CData를 사용하여 RapidMiner로 Couchbase 분석 확장하기
이 문서에서는 Couchbase용 CData JDBC 드라이버를 사용하여 RapidMiner에서 Couchbase Analytics로의 연결을 설정하는 데 필요한 단계를 안내합니다. 이 드라이버에 대한 자세한 내용은 여기에서 찾을 수 있습니다..
전제 조건
카우치베이스
먼저 데이터 및 분석 서비스가 활성화된 Couchbase Server Enterprise Edition(EE) 6.x 클러스터가 필요합니다. 저는 단일 노드 로컬 설치를 사용하고 있지만, 이 문서의 정보는 모든 Couchbase Server EE 클러스터에 적용됩니다.
기존 Couchbase Server EE 클러스터가 없는 경우 다음 링크를 통해 빠르게 시작하고 실행할 수 있습니다:
- Couchbase Server EE 다운로드
- 카우치베이스 서버 EE 설치
- 단일 노드 클러스터 프로비저닝 (참고: 클러스터 구성에 기본값 사용)
카우치베이스용 CData JDBC 드라이버
다음으로 다음을 다운로드하여 설치해야 합니다. Couchbase용 CData JDBC 드라이버.
다운로드하고 패키지를 풀면 라이선스를 설정해야 합니다:
명령줄 활성화
설치 과정에서 시스템에 대한 라이선스가 자동으로 설치됩니다. 그러나 명령줄에서 cdata.jdbc.couchbase.jar를 통해 라이선스를 설치할 수도 있습니다. 이렇게 하려면 다음 명령을 실행합니다: java -jar cdata.jdbc.couchbase.jar -license. 이 프로세스는 cdata.jdbc.couchbase.lic 항아리 옆에 있거나 .cdata 디렉토리를 사용자 홈 디렉토리에 추가합니다.
평가판 라이선스 설치
설치 과정에서 시스템에 대한 평가판 라이선스가 자동으로 설치됩니다. 위의 '명령줄 활성화' 섹션에 설명된 방법을 사용하여 평가판 라이선스를 설치할 수도 있습니다. 메시지가 표시되면 제품 키로 "TRIAL"을 입력하기만 하면 됩니다.
참고** cdata.jdbc.couchbase.lic은 jar 옆이나 다음 위치에 있어야 합니다. .cdata 디렉토리를 사용자 홈 디렉터리 아래에 추가합니다. 즉, "/Users/justinsimpson/.CData/cdata.jdbc.couchbase.lic"
카우치베이스 설정
Couchbase에서 설정
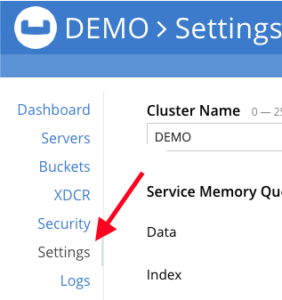
그런 다음 샘플 버킷

맥주 샘플 선택 확인란을 선택하고 샘플 데이터를 로드합니다. 그런 다음 버킷 를 클릭하고 맥주 샘플.
이 작업이 완료되면 애널리틱스를 설정해야 합니다.
선택 애널리틱스, 의 섀도 데이터 집합을 생성한 다음 맥주 의 버킷에서 맥주 샘플.
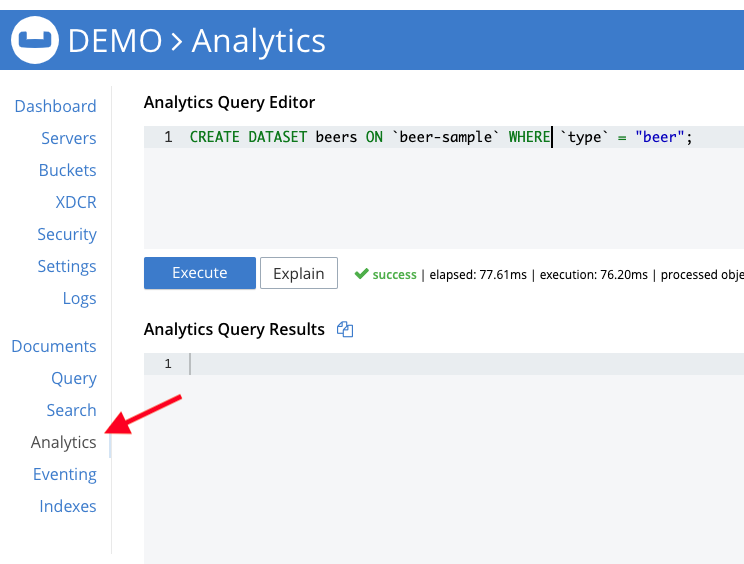
카우치베이스 애널리틱스에서 데이터 집합 만들기
|
1 |
CREATE DATASET beers ON `beer-sample` WHERE `type` = "beer"; |
클릭 실행합니다, 를 입력하면 섀도 데이터 세트 정의가 크레이트됩니다.
다음 정의를 사용하여 두 번째 섀도 데이터 집합을 생성하여 이 단계를 반복하겠습니다.
|
1 |
CREATE DATASET breweries ON `beer-sample` WHERE `type` = "brewery"; |
다음으로 다음을 사용하여 데이터 집합을 활성화하여 초기화해야 합니다.
|
1 |
CONNECT LINK Local; |
실행을 클릭합니다.
이제 애널리틱스 대시보드에서 다음과 같이 실행하여 이를 테스트할 수 있습니다.
|
1 2 3 |
SELECT COUNT(*) FROM beers UNION ALL SELECT COUNT(*) FROM breweries; |
카우치베이스 애널리틱스에 대한 자세한 내용은 다음과 같습니다. 여기에서 찾을 수 있습니다.
카우치베이스 설정이 완료되었습니다!
RapidMiner 설정
카우치베이스 애널리틱스의 확장으로 RapidMiner를 사용하는 간단한 작업을 수행하려면 두 가지 기본 단계가 있습니다.
- 연결 설정
- '데이터베이스 읽기'를 위한 연산자 2개가 있는 프로세스를 생성합니다. 또한 이러한 결과를 로컬에 저장하여 결합하고 다른 연산자와 프로세스를 RapidMiner 내에서 사용할 수도 있습니다.
연결 설정
RapidMiner 내에서 저는 빈 프로세스에서 시작합니다. 연결에서 다음을 선택합니다. 연결 만들기 을 클릭하고 연결 이름을 지정합니다. 이 예제에서는 'CBLocal'을 사용합니다.
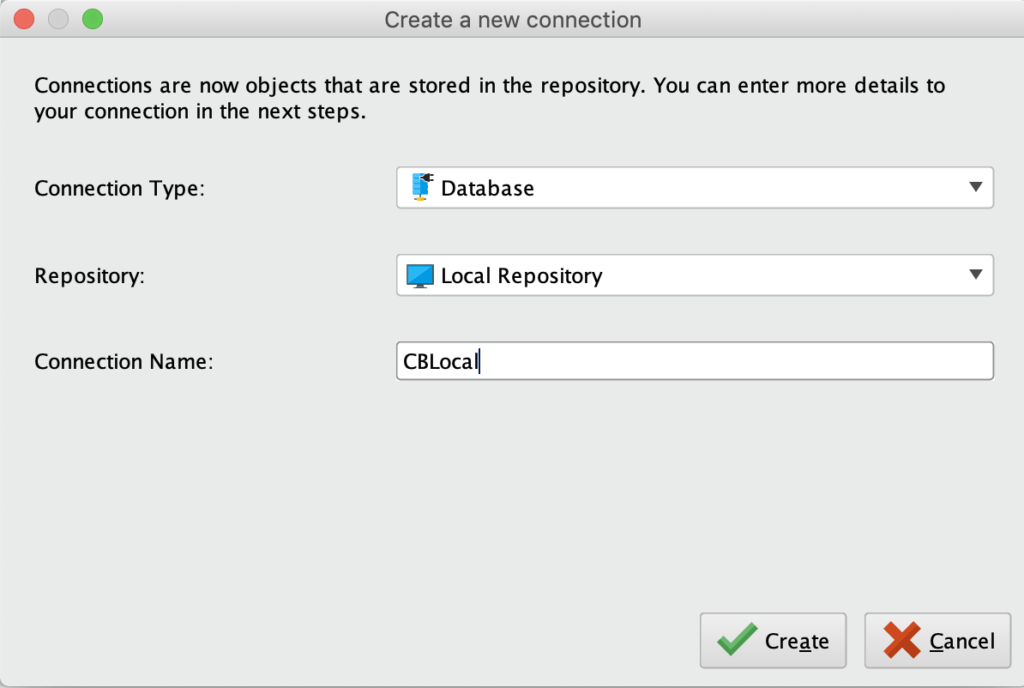
RapidMiner 연결 JDBC 연결 설정
에서 설정 탭에서 데이터베이스 시스템이 '사용자 지정(드라이버 탭에서 구성)'으로 설정되어 있는지 확인하고 URL 수동 구성을 선택합니다.
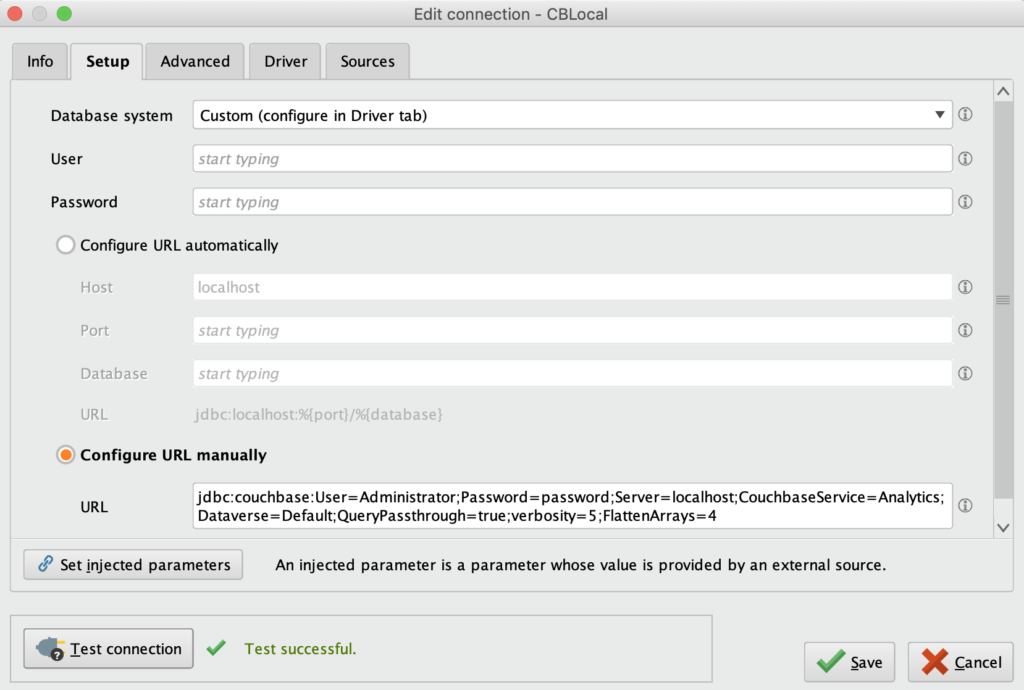
카우치베이스 애널리틱스를 위한 RapidMiner 연결 JDBC URL 설정
URL을 다음과 같이 입력합니다:
|
1 |
jdbc:couchbase:User=Administrator;Password=password;Server=localhost;CouchbaseService=Analytics;Dataverse=Default;QueryPassthrough=true;verbosity=5;FlattenArrays=4 |
모든 연결 문자열 옵션 및 세부 정보는 아래에서 확인할 수 있습니다. CData JDBC 연결 문자열 옵션.
그런 다음 드라이버 탭을 탭하여 설정을 완료합니다.
JDBC 드라이버 Jar 파일을 설정하려면 폴더 아이콘을 클릭하여 cdata.jdbc.couchase.jar의 위치를 찾습니다. 이 위치가 선택되면 드롭다운 목록에서 'cdata.jdbc.couchbase.CouchbaseDriver'를 선택할 수 있습니다.
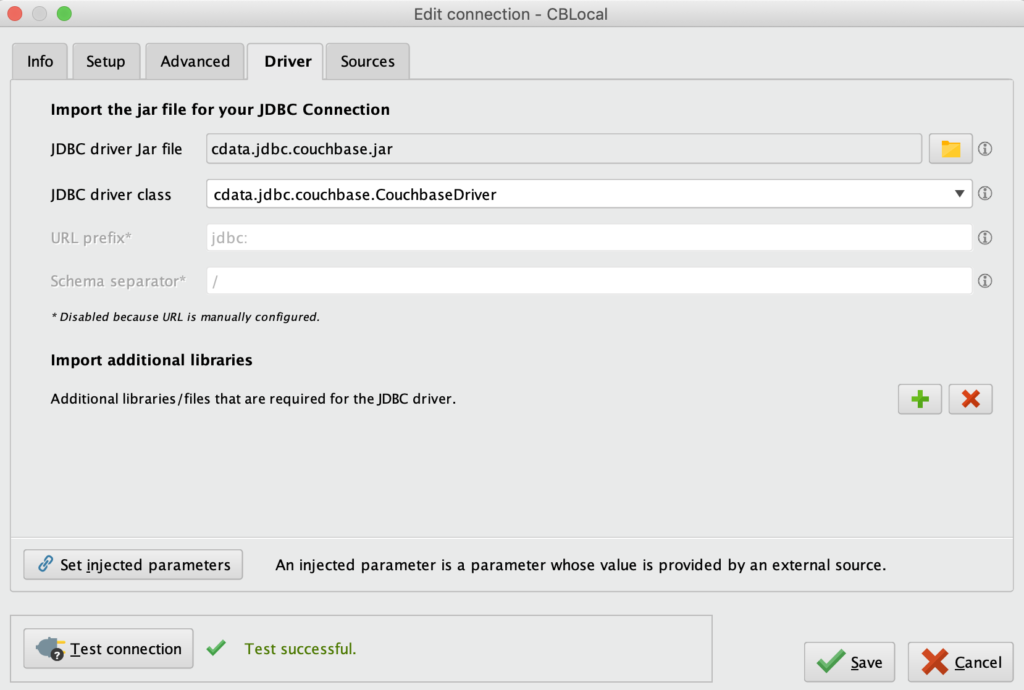
카우치베이스 애널리틱스용 RapidMiner 연결 JDBC 드라이버 설정
이제 연결 테스트를 클릭하여 설정이 완료되었는지 확인할 수 있습니다.
RapidMiner 사용
이제 RapidMiner에 새 연결이 구성되었으니, 데이터를 로드할 차례입니다!
빈 프로세스에서 시작하세요.
- '데이터베이스 읽기' 연산자를 끌어다 놓습니다(프로세스 창에서 출력(out)을 결과(res)에 연결하는 것이 중요합니다).
- 방금 만든 연결을 선택합니다.
- SQL 쿼리 작성을 선택하고 Couchbase 애널리틱스에 전달할 쿼리를 입력합니다.
1SELECT brewery_id,name,style,abv FROM beers; - '플레이' 버튼을 클릭하면 결과를 확인할 수 있습니다!
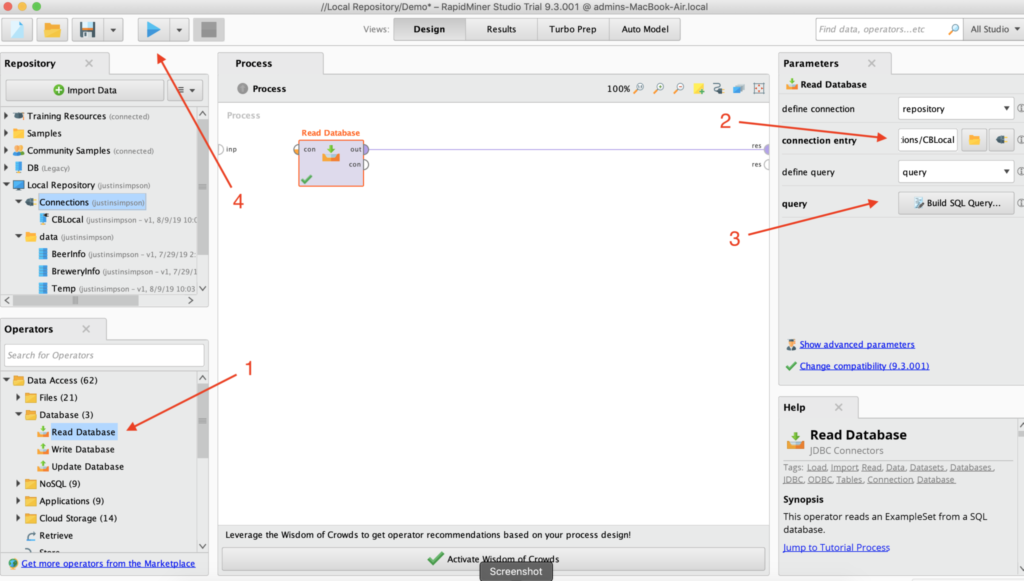
카우치베이스 애널리틱스에서 RapidMiner 읽기 데이터베이스 연산자 설정하기
내 결과 세트는 다음과 같습니다...
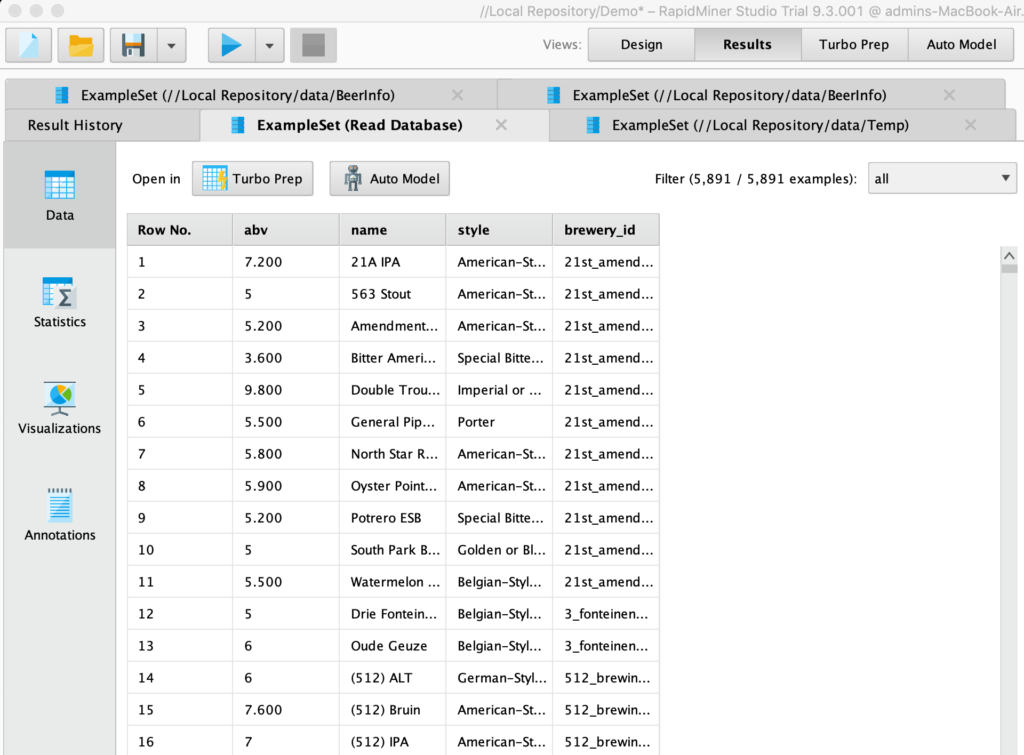
카우치베이스 애널리틱스의 RapidMiner 결과
이러한 결과를 저장하고 여러 데이터 세트를 생성하여 다른 RapidMiner 도구를 활용하려면 '저장' 연산자를 드래그하여 연산자를 추가하고 데이터를 저장할 위치를 설정하기만 하면 됩니다.
참고** '데이터베이스 읽기' 연산자의 출력(아웃)에서 스토어 연산자의 입력(인풋)으로의 연결이 제대로 설정되어 있는지 확인해야 합니다.
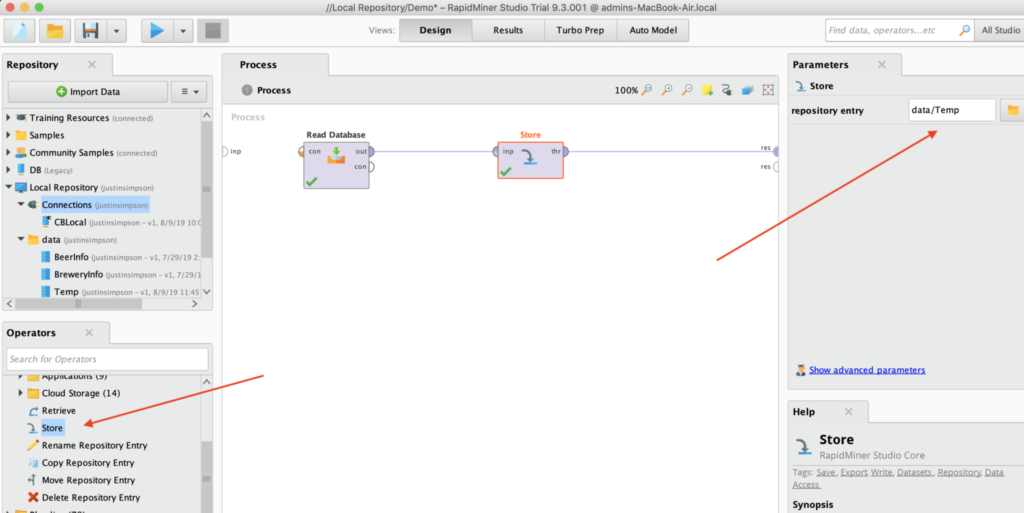
RapidMiner 스토어 설정
그런 다음 위의 데이터 섹션에서 볼 수 있듯이 '양조장'을 만든 다른 섀도 데이터 집합에 대해 이 프로세스를 반복했습니다.
래피드 마이너 스튜디오에 대한 자세한 내용은 다음과 같습니다. 여기에서 찾을 수 있습니다.
다음 단계
Couchbase 다운로드설정 분석을 클릭하고 RapidMiner 데이터로 어떤 인사이트를 얻을 수 있는지 알아보세요. 다양한 도구를 사용하여 다른 도구로 분석 확장하기 Couchbase CData 드라이버 여러분의 손끝에 있습니다.