이 블로그 게시물의 제목을 집계 그룹화로 정했지만 이것이 가장 적합한 이름인지는 모르겠습니다. MySQL의 GROUP_CONCAT 함수 또는 FOR XML PATH('') SQL Server의 해결 방법? 이것이 바로 제가 오늘 이 글을 쓰는 이유입니다. Couchbase Server를 사용하면 가장 쉽게 할 수 있는 방법은 N1QL의 ARRAY_AGG 함수를 사용할 수도 있지만, 구식 MapReduce 보기를 사용하여 수행할 수도 있습니다.
이 글을 쓰는 이유는 저희 솔루션 엔지니어 중 한 명이 한 고객(이름을 밝히지 않겠습니다)을 위해 이 문제를 해결하고 있었기 때문입니다. 우리 둘 다 해답이 담긴 블로그 게시물을 찾을 수 없었기 때문에 함께 해결책을 생각해낸 후 미래의 저를 위해 블로그에 올리기로 결정했습니다(사실 제가 블로그에 글을 쓰는 주된 이유이기도 합니다). 또 다른 이유는 다른 사람이 더 좋은 방법을 알고 있는지 알아보기 위해서입니다.)
시작하기 전에 몇 가지 자료를 준비해 두었으니 참고하시기 바랍니다. 이 게시물에 사용된 '환자' 데이터를 생성하는 데 사용한 소스 코드 는 깃허브에서 사용할 수 있습니다.. NET에 익숙하지 않다면, 그냥 cbimport on 샘플 데이터 를 만들 수 있습니다. (또는 N1QL 샌드박스에 대한 자세한 내용은 나중에 설명합니다.) 이 블로그 게시물의 나머지 부분에서는 해당 샘플 데이터가 들어 있는 '환자' 버킷이 있다고 가정합니다.
요구 사항
환자 문서가 가득 쌓여 있습니다. 각 환자에는 한 명의 의사가 있습니다. 환자 문서는 다음과 같은 필드로 의사를 가리킵니다. doctorId. 환자 문서에는 다른 데이터도 있을 수 있지만, 주로 환자 문서의 키와 doctorId 값으로 설정합니다. 몇 가지 예입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
key 01257721 { "doctorId": 58, "patientName": "Robyn Kirby", "patientDob": "1986-05-16T19:01:52.4075881-04:00" } key 116wmq8i { "doctorId": 8, "patientName": "Helen Clark", "patientDob": "2016-02-01T04:54:30.3505879-05:00" } |
다음으로, 각 의사가 여러 명의 환자를 가질 수 있다고 가정할 수 있습니다. 의사 문서가 존재한다고 가정할 수도 있지만 이 튜토리얼에서는 실제로 필요하지 않으므로 지금은 환자에만 집중해 보겠습니다.
마지막으로, 우리가 애플리케이션(또는 보고서 등)에서 원하는 것은 의사와 함께 환자를 종합적으로 그룹화하는 것입니다. 각 레코드는 의사와 환자 목록/배열/모음을 식별할 수 있습니다. 예를 들어
| 의사 | 환자 |
|---|---|
|
58 |
01257721, 450MKKRI, 8G2MRZE2 ... |
|
8 |
05WOKNFK, 116WMQ8I, 2T5YTTQI ... |
|
... 등 ... |
... 등 ... |
예를 들어 의사에게 배정된 모든 환자를 보여주는 대시보드에 유용할 수 있습니다. 이 형식의 데이터를 N1QL 또는 MapReduce로 어떻게 가져올 수 있을까요?
N1QL 집계 그룹화
N1QL 는 우리에게 ARRAY_AGG 함수 를 사용하여 이를 가능하게 합니다.
먼저 각 환자 문서에서 의사 ID와 환자 문서의 키를 선택합니다. 그런 다음 ARRAY_AGG 를 환자 문서 ID에 추가합니다. 마지막으로 의사 ID별로 결과를 그룹화합니다.
|
1 2 3 |
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients FROM patients p GROUP BY p.doctorId; |
참고: 실행하는 것을 잊지 마세요. 환자에 대한 기본 지표 만들기 를 사용하여 기본 인덱스 스캔을 활성화합니다.
이 쿼리에 ARRAY_AGG. 각 환자에 대해 하나의 레코드를 반환합니다. 여기에 ARRAY_AGG 및 그룹 기준이제 각 의사에 대해 하나의 기록을 반환합니다.
다음은 제가 만든 샘플 데이터 세트에 대한 결과의 일부입니다:
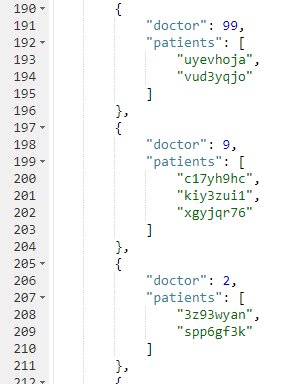
버킷을 생성하고 샘플 데이터를 가져오는 번거로움을 겪고 싶지 않다면 N1QL 튜토리얼 샌드박스. 여기에는 환자 문서가 없으므로 쿼리가 약간 달라집니다.
이메일을 연령별로 그룹화해 보겠습니다. 먼저 각 문서에서 연령을 선택하고 각 문서에서 이메일을 선택합니다. 그런 다음 ARRAY_AGG 을 이메일에 추가합니다. 마지막으로 결과를 연령별로 그룹화합니다.
|
1 2 3 |
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails FROM tutorial t group by t.age; |
다음은 샌드박스 결과의 일부 스크린샷입니다:

MapReduce를 사용한 그룹 집계
맵리듀스 뷰를 사용하여 유사한 집계 그룹화를 수행할 수도 있습니다.
먼저 새 보기를 만듭니다. Couchbase 콘솔에서 인덱스로 이동한 다음 뷰로 이동합니다. "환자" 버킷을 선택합니다. "개발 뷰 만들기"를 클릭합니다. 디자인 문서의 이름을 지정합니다(저는 "_design/dev_patient"라고 합니다. 뷰를 만듭니다(저는 "doctorPatientGroup"이라고 합니다).
지도와 사용자 지정 축소 함수가 모두 필요합니다.
먼저 맵의 경우, 의사 ID(그룹화를 사용할 것이므로 배열로)와 환자의 문서 ID만 있으면 됩니다.
|
1 2 3 |
function (doc, meta) { emit([doc.doctorId], meta.id); } |
다음으로, 축소 함수의 경우 값을 가져와 배열로 연결합니다. 다음은 이를 수행할 수 있는 한 가지 방법입니다. 저는 자바스크립트 전문가나 MapReduce 전문가가 아니므로 더 효율적인 방법이 있을 수 있습니다:
|
1 2 3 4 |
function reduce(key, values, rereduce) { var merged = [].concat.apply([], values); return merged; } |
맵과 축소 함수를 모두 생성한 후 색인을 저장합니다.
마지막으로 이 인덱스를 실제로 호출할 때 그룹 레벨을 1로 설정합니다. UI에서 이 작업을 수행할 수 있습니다:
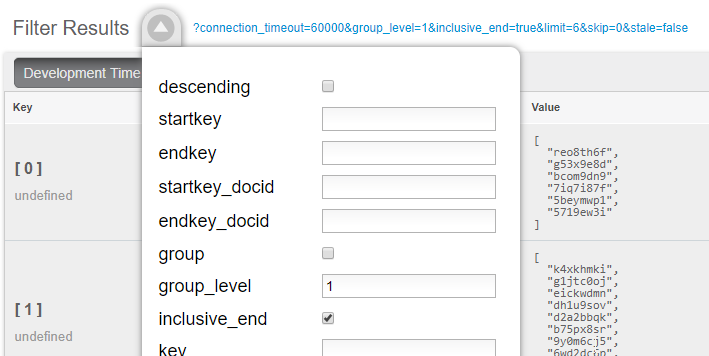
또는 인덱스 URL에서 할 수 있습니다. 다음은 제 로컬 컴퓨터에서 실행 중인 클러스터의 예입니다:
|
1 |
https://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=false |
해당 뷰의 결과는 다음과 같아야 합니다(블로그 게시물에 보기 좋게 잘라낸 모습):
|
1 2 3 4 5 6 7 8 9 |
{"rows":[ {"key":[0],"value":["reo8th6f","g53x9e8d", ... ]}, {"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]}, {"key":[2],"value":["spp6gf3k","3z93wyan"]}, {"key":[3],"value":["qnx93fh3","gssusiun", ...]}, {"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]}, {"key":[5],"value":["ywjfvad6","so4uznxx", ...]} ... ]} |
요약
N1QL 방법이 더 쉽다고 생각하지만 경우에 따라서는 MapReduce를 사용하는 것이 성능상 이점이 있을 수 있습니다. 두 경우 모두 관계형 데이터베이스에서와 마찬가지로 쉽게(더 쉽지는 않더라도) 집계 그룹화를 수행할 수 있습니다.
N1QL에 대해 더 자세히 알고 싶으신가요? 다음을 확인해 보세요. 전체 N1QL 튜토리얼/샌드박스. MapReduce 보기에 관심이 있으신가요? 맵리듀스의 맵리듀스 뷰 문서 를 클릭하여 시작하세요.
이 게시물이 유용했나요? 개선할 점이 있으신가요? 아래에 댓글을 남기거나 다음 연락처로 문의해 주세요. 트위터 @mgroves.