¿Qué es la búsqueda vectorial?
Los desarrolladores recurren en masa a la búsqueda vectorial para que sus aplicaciones se adapten mejor a los usuarios. El término busque en implica que la búsqueda vectorial sirve para encontrar y comparar objetos utilizando un concepto conocido como vectores. En pocas palabras, le ayuda a encontrar similitud entre objetos, lo que permite encontrar relaciones complejas y contextuales en los datos. Es una tecnología que respalda y potencia las aplicaciones de búsqueda de última generación.
La búsqueda vectorial es una función de búsqueda impulsada por IA en plataformas de datos modernas, como bases de datos vectorialesque ayuda a los usuarios a crear aplicaciones más flexibles. Ya no está limitado a la búsqueda básica de palabras clave; en su lugar, puede encontrar semánticamente similares información en cualquier tipo de soporte digital.
En esencia, es uno de los muchos sistemas de aprendizaje automático impulsados por grandes modelos lingüísticos (LLM) de diversos tamaños y complejidad. Están disponibles a través de bases de datos y plataformas tradicionales e incluso se están empujando a la borde para funcionar en dispositivos móviles.
Para obtener más información sobre la búsqueda vectorial, los términos relacionados, las capacidades y cómo se aplica a las innovaciones modernas de la tecnología de bases de datos en inteligencia artificial (IA), seguir leyendo.
¿Qué significa vector?
Un vector es un estructura de datos que contiene una matriz de números. En nuestro caso, se trata de vectores que almacenan un resumen digital del conjunto de datos al que se han aplicado. Puede considerarse una huella digital o un resumen, pero formalmente se denomina incrustación. He aquí un ejemplo rápido de cómo podría ser uno:
|
1 |
"blue t-shirts": [-0.02511234 0.05473123 -0.01234567 ... 0.00456789 0.03345678 -0.00789012] |
Ventajas de la búsqueda vectorial
La búsqueda vectorial ofrece una serie de nuevas posibilidades a las bases de datos y a las aplicaciones que las utilizan. En pocas palabras, la búsqueda vectorial ayuda a los usuarios a encontrar más coincidencias contextuales dentro de una gran colección de información (también conocida como corpus). La idea de cercanía es importante: la búsqueda vectorial agrupa estadísticamente los elementos para mostrar su similitud o relación. Esto se aplica a mucho más que texto, aunque muchos de nuestros ejemplos se basan en texto para facilitar la comparación con los sistemas de búsqueda tradicionales.
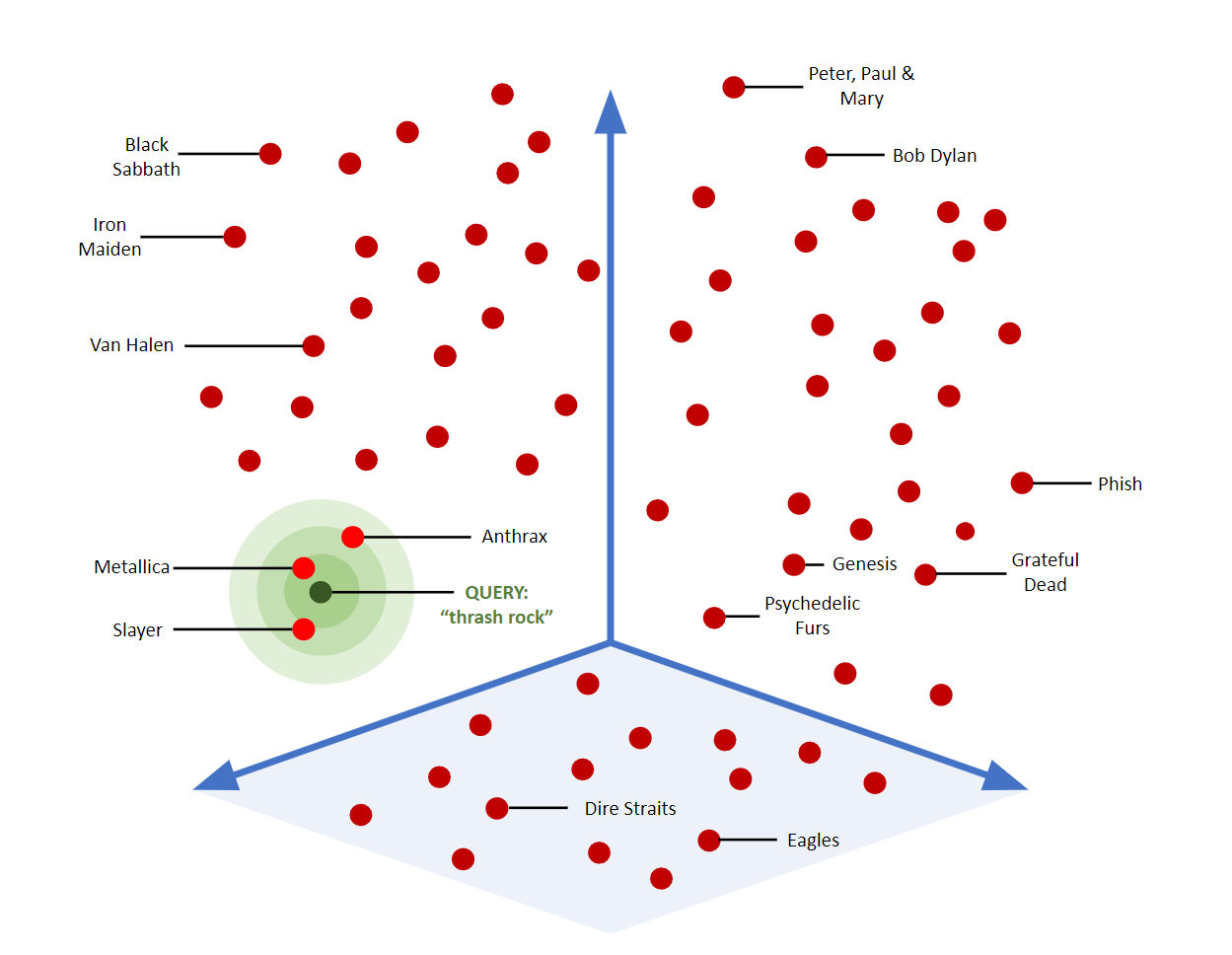
Este gráfico muestra un ejemplo visual de cómo la búsqueda vectorial puede mapear, encontrar y agrupar objetos "similares" en el espacio 3D.
Acceso a amplios conocimientos generales
La búsqueda vectorial es también una gran estrategia para introducir herramientas de inteligencia artificial en una aplicación, proporcionando una flexibilidad adaptativa imposible con las herramientas de búsqueda tradicionales por sí solas. Debido al gran volumen de LLM públicos disponibles, cualquier empresa puede adoptar uno y utilizarlo como base para la búsqueda en sus aplicaciones. Como los LLM almacenan mucha información, los resultados de las búsquedas en ellos pueden añadir un valor exponencial a su aplicación sin tener que escribir ningún código complejo. Es una forma de actualizar muchas aplicaciones con nuevas y potentes funciones.
Búsqueda superpotente frente a búsqueda tradicional
Afortunadamente, la búsqueda vectorial también es más rápida en situaciones más complejas. Los sistemas de búsqueda tradicionales basados en palabras clave pueden optimizarse para encontrar texto coincidente en los documentos, pero una vez que es necesario aplicar algoritmos complejos de coincidencia difusa o soluciones extremas de predicados booleanos (muchas cláusulas WHERE, por ejemplo), empieza a ser más lento y complejo.
Las diversas compensaciones necesarias para buscar con éxito en entornos complejos pueden evitarse con la búsqueda vectorial. Sin embargo, la compensación necesitará una API a nivel de servicio (por ejemplo, OpenAI) con los recursos adecuados para ayudarle a interconectar las aplicaciones con un LLM. También tendrás opciones y limitaciones dependiendo del LLM que esté detrás de tu sistema de búsqueda vectorial.
¿Cuál es la diferencia entre la búsqueda tradicional y la búsqueda vectorial?
Las ventajas anteriores se solapan con algunas de las diferencias técnicas entre los enfoques de búsqueda tradicional y vectorial. En esta sección, investigamos qué es lo que realmente importa entre estos distintos enfoques.
Contexto y búsqueda semántica
Muchos sistemas diferentes relacionados con la búsqueda han utilizado palabras clave o frases optimizadas para encontrar preciso coincidencias textuales o para encontrar los documentos que utilizan una palabra clave con más frecuencia. El problema es que estas búsquedas pueden carecer de contexto y flexibilidad. Por ejemplo, una búsqueda textual de "árbol" puede no coincidir nunca con datos que contengan nombres reales de especies arbóreas, aunque fueran muy pertinentes. Este tipo de concordancia contextual es una forma de búsqueda semántica-donde el contexto y la relación entre las palabras importan.
Similitud
Pero la búsqueda vectorial no se limita a las relaciones semánticas. Por ejemplo, en una aplicación basada en texto, va más allá del uso de palabras y frases sueltas para encontrar similar cotejar documentos a partir de palabras, frases, párrafos o más, buscando ejemplos de texto que coincidan con la semántica y el contexto a un nivel muy profundo.
La búsqueda de similitudes también funciona para las imágenes. Si tuvieras que escribir una aplicación que comparara dos imágenes, ¿cómo lo harías? Si te limitaras a comparar cada píxel de una con cada píxel de otra, sólo encontrarías imágenes que sean idéntico en color, resolución, codificación, etc. Pero si pudieras analizar tus imágenes y producir una incrustación vectorial del contenido, podrías compararlas y encontrar coincidencias. Aplicado al ejemplo de las imágenes, una incrustación vectorial describe el contenido de cada imagen y, a continuación, permite compararlas: una forma mucho más sólida de compararlas y encontrar "similitudes" entre ellas.
Más información incrustación vectorial en nuestra otra entrada del blog en detalle, o siga leyendo para obtener una visión general básica.
Cómo funciona la búsqueda vectorial
La búsqueda vectorial crea y compara incrustaciones vectoriales. Funciona según el principio de que los datos pueden convertirse en una representación vectorial numérica (incrustación) y compararse con otros datos catalogados con una representación digital similar (mediante LLM).
Indexa distintos tipos de contenidos digitales (texto, audio, vídeo, etc.) en un lenguaje común que entienden las redes neuronales. Consulte nuestro guía de la IA generativa que trata de las redes generativas adversariales (GAN) para aprender más sobre los enfoques de redes neuronales.
Los modelos creados por LLM contienen los vectores que representan los datos con los que se ha entrenado el modelo. Por ejemplo, cada párrafo de Wikipedia podría resumirse e indexarse como vectores. A continuación, un usuario puede enviar un vector de sus propios datos (normalmente creado mediante un proceso de incrustación) a un sistema de búsqueda vectorial para encontrar párrafos similares.
Hay mucho trabajo detrás de esos pasos, pero esa es la esencia.
Tres pasos para crear una aplicación de búsqueda vectorial
La creación o utilización de una aplicación de búsqueda vectorial consta de tres etapas. Éstas son:
-
- Creación de incrustaciones para sus datos o consultas personalizados
- Comparación de los resultados con un motor vectorial entrenado en grandes modelos lingüísticos (LLM) para encontrar la mejor correspondencia semántica de los datos con la corpus de datos en el modelo
- Comparar los resultados de LLM con los datos de su aplicación personalizada o base de datos para encontrar coincidencias más relevantes.
Paso 1 - Crear incrustaciones de una solicitud
Las incrustaciones actúan como la huella dactilar de un dato en las aplicaciones vectoriales, como una clave que puede utilizarse posteriormente en un índice. Un dato (texto, imágenes, vídeo, etc.) se envía a una aplicación de incrustación vectorial que lo convierte en una representación numérica en forma de lista de números (un vector). Esta incrustación vectorial representa el objeto suministrado a la aplicación de incrustación. Entre bastidores, se utiliza un motor de modelos lingüísticos extensos (LLM) para crear la incrustación, de modo que pueda utilizarse para recuperar coincidencias del mismo LLM en el paso siguiente.
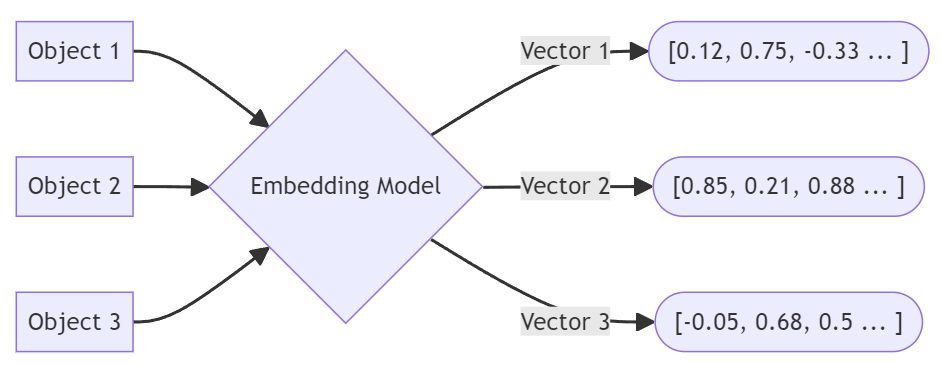
Los objetos se someten a un incrustación vectorial proceso.
En el mundo de las bases de datos, el texto de una columna de una tabla podría ejecutarse a través del motor de incrustación, y el objeto vectorial podría guardarse en una propiedad para esa fila u objeto JSON. Las incrustaciones de cada documento o registro se indexan para futuras comparaciones internas durante una solicitud de búsqueda.
Pensemos en una aplicación web que permite buscar en un catálogo comercial. Un usuario puede introducir un texto que describa un tipo de ropa y un color para buscar la disponibilidad. A partir de ahí, la aplicación envía la solicitud del usuario a un LLM como parte del proceso de incrustación vectorial. El LLM se utiliza para calcular una representación vectorial que se utilizará en el siguiente paso. "Camisetas azules" puede convertirse en un vector con este aspecto en una matriz de alta dimensión, como se muestra aquí almacenado en JSON:
|
1 2 3 4 |
{ "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] } |
Se trata de un ejemplo demasiado simplificado, pero en el fondo, las incrustaciones vectoriales no son más que matrices multidimensionales que resumen un conjunto de datos analizados por un proceso de aprendizaje automático concreto. Hay incrustaciones de distintos tipos y tamaños y se basan en una amplia gama de LLM diferentes, pero eso queda fuera del alcance de este artículo.
Paso 2 - Encontrar coincidencias de un LLM
Ahora, considere que un LLM ha creado esencialmente incrustaciones para todas las piezas de datos sobre las que se construyó. Si se utilizó Wikipedia para entrenar el LLM, quizá cada párrafo haya producido sus propias incrustaciones. ¡Muchas incrustaciones!
La etapa de búsqueda consiste en encontrar las incrustaciones que más se asemejen entre sí. Un motor de búsqueda vectorial puede tomar una incrustación existente o crearla sobre la marcha a partir de una consulta de búsqueda. Por ejemplo, puede tomar el texto introducido por el usuario en una aplicación o base de datos y utilizar el LLM para encontrar contenido similar en el modelo. A continuación, devuelve las coincidencias más relevantes para la aplicación.
Siguiendo con nuestro ejemplo del comercio, el vector "camisetas azules" puede utilizarse como clave para encontrar datos similares. La aplicación enviaría ese vector a un LLM central para encontrar los contenidos más similares y semánticamente relacionados basándose en las descripciones de texto o las imágenes analizadas al construir el LLM.
Por ejemplo, puede obtener una lista de cinco documentos que coinciden por similitud en sus incrustaciones vectoriales. Como puede ver, cada uno tiene su propia representación vectorial.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "embeddings": [ { "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] }, { "word": "navy shirt", "embedding": [0.71, -0.42, 0.85, 0.15, -0.68, 0.29, 0.53, 0.78] }, { "word": "azure top", "embedding": [0.73, -0.46, 0.87, 0.11, -0.64, 0.33, 0.56, 0.74] }, { "word": "cobalt blouse", "embedding": [0.75, -0.41, 0.89, 0.14, -0.67, 0.28, 0.54, 0.77] }, { "word": "sapphire tee", "embedding": [0.72, -0.44, 0.86, 0.13, -0.66, 0.30, 0.55, 0.76] }, { "word": "denim shirt", "embedding": [0.70, -0.43, 0.84, 0.16, -0.69, 0.27, 0.52, 0.79] } ] } |
Paso 3: Buscar coincidencias con sus propios datos
Si lo único que buscas son coincidencias con información almacenada en un LLM, entonces ya está. Sin embargo, las aplicaciones verdaderamente adaptativas querrán obtener coincidencias e información de fuentes de datos internas, como una base de datos corporativa.
Supongamos que los documentos o registros de la base de datos ya tienen incrustaciones vectoriales guardadas, además de las coincidencias del LLM. Ahora, puede tomarlos, enviarlos a la capacidad de búsqueda vectorial de su base de datos y encontrar documentos de la base de datos relacionados. Desde el punto de vista operativo, se parecería a otro campo indexado, pero daría una sensación más cualitativa a los resultados de la búsqueda.
¿Cómo encuentra coincidencias la búsqueda vectorial?
La búsqueda vectorial combina tres conceptos: datos generados por el usuario (una solicitud), un LLM corpus que incluye modelos que representan una fuente de datos (un modelo) y datos personalizados en una base de datos (correspondencia personalizada). La búsqueda vectorial permite que estos tres factores trabajen juntos.
¿Qué puede hacer la búsqueda vectorial?
La búsqueda vectorial encontrará similitudes entre cualquier tipo de datos siempre que pueda crear incrustaciones y compararlas con otras creadas del mismo modo (a partir del mismo LLM).
Dependiendo del LLM utilizado, los resultados pueden variar drásticamente debido a los datos de origen sobre los que se ha entrenado el LLM. Por ejemplo, si quieres buscar imágenes similares pero utilizas un LLM que solo incluye literatura clásica, obtendrás respuestas inutilizables (aunque si fueran imágenes de escritores clásicos, podría haber alguna esperanza).
Del mismo modo, si estás construyendo un caso legal y tu LLM sólo está entrenado en datos de Reddit, te estarás preparando para un escenario único que podría ser una gran película algún día (después de que te inhabiliten, por supuesto).
Por ello, asegúrese de que el LLM que impulsa su experiencia se dirige a los objetivos correctos caso práctico de búsqueda vectorial y la información que necesitas es importante. Los LLM generales muy amplios tendrán más contexto, pero los LLM especializados para tu sector tendrán información más precisa y matizada para tu negocio.
Cómo se realiza la búsqueda vectorial a escala
Cualquier sistema empresarial que realice búsquedas vectoriales debe ser capaz de escalar cuando entre en producción (consulte nuestra guía para la replicación de datos en la nube). Esto hace que los sistemas de búsqueda vectorial que pueden replicar y fragmentar sus índices especialmente crucial.
Cuando el sistema necesita buscar coincidencias en el índice, la carga de trabajo puede distribuirse entre varios nodos.
Del mismo modo, la creación de nuevas incrustaciones y su indexación también se beneficiarán de aislamiento de recursospor lo que otras funciones de la aplicación no se ven afectadas. El aislamiento de recursos significa que las funciones relacionadas con la búsqueda vectorial disponen de sus propios recursos de memoria, CPU y almacenamiento.
En el contexto de una base de datos, es esencial que todos los servicios reciban una asignación de recursos adecuada para que no compitan entre sí. Por ejemplo, los servicios de consulta de tablas, análisis en tiempo real, registro y almacenamiento de datos necesitan su propio espacio para respirar, además de los servicios de búsqueda vectorial.
API distribuidas para el acceso al LLM también son importantes. Dado que muchos otros servicios pueden estar solicitando incrustaciones, las API y los sistemas que producen las incrustaciones también deben ser capaces de crecer con más tráfico. En el caso de los servicios LLM basados en la nube, asegúrate de que sus acuerdos de nivel de servicio pueden satisfacer tus requisitos de producción antes de empezar a crear prototipos.
El uso de servicios externos a menudo puede ampliarse de forma rápida y eficiente, pero requerirá financiación adicional a medida que aumente su escala. Asegúrese de que las escalas de precios se entienden claramente al evaluar las opciones.
El futuro de la búsqueda vectorial
El desarrollo de aplicaciones adaptables se impulsará mediante búsqueda híbrida escenarios. Un único método de búsqueda o consulta ya no será suficiente para la flexibilidad necesaria en el futuro. Las capacidades de búsqueda híbrida permiten utilizar la búsqueda vectorial para obtener coincidencias semánticas, pero acotar los resultados mediante predicados SQL básicos e incluso realizar consultas geográficas utilizando un índice espacial.
El acoplamiento de estos elementos en una única experiencia de búsqueda híbrida facilitará a los desarrolladores la extracción de la máxima flexibilidad de sus aplicaciones. Esto incluirá la ampliación de todos los capacidades de búsqueda de vectores en la periferia con móviles integración de bases de datos, así como en la nube y on-prem.
Generación aumentada por recuperación (RAG) permitirá al desarrollador añadir un conocimiento contextual aún más personalizado sobre el LLM. Esto reducirá la necesidad de volver a entrenar un LLM al tiempo que ofrece a los desarrolladores la flexibilidad necesaria para mantener actualizados la incrustación y el emparejamiento.
La búsqueda vectorial también se definirá mediante un tipo de módulo de conocimiento enchufable que permite a las empresas aportar una amplia gama de información basada en LLM de diversas fuentes. Imaginemos una aplicación móvil de campo que ayude a mantener postes eléctricos. Una búsqueda semántica de imágenes podría ayudar a identificar problemas con la estructura física de un poste, pero con otro módulo de conocimiento sobre plantas, también podría advertir al usuario de una planta tóxica vista cerca.
Recursos de IA de Couchbase
Para seguir leyendo sobre búsqueda de vectores, estrategias y otros temas relacionados con inteligencia artificialconsulte los siguientes recursos:
-
- ¿Qué son las incrustaciones vectoriales?
- Desbloquear la búsqueda de siguiente nivel: El poder de las bases de datos vectoriales
- Visión general de la generación mejorada por recuperación
- Couchbase presenta un nuevo servicio de IA en la nube, Capella iQ
- Explicación de los grandes modelos lingüísticos
- Guía para el desarrollo de IA generativa
- Cómo funciona la IA generativa con Couchbase
- GenAI: una nueva herramienta para los desarrolladores
- Póngase manos a la obra con la búsqueda vectorial:
Búsqueda vectorial FAQ
¿Por qué es importante la búsqueda vectorial?
La búsqueda vectorial es importante porque ofrece una forma novedosa de encontrar similitudes y contextos entre datos digitales, utilizando lo último en aprendizaje automático y técnicas de IA.
¿Qué son las incrustaciones de búsqueda vectorial?
Las incrustaciones vectoriales son vectores que almacenan una representación numérica única de un fragmento de datos analizados. Los grandes modelos lingüísticos (LLM) son utilizados por aprendizaje automático (AM) herramientas para analizar los datos de entrada y producir las incrustaciones vectoriales que describen los datos. A continuación, la incrustación vectorial se almacena en una base de datos o un archivo para otro momento.
¿Cuál es la diferencia entre la búsqueda tradicional y la búsqueda vectorial?
La principal diferencia es que la búsqueda tradicional está optimizada para encontrar coincidencias precisas y exactas de palabras clave o frases, mientras que la búsqueda vectorial está diseñada para encontrar conceptos similares en un contexto de significado más definido.
¿Cuáles son los retos de la búsqueda vectorial?
El principal reto es que las aplicaciones deben basarse en grandes modelos lingüísticos (LLM) para ayudar a crear incrustaciones y encontrar coincidencias contextuales. Esta es una pieza nueva en la arquitectura de la información actual y requiere una cuidadosa evaluación de la seguridad, el rendimiento y la escalabilidad.