저자 및 엔지니어링 팀: 빙지에 미아오, 케샤브 머시, 마르코 그레코, 프라티바 비사라할리. Couchbase, Inc.
규칙 기반 최적화 도구는 모든 것에 대한 규칙과 비용을 알고 있습니다. 오스카 와일드
초록
Couchbase는 분산형 JSON 데이터베이스입니다. 분산 데이터 처리, 고성능 인덱싱 및 선언적 쿼리 언어 N1QL과 함께 검색 인덱스, 이벤트 및 분석을 제공합니다. N1QL(Non First Normal Query Language)은 JSON용 SQL입니다. N1QL은 관계형에 SQL이 있다면 JSON에 SQL입니다. 개발자가 무엇을 해야 하는지 말하면 N1QL 엔진이 "어떻게"를 알아냅니다. 현재 N1QL 최적화 도구는 규칙 기반 최적화 도구. SQL용 비용 기반 최적화 도구(CBO)는 다음에서 개발되었습니다. 약 40년 전 IBM RDBMS의 성공과 개발자/DBA의 생산성에 매우 중요한 역할을 해왔습니다. NoSQL 데이터베이스는 약 10년 전에 발명되었습니다. 발명 직후, NoSQL 데이터베이스는 제한된 액세스 경로와 최적화 도구 기능을 갖춘 SQL과 유사한 쿼리 언어를 추가하기 시작했습니다. 대부분은 규칙 기반 최적화 도구를 사용하거나 단순한 스칼라 값(문자열, 숫자, 부울 등)에 대해서만 비용 기반 최적화를 지원합니다.
JSON 모델에 대한 CBO를 만들려면 먼저 통계를 수집하고 정리해야 합니다. JSON의 유연한 스키마에서 통계를 수집, 저장 및 사용하려면 어떻게 해야 할까요? 객체, 배열, 객체 내의 요소에 대한 통계는 어떻게 수집하나요? 옵티마이저 내에서 어떻게 효율적으로 사용할 수 있나요?
루카스 에더 "비용 기반 최적화 도구는 SQL을 완전히 선언적으로 만듭니다."라고 말한 적이 있습니다. 일리가 있는 말입니다. Couchbase 6.5(현재 GA)에는 N1QL용 비용 기반 최적화 도구가 있습니다. 이 문서에서는 N1QL 비용 기반 최적화 도구(CBO)에 대해 소개합니다. Couchbase 6.5. CBO는 특허 출원 중인 개발자 미리 보기 기능입니다. 이 문서에서는 CBO를 사용하는 방법과 구현 세부 사항에 대해 설명합니다.
이 문서의 PDF 버전은 여기에서 다운로드.
목차
- 초록
- N1QL 소개
- N1QL에 비용 기반 최적화 도구 사용
- N1QL 옵티마이저
- N1QL용 비용 기반 최적화 도구
- N1QL CBO용 통계 수집
- 요약
- 리소스 N1QL 규칙 기반 옵티마이저
- 참조
N1QL 소개
정보 기술 업계에서 JSON이 정보 변경을 위한 공용어로 점점 더 많이 받아들여짐에 따라, JSON 문서를 기본적으로 저장, 업데이트 및 쿼리하는 리포지토리에 대한 필요성이 기하급수적으로 증가했습니다. SQL은 다음에서 JSON을 조작하는 기능을 추가했습니다. SQL:2016. SQL:2016에는 JSON을 조작하는 새로운 스칼라 및 테이블 함수가 추가되었습니다. 다른 접근 방식은 JSON을 데이터 모델로 취급하고 기본적으로 JSON에서 작동하도록 언어를 설계하는 것입니다. N1QL 그리고 SQL++ 는 후자의 접근 방식을 사용하여 스칼라, 객체, 배열, 객체 배열, 객체 내의 배열 등에 대한 자연스러운 액세스를 제공합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SQL:2016: From: Microsoft SQL Server. SELECT Name,Surname, JSON_VALUE(jsonCol,'$.info.address.PostCode') AS PostCode, JSON_VALUE(jsonCol,'$.info.address."Address Line 1"')+' ' +JSON_VALUE(jsonCol,'$.info.address."Address Line 2"') AS Address, JSON_QUERY(jsonCol,'$.info.skills') AS Skills FROM People WHERE ISJSON(jsonCol) > 0 AND JSON_VALUE(jsonCol,'$.info.address.Town')='Belgrade' AND Status='Active' ORDER BY JSON_VALUE(jsonCol,'$.info.address.PostCode') |
|
1 2 3 4 5 6 7 8 9 10 |
N1QL: Same query written in N1QL on the JSON model SELECT Name,Surname, jsonCol.info.address.PostCode AS PostCode, (jsonCol.info.address.`Address Line 1` + ' ' + jsonCol.`info.address.`Address Line 2`) AS Address, jsonCol.info.skills' AS Skills FROM People WHERE jsonCol.info.address.Town = 'Belgrade' AND Status='Active' ORDER BY jsonCol.info.address.PostCode |
다음에서 N1QL에 대해 알아보세요. https://query-tutorial.couchbase.com/
카우치베이스 서버:
카우치베이스에는 N1QL을 지원하는 엔진이 있습니다:
- 쿼리 서비스의 대화형 애플리케이션을 위한 N1QL.
- 애널리틱스 서비스의 애널리틱스용 N1QL.
이 문서에서는 쿼리 서비스에서 구현된 쿼리용 N1QL(대화형 애플리케이션)에 중점을 둡니다. N1QL로 조작되는 모든 데이터는 데이터 서비스에서 관리하는 Couchbase 데이터 저장소 내에 JSON으로 저장됩니다.
JSON에 대한 쿼리 처리를 지원하기 위해 N1QL은 여러 가지 방법으로 SQL 언어를 확장합니다:
-
- 반구조화된 자체 설명 JSON에서 유연한 스키마를 지원합니다.
- 스칼라 값, 객체, 배열, 스칼라 값의 객체, 스칼라 값의 배열, 객체의 배열, 배열의 배열 등 JSON의 요소에 액세스하고 조작할 수 있습니다.
- 문서에서 누락된 키-값 쌍을 나타내는 새로운 부울 값인 MISSING을 도입하여 알려진 null 값과 구별됩니다. 이것은 3값 논리 에 4값 논리.
- 배열을 생성하고 배열을 평평하게 만드는 NEST 및 UNNEST 연산을 위한 새로운 연산이 각각 추가되었습니다.
- JSON 스칼라, 객체 및 배열로 작업하도록 JOIN 연산을 확장합니다.
- 이러한 JSON 문서의 처리 속도를 높이기 위해 하나 이상의 스칼라 값, 배열의 스칼라 값, 중첩된 객체, 중첩된 배열, 객체, 배열 객체, 배열 요소에 대해 전역 보조 인덱스를 만들 수 있습니다.
- 반전 검색 인덱스를 사용하여 통합 검색 기능을 추가합니다.
N1QL에 CBO 사용
Couchbase 6.5(현재 GA)에서 (CBO)를 도입했습니다. 자세한 내용을 살펴보기 전에 이 기능을 사용하는 방법을 살펴보겠습니다.
- 새 버킷을 만들고 샘플 버킷 이동 샘플에서 데이터를 로드합니다.
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO hotel(KEY id, VALUE h) SELECT META().id id, h FROM `travel-sample` h WHERE type = "hotel" |
- 호텔 문서 샘플
다음은 호텔 문서 예시입니다. 이러한 값은 스칼라, 객체 및 배열입니다. 이에 대한 쿼리는 이러한 모든 필드에 액세스하고 처리합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
{ "hotel": { "address": "Capstone Road, ME7 3JE", "alias": null, "checkin": null, "checkout": null, "city": "Medway", "country": "United Kingdom", "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "directions": null, "email": null, "fax": null, "free_breakfast": true, "free_internet": false, "free_parking": true, "geo": { "accuracy": "RANGE_INTERPOLATED", "lat": 51.35785, "lon": 0.55818 }, "id": 10025, "name": "Medway Youth Hostel", "pets_ok": true, "phone": "+44 870 770 5964", "price": null, "public_likes": [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Ms. Moses Feeney", "Elnora Trantow" ], "reviews": [ { "author": "Ozella Sipes", "content": "This was our 2nd trip here and we enjoyed it as much or more than last year. Excellent location across from the French Market and just across the street from the streetcar stop. Very convenient to several small but good restaurants. Very clean and well maintained. Housekeeping and other staff are all friendly and helpful. We really enjoyed sitting on the 2nd floor terrace over the entrance and \"people-watching\" on Esplanade Ave., also talking with our fellow guests. Some furniture could use a little updating or replacement, but nothing major.", "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } }, { "author": "Barton Marks", "content": "We found the hotel de la Monnaie through Interval and we thought we'd give it a try while we attended a conference in New Orleans. This place was a perfect location and it definitely beat staying downtown at the Hilton with the rest of the attendees. We were right on the edge of the French Quarter withing walking distance of the whole area. The location on Esplanade is more of a residential area so you are near the fun but far enough away to enjoy some quiet downtime. We loved the trolly car right across the street and we took that down to the conference center for the conference days we attended. We also took it up Canal Street and nearly delivered to the WWII museum. From there we were able to catch a ride to the Garden District - a must see if you love old architecture - beautiful old homes(mansions). We at lunch ate Joey K's there and it was excellent. We ate so many places in the French Quarter I can't remember all the names. My husband loved all the NOL foods - gumbo, jambalya and more. I'm glad we found the Louisiana Pizza Kitchen right on the other side of the U.S. Mint (across the street from Monnaie). Small little spot but excellent pizza! The day we arrived was a huge jazz festival going on across the street. However, once in our rooms, you couldn't hear any outside noise. Just the train at night blowin it's whistle! We enjoyed being so close to the French Market and within walking distance of all the sites to see. And you can't pass up the Cafe du Monde down the street - a busy happenning place with the best French dougnuts!!!Delicious! We will defintely come back and would stay here again. We were not hounded to purchase anything. My husband only received one phone call regarding timeshare and the woman was very pleasant. The staff was laid back and friendly. My only complaint was the very firm bed. Other than that, we really enjoyed our stay. Thanks Hotel de la Monnaie!", "date": "2015-03-02 19:56:13 +0300", "ratings": { "Business service (e.g., internet access)": 4, "Check in / front desk": 4, "Cleanliness": 4, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } } ], "state": null, "title": "Gillingham (Kent)", "tollfree": null, "type": "hotel", "url": "https://www.yha.org.uk", "vacancy": true } } |
- 실행하려는 쿼리를 알고 나면 키를 사용하여 인덱스를 생성하기만 하면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX i3 ON `hotel`(name, country); CREATE INDEX i4 ON `hotel`(country, name); CREATE INDEX i3 ON `hotel`(country, city); CREATE INDEX i4 ON `hotel`(city, country); /* Array indexes on the array keys you want to filter on. CREATE INDEX i5 ON `hotel`(DISTINCT public_likes); CREATE INDEX i6 ON `hotel`(DISTINCT ARRAY r.ratings.Overall FOR r IN reviews END); /* Index on the fields within the geo object */ CREATE INDEX i7 ON `hotel`(geo.lat, geo.lon) |
- 이제 필터를 적용할 필드에 대한 통계를 수집합니다. 일반적으로 색인하는 필드를 색인합니다. 따라서 해당 필드에 대한 통계도 수집하려고 합니다. CREATE INDEX 문과 달리 UPDATE STASTICS 문에서는 키의 순서가 영향을 미치지 않습니다.
UPDATE STATISTICS for `hotel` (type, address, city, country, free_breakfast, id, phone);
- 간단한 스칼라 배열의 인덱스입니다. public_likes는 문자열 배열입니다. DISTINCT public_likes는 전체 public_likes 배열이 아닌 public_likes의 각 요소에 대한 인덱스를 생성합니다. 배열 통계에 대한 자세한 내용은 이 글의 뒷부분에서 설명합니다.
UPDATE STATISTICS for `hotel`(DISTINCT public_likes);
- 이제 이 문장을 실행하고 설명하고 관찰하세요. CBO는 위에서 수집한 통계를 기반으로 술어(country = '프랑스')
|
1 2 3 4 |
SELECT count(*) FROM `hotel` WHERE country = 'France'; { "$1": 140 } |
- 다음은 EXPLAIN의 스니펫입니다. 설명 출력에는 카디널리티 추정치가 있고 프로필 출력에는 각 연산자에서 정규화된 실제 문서(행, 키)가 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
"#operator": "IndexScan3", "cardinality": 141.54221635883903, "cost": 71.19573482849603, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`type`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i2", SELECT count(*) FROM `hotel` WHERE country = 'United States'; { "$1": 361 } "cardinality": 361.7189973614776, "cost": 181.94465567282322, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`type`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i2", |
- 여러 술어에 대한 비용 계산을 결합합니다. 실제 결과는 카디널리티 추정치에 비례한다는 점에 유의하세요. 조인 선택도 추정 는 상관관계로 인해 추정하기 어렵고 추가적인 기술이 필요합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
SELECT count(*) FROM `hotel` WHERE country = 'United States' and name LIKE 'A%'; { "$1": 7 } "cardinality": 13.397476328354337, "cost": 8.748552042415382, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`name`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i4", SELECT count(*) FROM `hotel` WHERE country = 'United States' and name = 'Ace Hotel DTLA' { "$1": 1 } "#operator": "IndexScan3", "cardinality": 0.39466325234388644, "cost": 0.25771510378055784, "covers": [ "cover ((`hotel`.`name`))", "cover ((`hotel`.`country`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i3", select count(1) from hotel where country = 'United States' and city = 'San Francisco'; { "$1": 132 } "#operator": "IndexScan3", "cardinality": 361.7189973614776, "cost": 181.94465567282322, "index": "i2", "index_id": "a020ba7594f7c045", "index_projection": { "primary_key": true }, "keyspace": "hotel", |
- 배열 술어에 대한 계산: ANY. 여기에서는 위의 UPDATE 통계에서 표현식(DISTINCT public_likes)에 대한 통계 컬렉션을 사용합니다. 배열 통계는 배열 인덱스 키가 일반 인덱스 키와 다른 것과 같은 방식으로 일반 스칼라 통계와 다릅니다. public_keys의 히스토그램에는 동일한 문서의 값이 두 개 이상 포함됩니다. 따라서 모든 계산에서 이를 고려해야 실제에 가까운 추정치를 얻을 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT COUNT(1) FROM hotel WHERE ANY p IN public_likes SATISFIES p LIKE 'A%' END { "$1": 272 } "#operator": "DistinctScan", "cardinality": 151.68407386905272, "cost": 144.52983565532256, "scan": { "#operator": "IndexScan3", "cardinality": 331.49044875073974, "cost": 143.53536430907033, "covers": [ "cover ((distinct ((`hotel`.`public_likes`))))", "cover ((meta(`hotel`).`id`))" ], |
- 배열의 객체 내 필드에서 배열 술어에 대한 계산: ANY r IN reviews SATISFIES r.ratings.Overall = 4 END. 표현식에 대한 통계 수집: (DISTINCT ARRAY r.ratings.Overall FOR r IN reviews END). 통계 수집 표현식은 인덱스 키 배열 표현식과 정확히 동일해야 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
SELECT COUNT(1) FROM hotel WHERE ANY r IN reviews SATISFIES r.ratings.Overall = 4 END { "$1": 617 } "#operator": "IndexScan3", "cardinality": 621.4762784966113, "cost": 206.95160073937154, "covers": [ "cover ((distinct (array ((`r`.`ratings`).`Overall`) for `r` in (`hotel`.`reviews`) end)))", "cover ((meta(`hotel`).`id`))", "cover (count(1))" ], "filter_covers": { "cover (any `r` in (`hotel`.`reviews`) satisfies (((`r`.`ratings`).`Overall`) = 4) end)": true }, "index": "i6", SELECT COUNT(1) FROM hotel WHERE ANY r IN reviews SATISFIES r.ratings.Overall < 2 END { "$1": 201 } "#operator": "DistinctScan", "cardinality": 182.14723292266834, "cost": 69.4615304990758, "scan": { "#operator": "IndexScan3", "cardinality": 206.73074553296368, "cost": 68.84133826247691, "covers": [ "cover ((distinct (array ((`r`.`ratings`).`Overall`) for `r` in (`hotel`.`reviews`) end)))", "cover ((meta(`hotel`).`id`))" ], "filter_covers": { "cover (any `r` in (`hotel`.`reviews`) satisfies (((`r`.`ratings`).`Overall`) < 2) end)": true }, "index": "i6", |
N1QL 옵티마이저
쿼리 실행 흐름:
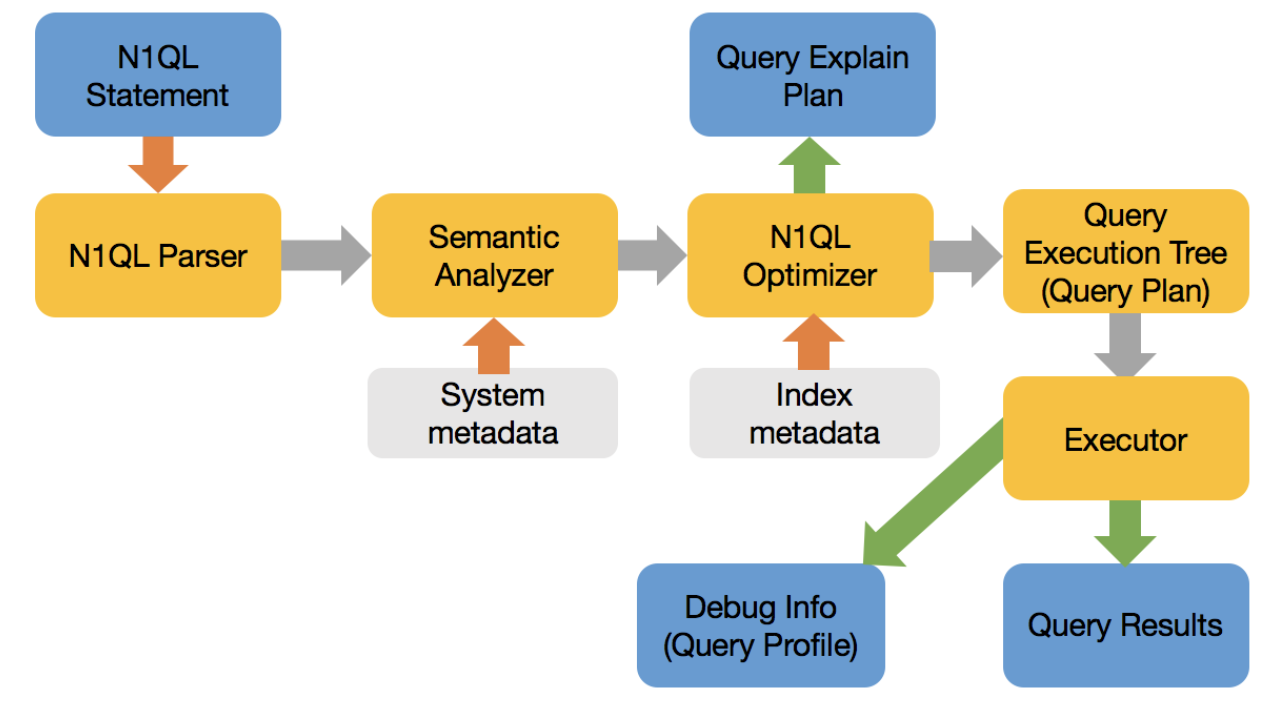
최적화 도구는 크게 다음과 같은 작업을 수행합니다:
- 쿼리를 최적의 동등한 형태로 다시 작성하여 최적화와 선택이 더 쉬워지도록 합니다.
- 각 키 공간(테이블에 해당)에 대한 액세스 경로를 선택합니다.
- 각 키 스페이스에 대해 하나 이상의 인덱스를 선택합니다.
- FROM 절에 있는 모든 조인에 대한 조인 순서를 선택합니다. N1QL 옵티마이저는 아직 조인 순서를 다시 지정하지 않습니다.
- 각 조인에 대해 조인 유형(예: 중첩 루프 또는 해시 조인)을 선택합니다.
- 마지막으로 쿼리 실행 트리(계획)를 만듭니다.
이 백서에서 N1QL의 규칙 기반 최적화 도구에 대해 설명했습니다: Couchbase N1QL 쿼리 최적화에 대한 심층 분석.
이 문서에서는 주로 SELECT 문에 대해 논의하지만, CBO는 업데이트, 삭제, 병합 및 INSERT(SELECT와 함께) 문에 대한 쿼리 계획을 선택합니다. 도전 과제, 동기 부여 및 해결책은 이러한 모든 DML 문에 동일하게 적용됩니다.
N1QL에는 다음과 같은 액세스 방법이 있습니다:
- 가치 스캔
- 키 스캔
- 인덱스 스캔
- 커버링 인덱스 스캔
- 기본 스캔
- 중첩 루프 조인
- 해시 조인
- 언네스트 스캔
비용 기반 최적화 도구(CBO)의 동기 부여
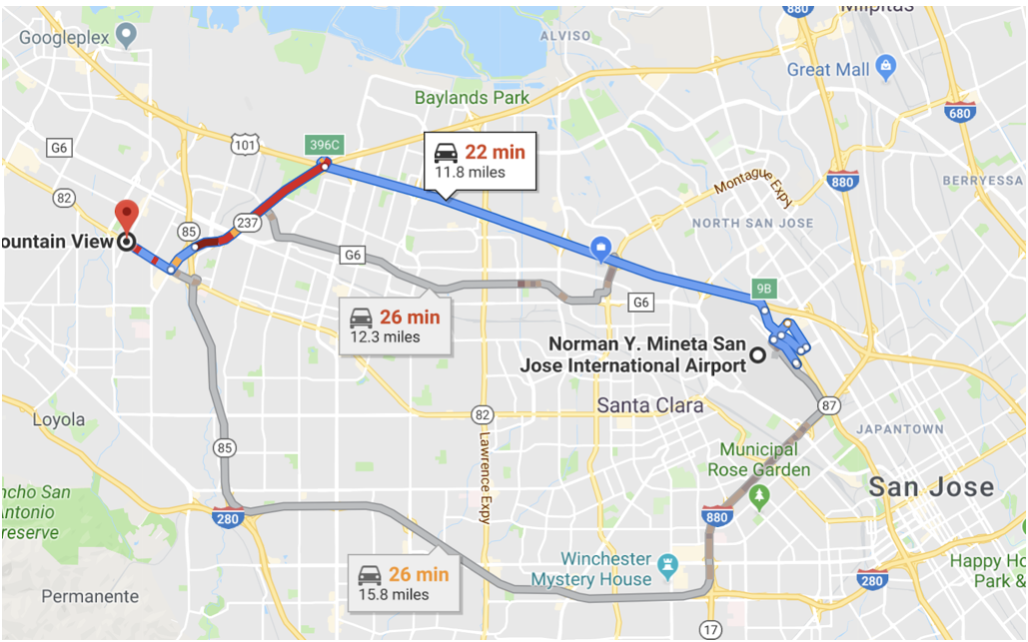
Google 지도가 현재 교통 상황과 상관없이 동일한 경로를 안내한다고 상상해 보세요. 비용 기반 라우팅은 현재 비용(현재 트래픽 흐름에 따른 예상 시간)을 고려하여 가장 빠른 경로를 찾습니다. 마찬가지로 비용 기반 최적화는 각 작업의 처리량(메모리, CPU, I/O)을 고려하고 대체 경로의 비용을 추정하여 비용이 가장 적은 쿼리 계획(쿼리 실행 트리)을 선택합니다. 위의 예에서 라우팅 알고리즘은 거리, 트래픽을 고려하여 최적의 경로 세 개를 제시했습니다.
관계형 시스템의 경우, CBO는 1970년 IBM에서 개발되었으며, 다음과 같이 설명됩니다. 정액 논문. N1QL의 현재 규칙 기반 최적화 도구에서 계획 결정은 다양한 액세스 경로에 대한 데이터 왜곡 및 술어에 적합한 데이터의 양과 무관하게 이루어집니다. 따라서 결정이 최적이 아닐 수 있기 때문에 쿼리 계획이 일관성 없이 생성되고 성능이 일관되지 않게 됩니다.
많은 JSON 데이터베이스가 있습니다: 몽고DB, 카우치베이스, 코스모스 DB, 카우치DB. 많은 관계형 데이터베이스는 JSON 내에서 데이터를 색인하고 액세스하기 위해 JSON 유형과 접근자 함수를 지원합니다. 그 중 Couchbase, CosmosDB, MongoDB는 JSON을 위한 선언적 쿼리 언어를 가지고 있으며 액세스 경로 선택 및 계획 생성을 수행합니다. 이들 모두는 휴리스틱에 기반한 규칙 기반 최적화 도구를 구현합니다. 아직 JSON 데이터베이스를 위한 비용 기반 최적화 도구에 대한 논문이나 설명서를 본 적이 없습니다.
NoSQL 및 Hadoop 세계에서는 비용 기반 최적화 도구의 몇 가지 예가 있습니다.
그러나 이들은 관계형 데이터베이스 옵티마이저와 마찬가지로 기본적인 스칼라 유형만 처리합니다. JSON을 통한 선언적 쿼리 언어의 성공에 매우 중요한 유형 변경, 스키마 변경, 객체, 배열, 배열 요소는 처리하지 못합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Consider the bucket customer: /* Create some indexes */ CREATE PRIMARY index ON customer; CREATE INDEX ix1 ON customer(name, zip, status); CREATE INDEX ix2 ON customer(zip, name, status); CREATE INDEX ix3 ON customer(zip, status, name); CREATE INDEX ix4 ON customer(name, status, zip); CREATE INDEX ix5 ON customer(status, zip, name); CREATE INDEX ix6 ON customer(status, name, zip); CREATE INDEX ix7 ON customer(status); CREATE INDEX ix8 ON customer(name); CREATE INDEX ix9 ON customer(zip); CREATE INDEX ix10 ON customer(status, name); CREATE INDEX ix11 ON customer(status, zip); CREATE INDEX ix12 ON customer(name, zip); |
쿼리 예시:
선택 * 고객으로부터 WHERE name = "Joe" AND zip = 94587 AND 상태 = "프리미엄";
간단한 질문입니다:
- 위의 모든 인덱스는 쿼리를 평가하는 데 유효한 액세스 경로입니다. 쿼리를 효율적으로 실행하려면 N1QL이 여러 인덱스 중 어떤 인덱스를 사용해야 하나요?
- 이에 대한 정답은 다음과 같습니다, 따라 다릅니다.. 이는 각 키에 대한 데이터의 통계적 분포에 따라 달라지는 카디널리티에 따라 달라집니다.
Joe라는 이름을 가진 사람이 백만 명, 우편번호 94587에 천만 명, 프리미엄 상태는 5명일 수 있습니다. Joe라는 이름을 가진 사람이 적거나 프리미엄 상태인 사람이 많거나 우편 번호 94587에 있는 고객이 적을 수도 있습니다. 각 필터에 해당하는 문서의 수와 합산된 통계가 결정에 영향을 미칩니다.
지금까지의 문제는 SQL 최적화와 동일합니다. 이 접근 방식을 따르는 것은 통계를 수집하고, 선택도를 계산하고, 쿼리 계획을 세우는 데 안전하고 건전합니다.
하지만 JSON은 다릅니다:
- 데이터 유형은 여러 문서 간에 변경될 수 있습니다. 한 문서에서는 숫자가, 다른 문서에서는 문자열이, 세 번째 문서에서는 객체가 될 수 있습니다. 통계를 수집하고, 저장하고, 효율적으로 사용하려면 어떻게 해야 할까요?
- 배열과 객체를 사용하여 복잡하고 중첩된 구조를 저장할 수 있습니다. 중첩 구조, 배열 등에 대한 통계를 수집한다는 것은 무엇을 의미하나요?
스칼라: 숫자, 부울, 문자열, null, 누락. 아래 문서에서 a, b, c, d, e는 모두 스칼라입니다.
{ "a": 482, "b": 2948.284, "c": "Hello, World", "d": null, "e": missing }
객체:
- 전체 개체 검색
- 개체 내 요소 검색
- 개체 내에서 속성의 정확한 값을 검색합니다.
- 계층 구조 내에서 요소, 배열, 객체를 일치시킵니다.
이 구조는 사용자가 쿼리에서 이러한 참조를 지정한 후에야 알 수 있습니다. 이러한 표현식이 술어에 있는 경우 실제로 존재하는지 확인한 다음 선택 여부를 결정하는 것이 좋습니다.
다음은 몇 가지 예입니다.
객체:
- 객체 내부의 스칼라를 참조합니다. 예: Name.fname, Name.lname
- 객체 배열 내부의 스칼라를 참조합니다. 예: 청구[*].status
- (1), (2) 및 (3)의 중첩된 경우. 사용 UNNEST 작동합니다.
- (1) ~ (4)의 경우 객체 또는 배열을 참조하세요.
배열:
- 전체 배열을 일치시킵니다.
- 배열의 스칼라 요소를 지원되는 유형(숫자, 문자열 등)과 일치시킵니다.
- 배열 내의 객체를 일치시킵니다.
- 배열의 배열 내 요소를 일치시킵니다.
- 계층 구조 내에서 요소, 배열, 객체를 일치시킵니다.
LET 표현식:
- WHERE 절에 사용된 표현식에 대한 선택성을 가져와야 합니다.
UNNEST 작업:
- 중첩되지 않은 문서에서 필터를 선택하면 올바른 (배열) 인덱스를 선택하는 데 도움이 됩니다.
JOINs: 안쪽, 왼쪽 바깥쪽, 오른쪽 바깥쪽
- 선택 항목에 참여하세요.
- 일반적으로 RDBMS에서도 큰 문제입니다. v1에는 없을 수 있습니다.
술어:
- 사용 키
- 스칼라 값 비교: =, >, =, <=, BETWEEN, IN
- 술어를 배열합니다: any, every, any & every, within
- 하위 쿼리
N1QL용 비용 기반 최적화 도구
이제 비용 기반 최적화 도구가 사용 가능한 데이터 통계를 기반으로 비용을 추정하고, 각 작업의 비용을 계산하고, 최적의 경로를 선택합니다.
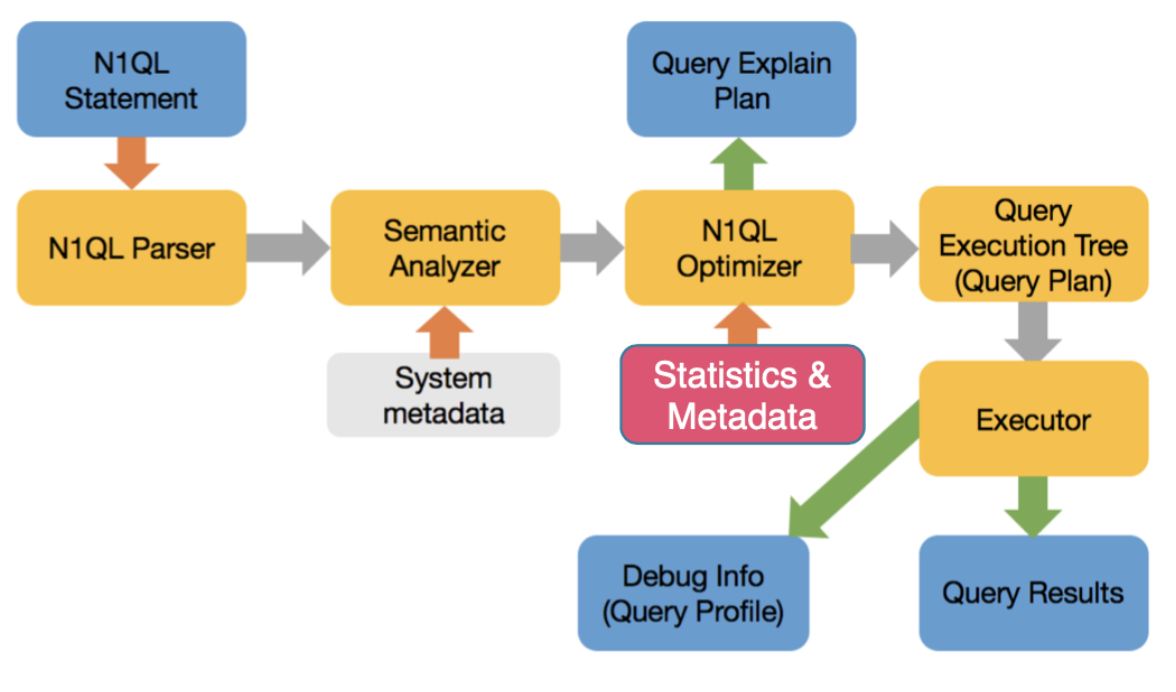
JSON용 비용 기반 옵티마이저의 과제
- 스칼라, 객체, 배열, 배열 요소 등 술어(필터)를 적용할 수 있는 모든 항목에 대한 통계를 수집합니다.
- 유형이 매우 다양한 필드에 통계를 저장할 수 있는 올바른 데이터 구조를 만듭니다.
- 위에서 수집한 복잡한 통계 집합에 대한 정확한 추정치를 효율적으로 계산하기 위해 통계를 사용하는 방법을 만듭니다.
- 적절한 통계를 사용하고, 유효한 액세스 경로를 고려하고, 쿼리 계획을 만드세요.
- 필드는 한 문서에서는 정수로, 다음 문서에서는 문자열로, 다른 문서에서는 배열로, 또 다른 문서에서는 누락될 수 있습니다. 히스토그램
N1QL 비용 기반 최적화 도구에 대한 접근 방식
N1QL 최적화 도구는 쿼리에 대해 가장 효율적인 실행 전략을 결정하는 역할을 합니다. 일반적으로 주어진 쿼리에 대해 수많은 대체 평가 전략이 있습니다. 이러한 대안은 시스템 리소스 요구 사항 및/또는 응답 시간에서 크게 다를 수 있습니다. 비용 기반 쿼리 최적화 도구는 정교한 열거 엔진(즉, 액세스 및 조인 계획의 검색 공간을 열거하는 엔진)을 사용하여 수많은 대체 쿼리 평가 전략과 이러한 대체 전략 중에서 선택할 수 있는 실행 비용의 세부 모델을 효율적으로 생성합니다.
N1QL 옵티마이저 작업은 다음과 같이 분류할 수 있습니다:
- 통계 수집
- 개별 필드에 대한 통계를 수집하고 각 필드에 대해 단일 히스토그램을 만듭니다(이 필드에 나타날 수 있는 모든 데이터 유형 포함).
- 사용 가능한 각 인덱스에 대한 통계를 수집합니다.
- 쿼리 재작성.
- 기본 규칙 기반 쿼리 재작성.
- 카디널리티 추정치
- 선택도 추정을 위해 사용 가능한 히스토그램 및 인덱스 통계를 사용합니다.
- 카디널리티 추정에 이 선택성을 사용합니다.
- 배열의 경우에는 그렇게 간단하지 않습니다.
- 주문에 참여하세요.
- 쿼리 고려: a JOIN b JOIN c
- 이는 ( b JOIN a JOIN c), (a JOIN c JOIN b) 등과 동일합니다.
- 올바른 순서를 선택하면 쿼리에 큰 영향을 미칩니다.
- Couchbase 6.5 구현에서는 아직 이 기능을 지원하지 않습니다. 이것은 SQL에서 해결책을 빌릴 수 있는 잘 알려진 문제입니다. JSON은 새로운 문제를 도입하지 않습니다. ON 절 술어에는 배열 술어가 포함될 수 있습니다. 이것은 로드맵에 있습니다.
- 쿼리 고려: a JOIN b JOIN c
- 조인 유형
- 규칙 기반 옵티마이저는 기본적으로 블록 중첩 루프를 사용했습니다. 해시 조인을 강제하려면 지시어를 사용해야 합니다. 또한 지시어는 빌드/프로브 쪽을 지정해야 합니다. 둘 다 바람직하지 않습니다.
- CBO가 조인 유형을 선택해야 합니다. 해시 조인을 선택하면 자동으로 빌드 및 프로브 쪽을 선택해야 합니다. 중첩 루프에 가장 적합한 내부/외부 키 스페이스 선택도 로드맵에 포함되어 있습니다.
N1QL CBO용 통계 수집
최적화 도구 통계는 비용 기반 최적화의 필수적인 부분입니다. 최적화 도구는 쿼리 실행의 다양한 단계에 대한 비용을 계산하며, 이 계산은 최적화 도구 통계라고 하는 서버의 물리적 엔티티의 다양한 측면에 대한 최적화 도구의 지식을 기반으로 합니다.
혼합 유형 처리
관계형 데이터베이스와 달리 JSON 문서의 필드에는 유형이 없습니다. 즉, 같은 필드에 여러 유형의 값이 존재할 수 있습니다. 따라서 배포는 서로 다른 유형의 값을 처리해야 합니다. 혼동을 피하기 위해 서로 다른 유형의 값을 서로 다른 분포 구간차원에 넣습니다. 즉, 각 유형에 대해 부분 구간차원(마지막 구간차원)을 가질 수 있습니다. 또한 특수 값인 MISSING, NULL, TRUE 및 FALSE를 특별히 처리합니다. 이러한 값(있는 경우)은 항상 오버플로 빈에 있습니다. N1QL에는 다양한 유형에 대해 미리 정의된 정렬 순서가 있으며, 정렬된 스트림의 시작 부분에 MISSING/NULL/TRUE/FALSE가 표시됩니다.
수집/버킷 통계
컬렉션이나 버킷의 경우, 수집합니다:
- 컬렉션/버킷에 있는 문서 수
- 평균 문서 크기
색인 통계
GSI 지수를 위해 수집합니다:
- 인덱스의 항목 수
- 색인 페이지 수
- 상주 비율
- 평균 아이템 크기
- 평균 페이지 크기
배포 통계
특정 필드의 경우 분포 통계도 수집하므로 "c1 = 100", "c1 >= 20" 또는 "c1 < 150"과 같은 술어에 대해 보다 정확한 선택도 추정이 가능합니다. 또한 "t1.c1 = t2.c2"와 같은 조인 조건에 대한 보다 정확한 선택도 추정치를 생성하며, 이는 t1.c1과 t2.c2 모두에 대한 분포 통계가 존재한다고 가정합니다.
최적화 도구 통계 수집
저희의 비전은 서버가 필요한 최적화 프로그램 통계를 자동으로 업데이트하는 것이지만, 초기 구현에서는 새로운 업데이트 통계 명령을 통해 최적화 프로그램 통계를 업데이트할 예정입니다.
UPDATE STATISTICS [FOR] <keyspace_reference> (<index_expressions>) [WITH <options>]
는 컬렉션 이름입니다(버킷도 지원할 수 있지만 현재로서는 미정입니다).
위의 명령은 분포 통계를 수집하는 명령으로, 는 분포 통계를 수집할 하나 이상의 (쉼표로 구분된) 표현식입니다. 필드, 중첩된 필드(중첩된 개체 내부, 예: location.lat), 배열에 대한 ALL 표현식 등 CREATE INDEX 명령과 동일한 표현식을 지원합니다.WITH 절은 선택 사항이며, 있는 경우 UPDATE STATISTICS 명령에 대한 옵션을 지정합니다. 옵션은 CREATE INDEX 또는 INFER와 같은 다른 명령에 대한 옵션 지정 방식과 유사하게 JSON 형식으로 지정됩니다.
현재 WITH 절에서 지원되는 옵션은 다음과 같습니다.:
- sample_size분포 통계 수집을 위해 사용자가 사용할 샘플 크기를 지정할 수 있습니다. 이 값은 정수입니다. 최소 표본 크기도 계산하며, 사용자가 지정한 표본 크기와 계산된 최소 표본 크기 중 더 큰 값을 사용합니다.
- 해상도분포 통계 수집을 위해 원하는 분포 구간차원(분포 구간차원의 세분성) 수를 지정합니다. 이 값은 실수로 지정되며 백분율로 지정됩니다. 예: {"해상도": 1.0}은 각 배포 구간에 전체 문서의 약 1%, 즉 ~100개의 배포 구간이 필요하다는 의미입니다. 기본 해상도는 1.0(분포 구간차원 100개)입니다. 최소 해상도 0.02(분포 구간차원 5000개)와 최대 해상도 5.0(분포 구간차원 20개)이 적용됩니다.
- 업데이트_통계_타임아웃시간 제한 값(초)을 지정할 수 있습니다. 시간 초과 기간에 도달하면 오류와 함께 UPDATE STATISTICS 명령이 시간 초과됩니다. 지정하지 않으면 기본 시간 초과 값은 사용된 샘플 수에 따라 계산됩니다.
혼합 유형 처리
관계형 데이터베이스와 달리 JSON 문서의 필드에는 유형이 없습니다. 즉, 같은 필드에 여러 유형의 값이 존재할 수 있습니다. 따라서 배포는 서로 다른 유형의 값을 처리해야 합니다. 혼동을 피하기 위해 서로 다른 유형의 값을 서로 다른 분포 구간차원에 넣습니다. 즉, 각 유형에 대해 부분 구간차원(마지막 구간차원)을 가질 수 있습니다. 또한 특수 값인 MISSING, NULL, TRUE 및 FALSE를 특별히 처리합니다. 이러한 값(있는 경우)은 항상 오버플로 빈에 있습니다. N1QL에는 다양한 유형에 대해 미리 정의된 정렬 순서가 있으며, 정렬된 스트림의 시작 부분에 MISSING/NULL/TRUE/FALSE가 표시됩니다.
경계 쓰레기통
각 구간차원의 최대값만 유지하므로 최소 경계는 이전 구간차원의 최대값에서 파생됩니다. 이는 또한 첫 번째 분포 구간에는 최소값이 없다는 것을 의미합니다. 이 문제를 해결하기 위해 맨 처음에 '경계 구간차원'을 두는데, 이는 구간차원 크기가 0인 특수한 구간차원이며, 이 구간차원의 유일한 목적은 다음 분포 구간차원의 최소 경계인 최대값을 제공하는 것입니다.
분포에 여러 유형이 포함될 수 있으므로 유형을 서로 다른 분포 구간차원으로 분리하고 각 유형에 '경계 구간차원'을 두어 분포의 각 유형에 대한 최소값을 알 수 있도록 합니다.
혼합 유형 및 경계 빈 처리 예시
UPDATE STATISTICS for CUSTOMER(quantity);
히스토그램: 총 문서 수입니다: 5000, 수량은 단순 정수로 표시됩니다.

술어:
-
(수량 = 100): 예상 1%
-
(200에서 100 사이의 수량) : 견적 20%
또한 이 선택도 계산을 개선하기 위해 각 구간차원에 대해 최고/차순위 최고, 최저, 두 번째 최저 값을 유지하고, 25% 이상 발생하는 값에 대해 오버플로 구간차원을 유지하는 등의 추가 기술을 사용하고 있습니다.
JSON에서 수량은 모든 유형이 될 수 있습니다: 누락, null, 부울, 정수, 문자열, 배열 및 객체입니다. 여기서는 간단하게 하기 위해 정수, 문자열, 배열의 세 가지 유형으로 수량 히스토그램을 표시합니다. 이 기능은 모든 유형을 포함하도록 확장되었습니다.

N1QL은 서로 다른 유형의 값을 비교할 수 있는 메서드를 정의합니다.
- 유형 순서: 가장 낮은 것부터 높은 것까지
- 누락 < 널 < 거짓 < 참 < 숫자 < 문자열 < 배열 < 개체
- 문서를 샘플링한 후에는 먼저 문서를 유형별로 그룹화하고 유형 그룹 내에서 정렬한 다음 각 유형에 대한 미니 히스토그램을 만듭니다.
- 그런 다음 이러한 미니 히스토그램을 각 유형 사이에 경계 구간이 있는 큰 히스토그램으로 연결합니다. 이렇게 하면 옵티마이저가 단일 유형 또는 여러 유형에 걸쳐 선택도를 효율적으로 계산하는 데 도움이 됩니다.
예시:
|
1 2 3 4 5 6 7 8 |
WHERE quantity between 100 and 1000; WHERE quantity between 100 and "4829"; WHERE quantity between 100 and [235]; WHERE quantity between 100 and {"val": "2829"}; |
간단한 데이터 유형에 대한 분포 통계는 간단합니다. 부울 값은 참과 거짓 값을 저장하는 두 개의 오버플로 구간차원을 갖습니다. 숫자 및 문자열 값도 처리하기 쉽습니다. 문자열 값의 크기를 구간차원 경계로 제한할지 여부, 즉 문자열이 매우 긴 경우 분포 구간차원의 최대값으로 저장하기 전에 문자열을 잘라낼지 여부는 여전히 미해결 문제로 남아 있습니다. 오버플로 구간차원의 긴 문자열 값은 정확히 일치해야 하므로 잘리지 않습니다.
분포 통계를 수집하는 방법에 대한 설계는 아직 확정되지 않았습니다. 아마도 배열 인덱스가 작동하는 방식이므로 배열의 개별 요소에 대한 분포 통계를 수집할 것입니다. 히스토그램을 구성하기 전에 배열에서 중복을 제거할지 여부를 결정하는 배열 필드 사양 앞에 동일한 키워드를 포함시켜 배열 인덱스의 DISTINCT/ALL 변형을 지원해야 할 수도 있습니다.
이러한 히스토그램을 기반으로 배열 술어(ANY 술어)의 선택성을 추정하는 것은 다소 어렵습니다. 컬렉션의 다양한 배열 길이를 설명할 수 있는 쉬운 방법이 없기 때문입니다. 첫 번째 릴리즈에서는 분포 통계의 일부로 평균 배열 크기를 유지하기로 했습니다. 이는 어떤 형태의 균일성을 가정하는 것이므로 이상적이지는 않지만 좋은 시작입니다.
모든 술어의 선택성을 추정하는 것은 훨씬 더 까다롭기 때문에 일종의 기본값을 사용해야 할 수도 있습니다.
키스페이스에 있는 다음 JSON 문서를 고려하십시오.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "a": 1, "b": [ 5, 10, 15,20,5,20,10], "c": [ { "x": "hello", "y": true }, { "x": "thanks", "y": false} ] } |
필드 "a"는 스칼라이고, b는 스칼라의 배열이며, c는 객체의 배열입니다. 쿼리를 발행할 때 a, b, c 중 일부 또는 모든 필드에 술어를 가질 수 있습니다. 지금까지 유형이 변경될 수 있는 스칼라에 대해 알아보았습니다. 이제 배열 술어 통계 수집 및 선택도 계산에 대해 알아보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Array predicates: FROM k WHERE ANY e IN b SATISFIES e = 10 END FROM k WHERE ANY e in b SATISFIES e > 50 END FROM k WHERE ANY e IN b SATISFIES e BETWEEN 30 and 100 END FROM k UNNEST k.b AS e WHERE e = 10; FROM k UNNEST k.b AS e WHERE e > 10; FROM k WHERE ANY f IN c SATISFIES e.x = “hello” END FROM k WHERE ANY f IN c SATISFIES e.y = true END FROM k UNNEST k.c AS f WHERE f.x = “thanks” |
스칼라 배열과 객체 배열에 대한 간단한 술어로, 배열의 배열, 배열의 객체 배열 등에서 요소와 값을 필터링하기 위해 쿼리를 작성할 수 있는 일반화된 구현입니다.
이러한 문서가 10억 개에 달하면 배열 인덱스를 생성하여 필터를 효율적으로 실행할 수 있습니다. 이제 최적화 프로그램에서는 주어진 술어에 해당하는 문서 수를 추정하는 것이 중요합니다.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX i1 ON k(DISTINCT b); CREATE INDEX I2 ON k (ALL b); CREATE INDEX i3 ON k(DISTINCT array f.x for f IN c) CREATE INDEX i3 ON k(ALL array f.x for f IN c) |
인덱스 i1에 DISTINCT b 키를 사용하면 b의 고유(고유) 요소만 있는 인덱스가 생성됩니다.
ALL b 키를 가진 인덱스 i2는 b의 모든 요소가 포함된 인덱스를 생성합니다.
이는 인덱스의 크기, 인덱스에서 큰 중간 결과를 얻을 수 있는 가능성을 관리하기 위해 존재합니다. 두 경우 모두 배열의 각 요소에 대해 여러 개의 인덱스 항목이 있습니다. 이는 JSON 문서당 인덱스에 항목이 하나만 있는 스칼라와는 다릅니다.
배열 인덱싱에 대한 자세한 내용은 다음을 참조하세요. 카우치베이스의 배열 인덱싱 문서.
이 배열 또는 개체 배열에 대한 통계는 어떻게 수집하나요? 핵심 인사이트는 인덱스를 생성하는 표현식과 정확히 동일한 표현식에 대한 통계를 수집하는 것입니다.
이 경우 당사는 다음에 대한 통계를 수집합니다:
|
1 2 3 4 5 6 7 8 |
UPDATE STATISTICS FOR k(DISTINCT b) UPDATE STATISTICS FOR k(ALL b) UPDATE STATISTICS FOR k(DISTINCT array f.x for f IN c) UPDATE STATISTICS FOR k(ALL array f.x for f IN c) |
이제 히스토그램 내에서 동일한 문서에서 비롯된 값이 0, 하나 또는 여러 개가 있을 수 있습니다. 따라서 선택도(필터에 적합한 문서의 예상 비율)를 계산하는 것은 그리 쉬운 일이 아닙니다!
배열 문제를 해결할 수 있는 새로운 솔루션이 있습니다:
일반 통계의 경우: 문서당 하나의 인덱스 항목이 있습니다.
카디널리티는 선택성 x 테이블 카디널리티로 간단해집니다;
배열 통계의 경우: 문서당 N개의 인덱스 항목이 있습니다;
N-> 배열의 고유 값 수입니다.
N = 0 ~ n, n <= ARRAY_LENGTH(a)
이 추가 통계를 수집하여 히스토그램에 저장해야 합니다.
이제 특정 술어의 평가를 위해 인덱스가 선택되면 인덱스 스캔은 중복을 포함하는 모든 적격 문서 키를 반환합니다. 그러면 쿼리 엔진은 고유한 키를 얻기 위해 별도의 작업을 수행하여 올바른(중복되지 않은) 결과를 얻습니다. 비용 기반 최적화 도구는 술어를 한정할 문서 수(인덱스 항목 수가 아닌)를 계산할 때 이 점을 고려해야 합니다. 따라서 예상값을 평균 배열 크기 길이의 예상값으로 나눕니다.
이 카디널리티를 사용하여 배열 인덱스 경로를 사용하는 비용과 다른 법적 액세스 경로를 사용하는 비용을 비교하여 최적의 액세스 경로를 찾을 수 있습니다.
객체, JSON 및 바이너리 값
객체/JSON 값 또는 이진 값의 히스토그램이 얼마나 유용할지는 불분명합니다. 쿼리에서 이러한 값으로 비교하는 경우는 거의 없을 것입니다. 다른 간단한 유형처럼 값 수, 고유값 수, 최대값 경계를 각 분포 구간차원에 넣는 식으로 처리하거나, 아니면 단순화하여 고유값 수와 최대값 없이 분포 구간차원에 개수만 넣을 수 있습니다. 최대값의 문제는 값이 클 수 있는 긴 문자열과 유사하며, 이렇게 큰 값을 저장하는 것이 히스토그램에 도움이 되지 않을 수 있습니다. 이 문제는 현재로서는 미해결 문제입니다.
중첩된 개체의 필드에 대한 통계
키스페이스에 있는 이 JSON 문서를 생각해 보세요:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "a": 1, "b": {"p": "NY", "q": "212-820-4922", "r": 2848.23}, "c": { "d": 23, "e": { "x": "hello", "y": true , "z": 48} } } |
다음은 중첩된 객체에 액세스하는 점선 표현식입니다.
FROM k WHERE b.p = "NY" AND c.e.x = "hello" AND c.e.z = 48;
각 경로가 고유하기 때문에 히스토그램을 수집하고 사용하는 것은 스칼라처럼 간단합니다.
k(b.p, c.e.x, c.e.z)에 대한 통계 업데이트
요약
N1QL(JSON용 SQL)을 위한 비용 기반 최적화 프로그램을 구현하고 다음과 같은 문제를 처리한 방법을 설명했습니다.
- N1QL CBO는 유연한 JSON 스키마를 처리할 수 있습니다.
- N1QL CBO는 스칼라, 객체 및 배열을 처리할 수 있습니다.
- N1QL CBO는 통계 수집을 처리하고 JSON 내의 모든 유형의 필드에 대한 예상치를 계산할 수 있습니다.
- 이 모든 것이 쿼리 계획을 개선하여 시스템 성능을 향상시킵니다. 또한 DBA 성능 디버깅 오버헤드를 줄임으로써 총 소유 비용(TCO)을 절감할 수 있습니다.
- 다운로드 Couchbase 6.5 를 클릭하고 직접 사용해 보세요!
리소스 N1QL 규칙 기반 옵티마이저
첫 번째 문서에서는 5.0 버전의 Couchbase Optimizer에 대해 설명합니다. Couchbase 5.5에서는 ANSI 조인이 추가되었습니다. 두 번째 문서에서는 이에 대한 설명과 일부 최적화에 대해 설명합니다.
- Couchbase N1QL 쿼리 최적화에 대한 심층 분석 https://dzone.com/articles/a-deep-dive-into-couchbase-n1ql-query-optimization
- N1QL의 ANSI JOIN 지원 https://dzone.com/articles/ansi-join-support-in-n1ql
- 올바른 인덱스를 생성하고 규칙 기반 최적화 도구에 적합한 성능을 얻으세요.
- 인덱스 선택 알고리즘
참조
- 관계형 데이터베이스 관리 시스템에서 액세스 경로 선택. https://people.eecs.berkeley.edu/~brewer/cs262/3-selinger79.pdf
- DB2 XML의 비용 기반 최적화. https://www2.hawaii.edu/~lipyeow/pub/ibmsys06-xmlopt.pdf
- 관계형 데이터베이스 관리 시스템에서 액세스 경로 선택. https://people.eecs.berkeley.edu/~brewer/cs262/3-selinger79.pdf