데이터 소스 간 데이터 이동. 이는 데이터 통합 프로젝트의 핵심 활동 중 하나입니다. 전통적으로 데이터 이동과 관련된 기법은 데이터 웨어하우스, BI 및 분석. 최근에는 빅 데이터, 데이터 레이크, 하둡이 이 분야에서 자주 사용됩니다.
이 항목에서는 이러한 종류의 시나리오에서 데이터를 대규모로 조작하기 위해 Couchbase N1QL 언어를 사용하는 방법에 대해 설명합니다.
먼저, 데이터 이동을 수행할 때 두 가지 고전적인 접근 방식을 기억해 보겠습니다:
ETL (추출-변환-로드). 이 모델을 사용하면 데이터는 다음과 같습니다. 추출 (원본 데이터 소스에서 가져옴), 변형 (데이터가 대상 시스템에 맞게 다시 포맷됨) 및 로드 (대상 데이터 저장소에서).
ELT (추출-로드-변환). 이 모델을 사용하면 데이터는 다음과 같습니다. 추출 (원본 데이터 소스에서 가져옴), 로드 를 대상 시스템에 동일한 형식으로 저장합니다. 그런 다음 변환 를 사용하여 원하는 데이터 형식을 얻습니다.
우리는 다음 사항에 집중할 것입니다. ELT 연습을 해보겠습니다. 관계형 데이터베이스에서 간단한 내보내기를 수행하고 데이터를 Couchbase에 로드해 보겠습니다. 입력 데이터 소스로는 인사 부서를 모델링하는 고전적인 HR 스키마 예제가 내장된 Oracle 데이터베이스를 사용합니다.
이것이 소스 데이터 모델입니다:
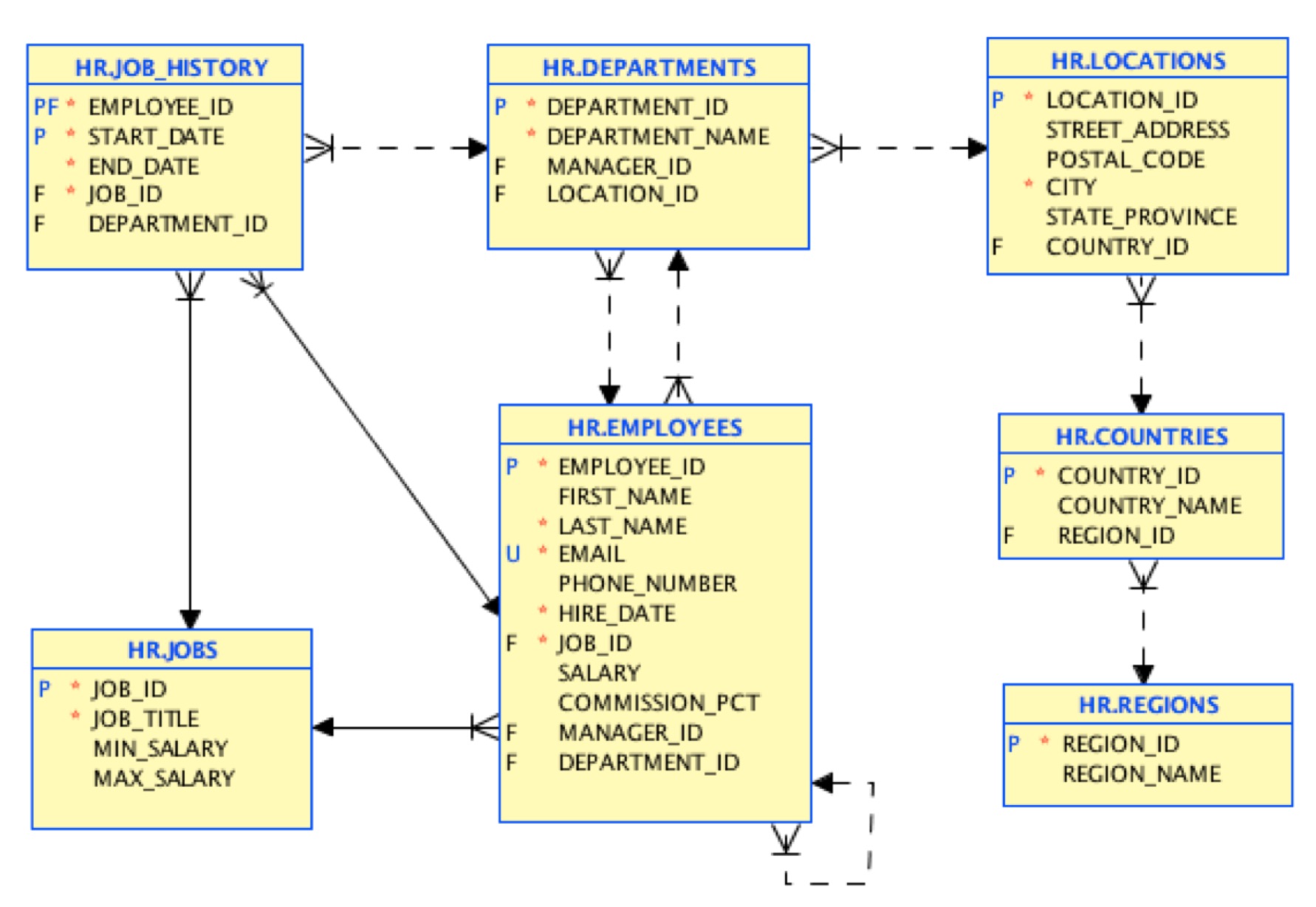
첫 번째 단계에서는 동일한 구조로 데이터를 로드합니다. 이 초기 마이그레이션을 수행하는 데 사용할 수 있는 무료 도구가 있습니다. 여기. 마지막에는 이 테이블 모델을 매핑하는 JSON 문서가 있습니다:
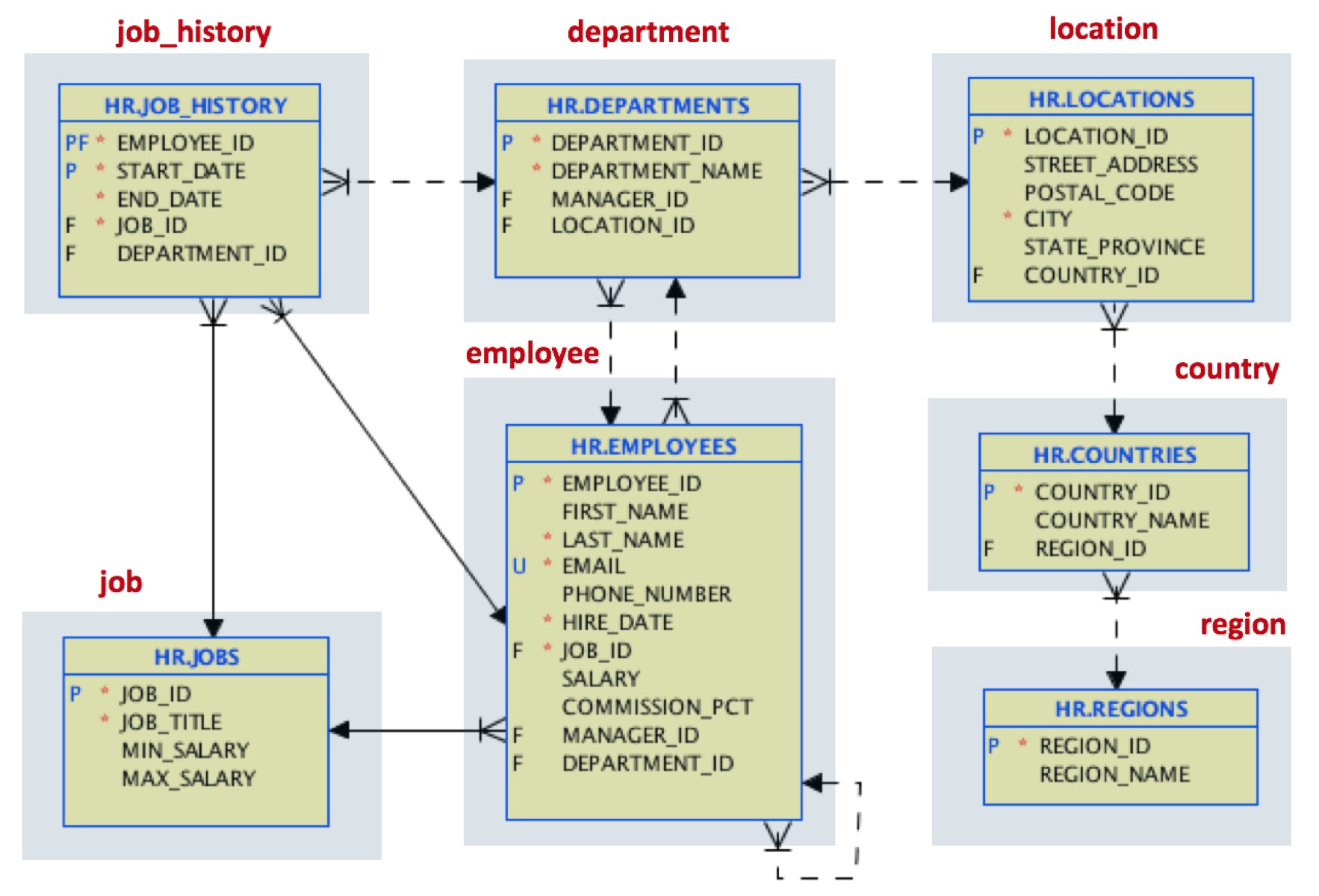
예를 들어 위치 문서는 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 |
{ "street_address": "2017 신주쿠구", "city": "Tokyo", "state_province": "도쿄 현", "postal_code": "1689", "type": "위치", "location_id": 1200, "country_id": "JP" } |
이것은 쉬운 첫 단계였습니다. 그러나 이러한 테이블과 문서 간의 매핑은 NoSQL 세계에서는 종종 잘못된 설계입니다. NoSQL에서는 참조된 데이터를 포함하는 보다 직접적인 액세스 경로를 위해 데이터의 정규화를 해제하는 경우가 빈번합니다. 목표는 데이터베이스 상호 작용과 조인을 최소화하여 최상의 성능을 찾는 것입니다.
직원의 전체 작업 기록에 자주 액세스해야 하는 사용 사례가 있다고 가정해 보겠습니다. 디자인을 다음과 같이 변경하기로 결정합니다:
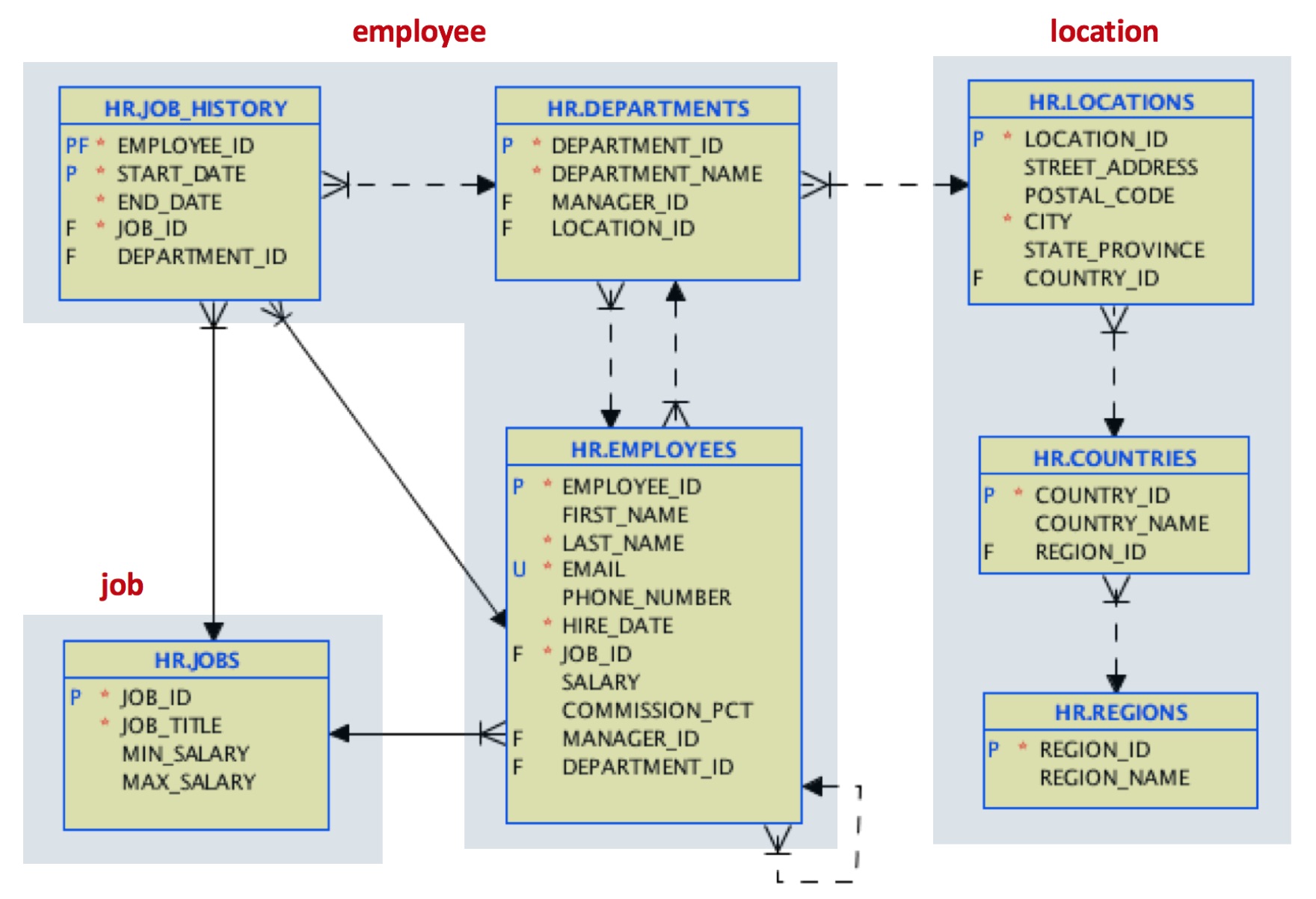
위치의 경우, 국가 및 지역에 대한 참조 데이터를 단일 위치 문서에 조인하고 있습니다.
직원 문서의 경우 부서 데이터를 포함하고 전체 업무 기록 또는 각 직원이 포함된 배열을 포함할 것입니다. JSON의 이러한 배열 지원은 관계형 세계에서 외래 키 참조 및 조인에 비해 크게 개선된 기능입니다.
작업 문서의 경우 원래 테이블 구조를 유지합니다.
그래서 우리는 추출 그리고 로드 이제 우리는 변환 이 모델을 완성하기 위해 ELT 예제. 이 작업을 어떻게 할 수 있을까요? N1QL을 사용할 때입니다.
N1QL은 데이터 액세스 및 데이터 조작을 위해 Couchbase에 포함된 SQL과 유사한 언어입니다. 이 예에서는 두 개의 버킷을 사용하겠습니다: 원래 Oracle HR 스키마에 매핑되는 HR과 대상 문서 모델을 보유할 HR_DNORM입니다.
이미 HR 스키마를 로드했습니다. 다음 단계는 HR_DNORM이라는 버킷을 만드는 것입니다. 그런 다음 이 새 버킷에 기본 인덱스를 생성합니다:
|
1 |
만들기 기본 INDEX 켜기 HR_DNORM |
이제 위치 문서를 만들 차례입니다. 이 문서는 원본 위치, 국가 및 지역 문서로 구성됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
삽입 INTO HR_DNORM (키 _k, 값 _v) 선택 메타().id _k, { "type":"위치", "city":loc.도시, "postal_code":loc.우편_코드, "state_province":IFNULL(loc.state_province, null), "street_address":loc.거리_주소, "country_name":ct.국가_이름, "region_name":rg.지역_이름 } as _v FROM HR loc JOIN HR ct 켜기 키 "국가::" || loc.country_id JOIN HR rg 켜기 키 "regions::" || TO_STRING(ct.region_id) 어디 loc.유형="위치" |
몇 가지 주목해야 할 사항이 있습니다:
- 여기서는 삽입을 위해 SELECT 문의 투영을 사용하고 있습니다. 이 예제에서 원본 데이터는 다른 버킷에서 가져온 것입니다.
- JOIN은 원래 버킷에서 국가 및 지역을 참조하는 데 사용됩니다.
- state_province 필드에 명시적으로 null 값을 설정하는 데 사용되는 IFNULL 함수
- 키 참조를 위해 숫자 필드에 적용된 TO_STRING 함수
원본 샘플은 이렇게 됩니다:
|
1 2 3 4 5 6 7 8 9 |
{ "city": "Tokyo", "country_name": "일본", "postal_code": "1689", "region_name": "아시아", "state_province": "도쿄 현", "street_address": "2017 신주쿠구", "type": "위치" } |
참조 위치_id 및 국가_id를 제거했습니다.
이제 직원 문서를 작성할 차례입니다. 여러 단계로 진행하겠습니다. 첫 번째는 부서 및 실제 직무 정보를 포함하여 원래 HR 버킷에서 직원을 만드는 것입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
삽입 INTO HR_DNORM (키 _k, 값 _v) 선택 메타().id _k, { "type":"직원", "employee_id": emp. employee_id, "first_name": emp.first_name, "last_name": emp.last_name, "전화 번호": emp.전화 번호, "이메일": emp.이메일, "hire_date": emp.hire_date, "급여": emp.급여, "commission_pct": IFNULL(emp.commission_pct, null), "manager_id": IFNULL(emp.관리자_id, null), "job_id": emp.job_id, "job_title": job.job_title, "부서" : { "name" : dpt.부서_이름, "manager_id" : dpt.관리자_id, "department_id" : dpt.부서_id } } as _v FROM HR emp JOIN HR job 켜기 키 "jobs::" || emp.job_id JOIN HR dpt 켜기 키 "부서::" || TO_STRING(emp.부서_ID) 어디 emp.유형="직원" 반환 메타().id; |
둘째, 임시 구조를 사용하여 작업 기록 배열을 구축합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
삽입 INTO HR_DNORM (키 _k, 값 job_history) 선택 "job_history::" || TO_STRING(jobh.employee_id) AS _k, { "jobs" : ARRAY_AGG( { "start_date": jobh.start_date, "end_date": jobh.end_date, "job_id": jobh.job_id, "department_id": jobh.부서_id } ) } AS job_history FROM HR jobh 어디 jobh.유형="job_history" 그룹 BY jobh.employee_id 반환 메타().id; |
이제 job_history 배열을 추가하여 직원 문서를 쉽게 업데이트할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 |
업데이트 HR_DNORM emp SET job_history=( 선택 RAW 일자리 FROM HR_DNORM jobh 사용 키 "job_history::" || SUBSTR(메타(emp).id, 11) )[0] 어디 emp.유형="직원" 반환 메타().id |
직원 문서는 이렇게 생겼습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
{ "commission_pct": null, "부서": { "department_id": 10, "manager_id": 200, "name": "관리" }, "이메일": "JWHALEN", "employee_id": 200, "first_name": "Jennifer", "hire_date": "2003-09-16T22:00:00Z", "job_history": [ { "department_id": 80, "end_date": "2007-12-31T23:00:00Z", "job_id": "SA_REP", "start_date": "2006-12-31T23:00:00Z" }, { "department_id": 90, "end_date": "2001-06-16T22:00:00Z", "job_id": "AD_ASST", "start_date": "1995-09-16T22:00:00Z" }, { "department_id": 90, "end_date": "2006-12-30T23:00:00Z", "job_id": "AC_ACCOUNT", "start_date": "2002-06-30T22:00:00Z" } ], "job_id": "AD_ASST", "job_title": "관리 도우미", "last_name": "Whalen", "manager_id": 101, "전화 번호": "515.123.4444", "급여": 4400, "type": "직원" } |
이전 직책의 job_history 배열에 주목하세요.
이제 임시 job_history 문서를 삭제할 수 있습니다:
|
1 2 |
삭제 FROM HR_DNORM emp 어디 메타().id 좋아요 "job_history::%" |
마지막 단계로 원본 작업 문서를 삽입합니다:
|
1 2 3 4 |
삽입 INTO HR_DNORM (키 _k, 값 _v) 선택 메타().id _k, _v FROM HR _v 어디 _v.유형="jobs" |
끝났습니다. 이것은 간단한 예이지만 N1QL 데이터 조작이 강력할 수 있음을 보여줍니다. 행복한 데이터 마이그레이션!