
Managing large volumes of high velocity data brings a unique set of challenges. From the ability of the database to ingest the data to the TCO of the solution given expanding data volumes. Couchbase’s new Magma storage engine provides a compelling case for storing such data at optimal costs while providing high performance for analytical workloads. In this blog, I describe a real-life implementation of Magma and the benefits it is providing at a client site.
Infosys has been supporting a large client in the tourism industry in collaboration with Couchbase. The client uses Couchbase as the core technology to support industry leading use cases that provide the next level of experience to its guests. This includes IoT-based devices that stream information from multiple sites run by the client. This data is varied with over 20 different kinds of data points and is high velocity with data being generated at the rate of thousands per second. This data is streamed into local Couchbase clusters and processed before being sent to a cloud-based analytics cluster.
The solution has stood the test of time and has been providing valuable insights to the business on guest preferences and behavior as well as serving important regulatory needs. Due to the success of the program, the number of locations and guests has seen a 4x increase in the recent past, and this has resulted in huge increase in the volume of data. The Couchbase clusters have absorbed this flood of data with ease, and the Analytics cluster has efficiently served the increased needs of business for insights into the data.
As the data volumes have grown, we have had to increase the size of the cluster to keep pace, and this has increased the cost of running the cluster. Given the future for the number of deployments, our client was looking at optimizing the TCO of running the analytics cluster.
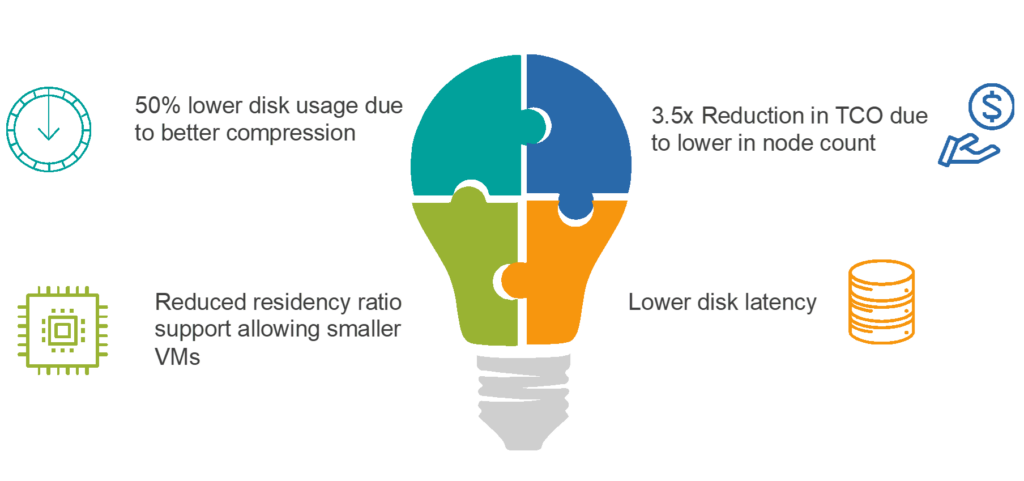
The launch of the Couchbase Magma storage engine came at the perfect time for us, and we were one of the early adopters of the new technology. We created an archive cluster to take data from the main Couchstore-based cluster (Couchstore is the original deep storage engine) and implemented a 6-week TTL on the main cluster. The main cluster had 14 data nodes, but we were able to reduce the size of the archive cluster running Magma to just 4 data nodes. That’s a 3.5x reduction in needed hardware and storage capacity. This resulted in an annual savings of around $800K! We could have pushed it even more, but we have left enough headroom to accommodate future growth for the next 12 – 14 months.
There were two key features of Magma that allowed us to do this dramatic reduction:
- The size of disks was increased to 10 TB per node (max recommended on Magma) compared to 1.5 TB limit per node
- Reducing the residency ratio to 5% for the buckets (lowest recommended being 1%) compared to 40% for Couchstore
Another interesting benefit that we were able to observe is the savings in disk usage due to block compression. We saw an almost 50% better compression on the Magma engine compared to Couchstore with the disk usage per document going from 2.28 KB/doc to 1.47 KB/doc on disk for data that is fairly uniform.
As next steps we intend to take the 7.1.2 version of Couchbase which has support for Analytics and Eventing on Magma and improve the data segregation on the Magma cluster. We will be able to split the data by month and year to allow for specific data required for historical research to be located efficiently.
If you are interested in the internal workings of Magma, I recommend you go through the paper presented at VLDB 2022 here.
Leave a comment
You must be logged in to post a comment.