배열은 THE 관계형 모델과 JSON 모델의 차이점을 설명합니다. - 제럴드 상구디
초록
JSON 배열은 요소의 유형, 요소 수, 요소의 크기, 요소의 깊이를 유연하게 설정할 수 있습니다. 이는 Couchbase 및 MongoDB와 같은 운영형 JSON 데이터베이스의 유연성을 더해줍니다. 운영 데이터베이스에서 배열 술어가 있는 쿼리의 성능은 배열 인덱스에 따라 달라집니다. 그러나 이러한 데이터베이스의 배열 인덱스에는 상당한 수준의 제한 사항. 예를 들어 인덱스당 하나의 배열 키만 허용됩니다. 배열 인덱스는 생성되더라도 AND 술어만 효율적으로 처리할 수 있습니다. 곧 출시될 Couchbase 6.6 릴리즈에서는 내장된 반전 인덱스를 사용하여 N1QL에서 배열을 색인하고 쿼리하는 데 사용함으로써 이러한 JSON 제한을 제거합니다. 이 문서에서는 이 새로운 구현의 배경과 작동 방식에 대해 설명합니다.
소개
배열은 기본 유형으로 JSON 로 정의 An 배열 는 값의 정렬된 컬렉션입니다. 배열은 다음과 같이 시작됩니다. [왼쪽 대괄호 로 끝나고 ]오른쪽 대괄호. 값은 ,쉼표. 배열은 스칼라, 벡터, 객체 값을 임의의 개수로 포함할 수 있기 때문에 유연성을 제공합니다. 사용자 프로필에는 취미 배열이, 고객 프로필에는 자동차 배열이, 회원 프로필에는 친구 배열이 포함될 수 있습니다. Couchbase N1QL은 풍부한 연산자 세트 를 사용하여 배열을 조작할 수 있습니다. 배열을 처리하는 연산자 도 마찬가지입니다.
쿼리를 시작하기 전에 데이터를 배열로 모델링해야 합니다. Couchbase, MongoDB와 같은 모든 JSON 문서 데이터베이스는 성능과 앱 개발을 개선하기 위해 데이터 모델을 비정규화할 것을 권장합니다. 즉, 1:N 관계를 1에 N을 포함시켜 단일 문서로 변환하는 것입니다. JSON에서는 배열을 사용하여 이를 수행합니다. 아래 예시에서는 문서(1)에 좋아요 8개(N)가 포함되어 있습니다. 다른 테이블에 대한 외래 키 참조를 저장하는 대신 JSON에서는 데이터를 인라인으로 저장합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
"public_likes": [ "줄리어스 트롬프 1세", "코린 힐", "제이든 맥켄지", "발리 라이언", "브라이언 킬백", "릴리안 맥러플린", "모세 피니 씨", "엘노라 트란토우" ], |
여기서 값은 문자열 배열입니다. JSON에서 각 요소는 스칼라(숫자, 문자열 등), 객체 또는 벡터(배열) 등 모든 유효한 JSON 유형이 될 수 있습니다. 각 호텔 문서에는 리뷰 배열이 포함되어 있습니다. 이것이 바로 비정규화 과정입니다. 여러 개의 1:N 관계를 N개의 공개_좋아요와 M개의 리뷰를 포함하는 단일 호텔 객체로 변환합니다. 이렇게 하면 호텔 객체에는 public_likes와 리뷰라는 두 개의 배열이 포함됩니다. 이 배열 아래에는 어떤 유형의 값도 얼마든지 포함될 수 있습니다. 이것이 바로 JSON 스키마의 유연성에 기여하는 핵심 요소입니다. 새로운 좋아요 또는 리뷰를 추가해야 하는 경우 여기에 새 값이나 개체를 추가하기만 하면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
"리뷰": [ { "author": "오젤라 시프", "content": "이번이 두 번째 여행이었는데...", "date": "2013-06-22 18:33:50 +0300", "ratings": { "청결": 5, "위치": 4, "전반적으로": 4, "Rooms": 3, "서비스": 5, "가치": 4 } }, { "author": "바튼 마크", "content": "호텔을 찾았습니다...", "date": "2015-03-02 19:56:13 +0300", "ratings": { "비즈니스 서비스(예: 인터넷 액세스)": 4, "체크인/프런트 데스크": 4, "청결": 4, "위치": 4, "전반적으로": 4, "Rooms": 3, "서비스": 3, "가치": 5 } } ], |
위의 호텔 객체처럼 데이터 모델을 JSON으로 비정규화하면 각 객체에 대해 많은 배열이 있을 수 있습니다. 프로필에는 취미, 자동차, 신용카드, 환경 설정 등에 대한 배열이 있으며, 각 배열은 스칼라(단순한 숫자/ 문자열/ 부울 값) 또는 벡터(다른 스칼라 배열, 객체 배열 등)가 될 수 있습니다.
데이터를 모델링하고 저장한 후에는 선택, 조인, 프로젝트 등 데이터를 처리해야 합니다. 카우치베이스 N1QL (JSON용 SQL)은 이러한 작업을 비롯한 다양한 작업을 수행할 수 있는 표현 언어를 제공합니다. 다음은 일반적인 사용 사례입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
1. 찾기 모두 의 문서 와 함께 a simple 값 can be 완료 by 중 하나 의 의 다음 쿼리. 선택 * FROM `여행-sample` 어디 유형 = "호텔" AND ANY p IN 공개_좋아요 만족 p = "발리 라이언" END 선택 t FROM `여행-sample` t UNNEST t.public_likes AS p 어디 t.유형 = "호텔" AND p = "발리 라이언" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
2. 찾기 모두 의 문서 그 일치 a 범위. In 이 case, 우리 시도 에 찾기 모두 의 문서 그 가지고 적어도 하나 평가 has "전반적으로" > 4 셀렉트 카운트(1) FROM `여행-sample` 어디 유형 = "호텔" AND ANY r IN 리뷰 만족 r.ratings.Overall > 4 END 셀렉트 카운트(1) FROM `여행-sample` t UNNEST 리뷰 AS r 어디 t.유형 = "호텔" AND r.ratings.Overall > 4 그룹 BY t.유형 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
3. 찾기 모두 의 문서 어디 모든 평가 에 대한 "전체" > 4 선택 * FROM `여행-샘플` 어디 유형 = '호텔' AND ANY AND 모든 r in 리뷰 만족 r.전체 > 4 END 선택 COUNT(1) FROM `여행-샘플` 어디 유형 = "호텔" AND ANY AND 모든 r IN 리뷰 만족 r.평가.전체 > 4 END 선택 리뷰[*].평가[*].전체 FROM `여행-샘플` 어디 유형 = "호텔" AND ANY AND 모든 r IN 리뷰 만족 r.평가.전체 > 4 END limit 10; [ { "전반적으로": [ 5 ], "name": "불스 헤드" }, { "전반적으로": [ 5, 5, 5, 5, 5 ], "name": "라 프라델라" }, { "전반적으로": [ 5, 5, 5 ], "name": "컬로든 하우스 호텔" }, { "전반적으로": [ 5 ], "name": "오베르주-캠핑 바가텔" }, { "전반적으로": [ 5, 5 ], "name": "아비뇽 호텔 몽클라르" } ] |
배열 인덱싱:
배열 인덱싱은 B-트리 기반 인덱스의 경우 어려운 과제입니다. 그러나 성능 요구 사항을 충족하기 위해서는 JSON 데이터베이스가 이를 수행해야 합니다: 몽고DB가 해드립니다.; 카우치베이스가 해드립니다.. 그러나 둘 다 제한이 있습니다. 인덱스 내에는 하나의 배열 키만 가질 수 있습니다. 이는 몽고DB의 경우이것은 카우치베이스 N1QL의 경우. 이 제한의 핵심 이유는 배열의 요소를 인덱싱할 때 별도의 인덱스 항목이 필요하기 때문입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
고려 사항 의 배열: 문서 키입니다: "bob" { "Id": "bob123" "A": [1, 2, 3, 4] "B": [521, 4892, 284] } 인덱싱 의 의 필드 "id" 간단하게 요구 사항 1 항목 in 의 색인: "bob123":bob 인덱싱 의 의 필드 "a" 요구 사항 4 항목 in 의 색인: "1":"bob", 2:"bob", 3:"bob", 4:"bob" 인덱싱 의 의 합성 색인 (id, a) 요구 사항 4 항목을 입력합니다: "bob123", 1: bob "bob123", 2: bob "bob123", 3: bob "bob123", 4: bob 인덱싱 의 의 합성 색인 (id, a, b) 요구 사항 의 다음 12 항목을 입력합니다: "bob123", 1, 521: bob "bob123", 1,4982: bob "bob123", 1, 284: bob "bob123", 2, 521: bob "bob123", 2,4982: bob "bob123", 2, 284: bob "bob123", 3, 521: bob "bob123", 3,4982: bob "bob123", 3, 284: bob "bob123", 4, 521: bob "bob123", 4,4982: bob "bob123", 4, 284: bob |
인덱스의 크기는 인덱스의 배열 키 수와 인덱스의 배열 요소 수에 따라 기하급수적으로 증가합니다. 따라서 제한이 있습니다. 이 제한의 의미는 다음과 같습니다:
- 인덱스 스캔에는 하나의 배열 술어만 푸시하고 다른 술어는 인덱스 스캔 후에 처리합니다.
- 즉, 배열 술어가 여러 개 있는 쿼리는 속도가 느려질 수 있습니다.
- 거대한 인덱스를 피하려면 배열 키가 있는 복합 인덱스를 피하세요.
- 즉, 배열 키에 복잡한 술어가 있는 쿼리는 속도가 느려집니다.
좋은 소식은 왼쪽 필드.
전체 텍스트 검색 인덱스는 관련성을 기반으로 텍스트 패턴 검색을 처리하도록 설계되었습니다. 그 방식은 각 필드를 토큰화하는 것입니다. 아래 예에서는 각 문서를 분석하여 토큰을 얻습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
"doc:1"->"desc": {"desc": "an appel a 일, 유지 의 의사 away."} "doc:2"->"desc": {"desc":"an appel a 일, 유지 Billl Gates away."} "doc:3"->"desc": {"desc": "an 사과 a dday, 유지 의 사과 농부 rich."} "doc:1"->"desc": ["사과", "일", "keep", "의사", "away"] "doc:2"->"desc": ["사과", "일", "keep", "bill", "gates", "away"] "doc:3"->"desc": ["사과", "일", "keep", "농부", "rich"] 이 다음 는 결합 에 get a 단일 배열 의 토큰: ["사과", "away", "bill", "일", "의사", "농부", "gates", "keep", "rich"] |
각 토큰에 대해 해당 토큰이 있는 문서 목록을 유지합니다. 이것이 바로 역 트리 구조입니다! B-Tree 기반 인덱스와 달리, 동일한 토큰 값이 문서마다 하나씩 N번 반복되는 것을 방지합니다. 수백만 또는 수십억 개의 문서가 있는 경우, 이는 엄청난 절약입니다.
여기서 주목해야 할 두 번째 사항은 반전된 인덱스입니다. 토큰 배열! 실제로 전체 텍스트 검색의 반전된 트리 구조는 특히 배열 값에 중복이 있을 때 배열 값을 색인하고 검색하는 데 이상적입니다.
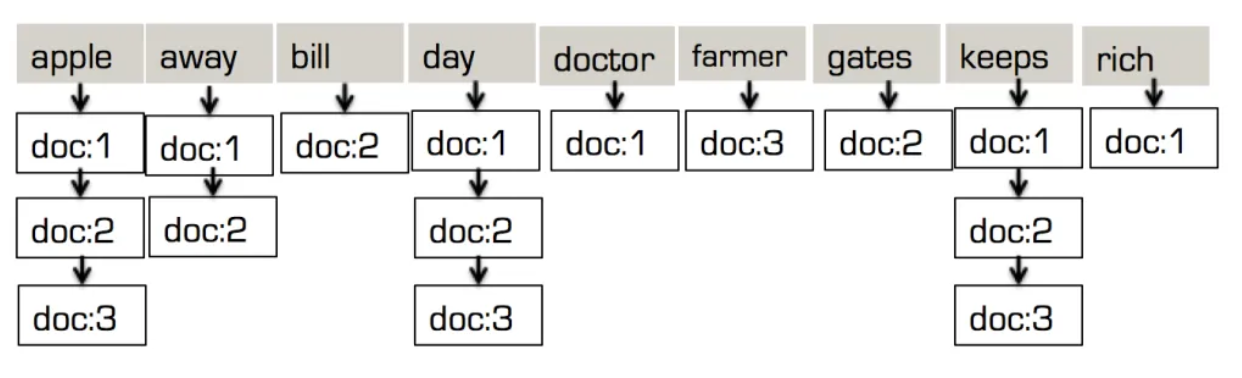
반전된 인덱스를 사용하여 배열을 색인하는 것은 토큰화가 없다는 점을 제외하면 동일한 프로세스입니다. "bob" 문서와 추가 문서 "Sam" 및 "Neill"을 색인하는 것을 다시 살펴봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
문서 키입니다: "bob" { id": "bob123" "a": [1, 2, 3, 4] "b": [521, 4892, 284] } 문서 키입니다: "샘" { "id": "sam456" "a": [1,3, 4, 9] "b": [521, 232, 284] } 문서 키입니다: "neil" { "id": "neil987" "A"[1, 2, 4, 6] "b": [521, 4892, 543] } |
그리고 카우치베이스 FTS 라는 분석기가 있습니다. 키워드 분석기. 이것은 값을 줄여서 루트를 찾는 대신 값을 있는 그대로 인덱싱합니다. 기본적으로 값은 토큰입니다. 배열 값 인덱싱의 경우, 이 인덱스를 사용하여 역 인덱스의 효율성을 활용할 수 있습니다. 밥, 샘, 닐 문서에 FTS 인덱스를 구축해 보겠습니다. 역 트리의 경우, 각 필드에는 id, a, b에 대해 각각 하나씩의 역 트리가 있습니다. 이러한 트리는 개별 트리이므로 B-트리 복합 인덱스처럼 기하급수적으로 증가하지 않습니다. 인덱스 항목의 수는 각 필드에 있는 고유 항목의 수에 비례합니다. 이 경우에는 다음과 같습니다. 14개 항목 를 사용하여 총 24개의 값으로 구성된 3개의 필드에 대해 3개의 문서를 생성합니다. 동일한 문서에 대해 (id, a, b)에 B-트리 인덱스를 만들면 다음과 같이 생성됩니다. 36개의 출품작!
인덱스 항목이 2개인 3개의 문서의 경우 그 차이는 157%입니다. 문서 수, 배열 수가 증가함에 따라 반전 인덱스를 사용한 절약 효과도 증가합니다.
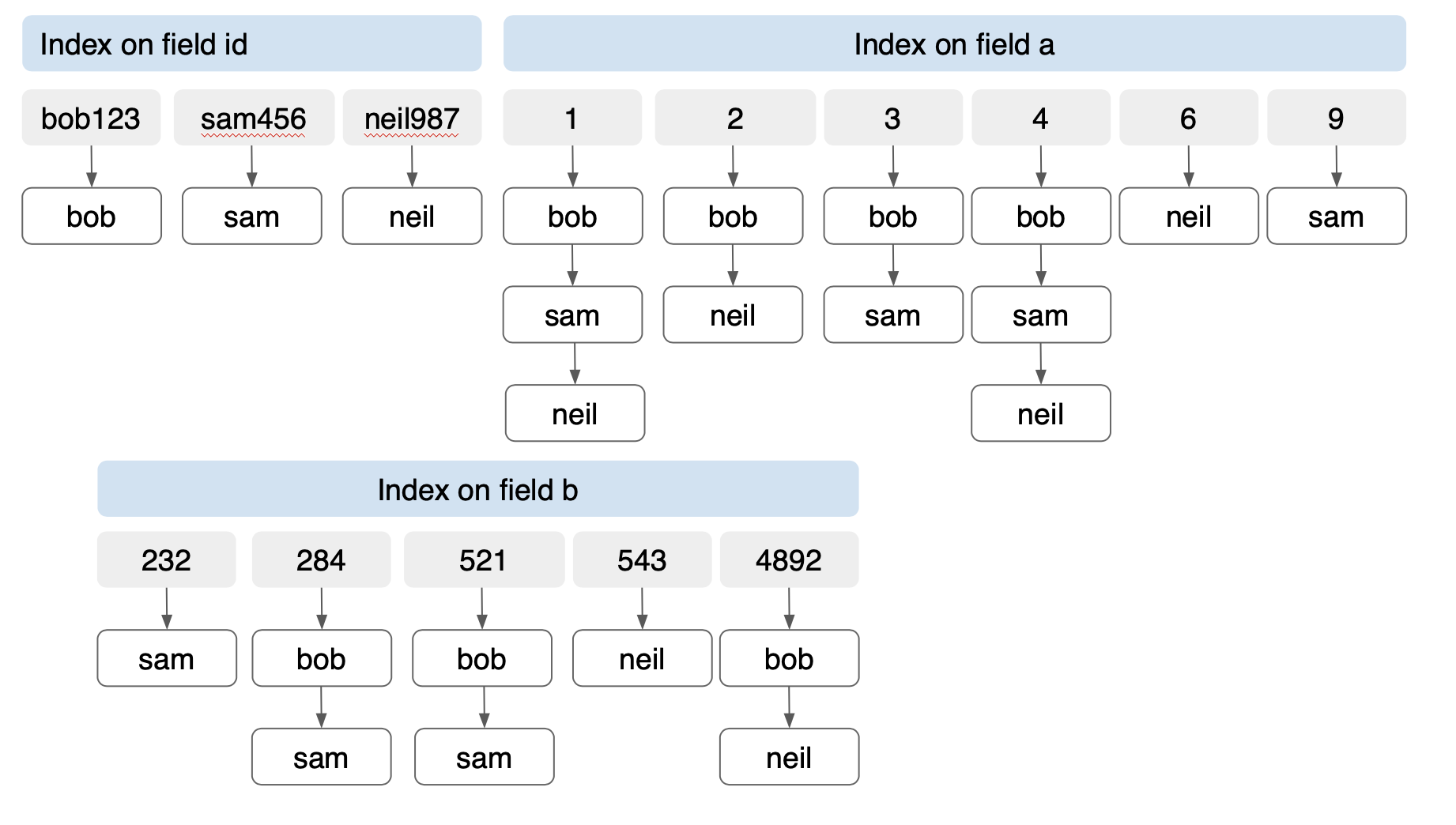
세 필드의 인덱스가 반전되었습니다.
하지만 한 가지 문제가 있습니다. 술어를 어떻게 처리하나요?
|
1 2 3 4 5 6 7 |
어디 id 사이 "ada" 그리고 "tate" AND ANY x IN a 만족 x = 3 END AND ANY y in b 만족 y = 521 END |
B-Tree 인덱스는 (id, a, b)의 모든 값을 함께 저장하지만, FTS의 반전 인덱스는 각 필드마다 고유한 트리를 가지고 있습니다. 따라서 여러 술어를 적용하는 것은 그리 쉬운 일이 아닙니다. 이는 텍스트 처리뿐만 아니라 배열 처리에서도 마찬가지입니다. 텍스트 처리에서는 다음과 같은 질문을 하는 것이 일반적입니다. 캘리포니아 거주자 와 함께 스키 그들의 취미.
이를 처리하기 위해 FTS는 각 필드에 술어를 개별적으로 적용하여 각 술어에 대한 문서 키 목록을 가져옵니다. 그런 다음 부울 술어인 AND 를 추가합니다. 이 레이어는 유명한 로잉 비트맵 패키지 를 사용하여 문서 ID의 비트맵을 생성하고 처리하여 결과를 완성합니다. 예, 간단한 B-TREE 기반 인덱스에 비해 추가 처리가 필요하지만 이를 통해 많은 배열을 인덱싱하고 합리적인 시간 내에 쿼리를 처리할 수 있습니다.

거꾸로 된 나무: 계속 베푸는 나무!
B-Tree 복합 인덱스는 스캐닝과 AND 술어 적용을 결합합니다. 역 트리 접근 방식은 이 둘을 분리합니다. 각 필드를 인덱싱하고 스캔하는 것은 복합 술어를 처리하는 것과는 다릅니다. 이러한 분리로 인해 비트맵 레이어는 AND 술어와 함께 OR, NOT 술어를 처리할 수 있습니다. 이전 예제에서 AND를 OR로 변경하는 것은 단순히 문서 자격 및 중복 제거에 대한 비트맵 처리에 대한 명령입니다.
|
1 2 3 4 5 6 7 |
어디 id 사이 "ada" AND "tate" 또는 ANY x IN a 만족 x = 3 END 또는 ANY y in b 만족 y = 521 END<b></b> |
터치베이스 릴리스:
Couchbase 6.6은 복잡한 배열 술어를 처리하기 위해 FTS 인덱스 사용을 지원합니다. 이를 통해 배열 처리의 TCO가 개선되고 개발자와 디자이너가 필요에 따라 제한 없이 배열을 사용, 인덱싱, 쿼리할 수 있습니다. 향후 공지사항, 설명서, 기능 블로그 등에서 자세히 알아보세요.
참조
- N1QL에서 JSON 배열로 작업하기
- 배열 활용하기: 모델링, 쿼리 및 인덱싱하기
- 카우치베이스 N1QL 컬렉션 오퍼레이터
- 몽고DB: 배열 쿼리하기
- 카우치베이스 FTS
- 무료: 카우치베이스 대화형 교육
- FTS 블로그: https://www.couchbase.com/blog/tag/fts/
- 수집 운영자
- 배열 인덱싱
- 배열을 최대한 활용하기...N1QL 배열 인덱싱으로
- 배열 인덱스 커버링 등으로 배열을 최대한 활용하세요.
- 카우치베이스 인덱싱
- NEST 및 UNNEST: 즉석에서 JSON 정규화 및 비정규화하기