시간이 지남에 따라 데이터베이스 업계는 전체 텍스트 검색과 SQL이 동전의 양면이라는 사실을 깨달았습니다. 텍스트 검색에는 추가 쿼리 처리가 필요하고, 쿼리 처리에는 텍스트 패턴을 효율적으로 필터링하기 위한 텍스트 검색이 필요합니다. SQL 데이터베이스는 단일 노드 SMP 시스템용이긴 하지만 그 안에 전체 텍스트 검색을 추가했습니다.
-
- SQL Server 지원 텍스트 검색을 위한 CONTAINS()
- 오라클 지원 텍스트 검색을 위한 CONTAINS()
- MySQL에 full 텍스트 지원
- PostgreSQL에는 다음과 같은 기능이 있습니다. 지원되는 텍스트 검색 를 오랫동안 사용해 왔습니다.
Couchbase 전체 텍스트 검색(FTS)은 크게 세 가지 동기로 만들어졌습니다:
FTS는 반전된 인덱스와 풍부한 쿼리 술어간단한 단어 검색부터 패턴 매칭, 복잡한 범위 술어까지 다양한 검색을 지원합니다. 검색 외에도 다음을 통한 집계를 지원합니다. 검색 패싯.
NoSQL 세계에서 루씬은 널리 사용되는 검색 인덱스이며, 루씬 기반의 검색 서버도 마찬가지입니다: Solr 그리고 Elasticsearch. RDBMS 사촌을 따라갑니다, Elasticsearch, Elasticsearch용 Opendistro 모두 검색에 SQL을 추가했습니다. 카우치베이스는 전체 텍스트 서비스를 도입했습니다, FTS 를 출시했으며, 후속 조치로 N1QL 내 검색을 지원하고 있습니다.
-
- N1QL을 사용한 FTS
- SQL을 사용한 Elasticsearch
- SQL을 사용한 Elasticsearch용 Opendistro
- 그리고 최근 검색 시장에 진입한 몽고DB는 다음과 같은 기능을 추가했습니다. MQL로 검색 Atlas 서비스에서 Lucene을 사용하고 있습니다.
의 SQL 구현 SQL을 사용한 Elasticsearch 그리고 MongoDB의 MQL 에는 여러 가지 제한 사항이 있습니다.
SQL을 사용한 Elasticsearch 의 제한 사항을 여기에 나열했습니다:
-
- 전체 목록: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- 또한 이 언어는 초기 구현으로 인해 당연히 제한적입니다.
- 집합 작업 조인 등을 지원하지 않습니다.
- 창 기능이 없습니다.
MongoDB의 MQL의 검색 통합에는 여러 가지 제한 사항이 있습니다.
-
- Atlas 검색 서비스에서만 사용할 수 있으며 온프레미스 제품에서는 사용할 수 없습니다.
- 검색은 집계() 파이프라인 내에서 첫 번째 작업만 할 수 있습니다.
- 집계 파이프라인(aggregate())에서만 사용할 수 있으며 find(), insert(), update(), remove() 및 기타 다른 작업에서는 사용할 수 없습니다.
aggregate() API와의 통합에는 몇 가지 제한 사항이 있습니다: 온프레미스 데이터베이스에서는 사용할 수 없는 파이프라인의 첫 번째 작업만 가능합니다. 이 문서에서 설명하는 기능은 Couchbase 6.5 이상 버전에 있습니다.
다음은 N1QL의 예입니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT country, city, name, ROW_NUMBER() OVER(ORDER BY country DESC, city DESC) rownum FROM `travel-sample` AS t1 WHERE t1.type = "hotel" AND SEARCH(t1.description, "garden") AND ANY r in reviews satisfies r.ratings.Service > 3 END; |
여기에는 SEARCH() 외에도 다음이 포함됩니다:
- 문서에서 필드 투영: 국가, 도시, 이름
- 창 함수 ROW_NUMBER()를 통한 행 번호 생성
- 추가 스칼라 술어 t1.type = "hotel"
- 리뷰에 대한 배열 술어(ANY)
효율적인 검색과 더불어 최고 수준의 쿼리 처리의 모든 이점을 누릴 수 있습니다. 이뿐만이 아닙니다. N1QL에는 더 많은 기능이 있습니다. 혜택 및 SQL의 효과 는 잘 알려져 있습니다. N1QL은 JSON용 SQL입니다. N1QL의 목표는 개발자와 기업에게 JSON 데이터를 쿼리, 변환 및 조작할 수 있는 표현력이 풍부하고 강력하며 완벽한 언어를 제공하는 것입니다.
사용의 이점 N1QL 를 검색하면 다음과 같은 결과를 얻을 수 있습니다:
- 술어:
- FTS는 관련성 기반 검색에 적합합니다. SQL은 복합 술어, 배열 술어, 추가 스칼라 등 복잡한 쿼리 처리를 처리할 때 유용합니다.
- 연산자 그리고 함수:
- 조인 처리
- N1QL은 내부 조인, 왼쪽 외부 조인, (제한된) 오른쪽 외부 조인, 중첩, 중첩 해제를 수행할 수 있습니다.
- 버킷, 컬렉션 및 하위 쿼리 결과 간에 조인합니다.
- SET 작업
- UNION
- 모두 통합
- 예외
- 모두 제외
- 교차
- 모두 교차
- CTE (공통 테이블 표현식) 및 LET 절 쿼리 작성 개선
- SEARCH() 이상
- SELECT 외에도 INSERT, UPDATE, DELETE, MERGE 문의 WHERE 절에 SEARCH() 술어를 사용할 수 있습니다.
- 이러한 문장을 준비하고 반복적이고 효율적으로 실행할 수 있습니다.
- 부여 및 취소를 통해 RBAC 역할을 통해 일반적인 보안을 확보할 수 있습니다.
- 개발자 생산성: 개발자가 이미 알고 있는 언어인 SQL로 쿼리를 작성합니다.
N1QL 엔진이 이를 어떻게 실행하는지 살펴봅시다. Couchbase FTS 엔지니어링의 Abhinav Dangeti는 이미 의사 결정과 사례를 자세히 설명하는 훌륭한 블로그. 이 문서에서는 위에서 언급한 카테고리의 추가 예시를 통해 이를 시각적으로 설명합니다.
1. 쿼리 실행을 위한 아키텍처
검색() 을 사용하는 쿼리 실행에 세 가지 중요한 단계를 추가했습니다:
- 검색() 술어가 쿼리에 존재하는 경우 플래너는 FTS 검색 인덱스를 유효한 액세스 경로 중 하나로 간주합니다.
- 검색 인덱스를 선택하면 검색 술어를 FTS 인덱스에 밀어넣어 계획을 생성합니다.
- 검색 인덱스가 선택되면, 실행자는 인덱스 서비스에 대한 검색 요청 대신 FTS 노드 중 하나에 검색 요청을 발행합니다.
- 검색 결과가 확정되기 전에 쿼리 서비스는 데이터에 대한 문서의 검색 자격을 다시 확인합니다.
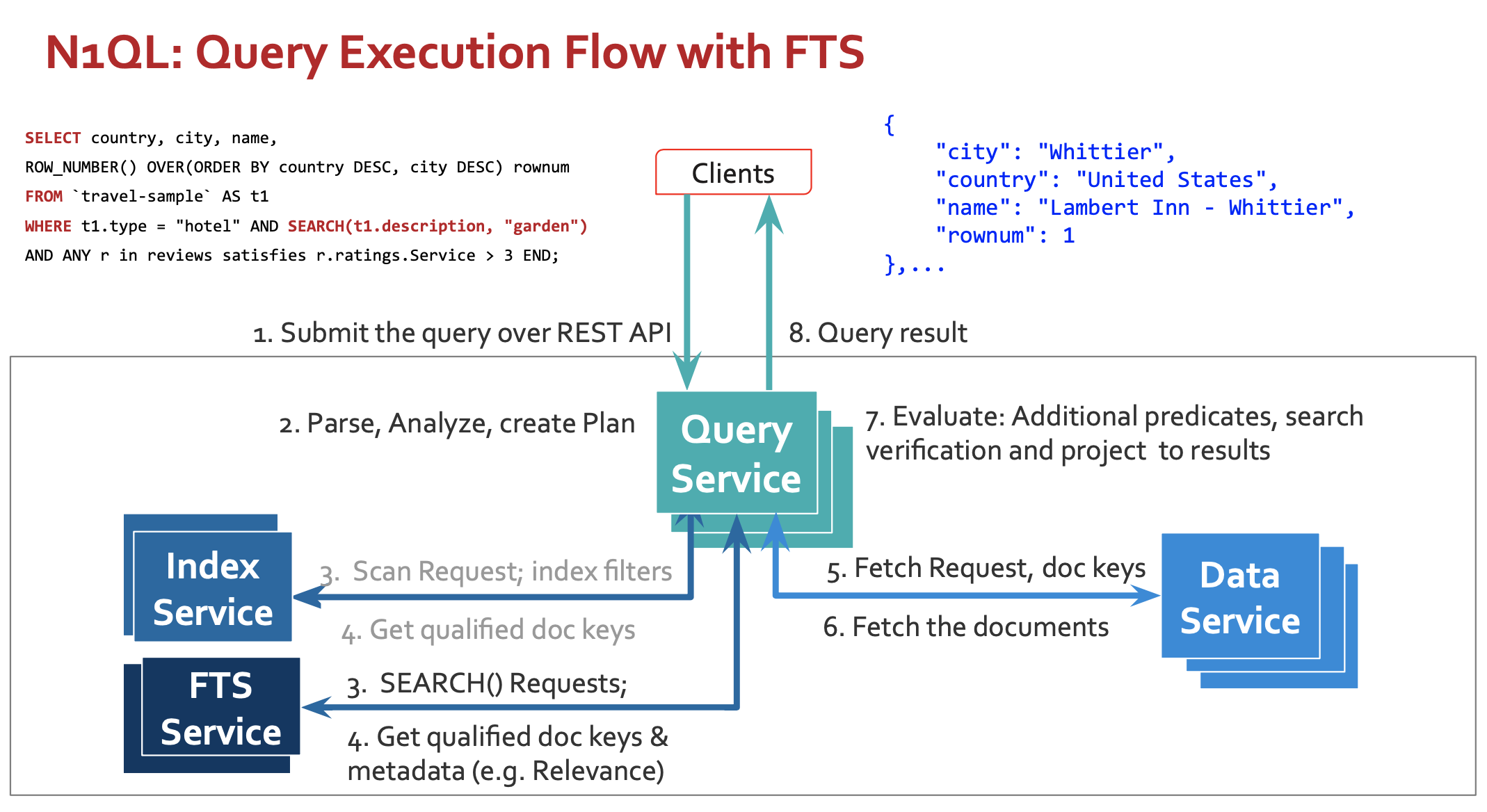
FTS를 사용한 N1QL 쿼리 실행
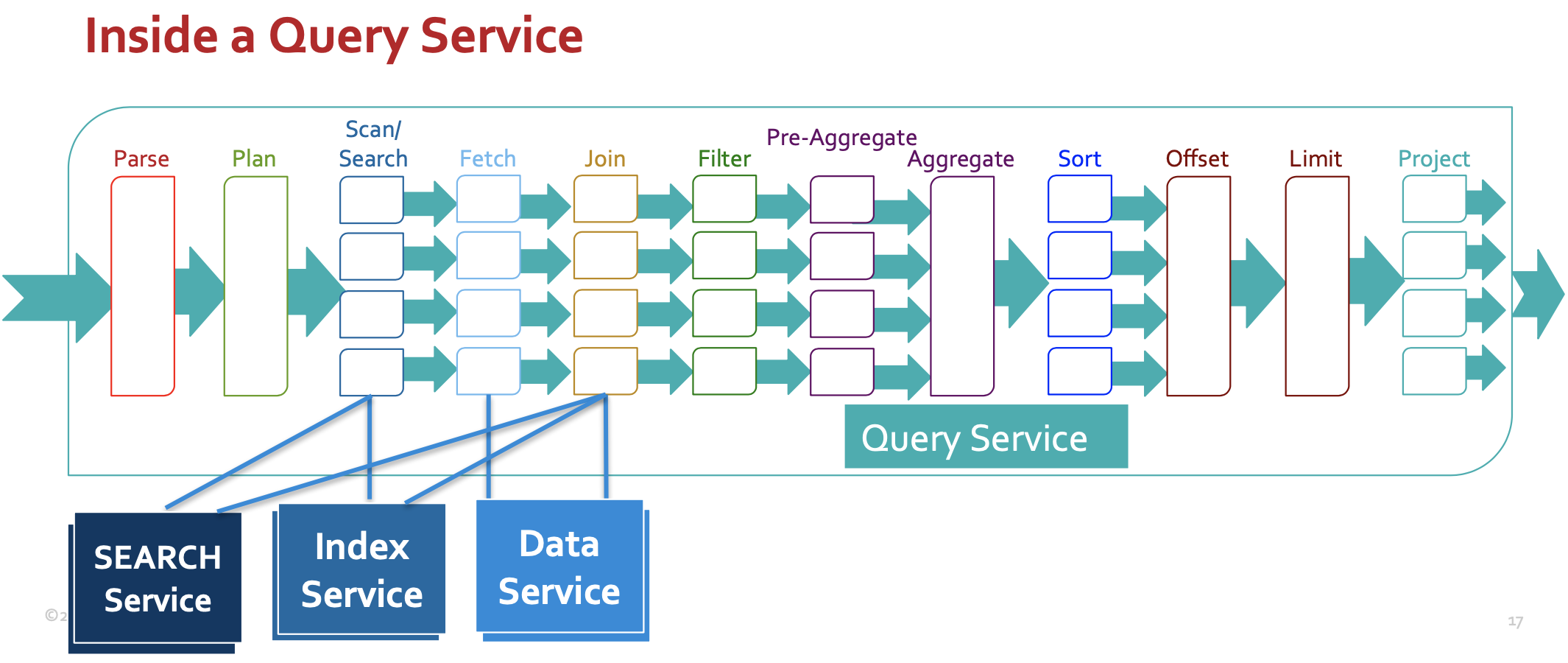
쿼리 서비스 내부
2. 술어 처리
다음 쿼리에서 SEARCH() 술어(predicate-2)는 FTS 검색 요청으로 푸시됩니다. 다른 모든 술어는 위의 '쿼리 서비스 내부' 그림에 표시된 것처럼 쿼리 엔진이 검색 후 '필터' 단계에서 처리합니다. 여기에는 한 가지 예외가 있습니다. FTS 인덱스가 다음과 같은 인덱스를 생성한 경우 JSON 유형 필드(인덱스 정의 문서의 doc_config.type_field) 를 정의하여(이 경우 유형 = "hotel") 문서의 하위 집합에 인덱스를 만들면 인덱스 선택과 검색 푸시다운 모두 이 술어를 활용합니다. 이 경우에도 이 술어는 문서 가져오기 후에 다시 적용됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT country, city, name, ROW_NUMBER() OVER(ORDER BY country DESC, city DESC) rownum FROM `travel-sample` AS t1 WHERE t1.type = "hotel" /* predicate-1 */ AND SEARCH(t1.description, "garden") /* predicate-2 */ AND ANY r in reviews satisfies r.ratings.Service > 3 END; /* predicate-2 */ |
3. 운영자 그리고 기능
다음은 연산자와 함수를 악용하는 쿼리의 예입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT LOWER(country), /* scalar function */ city, lastname || " " || firstname AS fullname /* string operator */ ROW_NUMBER() OVER(ORDER BY country DESC, city DESC) rownum /* window function */ FROM `travel-sample` AS t1 WHERE LOWER(t1.type) = "hotel" /* scalar function */ AND SEARCH(t1.description, "garden") AND ARRAY_CONTAINS(public_likes, "Joe Black") /* Array function */ |
이 쿼리에 대한 쿼리 계획은 다음과 같습니다. IndexSearch는 FTS 검색 요청을 수행하며 이는 쿼리 실행 파이프라인에 계층화됩니다. 따라서 쿼리는 N1QL의 다른 모든 기능의 이점을 얻습니다. 이것은 위 그림의 파이프라인 단계를 반영합니다.
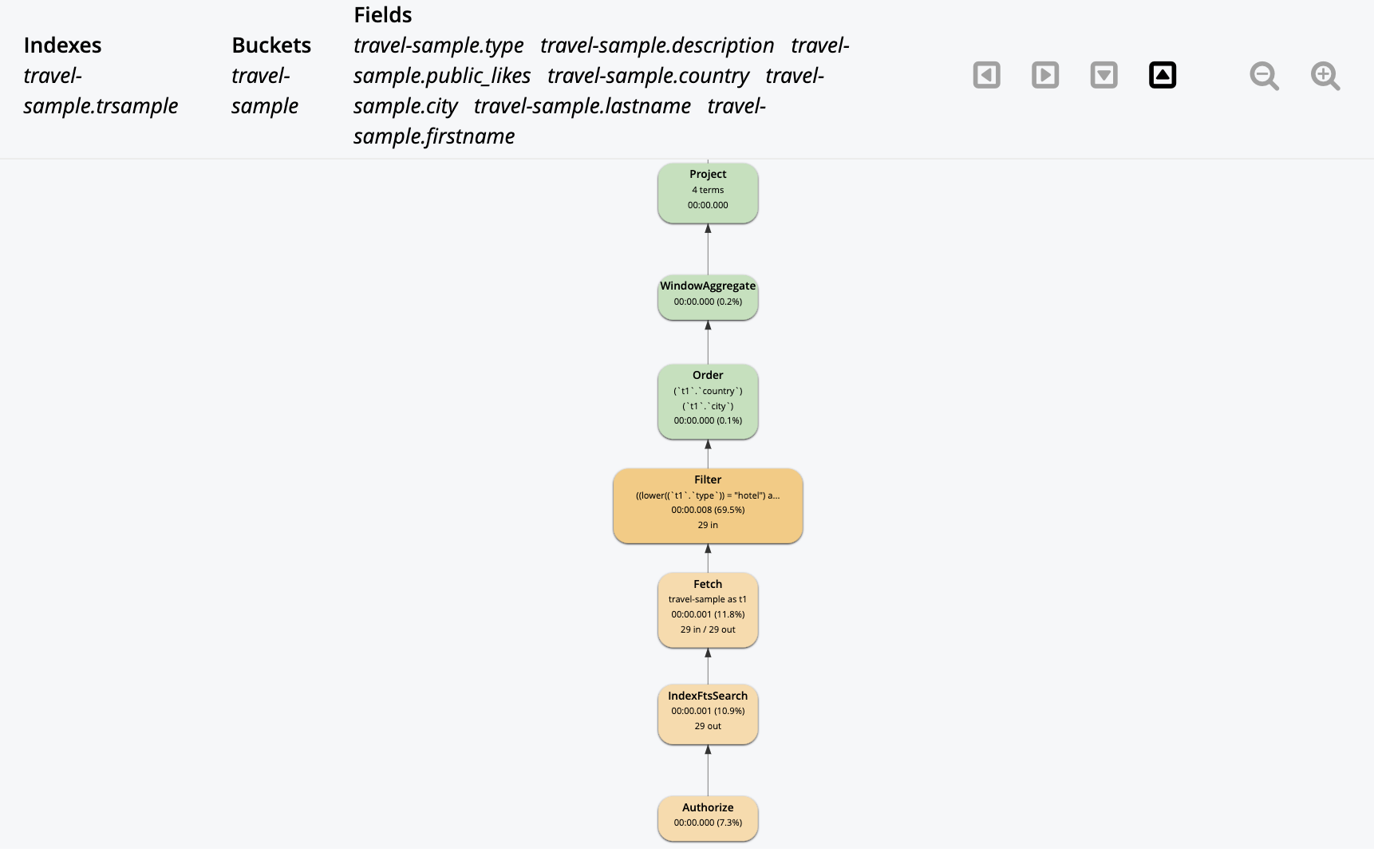
SEARCH()를 사용한 쿼리 계획
4. 조인 처리
.SEARCH()를 조인 처리의 일부로 사용할 수도 있습니다. 이 경우 FTS는 정원이 있는 호텔이 있는 모든 도시를 찾은 다음 공항과 조인하는 데 사용됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT hotel.name hname, airport.city FROM `travel-sample` hotel LEFT OUTER JOIN `travel-sample` airport ON hotel.city = airport.city WHERE hotel.type = 'hotel' AND SEARCH(hotel.description, "garden") AND airport.type = 'airport' ; |
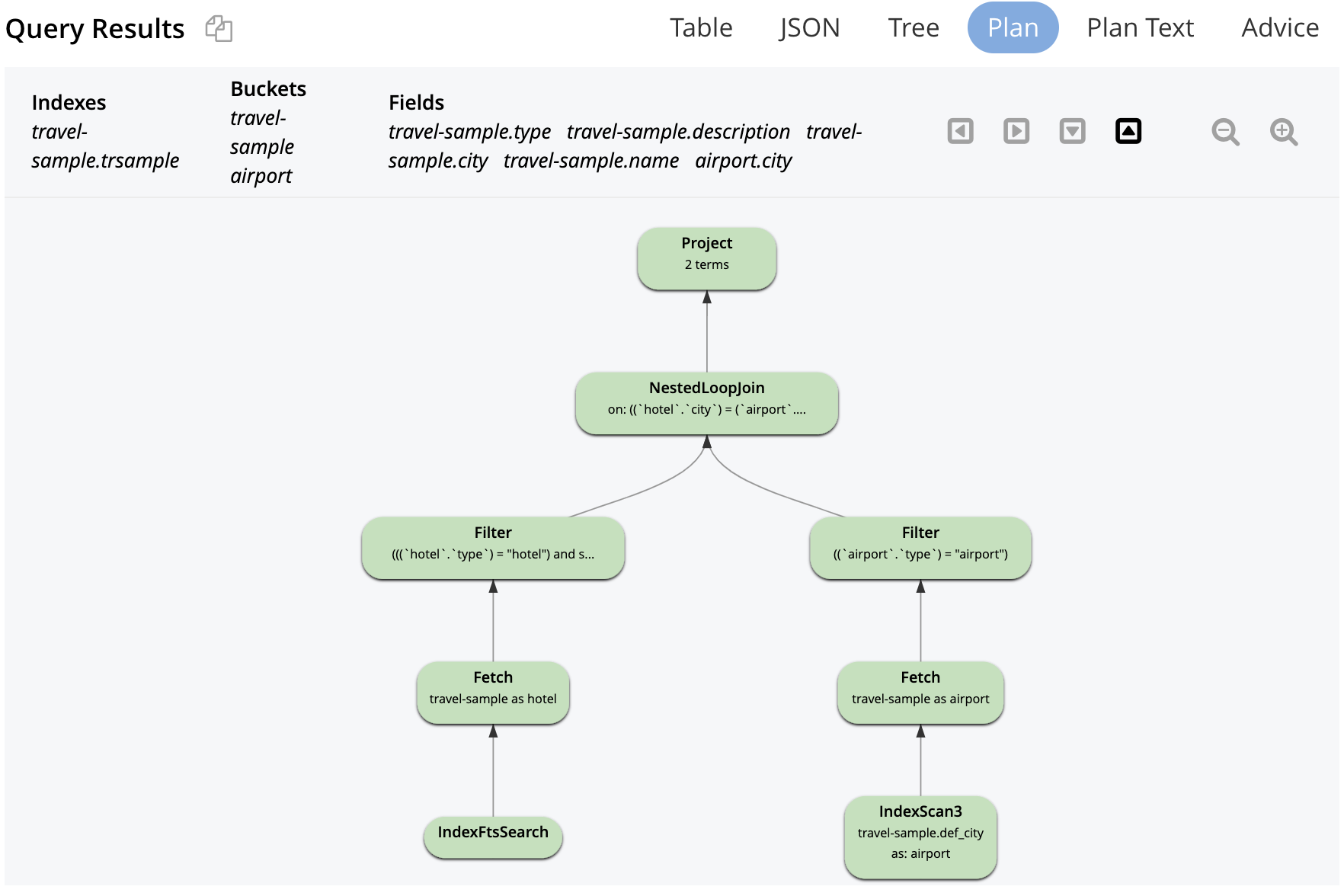
검색으로 가입하기
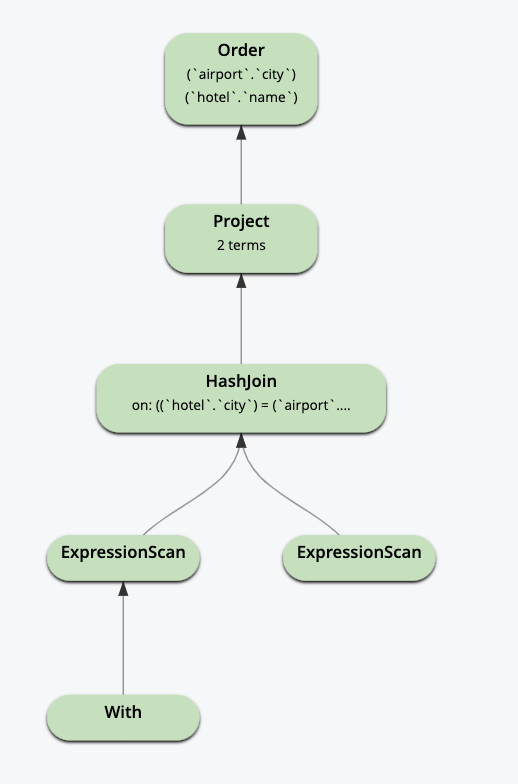
5. 공통 테이블 표현식(CTE).
쿼리 서비스의 N1QL은 비재귀적 CTE를 지원합니다. 각 표현식 내에서 SEARCH()를 사용할 수 있습니다. 해당 표현식에서 파생된 테이블(호텔 및 공항)이 쿼리 내에서 키 스페이스로 사용됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
WITH hotel AS ( SELECT name, city FROM `travel-sample` WHERE type = 'hotel' AND search(description, "garden")), airport AS ( SELECT name, city FROM `travel-sample` WHERE type = 'airport' AND SEARCH(city, "angeles")) SELECT hotel.name hname, airport.city FROM hotel INNER JOIN airport ON hotel.city = airport.city ORDER BY airport.city, hotel.name; |
5. 업데이트에서 사용
SEARCH()는 다른 DML 문 내에서 술어가 허용되는 곳이면 어디에서나 사용할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* INSERT INTO... SELECT statement. */ INSERT INTO mybucket (KEY id, VALUES v) SELECT meta().id id, v FROM `travel-sample` v WHERE SEARCH(v, "+type:hotel +description:clean"); /* DELETE statement */ DELETE FROM `travel-sample` WHERE SEARCH(v, "+type:hotel +description:clean"); /* UPDATE statement */ UPDATE `travel-sample` SET new_field = "search n update!" WHERE SEARCH(v, "+type:hotel +description:clean"); |
예제는 길게 이어질 수 있습니다. 일반적인 샘플 예제를 보여드렸습니다. 다양한 SQL 문(DML)에서 이 예제를 사용합니다.
결론:
Couchbase FTS는 확장 가능한 분산형 텍스트 검색 엔진을 제공합니다. 이를 Couchbase 쿼리 서비스의 N1QL에 원활하게 계층화하여 쿼리의 모든 기능을 검색의 모든 기능과 함께 사용할 수 있도록 했습니다. 더 많은 혁신이 준비 중입니다. 계속 지켜봐 주세요!