프롤로그
최신 비즈니스 애플리케이션은 새로운 기능의 계획된 출시와 운영 체제 또는 애플리케이션의 주기적인 패치 기간 중에도 24시간 연중무휴로 가동되어야 합니다. 이를 달성하려면 개발 속도, 인프라 안정성 및 확장성을 보장하는 도구와 기술이 필요합니다.
Kubernetes와 같은 컨테이너 오케스트레이션 도구는 관리하는 물리적 머신을 추상화함으로써 오늘날 애플리케이션 개발 및 배포 방식에 혁신을 불러일으키고 있습니다. Kubernetes를 사용하면 기본 인프라에 대한 걱정 없이 원하는 메모리와 컴퓨팅 성능의 양을 정의하고 이를 사용할 수 있습니다.
쿠버네티스 환경의 파드(컴퓨팅 리소스 단위)와 컨테이너(애플리케이션이 실행되는 곳)는 모든 유형의 장애 발생 시 자체 복구할 수 있습니다. 본질적으로 임시적입니다. 이것은 상태 비저장 마이크로서비스가 있는 경우 잘 작동하지만, 예를 들어 Couchbase와 같은 데이터베이스 관리 시스템처럼 상태를 유지해야 하는 애플리케이션의 경우, 스토리지 볼륨을 새로 선출된 파드에 간단히 다시 마운트하여 데이터를 빠르게 복구할 수 있도록 파드 및 컨테이너의 수명 주기 관리에서 스토리지를 외부화할 수 있어야 합니다.
이것이 바로 영구 볼륨 는 Kubernetes 기반 배포에서 활성화됩니다. 카우치베이스 자율 운영자 는 이 기술을 가장 먼저 도입하여 인프라 기반 장애를 원활하고 신속하게 복구하는 기업 중 하나입니다.
이 문서에서는 1) 고가용성을 위해 별도의 가용성 영역에 매핑할 수 있는 여러 Couchbase 서버 그룹 사용 2) 인프라 장애로부터 빠른 복구를 위해 퍼시스턴트 볼륨을 활용하는 방법을 단계별로 살펴봅니다.
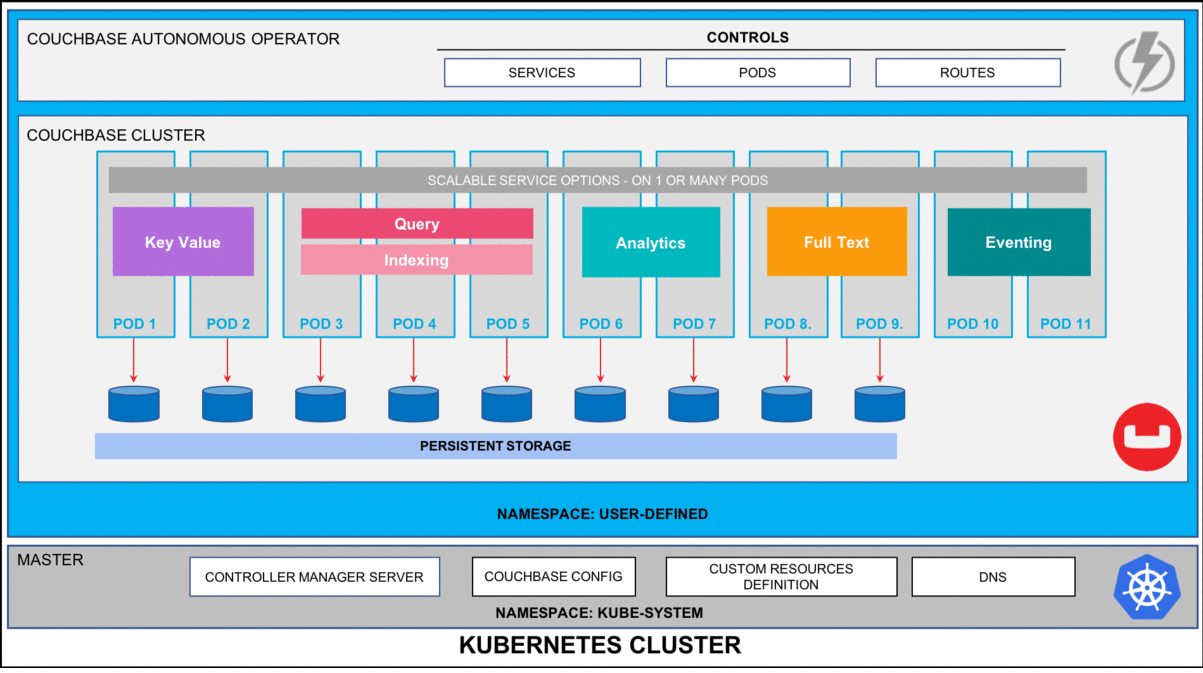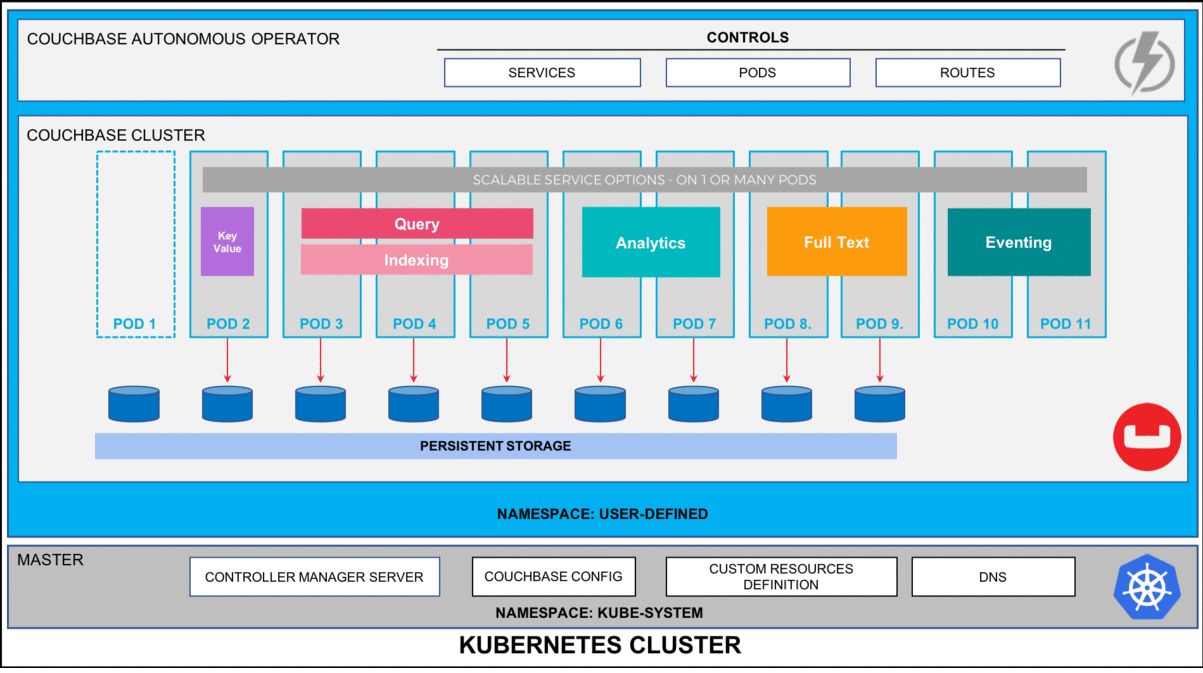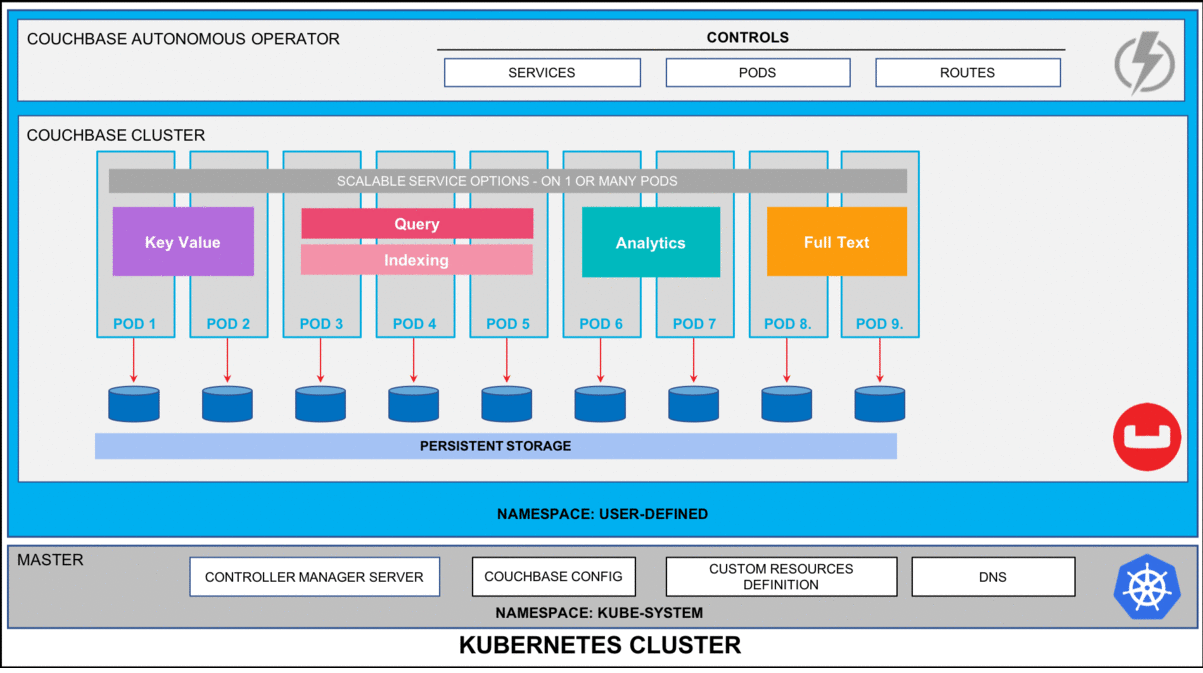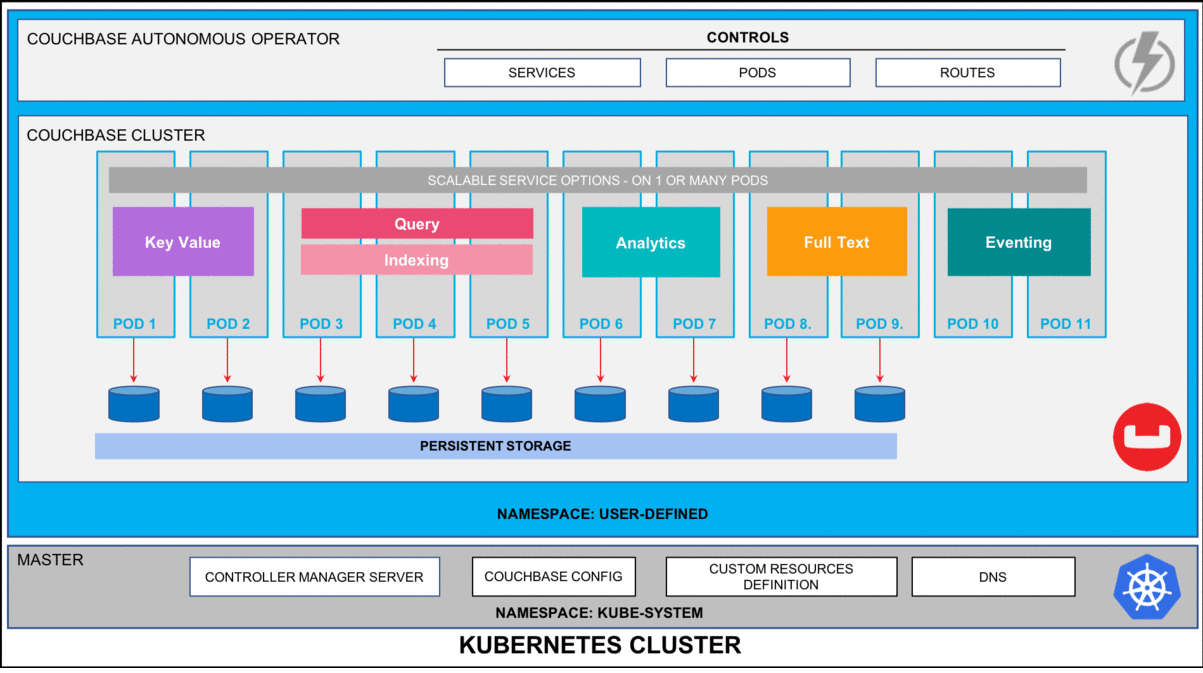
그림 1: 카우치베이스 데이터베이스 플랫폼을 자체 모니터링하고 자체 복구하는 카우치베이스 자율 운영자 for Kubernetes.
1. 전제 조건
EKS에 카우치베이스 자율 운영자 배포를 시작하기 전에 세 가지 높은 수준의 전제 조건이 있습니다:
- 다음이 있습니다. kubectl 를 로컬 머신에 설치합니다.
- 최신 AWS CLI 는 로컬 머신과 AWS에서 실행되는 Kubernetes 컨트롤 플레인 간에 채널을 안전하게 설정할 수 있도록 구성됩니다.
- Amazon EKS 클러스터 는 세 개의 개별 가용 영역에 최소 3개의 워커 노드와 함께 배포되므로 나중에 Couchbase 클러스터를 배포하고 관리할 수 있습니다. 여기서는 us-east-1을 리전으로, us-east-1a/1b/1c를 3개의 가용 영역으로 사용하지만, 아래 예제에서 YAML 파일을 약간 변경하여 모든 리전/영역에 배포할 수 있습니다.
2. 카우치베이스 자율 운영자 배포하기
카우치베이스 오퍼레이터 설정을 시작하기 전에, 로컬 머신에서 'kubectl get nodes' 명령을 실행하여 EKS 클러스터가 실행 중인지 확인합니다.
$ kubectl get 노드
이름 상태 역할 나이 버전
ip-192-168-106-132.ec2.internal 준비 110m v1.11.9
ip-192-168-153-241.ec2.internal 준비 110m v1.11.9
ip-192-168-218-112.ec2.internal 준비 110m v1.11.9로컬 머신에서 Amazon EKS 클러스터에서 실행 중인 Kubernetes 컨트롤 플레인에 연결할 수 있는지 테스트한 후에는 이제 Couchbase 서버 클러스터를 Kubernetes에서 관리할 수 있도록 하는 글루 기술인 Couchbase Autonomous Operator 배포에 필요한 단계부터 시작할 수 있습니다.
2.1. 운영자 패키지 다운로드
먼저 최신 버전을 다운로드하여 시작하겠습니다. 카우치베이스 자율 운영자 를 다운로드하여 로컬 컴퓨터에 압축을 풉니다. 디렉터리를 운영자 폴더로 변경하여 Couchbase 운영자를 배포하는 데 필요한 YAML 파일을 찾을 수 있도록 합니다:
$ cd couchbase-autonomous-operator-kubernetes_1.2.0-981_linux-x86_64
$ ls
라이선스.txt couchbase-cli-create-user.yaml 운영자-역할-바인딩.yaml secret.yaml
README.txt couchbase-cluster.yaml operator-role.yaml
admission.yaml crd.yaml operator-service-account.yaml
bin operator-deployment.yaml pillowfight-data-loader.yaml2.2. 네임스페이스 만들기
클러스터 리소스를 여러 사용자 간에 잘 분리할 수 있는 네임스페이스를 생성합니다. 이를 위해 배포를 위해 emart라는 고유 네임스페이스를 사용하고 나중에 이 네임스페이스를 사용하여 Couchbase 클러스터를 배포할 것입니다.
작업 디렉토리에 namespace.yaml 파일에 이 콘텐츠를 추가하고 Couchbase 운영자 디렉토리에 저장합니다:
apiVersion: v1
종류: 네임스페이스
메타데이터:
name: emart네임스페이스 구성을 파일에 저장한 후, kubectl cmd를 실행하여 생성한다:
$ kubectl create -f namespace.yaml네임스페이스가 성공적으로 생성되었는지 확인하려면 get 네임스페이스 명령을 실행합니다:
$ kubectl 네임스페이스 가져오기
출력한다:
이름 상태 나이
기본 활성 1시간
이마트 활성 12초이제부터는 모든 리소스 프로비저닝의 네임스페이스로 emart를 사용할 것입니다.
2.3. TLS 인증서 추가
주어진 인증서로 Couchbase 운영자 및 서버에 대한 비밀을 만듭니다. 참조 사용자 지정 인증서를 만드는 방법 섹션이 없는 경우 해당 섹션을 추가하세요.
$ kubectl 생성 비밀 일반 couchbase-server-tls --from-file chain.pem --from-file pkey.key --namespace emart
비밀/카우치베이스-서버-tls 생성됨$ kubectl 생성 비밀 일반 카우치베이스 운영자-tls --from-file pki/ca.crt --namespace emart
비밀/카우치베이스-운영자-tls 생성됨2.4. 입장 컨트롤러 설치
어드미션 컨트롤러는 Couchbase Autonomous Operator의 필수 구성 요소이며 별도로 설치해야 합니다. 어드미션 컨트롤러의 주요 목적은 운영자가 작업을 수행하기 전에 Couchbase 클러스터 구성 변경의 유효성을 검사하여 잘못된 구성으로 인해 발생할 수 있는 우발적인 손상으로부터 Couchbase 배포(및 운영자)를 보호하는 것입니다. 아키텍처에 대한 자세한 내용은 문서 페이지의 입학 컨트롤러
다음 단계에 따라 입장 컨트롤러를 배포합니다:
- 카우치베이스 운영자 디렉토리에서 다음 명령을 실행하여 입장 컨트롤러를 생성합니다:
$ kubectl create -f admission.yaml --namespace emart- 입장 컨트롤러가 성공적으로 배포되었는지 확인합니다:
$ kubectl get deployments --namespace emart
이름 원하는 현재 최신 사용 가능 연령
카우치베이스-운영자-입장 1 1 1 1 1m2.5. CRD 설치
운영자 설치의 첫 번째 단계는 CouchbaseCluster 리소스 유형을 설명하는 사용자 정의 리소스 정의(CRD)를 설치하는 것입니다. 다음 명령을 사용하여 설치할 수 있습니다:
kubectl create -f crd.yaml --namespace emart2.6. 운영자 역할 만들기
다음으로 클러스터 역할 를 통해 운영자가 실행에 필요한 리소스에 액세스할 수 있습니다. 운영자는 다양한 네임스페이스에 해당 역할을 할당할 수 있으므로 클러스터 역할을 먼저 생성하는 것이 가장 좋습니다. 서비스 계정 네임스페이스에서
운영자에 대한 클러스터 역할을 만들려면 다음 명령을 실행합니다:
$ kubectl create -f operator-role.yaml --namespace emart이 클러스터 역할은 한 번만 만들면 됩니다.
2.7. 서비스 계정 만들기
클러스터 역할이 생성된 후에는 운영자를 설치할 네임스페이스에 서비스 계정을 만들어야 합니다. 서비스 계정을 만들려면 다음과 같이 하세요:
$ kubectl create serviceaccount couchbase-operator --namespace emart이제 서비스 계정에 운영자 역할을 할당합니다:
$ kubectl 생성 역할 바인딩 카우치베이스 오퍼레이터 --역할 카우치베이스 오퍼레이터 \.
--서비스어카운트 이마트:카우치베이스-운영자 --네임스페이스 이마트
출력한다:
clusterrolebinding.rbac.authorization.k8s.io/couchbase-operator 생성됨이제 더 진행하기 전에 모든 역할과 서비스 계정이 네임스페이스 아래에 생성되었는지 확인하겠습니다. emart. 이를 위해 다음 세 가지 검사를 실행하고 각 검사에서 무언가를 반환하는지 확인합니다:
Kubectl get roles -n emart
Kubectl get rolebindings -n emart
Kubectl get sa -n emart2.8. 카우치베이스 오퍼레이터 배포
이제 운영자를 배포할 모든 역할과 권한이 준비되었습니다. 운영자를 배포하는 방법은 Couchbase Autonomous Operator 디렉토리에서 operator.yaml 파일을 실행하는 것만큼 간단합니다.
$ kubectl create -f operator-deployment.yaml --namespace emart
출력한다:
deployment.apps/couchbase-operator 생성됨위의 명령은 오퍼레이터 도커 이미지(operator.yaml 파일에 지정됨)를 다운로드하고 오퍼레이터의 단일 인스턴스를 관리하는 디플로이먼트를 생성합니다. 오퍼레이터는 디플로이먼트를 사용하여 실행 중인 파드가 죽으면 다시 시작할 수 있습니다.
쿠버네티스가 오퍼레이터를 배포하고 오퍼레이터를 실행할 준비가 되는 데는 1분도 채 걸리지 않습니다.
a) 배포 상태 확인
다음 명령을 사용하여 배포 상태를 확인할 수 있습니다:
$ kubectl get deployments --namespace emart오퍼레이터가 배포된 직후 이 명령을 실행하면 출력은 다음과 같이 표시됩니다:
이름 원하는 현재 최신 사용 가능 연령
카우치베이스 운영자 1 1 1 0 10S참고: 위의 출력은 CouchBase 운영자가 배포되었음을 의미하며, 다음으로 CouchBase 클러스터 배포를 진행할 수 있습니다.
b) 운영자 상태 확인
다음 명령을 사용하여 운영자가 성공적으로 시작되었는지 확인할 수 있습니다:
$ kubectl get pods -l app=couchbase-operator --namespace emart오퍼레이터가 실행 중이면 명령은 READY 필드에 1/1이 표시된 출력을 반환합니다(예: 다음과 같이):
이름 준비 상태 재시작 연령
couchbase-operator-8c554cbc7-6vqgf 1/1 Running 0 57s로그를 확인하여 운영자가 실행 중인지 확인할 수도 있습니다. 메시지를 찾아보세요: CRD 초기화, 이벤트 수신 중... 모듈=컨트롤러.
$ kubectl 로그 couchbase-operator-8c554cbc7-6vqgf --namespace emart --tail 20
출력한다:
time="2019-05-30T23:00:58Z" level=info msg="couchbase-operator v1.2.0 (릴리스)" module=main
time="2019-05-30T23:00:58Z" level=info msg="리소스 잠금 얻기" module=main
time="2019-05-30T23:00:58Z" level=info msg="이벤트 레코더 시작 중" module=main
time="2019-05-30T23:00:58Z" level=info msg="카우치베이스-운영자 리더 선출 시도 중" module=main
time="2019-05-30T23:00:58Z" level=info msg="내가 리더입니다, 운영자 시작을 시도합니다" module=main
time="2019-05-30T23:00:58Z" level=info msg="카우치베이스-운영자 컨트롤러 생성 중" module=main
time="2019-05-30T23:00:58Z" level=info msg="Event(v1.ObjectReference{Kind:\"Endpoints\", Namespace:\"emart\", Name:\"couchbase-operator\", UID:\"c96ae600-832e-11e9-9cec-0e104d8254ae\", APIVersion:\"v1\", ResourceVersion:\"950158\", FieldPath:\"\"}): type: 'Normal' reason: 'LeaderElection' couchbase-operator-6cbc476d4d-2kps4가 리더가 됨" module=event_recorder3. 퍼시스턴트 볼륨을 사용하여 카우치베이스 클러스터 배포하기
시스템의 성능과 SLA가 가장 중요한 프로덕션 환경에서는 항상 퍼시스턴트 볼륨을 사용하여 Couchbase 클러스터를 배포하는 것이 도움이 되기 때문에 이를 계획해야 합니다:
- 데이터 복구 가능성: 퍼시스턴트 볼륨은 파드가 종료되는 경우 파드 내에 연결된 데이터를 복구할 수 있게 해준다. 이렇게 하면 데이터 손실을 방지하고 데이터 또는 인덱스 서비스를 사용할 때 시간이 많이 소요되는 인덱스 생성을 피할 수 있습니다.
- 파드 재배치: 쿠버네티스는 CPU 및 메모리 제한과 같은 리소스 임계값에 도달한 파드를 퇴출할 수 있다. 퍼시스턴트 볼륨으로 백업되는 파드는 다운타임이나 데이터 손실 없이 다른 노드에서 종료 및 재시작할 수 있습니다.
- 동적 프로비저닝: 운영자는 클러스터 확장에 따라 필요에 따라 퍼시스턴트 볼륨을 생성하므로 배포 전에 클러스터 스토리지를 사전 프로비저닝할 필요성이 줄어듭니다.
- 클라우드 통합: 쿠버네티스는 AWS 및 GCE와 같은 주요 클라우드 공급업체에서 제공되는 네이티브 스토리지 프로비저닝과 통합됩니다.
다음 섹션에서는 다양한 가용성 영역에서 스토리지 클래스를 정의하고 퍼시스턴트 볼륨 클레임 템플릿을 빌드하는 방법을 살펴보겠습니다. couchbase-cluster-with-pv-1.2.yaml 파일을 만듭니다.
3.1. 카우치베이스 관리 콘솔용 시크릿 만들기
가장 먼저 해야 할 일은 로그인하는 동안 관리 웹 콘솔에서 사용할 비밀 자격 증명을 만드는 것입니다. 편의를 위해 오퍼레이터 패키지에 샘플 시크릿이 제공됩니다. 이 시크릿을 쿠버네티스 클러스터에 푸시하면 사용자 이름은 Administrator로, 비밀번호는 password로 설정됩니다.
다음 명령을 실행하여 비밀을 Kubernetes 클러스터에 푸시합니다:
$ kubectl create -f secret.yaml --namespace emart
출력한다:
비밀/cb-example-auth 생성됨3.2 EKS 클러스터용 AWS 스토리지 클래스 생성하기
이제 퍼시스턴트볼륨을 카우치베이스 서비스(데이터, 인덱스, 검색 등)에 사용하려면 먼저 각 가용 영역(AZ)에 스토리지 클래스(SC)를 생성해야 합니다. 우리 환경에 어떤 스토리지 클래스가 있는지 확인하는 것부터 시작하겠습니다.
kubectl 명령을 사용하여 이를 확인해 보겠습니다:
$ kubectl 스토리지 클래스 가져오기
출력한다:
GP2 (기본값) kubernetes.io/aws-ebs 12m위의 출력은 기본 gp2 스토리지 클래스만 있고 Couchbase 클러스터를 배포할 모든 AZ에 별도의 스토리지 클래스를 생성해야 한다는 것을 의미합니다.
1) AWS 스토리지 클래스 매니페스트 파일을 생성합니다. 아래 예제는 스토리지 클래스의 구조를 정의합니다(sc-gp2.yaml), Amazon EBS gp2 볼륨 유형(일명 범용 SSD 드라이브)을 사용합니다. 이 스토리지는 나중에 볼륨클레임템플릿.
AWS 스토리지 클래스에 사용할 수 있는 옵션에 대한 자세한 내용은 쿠버네티스 문서에서 [AWS](https://kubernetes.io/docs/concepts/storage/storage-classes/#aws)를 참조한다.
apiVersion: storage.k8s.io/v1
종류: StorageClass
메타데이터:
레이블
k8s-애드온: storage-aws.addons.k8s.io
이름: gp2-멀티-존
매개변수
유형: gp2
프로비저너: 쿠버네티스.io/aws-ebs
리클레임폴리시: 삭제
볼륨바인딩모드: WaitForFirstConsumer
reclaimPolicy2) 이제 kubectl 명령을 사용하여 위에서 정의한 매니페스트 파일에서 스토리지 클래스를 물리적으로 생성합니다.
$ kubectl create -f sc-gp2.yaml
출력한다:
스토리지클래스.storage.k8s.io/gp2-멀티-존 생성됨
3) 새 스토리지 클래스 확인
모든 스토리지 클래스를 생성한 후에는 kubectl 명령어를 통해 확인할 수 있습니다:
$ kubectl get sc --namespace emart
출력한다:
네임 프로비저너 나이
gp2 (기본값) kubernetes.io/aws-ebs 16시간
gp2-멀티-존 kubernetes.io/aws-ebs 96초
3.3. 서버 그룹 인식
서버 그룹 인식은 그룹 정의를 통해 대규모 인프라 장애로부터 클러스터를 보호하므로 가용성이 향상됩니다.
그룹은 클러스터 노드의 물리적 분포에 따라 정의해야 합니다. 예를 들어, 그룹에는 단일 서버 랙에 있는 노드 또는 클라우드 배포의 경우 단일 가용성 영역에 있는 노드만 포함되어야 합니다. 따라서 정전이나 네트워크 장애로 인해 서버 랙 또는 가용성 영역을 사용할 수 없게 되는 경우, 그룹 장애 조치를 활성화하면 영향을 받는 데이터에 계속 액세스할 수 있습니다.
따라서 Couchbase 서버를 별도의 서버에 배치합니다. spec.servers.serverGroups를 사용하여 세 개의 서로 다른 AZ(us-east-1a/b/c)에서 실행되는 물리적으로 분리된 EKS 노드에 매핑할 것입니다:
사양:
서버
- 이름: 데이터-이스트-1A
size: 1
서비스:
- data
serverGroups:
- US-EAST-1A3.4. 퍼시스턴트 볼륨 클레임 템플릿에 스토리지 클래스 추가하기
서버 그룹이 정의되고 세 개의 AZ 모두에서 스토리지 클래스를 사용할 수 있으므로 이제 동적 스토리지 볼륨을 생성하여 영구 데이터가 필요한 각 Couchbase 서버에 마운트하겠습니다. 이를 위해 먼저 퍼시스턴트 볼륨 클레임 템플릿을 정의합니다. couchbase-cluster.yaml 파일(운영자 폴더에서 찾을 수 있음)을 열어야 합니다.
Spec:
볼륨클레임템플릿:
- 메타데이터:
이름: pvc-default
spec:
storageClassName: gp2-multi-zone
리소스:
요청
storage: 1Gi
- 메타데이터:
이름: pvc-data
spec:
storageClassName: gp2-multi-zone
리소스
요청
storage: 5Gi
- 메타데이터:
이름: pvc-index
spec:
storageClassName: gp2-multi-zone
리소스:
요청
storage: 3Gi클레임 템플릿을 추가한 후 마지막 단계는 각 영역에서 볼륨 클레임 템플릿을 서버 그룹과 적절하게 페어링하는 것이다. 예를 들어, 데이터-이스트-1a라는 이름의 서버-그룹 내의 파드는 볼륨클레임템플릿을 사용해야 한다. PVC 데이터 를 사용하여 데이터를 저장하고 PVC 기본값 Couchbase 바이너리 및 로그 파일용입니다.
예를 들어 다음은 서버 그룹과 연결된 볼륨클레임템플릿의 페어링을 보여줍니다:
사양:
서버
- 이름: 데이터-이스트-1A
size: 1
서비스:
- data
serverGroups:
- us-east-1a
pod:
볼륨 마운트:
기본값: pvc-default
데이터: pvc-data
- 이름: 데이터-이스트-1b
size: 1
서비스
- data
serverGroups:
- US-EAST-1B
pod:
볼륨 마운트:
기본값: pvc-default
데이터: pvc-data
- name: data-east-1c
size: 1
서비스
- data
serverGroups:
- us-east-1c
pod:
볼륨 마운트:
기본값: pvc-default
데이터: pvc-data해당 AZ의 영구 볼륨 클레임 템플릿을 사용하여 각각 자체 AZ에 위치한 세 개의 개별 데이터 서버 그룹(data-east-1a/-1b/-1c)을 만들었습니다. 이제 동일한 개념을 사용하여 인덱스와 쿼리 서비스를 추가하고 별도의 서버 그룹에 할당하여 데이터 노드와 독립적으로 확장할 수 있도록 합니다.
3.5. 카우치베이스 클러스터 배포
퍼시스턴트 볼륨을 사용하여 3개의 서로 다른 영역에 Couchbase 클러스터를 배포하기 위한 전체 사양은 다음 문서에서 확인할 수 있습니다. couchbase-cluster-with-pv-1.2.yaml 파일을 생성합니다. 이 파일과 이 문서에 사용된 다른 샘플 yaml 파일은 이 git 리포지토리에서 다운로드할 수 있습니다.
yaml 파일을 열면 데이터 서비스를 3개의 AZ에 배포하지만 인덱스 및 쿼리 서비스는 2개의 AZ에만 배포하고 있다는 점에 유의하세요. 프로덕션 요구 사항에 맞게 구성을 변경할 수 있습니다.
이제 kubectl을 사용하여 클러스터를 배포한다.
$ kubectl create -f couchbase-cluster-with-pv-1.2.yaml --save-config --namespace emart그러면 Couchbase 클러스터 배포가 시작되고 모든 것이 정상적으로 진행되면 위의 구성 파일에 따라 서비스를 호스팅하는 5개의 Couchbase 클러스터 파드가 생성됩니다. 진행 상황을 확인하려면 다음 명령을 실행하여 파드 생성 진행 상황을 감시(-w 인수)합니다:
$ kubectl get pods --namespace emart -w
출력한다:
이름 준비 상태 재시작 나이
cb_eks_demo-0000 1/1 Running 0 2m
cb_eks_demo-0001 1/1 Running 0 1m
cb_eks_demo-0002 1/1 Running 0 1m
cb_eks_demo-0003 1/1 Running 0 37s
cb_eks_demo-0004 1/1 컨테이너 생성 0 1초
카우치베이스-운영자-8C554CBC7-N8RHG 1/1 실행 중 0 19시간어떤 이유로든 예외가 발생하면 couchbase-operator 로그 파일에서 예외에 대한 자세한 내용을 확인할 수 있습니다. 로그의 마지막 20줄을 표시하려면 운영자 파드의 이름을 복사한 후 운영자 이름을 사용자 환경의 이름으로 바꾸어 아래 명령을 실행하세요.
$ kubectl 로그 couchbase-operator-8c554cbc7-98dkl --namespace emart --tail 20
출력한다:
time="2019-02-13T18:32:26Z" level=info msg="클러스터가 존재하지 않으므로 운영자가 클러스터를 생성하려고 시도 중입니다" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:26Z" level=info msg="데이터 노드에 대한 헤드리스 서비스 생성 중" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:26Z" level=info msg="데이터 노드용 NodePort UI 서비스(cb-eks-demo-ui) 생성 중" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:26Z" level=info msg="Couchbase 엔터프라이즈-5.5.3을 실행하는 포드(cb-eks-demo-0000) 생성 중" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:34Z" level=warning msg="node init: 오류로 실패했습니다 [Post https://cb-eks-demo-0000.cb-eks-demo.emart.svc:8091/node/controller/rename: 다이얼 tcp: 10.100.0.10:53에서 cb-eks-demo-0000.cb-eks-demo.emart.svc 조회: 해당 호스트 없음] ...다시 시도중" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:39Z" level=info msg="운영자가 관리할 멤버(cb-eks-demo-0000)를 추가했습니다." cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:39Z" level=info msg="클러스터의 첫 번째 노드를 초기화하는 중" cluster-name=cb-eks-demo module=cluster
time="2019-02-13T18:32:39Z" level=info msg="실행 시작..." cluster-name=cb-eks-demo module=cluster모든 파드가 준비되면 웹 콘솔에서 클러스터 상태를 볼 수 있도록 Couchbase 클러스터 포드 중 하나를 포트 포워딩할 수 있습니다. 포트 포워딩하려면 다음 명령을 실행하세요.
$ kubectl 포트 포워드 cb-eks-demo-0000 18091:18091 --네임스페이스 emart이 시점에서 브라우저를 열고 https://localhost:18091 을 입력하면 서버 통계 모니터링, 버킷 생성, 쿼리 실행을 한 곳에서 모두 수행할 수 있는 Couchbase 웹 콘솔이 나타납니다.
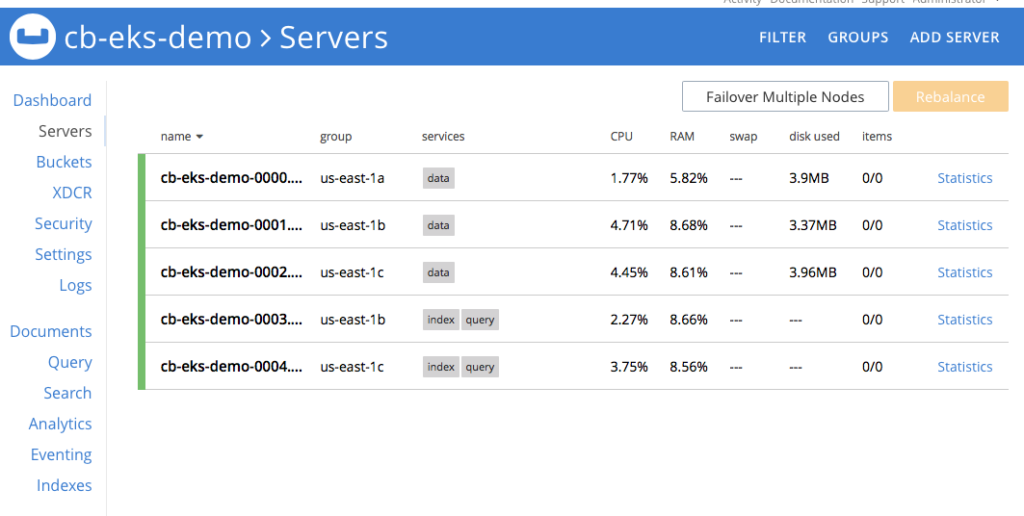
그림 2: 퍼시스턴트 볼륨을 사용하는 5노드 카우치베이스 클러스터.
참고: 우리를 방문하십시오 git 저장소 를 클릭하여 위 워크샵의 최신 버전을 찾아보세요.
결론
Couchbase 자율 운영자는 쿠버네티스 플랫폼에서 Couchbase 클러스터의 관리와 오케스트레이션을 원활하게 해줍니다. 이 운영자를 독특하게 만드는 것은 다양한 클라우드 벤더(AWS, Azure, GCP, RedHat OpenShift 등)에서 제공하는 스토리지 클래스를 쉽게 사용하여 영구 볼륨을 생성한 다음 Couchbase 데이터베이스 클러스터에서 데이터를 영구적으로 저장하는 데 사용할 수 있는 기능입니다. 포드 또는 컨테이너에 장애가 발생하는 경우, Kubernetes는 자동으로 새 포드/컨테이너를 다시 인스턴스화하고 퍼시스턴트 볼륨을 간단히 다시 마운트하기 때문에 복구가 빠릅니다. 또한 퍼시스턴트 볼륨을 사용하지 않는 경우 전체 복구가 아닌 델타 복구만 필요하므로 인프라 장애 복구 중 시스템의 SLA를 유지하는 데 도움이 됩니다.
이 문서에서는 Amazon EKS에서 퍼시스턴트 볼륨을 설정하는 방법을 단계별로 안내했지만, 다른 오픈 소스 Kubernetes 환경(AKS, GKE 등)을 사용하는 경우에도 동일한 단계를 적용할 수 있습니다. Couchbase Autonomous Operator를 사용해 보시고 사용 경험을 알려주시기 바랍니다.