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
st.sidebar.subheader("Select LLM") llm_choice = st.sidebar.selectbox( "Select LLM", [ "OpenAI", "Groq", "Gemini", "Ollama" ] ) if llm_choice == "Gemini": check_environment_variable("GOOGLE_API_KEY") llm = GoogleGenerativeAI( temperature=0.3, model="models/gemini-1.5-pro", ) llm_without_rag = GoogleGenerativeAI( temperature=0, model="models/gemini-1.5-pro", ) elif llm_choice == "Groq": check_environment_variable("GROQ_API_KEY") llm = ChatGroq( temperature=0.3, model_name="mixtral-8x7b-32768", ) llm_without_rag = ChatGroq( temperature=0, model_name="mixtral-8x7b-32768", ) elif llm_choice == "OpenAI": check_environment_variable("OPENAI_API_KEY") llm = ChatOpenAI( temperature=0.3, model="gpt-3.5-turbo", ) llm_without_rag = ChatOpenAI( temperature=0, model="gpt-3.5-turbo", ) elif llm_choice == "Ollama": llm = Ollama( temperature=0.3, model = ollama_model, base_url = ollama_url ) llm_without_rag = Ollama( temperature=0, model = ollama_model, base_url = ollama_url ) |
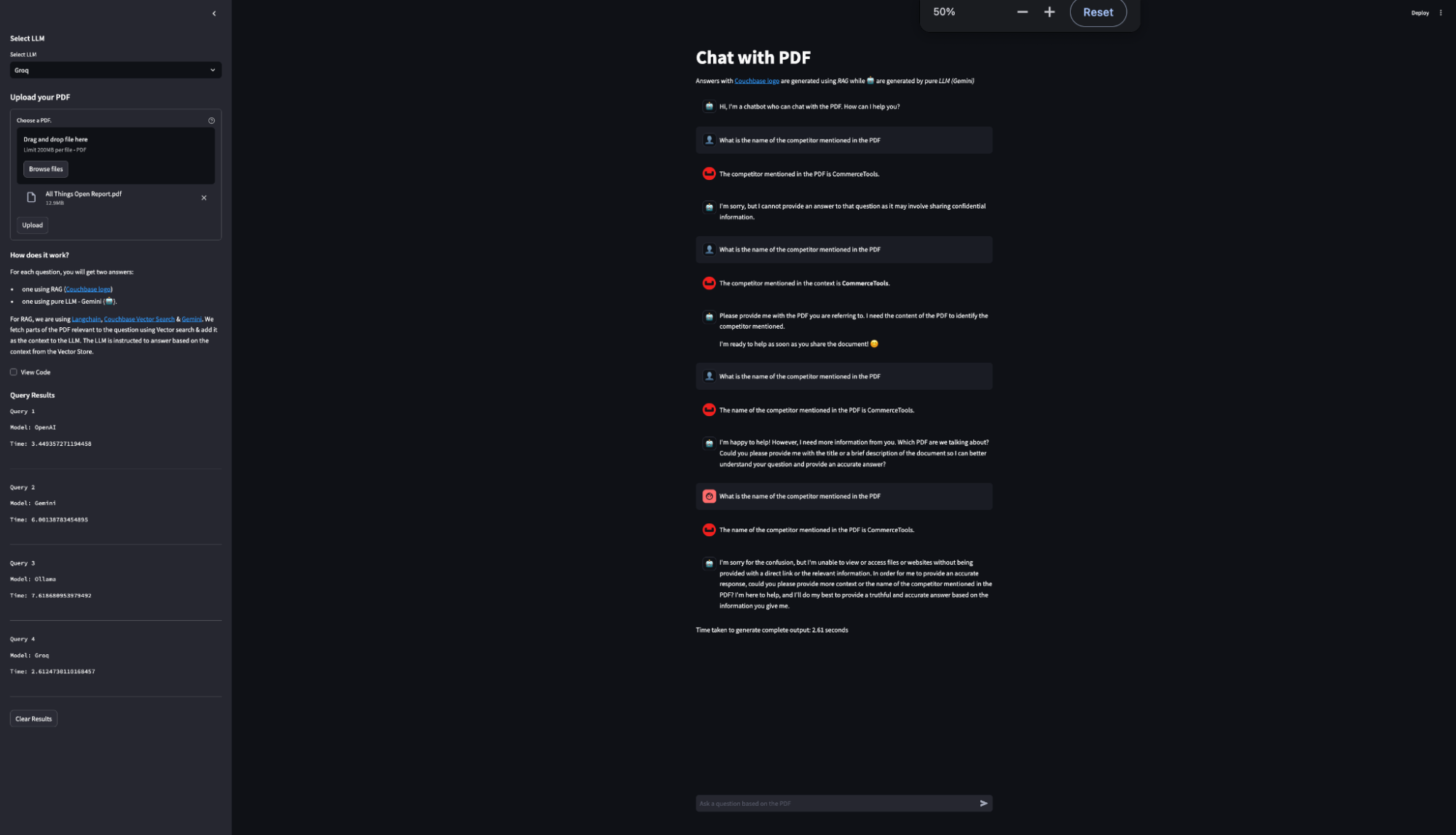
Groq의 빠른 추론 속도를 강조하기 위해 저희는 LLM 응답의 추론 시간을 계산하는 방법을 구축했습니다. 이는 각 응답 생성에 소요된 시간을 측정하고 기록합니다. 결과는 사이드바 테이블에 표시되어 사용된 모델과 각 쿼리에 소요된 시간을 OpenAI, Ollama, Gemini, Groq 등 다양한 LLM 제공업체와 비교하여 보여주며, 이러한 비교를 통해 Groq의 LLM이 가장 빠른 추론 시간을 일관되게 제공한다는 것을 알 수 있었습니다. 이 성능 벤치마크를 통해 사용자는 다양한 모델의 효율성을 실시간으로 확인할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
if question := st.chat_input("Ask a question based on the PDF"): # Start timing start_time = time.time() # Display user message in chat message container st.chat_message("user").markdown(question) # Add user message to chat history st.session_state.messages.append( {"role": "user", "content": question, "avatar": "👤"} ) # Add placeholder for streaming the response with st.chat_message("assistant", avatar=couchbase_logo): message_placeholder = st.empty() # stream the response from the RAG rag_response = "" for chunk in chain.stream(question): rag_response += chunk message_placeholder.markdown(rag_response + "▌") message_placeholder.markdown(rag_response) st.session_state.messages.append( { "role": "assistant", "content": rag_response, "avatar": couchbase_logo, } ) # stream the response from the pure LLM with st.chat_message("ai", avatar="🤖"): message_placeholder_pure_llm = st.empty() pure_llm_response = "" for chunk in chain_without_rag.stream(question): pure_llm_response += chunk message_placeholder_pure_llm.markdown(pure_llm_response + "▌") message_placeholder_pure_llm.markdown(pure_llm_response) st.session_state.messages.append( { "role": "assistant", "content": pure_llm_response, "avatar": "🤖", } ) # End timing and calculate duration end_time = time.time() duration = end_time - start_time # Display the time taken st.write(f"Time taken to generate complete output: {duration:.2f} seconds") st.session_state.query_results.append({ "model": llm_choice, "time": duration }) st.sidebar.subheader("Query Results") table_header = "| Model | Time (s) |\n| --- | --- |\n" # create table rows table_rows = "" for idx, result in enumerate(st.session_state.query_results, 1): table_rows += f"| {result['model']} | {result['time']:.2f} |\n" table = table_header + table_rows st.sidebar.markdown(table, unsafe_allow_html=True) if st.sidebar.button("Clear Results"): st.session_state.query_results = [] st.experimental_rerun() |
결과에서 볼 수 있듯이 Groq의 추론 속도는 다른 LLM 제공업체에 비해 가장 빠릅니다.
결론
LangChain은 AI 기반 애플리케이션을 구축하기 위해 벡터 저장소, 원하는 LLM을 위한 다양한 옵션을 제공하는 훌륭한 오픈 소스 프레임워크입니다. Groq은 가장 빠른 LLM 추론 엔진 중 하나로 선두를 달리고 있으며, 빠른 실시간 추론이 필요한 AI 기반 애플리케이션과 잘 어울립니다. 따라서 Groq과 Couchbase Vector Search의 빠른 추론 기능을 통해 프로덕션에 바로 사용할 수 있고 확장 가능한 RAG 애플리케이션을 구축할 수 있습니다.
-
- 지금 바로 카펠라 사용 시작하기무료로 제공
- 자세히 알아보기 벡터 검색
