En los sistemas distribuidos modernos, la capacidad de replicar datos entre entornos separados es crucial para garantizar la alta disponibilidad, la recuperación ante desastres y la optimización del rendimiento. La función XDCR (Cross Data Center Replication) de Couchbase permite replicar datos sin problemas entre clústeres, lo que permite compartir datos de forma robusta entre entornos geográfica o lógicamente aislados.
Esta guía le guiará a través de la configuración de XDCR entre dos clústeres de Couchbase alojados en clústeres separados de Amazon EKS (Elastic Kubernetes Service) dentro de diferentes VPC. Analizaremos cada paso, desde la configuración de la infraestructura hasta la configuración de DNS para la comunicación entre clústeres y el despliegue de Couchbase para la replicación en tiempo real. Al final de este recorrido, tendrás una configuración lista para producción con las habilidades para replicar esto en tu entorno.
Requisitos previos
Para seguir esta guía, asegúrese de tener:
-
- CLI DE AWS instalado y configurado
- Una cuenta de AWS con permisos para crear VPC, clústeres EKS y grupos de seguridad
- Familiaridad con Kubernetes y herramientas como kubectl y Helm
- Helm instalado para desplegar Couchbase
- Conocimientos básicos de conceptos de redes, incluidos bloques CIDR, tablas de enrutamiento y DNS.
Paso 1: Despliegue de clústeres EKS en VPC independientes
¿Qué estamos haciendo?
Crearemos dos clusters Kubernetes, Cluster1 y Cluster2, en VPCs separadas utilizando eksctl. Cada clúster funcionará de forma independiente y tendrá su propio bloque CIDR para evitar conflictos de IP.
¿Por qué es importante?
Esta separación garantiza:
-
- Aislamiento para mejorar la seguridad y la gestión
- Escalabilidad y flexibilidad para gestionar las cargas de trabajo
- Reglas claras de enrutamiento entre clusters
Comandos para crear clusters
Desplegar clúster1
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster1 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.0.0.0/16 |
Desplegar clúster2
|
1 2 3 4 5 6 7 8 9 10 |
eksctl create cluster \ --name cluster2 \ --region us-east-1 \ --zones us-east-1a,us-east-1b,us-east-1c \ --node-type t2.medium \ --nodes 2 \ --nodes-min 1 \ --nodes-max 3 \ --version 1.27 \ --vpc-cidr 10.1.0.0/16 |
Resultados esperados
-
- Cluster1 reside en VPC 10.0.0.0/16
- Cluster2 reside en VPC 10.1.0.0/16

Paso 2: Emparejar las VPC para la comunicación entre clústeres
¿Qué estamos haciendo?
Estamos creando una conexión VPC Peering entre las dos VPCs y configurando reglas de enrutamiento y seguridad para permitir la comunicación inter-clúster.
Pasos
2.1 Crear una conexión igualitaria
-
- Vaya a la consola de AWS > VPC > Conexiones Peering
- Haga clic en Crear conexión paritaria
- Seleccione VPC solicitante (Cluster1 VPC) y Aceptador VPC (Cluster2 VPC)
- Nombre de la conexión eks-peer
- Haga clic en Crear conexión paritaria
2.2 Aceptar la solicitud de interconexión
-
- Seleccione la conexión igualitaria
- Haga clic en Acciones > Aceptar solicitud
2.3 Actualizar tablas de rutas
-
- Para Cluster1 VPC, añada una ruta para 10.1.0.0/16, apuntando a la conexión peering
- Para Cluster2 VPC, añada una ruta para 10.0.0.0/16, apuntando a la conexión peering

2.4 Modificar los grupos de seguridad
¿Por qué es necesario?
Los grupos de seguridad actúan como cortafuegos, y debemos permitir el tráfico entre los clusters explícitamente.
Cómo modificar
-
- Vaya a EC2 > Grupos de seguridad en la consola de AWS
- Identificar los grupos de seguridad asociados a Cluster1 y Cluster2
- Para el grupo de seguridad de Cluster1:
- Haga clic en Editar reglas de entrada
- Añade una regla:
- Tipo: Todo el tráfico
- Fuente: ID del grupo de seguridad de Cluster2
- Repetir para Cluster2, permitiendo el tráfico del grupo de seguridad de Cluster1.



Paso 3: Probar la conectividad desplegando NGINX en Cluster2
¿Qué estamos haciendo?
Estamos desplegando un pod NGINX en Cluster2 para verificar que Cluster1 puede comunicarse con él.
¿Por qué es importante?
Este paso asegura que la red entre clusters es funcional antes de desplegar Couchbase.
Pasos
3.1 Crear un espacio de nombres en Cluster1 y Cluster2
|
1 2 |
kubectl create ns dev #in cluster1 kubectl create ns prod #in cluster2 |
3.2 Despliegue de NGINX en Cluster1 y Cluster2
-
- Crea nginx.yaml:
12345678910111213141516171819202122232425262728293031apiVersion: apps/v1kind: Deploymentmetadata:name: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80---apiVersion: v1kind: Servicemetadata:name: nginxspec:clusterIP: Noneports:- port: 80targetPort: 80selector:app: nginx
- Crea nginx.yaml:
3.3 Aplicar el YAML
|
1 |
kubectl apply -f nginx.yaml -n prod |
3.4 Verificar la conectividad desde Cluster1
-
- Ejecutar en el pod en Cluster1:
1kubectl exec -it -n dev <pod-name> -- /bin/bash
- Ejecutar en el pod en Cluster1:
3.5 Prueba de conectividad con Cluster2
|
1 |
curl nginx.prod |
Resultados esperados
En rizo fallará sin el reenvío DNS, lo que pone de manifiesto la necesidad de una mayor configuración DNS.

Paso 4: Configuración del reenvío DNS
¿Qué estamos haciendo?
Configuraremos el reenvío DNS para que los servicios en Cluster2 puedan ser resueltos por Cluster1. Esto es crítico para permitir que las aplicaciones en Cluster1 interactúen con los servicios en Cluster2 usando sus nombres DNS.
¿Por qué es importante?
El descubrimiento de servicios Kubernetes se basa en DNS, y por defecto, las consultas DNS para los servicios de un clúster no se pueden resolver en otro clúster. CoreDNS en Cluster1 debe reenviar las consultas a la resolución DNS de Cluster2.
Pasos
4.1 Recuperar el punto final del servicio DNS de Cluster2
-
- Ejecute el siguiente comando en Cluster2 para obtener el endpoint del servicio DNS:
1kubectl get endpoints -n kube-system - Busque el kube-dns o coredns y anote su dirección IP. Por ejemplo:
1234----------------------------------------NAME ENDPOINTS AGEkube-dns 10.1.20.116:53 3h----------------------------------------

- Ejecute el siguiente comando en Cluster2 para obtener el endpoint del servicio DNS:
4.2 Editar el CoreDNS ConfigMap en Cluster1
-
- Abra el CoreDNS ConfigMap para editarlo:
1kubectl edit cm coredns -n kube-system
- Abra el CoreDNS ConfigMap para editarlo:
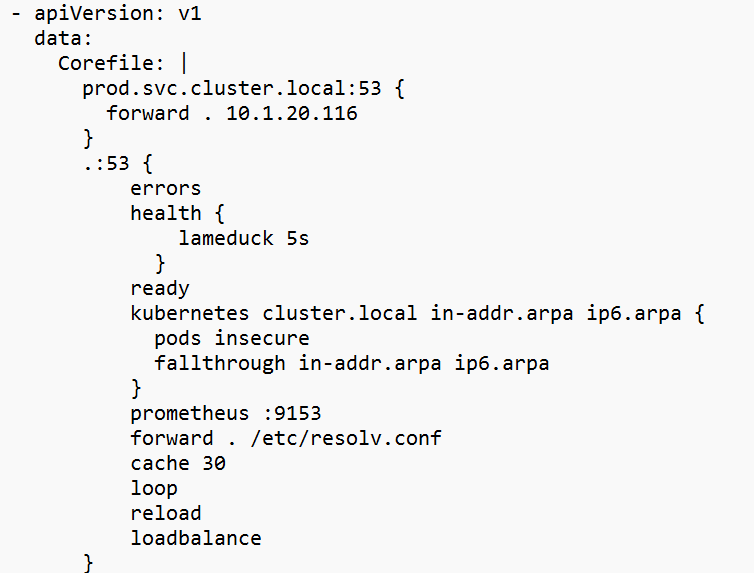
4.3 Add el siguiente bloque en la sección Corefile
|
1 2 3 |
prod.svc.cluster.local:53 { forward . 10.1.20.116 } |
Sustituya 10.1.20.116 por la IP real del endpoint DNS de Cluster2.
Nota: Sólo necesitamos utilizar uno de los endpoints CoreDNS para este ConfigMap. La IP de los pods CoreDNS raramente cambia pero puede hacerlo si el Nodo se cae. El servicio kube-dns ClusterIP puede ser utilizado pero requerirá que la IP y el Puerto estén abiertos en los Nodos EKS.
4.4 Reiniciar CoreDNS en Cluster1
-
- Aplique los cambios reiniciando CoreDNS:
1kubectl rollout restart deployment coredns -n kube-system

- Aplique los cambios reiniciando CoreDNS:
4.5 Verificar el reenvío DNS
-
- Ejecutar en cualquier pod en Cluster1:
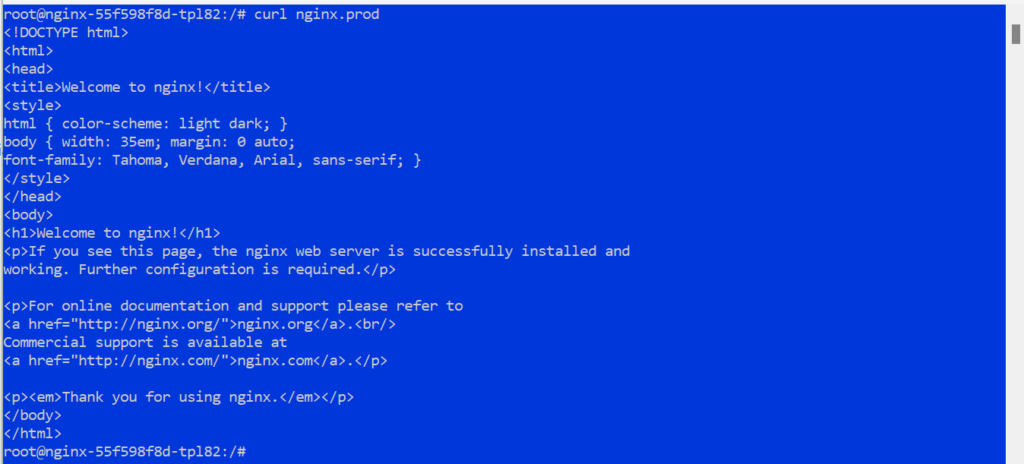
1kubectl exec -it -n default <pod-name> -- /bin/bash - Probar la resolución DNS para un servicio NGINX en Cluster2:
1curl nginx.prod.svc.cluster.local - Debería ver una respuesta del servicio NGINX
- Ejecutar en cualquier pod en Cluster1:
Resultados esperados
Las consultas DNS desde Cluster1 a Cluster2 deberían resolverse correctamente.
Paso 5: Despliegue de Couchbase
¿Qué estamos haciendo?
Desplegaremos clústeres de Couchbase en ambos entornos Kubernetes utilizando Helm. Cada clúster gestionará sus propios datos de forma independiente antes de conectarse a través de XDCR.
¿Por qué es importante?
Los clústeres Couchbase forman la base de la configuración XDCR, proporcionando una plataforma de base de datos NoSQL robusta y escalable.
Pasos
5.1 Añadir el repositorio de gráficos Couchbase Helm
|
1 2 |
helm repo add couchbase https://couchbase-partners.github.io/helm-charts/ helm repo update |
5.2 Despliegue de Couchbase en Cluster1
-
- Cambia a Cluster1:
1kubectl config use-context <cluster1-context> - Despliegue Couchbase:
1helm install couchbase couchbase/couchbase-operator --namespace dev
- Cambia a Cluster1:

5.3 Despliegue de Couchbase en Cluster2
-
- Cambia a Cluster2:
1kubectl config use-context <cluster2-context> - Despliegue Couchbase:
1helm install couchbase couchbase-operator --namespace prod
- Cambia a Cluster2:
5.4 Verificar la implantación
-
- Comprueba los pods de Couchbase:
12kubectl get pods -n dev # For Cluster1kubectl get pods -n prod # For Cluster2

- Asegúrese de que todos los pods están funcionando.
- Comprueba los pods de Couchbase:

Nota: Si encuentra un error de despliegue, edite el CRD de CouchbaseCluster para utilizar una versión de imagen compatible:
|
1 |
kubectl edit couchbasecluster <cluster-name> -n <namespace> |
Cambia:
|
1 |
image: couchbase/server:7.2.0 |
Para:
|
1 |
image: couchbase/server:7.2.4 |
Resultados esperados
Los clusters de Couchbase deben estar funcionando y accesibles a través de sus respectivas interfaces de usuario.
Paso 6: Configuración de XDCR
¿Qué estamos haciendo?
Configuraremos XDCR para habilitar la replicación de datos entre los dos clusters de Couchbase.
¿Por qué es importante?
XDCR garantiza la coherencia de los datos en todos los clústeres, lo que permite escenarios de alta disponibilidad y recuperación ante desastres.
Pasos
6.1 Obtener el nombre del servicio de Cluster2
-
- En cluster2 ejecute el siguiente comando para recuperar el nombre de servicio de uno de los pods para que podamos hacer port-forward a él.
1kubectl get services -n prod
- En cluster2 ejecute el siguiente comando para recuperar el nombre de servicio de uno de los pods para que podamos hacer port-forward a él.
6.2 Acceso a la interfaz de usuario de Couchbase para Cluster2
-
-
- Portar la interfaz de usuario de Couchbase:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- Portar la interfaz de usuario de Couchbase:
-
-
- Abra un navegador y vaya a
https://localhost:8091
- Abra un navegador y vaya a
-
- Inicie sesión con las credenciales configuradas durante la implantación.
6.3 Ver documentos en Cluster2
-
- En la interfaz de usuario de Couchbase, vaya a Cubos
- Tenga en cuenta que no existen Documentos en el por defecto cubo

6.4 Acceso a la interfaz de usuario de Couchbase para Cluster1
-
- Portar la interfaz de usuario de Couchbase:
1kubectl port-forward -n dev cluster1-0000 8091:8091

- Abra un navegador y vaya a
https://localhost:8091 - Inicie sesión con las credenciales configuradas durante la implantación
- Portar la interfaz de usuario de Couchbase:
6.5 Añadir un Cluster Remoto
-
- En la interfaz de usuario de Couchbase, vaya a XDCR > Añadir Cluster Remoto
- Configure el clúster remoto:
- Nombre del clúster: Grupo2
- IP/Nombre de host:.prod.svc.cluster.local
- Nombre de usuario: Nombre de usuario de administrador para Cluster2
- Contraseña: Contraseña de administrador para Cluster2
- Haga clic en Guardar

6.6 Configurar la replicación
-
- En la interfaz de usuario de Couchbase para Cluster1, vaya a XDCR > Añadir replicación
- Configure la replicación:
- Replicar desde cubo: Cubo por defecto en Cluster1
- Replicar a cubo: Cubo por defecto en Cluster2
- Cluster remoto: Seleccione Cluster2
- Haga clic en Guardar


6.7 Replicación de pruebas
-
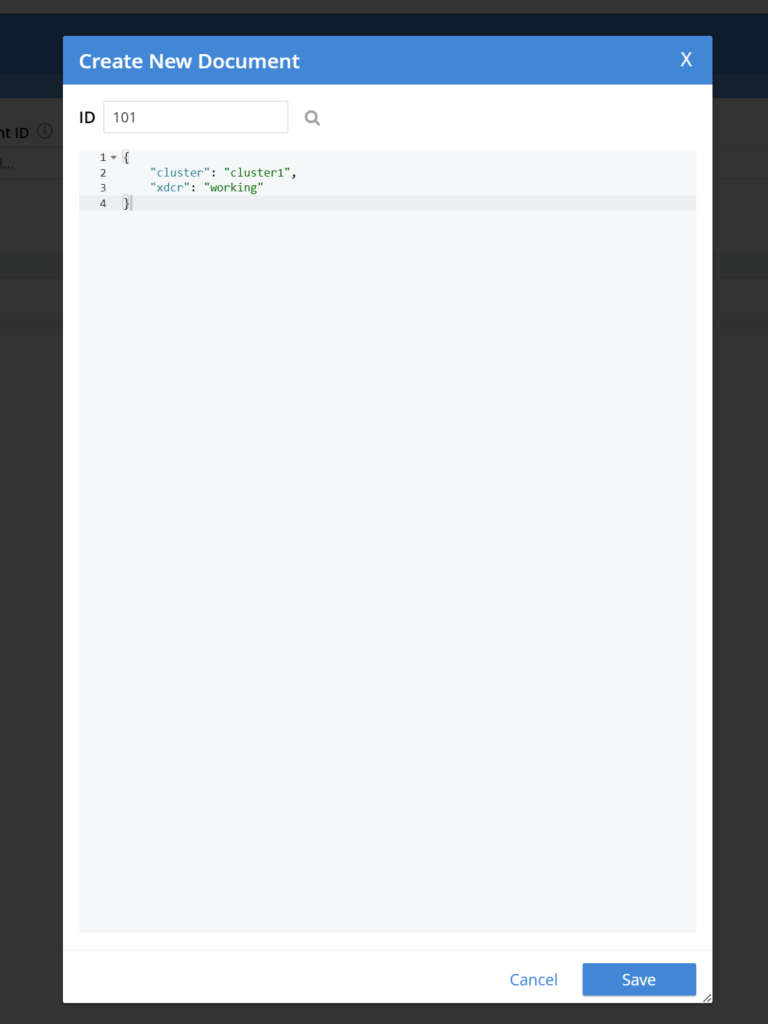
- Añade documentos de muestra al bucket por defecto en Cluster1:
- En la interfaz de usuario de Couchbase, vaya a Cubos > Documentos > Añadir documento
- Dar el Documento un único ID y algunos datos en JSON formato
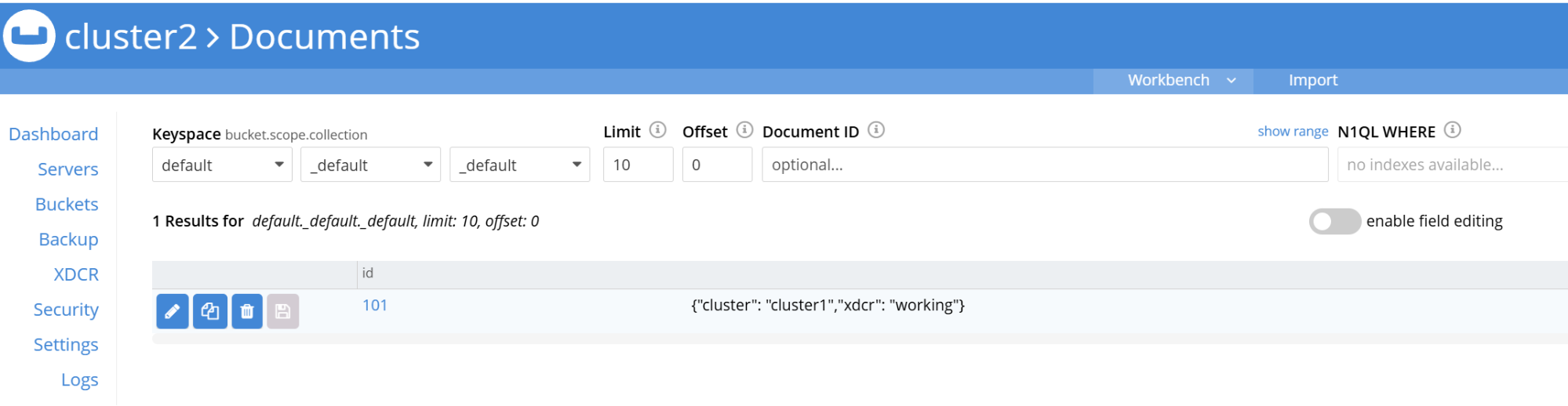
- Comprueba que los documentos aparecen en el bucket por defecto de Cluster2:
- Reenvíe el puerto a la interfaz de Cluster2 e inicie sesión:
1kubectl port-forward -n prod cluster2-0000 8091:8091
- Reenvíe el puerto a la interfaz de Cluster2 e inicie sesión:
- Navega hasta: https://localhost:8091
- Añade documentos de muestra al bucket por defecto en Cluster1:

Resultados esperados
Los datos añadidos al Cluster1 deben replicarse al Cluster2 en tiempo real.
Paso 7: Limpieza
¿Qué estamos haciendo?
Limpiaremos nuestro entorno AWS y borraremos todos los recursos que hemos desplegado.
¿Por qué es importante?
Esto evitará que incurra en gastos innecesarios.
Pasos
7.1 Acceder a la consola de AWS
-
- Vaya a la consola de AWS > VPC > Conexiones Peering
- Seleccione y elimine la conexión igualitaria
- Vaya a la consola de AWS > CloudFormation > Pilas
- Selecciona y elimina las dos pilas de nodegroups
- Una vez que las dos pilas de nodegroups hayan terminado de borrarse seleccione y borre las pilas de cluster
Resultados esperados
Todos los recursos creados para este tutorial se eliminan de la cuenta.
Conclusión
A través de esta guía, hemos establecido con éxito XDCR entre clústeres Couchbase que se ejecutan en clústeres EKS separados a través de AWS VPC. Esta configuración destaca el poder de combinar las redes de AWS con Kubernetes para obtener soluciones sólidas y escalables. Con la replicación entre clústeres implementada, sus aplicaciones ganan en resiliencia, latencia reducida para usuarios distribuidos y un mecanismo sólido de recuperación de desastres.
Al comprender y poner en práctica los pasos que aquí se describen, estará preparado para enfrentarse a los retos del mundo real que implican las configuraciones multiclúster, ampliando su experiencia tanto en las redes en la nube como en la gestión de bases de datos distribuidas.
-
- Más información Replicación entre centros de datos de Couchbase (XDCR)
- Leer el Documentación XDCR
- Lee cómo XDCR es esencial para los datos distribuidos globalmenteRecuperación en caso de catástrofe y alta disponibilidad

