Ratnopam Chakrabarti es un desarrollador de software que trabaja actualmente para Ericsson Inc. Lleva bastante tiempo centrado en IoT, tecnologías máquina a máquina, coches conectados y dominios de ciudades inteligentes. Le encanta aprender nuevas tecnologías y ponerlas en práctica. Cuando no está trabajando, le gusta pasar tiempo con su hijo de 3 años.
La búsqueda basada en texto completo es una función que permite a los usuarios realizar búsquedas basadas en textos y palabras clave, y es muy popular entre los usuarios y la comunidad de desarrolladores. Por lo tanto, es obvio que hay muchas API y frameworks que ofrecen búsquedas de texto completo, como Apache Solr, Lucene y Elasticsearch, por nombrar solo algunos. Couchbaseuno de los principales gigantes de NoSQL, comenzó a implementar esta función en su versión 4.5 de Couchbase Server.
En este post, voy a describir cómo integrar el servicio de búsqueda de texto completo en su aplicación utilizando el módulo SDK Java de Couchbase.
Puesta en marcha
Vaya a start.spring.io y seleccione Couchbase como dependencia en su aplicación Spring boot.
Una vez que tengas el proyecto configurado, deberías ver la siguiente dependencia en tu archivo de modelo de objetos del proyecto (pom.xml). Asegura que todas las librerías de Couchbase están en su lugar para la aplicación.
<dependency>
org.springframework.boot
spring-boot-starter-data-couchbase
</dependency>
Es necesario configurar un bucket de Couchbase para alojar el conjunto de datos de muestra en el que realizar la búsqueda.
He creado un bucket llamado "conference" en la consola de administración de Couchbase.
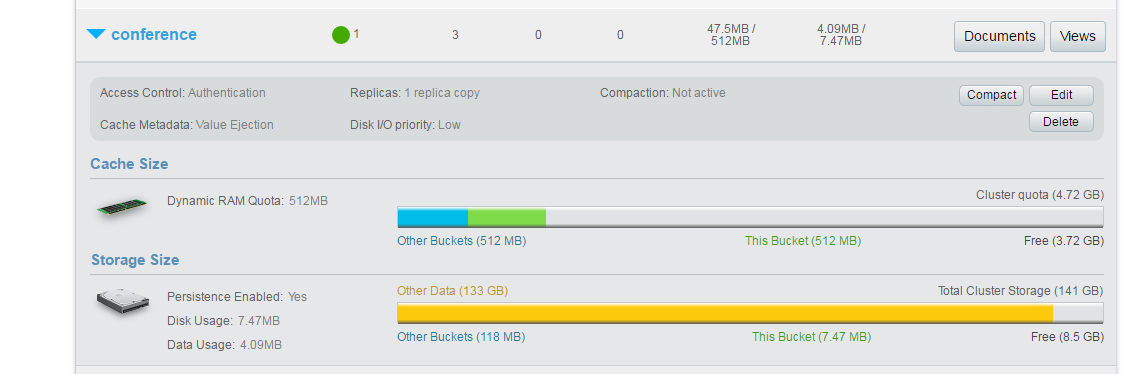
El bucket "conferencia" tiene actualmente tres documentos, y contienen datos sobre diferentes conferencias celebradas en todo el mundo. Si desea experimentar, puede ampliar este modelo de datos o crear uno propio. Por ejemplo, los currículos, los catálogos de productos o incluso los tweets son un buen caso de uso para la búsqueda de texto completo. Sin embargo, vamos a ceñirnos a los datos de las conferencias, como se muestra a continuación:
{
"title": "DockerCon",
"tipo": "Conferencia",
"localización": "Austin",
"inicio": "04/17/2017",
"end": "04/20/2017",
"topics": [
"contenedores",
"devops",
"microservicios",
"desarrollo de productos",
"virtualización"
],
"asistentes": 20000,
"resumen": "DockerCon contará con temas y contenidos que cubren todos los aspectos de Docker y su ecosistema y será adecuado para desarrolladores, DevOps, administradores de sistemas y ejecutivos de nivel C",
"social": {
"facebook": "https://www.facebook.com/dockercon",
"twitter": "https://www.twitter.com/dockercon"
},
"altavoces": [
{
"Nombre": "Arun Gupta",
"talk": "Docker con couchbase",
"date": "04/18/2017",
"duración": "2"
},
{
"Nombre": "Laura Frank",
"hablar": "Opensource",
"date": "04/19/2017",
"duración": "2"
}
]
}
Para poder utilizar la búsqueda de texto completo en el conjunto de datos anterior, primero debe crear un índice de búsqueda de texto completo. Realice los siguientes pasos:
En la consola de administración de Couchbase, haga clic en la pestaña Índices.
Haga clic en el enlace Texto completo, que mostrará una lista de los índices de texto completo actuales.
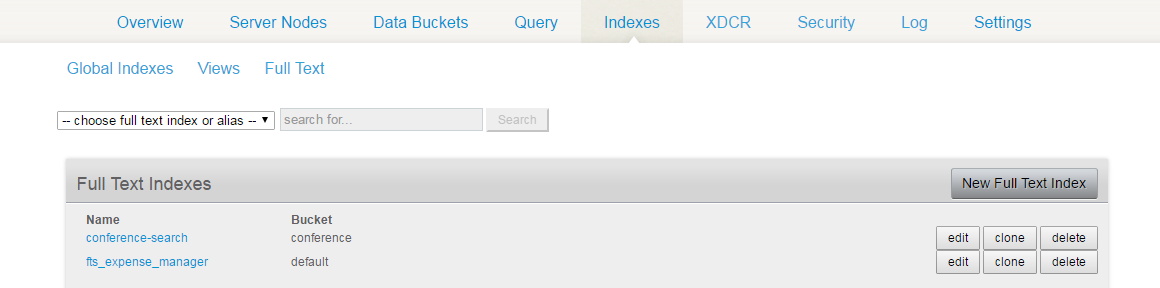
Como puedes adivinar, he creado un índice llamado "conference-search" que utilizaría desde el código Java para buscar los datos relacionados con la conferencia.
Haga clic en el botón Nuevo índice de texto completo para crear un nuevo índice.
Sí, es así de fácil. Una vez creado el índice, ya puedes utilizarlo desde la aplicación que estés creando.
Antes de sumergirnos en el código, echemos un vistazo a los otros dos documentos que ya están en el cubo.
Conferencia::2
{
"título": "Devoxx UK",
"tipo": "Conferencia",
"localización": "Bélgica",
"inicio": "05/11/2017",
"fin": "05/12/2017",
"topics": [
"nube",
"iot",
"big data",
"aprendizaje automático",
"realidad virtual"
],
"asistentes": 10000,
"resumen": "Devoxx UK vuelve a Londres en 2017. Una vez más, daremos la bienvenida a ponentes y asistentes increíbles para ofrecer el mejor contenido para desarrolladores y experiencias increíbles",
"social": {
"facebook": "https://www.facebook.com/devoxxUK",
"twitter": "https://www.twitter.com/devoxxUK"
},
"altavoces": [
{
"Nombre": "Viktor Farcic",
"hablar": "Cloudbees",
"date": "05/11/2017",
"duración": "2"
},
{
"Nombre": "Patrick Kua",
"hablar": "Thoughtworks",
"date": "05/12/2017",
"duración": "2"
}
]
}
Conferencia::3
{
"título": "ReInvent",
"tipo": "Conferencia",
"localización": "Las Vegas",
"inicio": "11/28/2017",
"end": "11/30/2017",
"topics": [
"aws",
"sin servidor",
"microservicios",
"computación en nube",
"realidad aumentada"
],
"asistentes": 30000,
"resumen": "Aamazon web services reInvent 2017 promete un recinto más grande, más sesiones y un enfoque en tecnologías como microservicios y Lambda.",
"social": {
"facebook": "https://www.facebook.com/reinvent",
"twitter": "https://www.twitter.com/reinvent"
},
"altavoces": [
{
"Nombre": "Ryan K",
"talk": "Amazon Alexa",
"date": "11/28/2017",
"duración": "2.5"
},
{
"Nombre": "Anthony J",
"hablar": "Lambda",
"date": "11/29/2017",
"duración": "1.5"
}
]
}
Invocar la búsqueda de texto completo desde código Java
Conectarse al bucket Couchbase desde el código
Spring boot ofrece una forma cómoda de conectar con el entorno Couchbase permitiéndonos especificar ciertos detalles del entorno Couchbase como una configuración de Spring. Normalmente especificamos los siguientes parámetros en el archivo application.properties:
spring.couchbase.bootstrap-hosts=127.0.0.1
spring.couchbase.bucket.name=conferencia
spring.couchbase.bucket.password=
Aquí, he especificado mi ip localhost ya que estoy ejecutando Couchbase Server en mi portátil. Nota: Puedes ejecutar Couchbase como un contenedor Docker proporcionando la dirección IP del contenedor.
El nombre del bucket tiene que coincidir con el nombre del bucket creado usando la consola de Couchbase.
También podemos especificar un cluster de direcciones IP como bootstrap-hosts. Spring proporcionará un cluster de entorno Couchbase con todos los nodos ejecutando Couchbase en ellos. Si se estableció una contraseña cuando se creó el bucket, también podemos especificarla; de lo contrario, deja ese campo vacío. En nuestro caso, lo dejamos vacío.
Para ejecutar una consulta contra el bucket deseado, primero necesitamos tener una referencia al objeto bucket. Y la configuración de spring-couchbase hace todo el trabajo pesado entre bastidores por nosotros. Todo lo que tenemos que hacer es inyectar el bucket desde el constructor dentro de la clase Spring service bean.
Aquí está el código:
@Servicio
public class Servicio de búsqueda de texto completo {
privado Bucket bucket;
public FullTextSearchService(Bucket bucket) {
this.bucket = bucket;
log.info("******** Cubo :: = " + cubo.nombre());
}
public void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(
new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields("summary"));
for (SearchQueryRow hit : result.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "
+ bucket.get(hit.id()).content().get("title"));
}
}
También podemos personalizar algunos de los parámetros de configuración de CouchbaseEnvironment. Para una lista detallada de los parámetros que podemos personalizar, echa un vistazo a lo siguiente directrices de referencia:
En este punto, podemos invocar el servicio desde el archivo CommandLineRunner frijol.
@Configuración
public class FtsRunner implements CommandLineRunner {
@Autowired
FullTextSearchService fts;
@Override
public void run(String... arg0) throws Exception {
fts.findByTextMatch("desarrollador");
}
}
Utilizar el servicio de búsqueda de texto completo
En el núcleo del SDK de Java, Couchbase ofrece consulta() como una forma de consulta en un cubo especificado. Si está familiarizado con N1QL Query o View Query, entonces el método consulta() ofrece un patrón similar; la única diferencia para Search es que acepta un método BúsquedaQuery como argumento.
A continuación se muestra el código que busca un texto determinado en el cubo "conferencia". getBucket() devuelve un asa del cubo.
Al crear una SearchQuery, debe proporcionar el nombre del índice que creó en la sección Configuración anterior. Aquí, estoy utilizando "conference-search" como el índice que se especifica en el FtsConstants.FTS_IDX_CONF. Por cierto, el código fuente completo de la aplicación está cargado en GitHub y disponible para su descarga. El enlace está al final del post.
public static void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields("summary"));
log.info("****** total aciertos := "+ resultado.aciertos().tamaño());
for (SearchQueryRow hit : result.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "+ bucket.get(hit.id()).contenido().get("título"));
}
}
El código anterior busca en el campo "summary" de los documentos del bucket utilizando la función matchPhrase(searchText) método.
El código se invoca mediante una simple llamada:
findByTextMatch("desarrollador");
Así, la búsqueda de texto completo debe devolver todos los documentos del bucket de conferencias que tengan el texto "desarrollador" en su campo de resumen. Este es el resultado:
Conferencia del cubo abierto
****** total aciertos := 1
****** puntuación := 0.036940739161339185 y contenido := Devoxx UK
El total de aciertos representa el número total de coincidencias encontradas. Aquí es 1 y también se puede encontrar la puntuación correspondiente a esa coincidencia. El código no imprime todo el documento, sólo el título de la conferencia. Si lo desea, puede imprimir los demás atributos del documento.
Existen otras formas de utilizar SearchQuery que se describen a continuación.
Búsqueda de texto difuso
Puede realizar una consulta difusa especificando un máximo de Distancia Levenshtein como el máximo fuzziness() a permitir en el término. El valor predeterminado es 2.
Por ejemplo, digamos que quiero encontrar la conferencia en la que "sysops" es uno de los "temas". En el conjunto de datos anterior, se puede ver que no hay temas "sysops" en ninguna de las conferencias. La coincidencia más cercana es "devops"; sin embargo, está a 3 distancias de Levenshtein. Por tanto, si ejecuto el siguiente código con fuzziness 1 o 2, no debería obtener ningún resultado, y no lo hace.
SearchQueryResult resultFuzzy = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.match(searchText).fuzziness(2)).fields("topics"));
log.info("****** total aciertos := "+ resultFuzzy.aciertos().tamaño());
for (SearchQueryRow hit : resultFuzzy.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "+ bucket.get(hit.id()).contenido().get("temas"));
}
findByTextFuzzy("sysops"); da el siguiente resultado:
total aciertos := 0
Ahora, si cambio la borrosidad a "3" y vuelvo a invocar el mismo código, me devuelve un documento. Allá va:
****** total aciertos := 1
****** puntuación := 0.016616112953992054 y contenido := ["contenedores","devops", "microservicios", "desarrollo de productos", "virtualización"]
Dado que "devops" coincide con "sysops" con una imprecisión de 3, la búsqueda es capaz de encontrar el documento.
Consulta de expresiones regulares
Puede realizar consultas basadas en expresiones regulares utilizando SearchQuery. El siguiente código utiliza la función RegExpQuery para buscar en "temas" basados en un patrón suministrado.
RegexpQuery rq = new RegexpQuery(regexp).field("topics");
SearchQueryResult resultRegExp = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, rq));
log.info("****** total aciertos := "+ resultadoRegExp.aciertos().tamaño());
for (SearchQueryRow hit : resultRegExp.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "+ bucket.get(hit.id()).contenido().get("temas"));
}
Cuando se invoca como
findByRegExp("[a-z]*\s*realidad");
Devuelve los 2 documentos siguientes:
****** total aciertos := 2
****** puntuación := 0.11597946228887497 y contenido := ["aws", "serverless", "microservicios", "cloud computing","realidad aumentada“]
****** puntuación := 0.1084888528694293 y contenido := ["nube", "iot", "big data", "aprendizaje automático","realidad virtual“]
Consulta por prefijo
Couchbase permite realizar consultas basadas en el "prefijo" de un elemento de texto. La API busca textos que empiecen por el prefijo especificado. El código es sencillo de utilizar; busca en el campo "resumen" del documento los textos que tienen el prefijo suministrado.
PrefixQuery pq = new PrefixQuery(prefijo).campo("resumen");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, pq).fields("summary"));
log.info("****** total aciertos :="+ resultadoPrefijo.aciertos().tamaño());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "+ bucket.get(hit.id()).contenido().get("resumen"));
}
Si invoca el código como findByPrefix("micro");
Obtendrá el siguiente resultado:
****** total aciertos := 1
****** puntuación := 0.08200986407165835 y contenido := Servicios web de Aamazon reInvent 2017 promete un recinto más grande, más sesiones y un enfoque en tecnologías como microservicios y Lambda.
Consulta por frases
El código siguiente permite consultar una frase en un texto.
MatchPhraseQuery mpq = new MatchPhraseQuery(matchPhrase).field("altavoces.hablar");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mpq).fields("altavoces.hablar"));
log.info("****** total aciertos :="+ resultadoPrefijo.aciertos().tamaño());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** puntuación := " + hit.puntuación() + " y contenido := "+ bucket.get(hit.id()).contenido().get("título") + " oradores = "+bucket.get(hit.id()).contenido().get("oradores"));
}
Aquí, la consulta busca una frase en el campo "speakers.talk" y devuelve la coincidencia si la encuentra.
Un ejemplo de invocación del código anterior con
findByMatchPhrase("Docker with couchbase") da el siguiente resultado esperado:
****** total aciertos := 1
****** score := 0.25054427342401087 and content := DockerCon speakers = [{"duration": "2″, "date": "04/18/2017″, "talk":"Docker con couchbase", "name": "Arun Gupta"},{"duration": "2″, "date": "04/19/2017″, "talk": "Opensource", "name": "Laura Frank"}]
Consulta de rangos
La búsqueda de texto completo también es muy útil cuando se trata de realizar búsquedas por rangos, ya sean numéricos o de fechas. Por ejemplo, si desea averiguar las conferencias cuyo número de asistentes se encuentra dentro de un intervalo, puede hacerlo fácilmente,
findByNumberRange(5000, 30000);
Aquí, el primer argumento es el mínimo del rango y el segundo argumento es el máximo del rango.
Este es el código que se activa:
NumericRangeQuery nrq = new NumericRangeQuery().min(min).max(max).field("attendees");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, nrq).fields("title", "attendees", "location"));
log.info("****** total aciertos :="+ resultadoPrefijo.aciertos().tamaño());
for (SearchQueryRow hit : resultPrefix.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuación := " + hit.puntuación() + " y título := "+ fila.contenido().get("título") + " asistentes := "+ fila.contenido().get("asistentes") + " ubicación := " + fila.contenido().get("ubicación"));
}
El resultado es el siguiente: se devuelven las conferencias en las que los asistentes se encuentran dentro del intervalo indicado.
****** total aciertos := 2
****** puntuación := 5,513997563179222E-5 y título := Asistentes a la DockerCon := 20000 ubicación := Austin
****** puntuación := 5,513997563179222E-5 y título := Asistentes a Devoxx UK := 10000 ubicación := Bélgica
Consulta combinada
El servicio de búsqueda de texto completo de Couchbase te permite utilizar una combinación de consultas según tus necesidades. Para demostrarlo, invoquemos primero la API proporcionando dos argumentos.
findByMatchCombination("aws", "containers");
Aquí, el código del cliente está intentando utilizar la búsqueda combinada basada en "aws" y "containers". Veamos ahora la API de consulta.
MatchQuery mq1 = new MatchQuery(text1).field("topics");
MatchQuery mq2 = new MatchQuery(text2).field("topics");
SearchQueryResult match1Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq1).fields("title", "attendees", "location", "topics"));
log.info("****** total de aciertos para match1 :="+ match1Result.hits().size());
for (SearchQueryRow hit : match1Result.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuaciones de la partida 1 := " + hit.score() + " y título := "+ row.content().get("title") + " asistentes := "+ row.content().get("attendees") + " temas := " + row.content().get("topics"));
}
SearchQueryResult match2Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq2).fields("title", "attendees", "location", "topics"));
log.info("****** total de aciertos para match2 :="+ match2Result.hits().size());
for (SearchQueryRow hit : match2Result.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuaciones para el partido 2:= " + hit.score() + " y título := "+ row.content().get("title") + " asistentes := "+ row.content().get("attendees") + " temas := " + row.content().get("topics"));
}
ConjunctionQuery conjunción = new ConjunctionQuery(mq1, mq2);
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, conjunction).fields("title", "attendees", "location", "topics"));
log.info("****** total de aciertos para la consulta conjunta := "+ result.hits().size());
for (SearchQueryRow hit : result.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuaciones para la consulta conjunta:= " + hit.score() + " y título := "+ row.content().get("title") + " asistentes := "+ row.content().get("attendees") + " temas := " + row.content().get("topics"));
}
DisjunctionQuery dis = new DisjunctionQuery(mq1, mq2);
SearchQueryResult resultDis = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, dis).fields("title", "attendees", "location", "topics"));
log.info("****** total de aciertos para la consulta de disyunción :="+ resultDis.hits().size());
for (SearchQueryRow hit : resultDis.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuaciones para la consulta disyunción:= " + hit.score() + " y título := "+ fila.contenido().get("título") + " asistentes := "+ fila.contenido().get("asistentes") + " temas := " + fila.contenido().get("temas"));
}
BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2);
SearchQueryResult resultBool = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, bool).fields("title", "attendees", "location", "topics"));
log.info("****** total de aciertos para la consulta booelan :="+ resultBool.hits().size());
for (SearchQueryRow hit : resultBool.hits()) {
JsonDocument fila = bucket.get(hit.id());
log.info("****** puntuaciones para resultBool query:= " + hit.score() + " y title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
En primer lugar, se buscan coincidencias individuales a partir de los textos. Encontramos el/los documento/s resultante/s que coinciden con "aws" como uno de los temas de la conferencia. Del mismo modo, encontramos los documentos que tienen "contenedores" como temas.
A continuación, empezamos a combinar los resultados individuales para formar consultas combinadas.
Consulta de conjunción
La consulta de conjunción devolvería todas las conferencias coincidentes cuyos temas fueran "aws" y "containers". Nuestro conjunto de datos actual aún no contiene ninguna conferencia de este tipo, por lo que, como era de esperar, al ejecutar la consulta no obtenemos ningún documento coincidente.
****** total de aciertos para match1 := 1 - esto coincide con "aws"
****** puntuaciones para coincidencia 1 := 0.11597946228887497 y título := ReInvent asistentes := 30000 temas := ["aws", "serverless", "microservicios", "cloud computing", "realidad aumentada"].
****** total de aciertos para match2 := 1 - esto coincide con "contenedores"
****** puntuaciones para coincidencia 2:= 0.12527214351929328 y título := DockerCon asistentes := 20000 temas := ["contenedores", "devops", "microservicios", "desarrollo de productos", "virtualización"].
****** total de aciertos para la consulta conjunta := 0
Consulta de disyunción
La consulta disyuntiva devolvería todas las conferencias coincidentes si alguna de las consultas candidatas devuelve una coincidencia. Dado que cada una de las consultas de coincidencia individuales devuelve una conferencia cada una, cuando ejecutamos nuestra consulta de disyunción, obtenemos ambos resultados.
****** total de aciertos para la consulta disyunción := 2
****** puntuaciones para la disyunción query:= 0.018374455634478874 y title := DockerCon attendees := 20000 topics := ["contenedores", "devops", "microservicios", "desarrollo de productos", "virtualización"]
****** puntuaciones para la disyunción query:= 0.01701143945069833 y title := ReInvent asistentes := 30000 topics := ["aws", "sin servidor", "microservicios", "computación en la nube", "realidad aumentada"].
Consulta booleana
Mediante la consulta bBoolean, podemos combinar diferentes combinaciones de consultas de coincidencia. Por ejemplo, BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2) devuelve todas las conferencias que deben coincidir con el resultado de la consulta del primer término, que es mq1, y al mismo tiempo no deben coincidir con mq2. Puede dar la vuelta a la combinación.
El resultado de nuestro código es el siguiente:
****** total de aciertos para la consulta booelan := 1
****** puntuaciones para resultBool query:= 0.11597946228887497 y title := ReInvent asistentes := 30000 temas := ["aws", "sin servidor", "microservicios", "computación en la nube", "realidad aumentada"].
Devuelve la conferencia que tiene un tema llamado "aws" (que, por cierto, es el mismo que mq1) y no tiene un tema llamado "containers" (es decir, mq2). La única conferencia que cumple estas dos condiciones se llama "ReInvent" y se devuelve como resultado.
Espero que te haya resultado útil. El código fuente se encuentra en en línea. Para obtener una idea general sobre el servicio de búsqueda de texto completo Couchbase, consulte lo siguiente entrada del blog para obtener información útil: