내가 있는 동안 JDays 괴테보르그에서 열린 프레젠테이션에 참석했습니다. 아파치 제플린. 대화형 데이터 분석이 가능한 웹 기반 노트북입니다. 이미 Spark, Markdown, Angular, Elastic 등과 같은 많은 인터프리터를 지원합니다. 정말 Spark와 잘 통합되어 있습니다. 그리고 Couchbase에는 스파크 커넥터. 그리고 Zeppelin의 개발자들은 Spark 사용자가 자체 종속성을 사용하고 싶어할 것이라는 것을 알고 있었기 때문에 정말 쉽게 만들었습니다. 플러그인을 작성할 필요가 없을 정도로 쉽습니다. 하지만 최신 버전이 있어야 합니다.
아파치 제플린 빌드
최신 소스에서 빌드한 최신 버전(물론 '그렇게' 쉽지는 않습니다...). 빌드는 매우 간단합니다. repo를 실행하여 올바른 종속성(git, jdk, npm, libfontconfig, maven)이 있는지 확인한 다음 저장소 유형 안에 mvn clean package -DskipTests -Pbuild-distr. 이제 모든 것을 구축할 테니 커피를 마시거나 새로운 [...]를 가지고 놀기 좋은 시간입니다. 전체 텍스트 검색 아직 설치하지 않았다면 Couchbase 4.5에서 설치하세요).
마지막에 배포 빌드 양식 소스가 아래에 있어야 합니다. ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/에 저장됩니다.. 이제 실행하려면 다음과 같이 입력하기만 하면 됩니다. ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/bin/zeppelin-daemon.sh 시작. http://localhost:8080/ 으로 이동하면 다음과 같은 내용이 표시됩니다:
카우치베이스 스파크 커넥터 종속성 추가하기
이제 목표는 Spark 인터프리터에 올바른 종속성을 추가하는 것입니다. 인터프리터는 패드의 콘텐츠를 다른 것으로 변환하는 코드 조각입니다. 따라서 통역사 탭을 클릭합니다. 여기에 사용 가능한 통역사 목록이 표시됩니다. 편집을 클릭하여 스파크 통역사를 편집할 수 있어야 합니다.
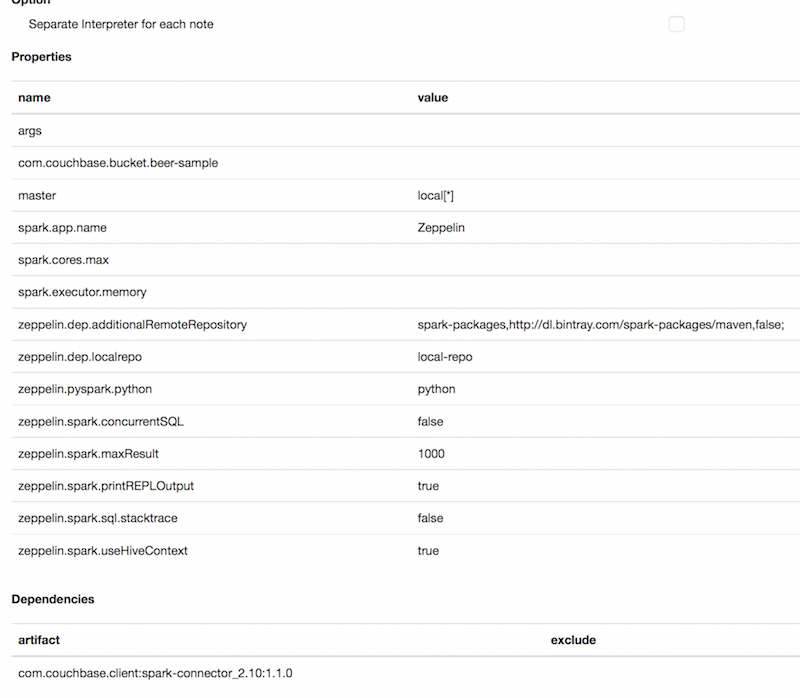
이 시점에서 해야 할 일이 두 가지 있습니다. 첫 번째 필수 단계는 카우치베이스 스파크 커넥터에 의존성을 추가하는 것입니다. 두 번째는 맥주 샘플 버킷에 액세스할 수 있는 속성을 추가하는 것입니다.
속성에서 다음을 추가합니다. com.couchbase.bucket.beer-sample 를 이름으로, 다른 것을 값으로 지정할 수 있습니다. 현재 새 빈 속성을 추가할 수 없는 버그가 있는 것 같습니다. 다음과 같이 수정할 수 있습니다.나중에 사용하세요.
종속성 아래에 다음을 추가합니다. com.couchbase.client:spark-connector_2.10:1.1.0 아티팩트 아래에 있습니다. 버튼을 클릭하는 것을 잊지 마세요.
스파크 패드 쓰기 시작
Couchbase에서 데이터를 읽거나 쓰기 시작할 수 있는 상태입니다. 저는 어떤 이유에서인지 항상 맥주 샘플을 가져옵니다. 그래서 우리가 할 수 있는 일은 거기서부터 읽기 시작하는 것입니다. 모든 맥주 문서에 대한 데이터 프레임을 쉽게 만들 수 있습니다. 기본적으로 read.couchbase 메서드는 기본 버킷에서 읽습니다. 따라서 맥주 샘플에서 읽기 위해 k/v 쌍 버킷/맥주 샘플을 포함하는 간단한 옵션 Map을 만듭니다. 또한 brewery가 아닌 맥주만 가져오도록 하기 위해 유형 필드에 필터를 추가할 수 있습니다. 이것이 모든 맥주 문서가 포함된 데이터 프레임을 얻기 위해 패드에 작성해야 하는 첫 두 줄입니다. 그런 다음 Spark SQL과 함께 사용하려면 해당 데이터프레임에서 임시 테이블을 생성하기만 하면 됩니다.
이렇게 하려면 노트북 그리고 새 노트 만들기. 그러면 Scala 코드 작성을 시작할 수 있는 빈 패드가 표시됩니다. 다음을 복사/붙여넣을 수도 있습니다(단, 복사/붙여넣기는 좋지 않다는 점을 기억하세요).
|
1 2 3 4 5 6 7 |
가져오기 org.아파치.스파크.sql.출처.EqualTo 가져오기 com.카우치베이스.스파크.sql._ val 옵션 = 지도("bucket" -> "맥주 샘플") val 데이터프레임 = sqlc.읽기.카우치베이스(스키마 필터 = EqualTo("type", "맥주"), 옵션) 데이터프레임.등록 온도 테이블("맥주") |
이 단락을 실행하면 후속 조치로 다른 패드가 추가됩니다. 기본적으로 인터프리터는 %spark. 다른 인터프리터를 사용하려면 해당 이름으로 패드를 시작하세요. 여기서는 Spark SQL 쿼리를 실행하고 싶습니다. 따라서 패드를 다음과 같이 시작하겠습니다. %sql. 이전처럼 Scala Spark 코드를 해석하는 대신, 곧바로 Spark SQL 쿼리를 해석합니다.
|
1 2 3 4 5 6 7 |
%sql 선택 abv, 카운트(1) 값 에서 맥주 그룹 by abv 주문 by abv |
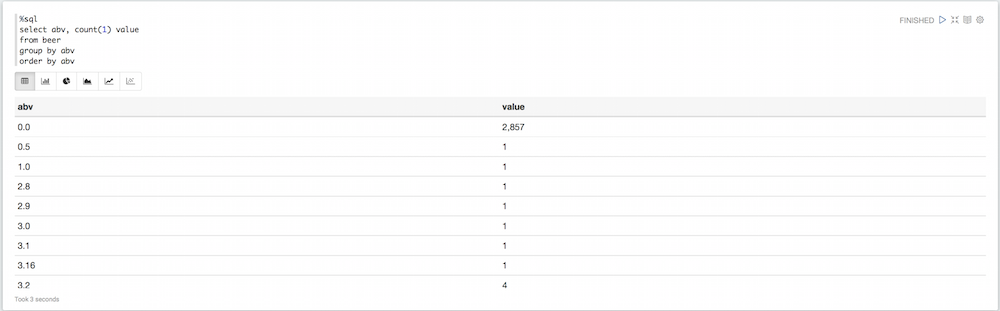
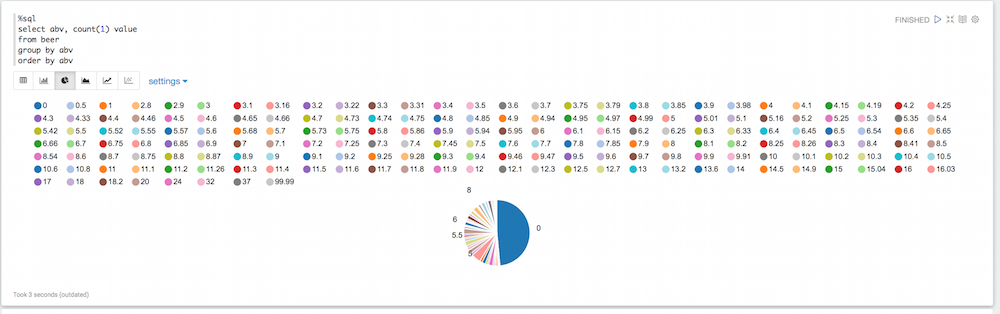
파이차트를 보면 반드시 유용하지 않은 값들이 많이 있다는 것을 알 수 있습니다. 어떤 맥주는 도수가 기본값이 0이고, 어떤 맥주는 도수가 엄청나게 높습니다. 이 모든 것을 필터링할 수 있습니다:
|
1 2 3 4 5 6 7 |
%sql 선택 abv, 카운트(1) 값 에서 맥주 어디 abv > 0 그리고 abv < 15 그룹 by abv 주문 by abv |
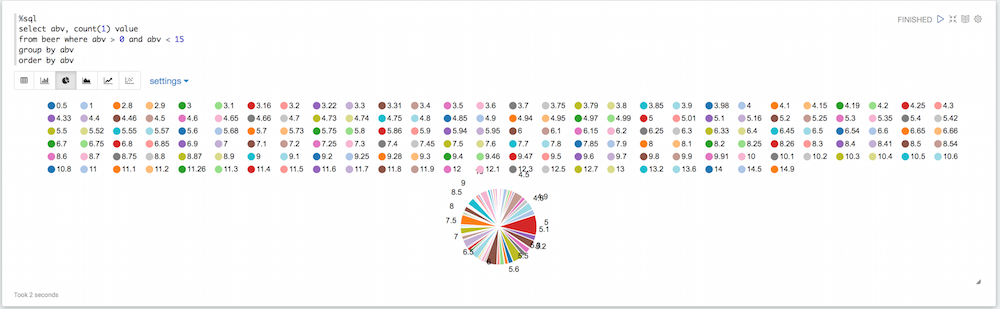
약간 나아졌지만 여전히 다양한 abv 값이 있으므로 이렇게 반올림할 수 있습니다:
|
1 2 3 4 5 6 7 |
%sql 선택 라운드(abv,0) roundABV, 카운트(1) 값 에서 맥주 어디 abv > 0 그리고 abv < 15 그룹 by abv 주문 by abv |
이제 좀 더 읽기 쉬워지기 시작했습니다. 카테고리별로 그룹화하고 동시에 빈 카테고리를 제거해 보겠습니다:
|
1 2 3 4 5 6 7 |
%sql 선택 카테고리, 라운드(abv,0) roundABV, 카운트(1) 값 에서 맥주 어디 abv > 0 그리고 abv < 15 그리고 카테고리 != "" 그룹 by abv, 카테고리 주문 by abv |
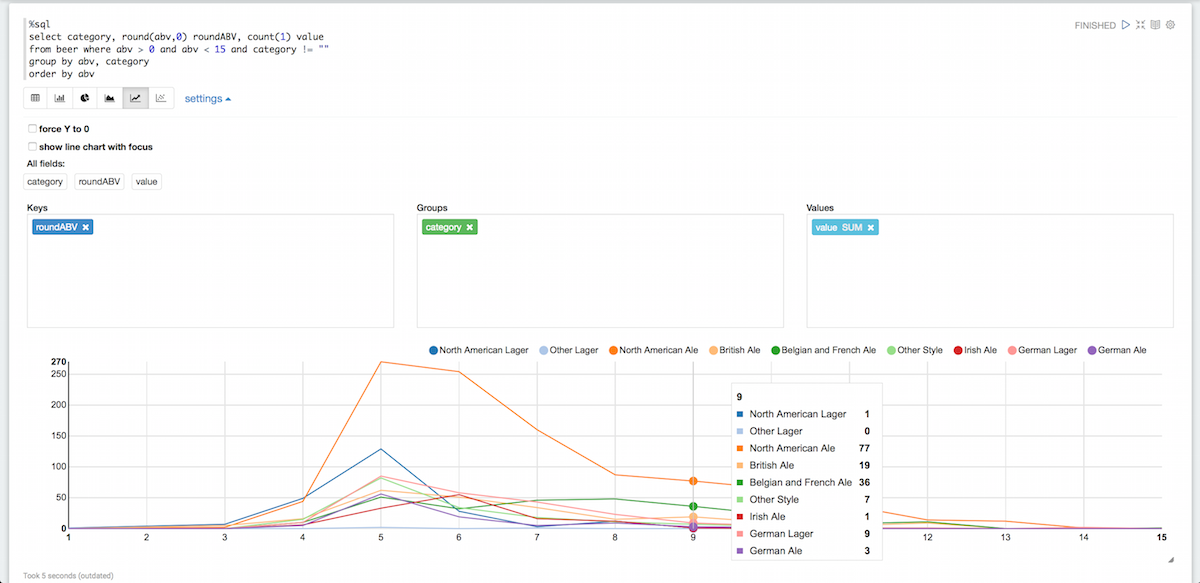
물론 제플린으로 할 수 있는 다른 많은 일들이 있지만, 이것만으로도 카우찹스를 시작하기에 충분할 것입니다. 제플린에 대해 더 자세히 알고 싶다면 다음 문서를 확인하세요. 여기또한, 그들은 또한 몇 가지 좋은 동영상.