![]()
Con la publicación de Servidor Couchbase versión 6.0 BetaCouchbase Analytics Service (CBAS) da oficialmente un paso más hacia la disponibilidad general.
Usamos una versión previa para la demostración técnica de Couchbase Connect Silicon Valley. En este artículo entraremos en detalles, como el código y las consultas utilizadas.
Puede ver un vídeo de la demostración (remitido a la parte de análisis) aquí.
¿Qué es CBAS y cómo se compara con Couchbase "estándar"?
Mientras que con una base de datos operativa se suelen realizar consultas optimizadas y predefinidas con índices de apoyo, CBAS está diseñada para ejecutar de forma eficiente consultas complejas, a menudo ad hoc, sobre grandes conjuntos de datos. Al añadir CBAS como servicio independiente y escalableEl Plataforma de datos Couchbase puede realizar una gran cantidad de análisis sin afectar al rendimiento operativo.
Para una introducción en profundidad al servicio Couchbase Analytics, haga clic en este enlace enlace.
Ejemplo de datos y configuración
Hemos creado más de 100 millones de documentos de datos médicos sintetizados basados en la FHIR para su uso en la demostración. Por supuesto, las implantaciones reales suelen alcanzar los terabytes de datos. El tamaño de este conjunto nos obligó a enfrentarnos a problemas realistas de optimización.
Configurar CBAS para esta aplicación es bastante sencillo. Encontrará instrucciones completas para configurar la demostración en esta entrada del blog y este vídeo. Hay un conjunto de datos más pequeño en la página Repo de GitHub para el proyecto.
Para la parte analítica en concreto, sólo tenemos que crear un bucket y designar algunos conjuntos de datos en la sombra. La interoperabilidad se inicia con el último comando "CONNECT". Todo ello se ejecuta en el motor de consultas analíticas. (Tenga en cuenta que diferente de N1QL. Si utiliza la consola de administración, debe ejecutarlos en la sección de análisis).
(Importante: Estos comandos funcionan a partir de Couchbase 6.0.0 Beta. Para actualizaciones e información sobre cambios de última hora en otras versiones, consulte Cambios en el servicio Couchbase Analytics.)
|
1 2 3 4 |
CREAR DATASET paciente EN salud DONDE resourceType = "Paciente" CREAR DATASET condición EN salud DONDE resourceType = "Condición" CREAR DATASET encuentro EN salud DONDE resourceType = "Encuentro" CONECTAR ENLACE Local |
Observe que no hay ETL implicados. Por supuesto, otras preocupaciones empresariales podrían requerir acondicionar los datos de alguna manera, pero disponer de una plataforma integrada puede ahorrar muchos quebraderos de cabeza en cuanto a herramientas.
Código y consultas
Cliente web
El código de la interfaz de usuario está en web/client/src/components/views/Analytics.vue. Tiene algunos selectores para parametrizar las consultas, y algunos componentes de visualización para los resultados.
Visualizamos los datos de dos maneras. Una utiliza un gráfico de líneas para mostrar los valores agregados. (Utilizamos Gráfico.js para ello). El gráfico es interactivo. Al hacer clic en un punto agregado aparece una tabla con detalles. No vamos a entrar en más detalles aquí. La mayor parte del trabajo se realiza en el servidor. La información se prepara allí de forma que el cliente pueda consumirla fácilmente.
Servidor web y consultas
Los datos se recuperan a través de puntos finales REST escritos en Node.js. Al igual que con los otros puntos finales REST, el código del lado del servidor de Node envuelve principalmente consultas a la base de datos.
Hemos optado por organizarlo a través de cuatro puntos finales: analyticsByAge, analyticsByAgeDetails, analíticaSocialy analyticsSocialDetails.
El código para una agrupación (edad, medios sociales) es similar. Echemos un vistazo a analyticsByAge. El código está en web/servidor/controllers/searchController.js.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
var express = requiere(exprés); var randomHexColor = requiere(random-hex-color); var enrutador = express.Router(); // Basado en colores Couchbase (TM) const paleta = [ #E72731, #0074e0, '#f0ce0f', '#b26cda', '#00b6bd', '#00a1db', #eb242a, '#fd9d0d' ]; const searchKeyAllGenders = Todos los géneros; const searchKeyAllCities = Todas las ciudades; ... exportaciones.analyticsByAge = async función(consulte, res, siguiente) { deje couchbase = consulte.aplicación.locales.couchbase; deje grupo = consulte.aplicación.locales.grupo; deje CbasQuery = couchbase.CbasQuery; deje consulta = `SELECCIONE año_mes, grupo_de_edad, cuente(p.id) como recuento_pacientes DESDE condición c, paciente p DONDE subcadena_después(c.tema.referencia, "uuid:") /*+ indexnl */ = meta(p).id Y c.código.texto = '${req.query.diagnosis}' Y fecha(c.assertedDate) > fecha('2007-10-01') `; si (!searchAllGenders(consulte.consulta.género)) { consulta += `Y p.género = ${req.query.gender.toLowerCase()}' `; } si (!buscarTodasLasCiudades(consulte.consulta.ciudad)) { consulta += `Y p.dirección[0].ciudad = ${req.query.city}' `; } consulta += `GRUPO POR subcadena(c.assertedDate, 0, 7) como año_mes, to_bigint((obtener_año(fecha_actual()) - obtener_año(fecha(p.fechaNacimiento))) / 30) como grupo_de_edad PEDIR POR año_mes` consulta = CbasQuery.fromString(consulta); grupo.consulta(consulta, (error, resultado) => { si (error) { devolver res.estado(500).enviar({ código: error.código, mensaje: error.mensaje }); } deje grupos = [0, 1, 2, 3]; deje Estadísticas = {}; deje conjuntos de datos = []; deje etiquetas = []; grupos.paraCada(grupo => Estadísticas[grupo] = {}); para (const registro de resultado) { si (!Estadísticas[registro.grupo_de_edad]) Estadísticas[registro.grupo_de_edad] = {}; si (!etiquetas.incluye(registro.año_mes)) { etiquetas.pulse(registro.año_mes); grupos.paraCada(grupo => Estadísticas[grupo][registro.año_mes] = 0); } Estadísticas[registro.grupo_de_edad][registro.año_mes] += registro.recuento_pacientes; } deje cuchillo = 0; para (const clave en Estadísticas) { si (Estadísticas.hasOwnProperty(clave)) { var entradas = []; para (deje nn = 0; nn < etiquetas.longitud; ++nn) { entradas.pulse(Estadísticas[clave][etiquetas[nn]]); } conjuntos de datos.pulse({ datos: entradas, etiqueta: `${30*clave} - ${30*clave + 29}`, rellenar: falso, backgroundColor: rgba(0, 0, 0, 0)', borderColor: paleta[cuchillo], pointBackgroundColor: paleta[cuchillo] }); } cuchillo = (cuchillo + 1) % paleta.longitud; } res.enviar({ etiquetas: etiquetas, conjuntos de datos: conjuntos de datos }); }); } |
El código de configuración Express (en app.js) se encarga de conectar con el cluster. Pasa dos objetos de control globalmente compartibles, el couchbaseque proporciona algunas interfaces generales, y el objeto grupoque es específico de un único clúster.
A partir de ahí, la lista anterior se divide en dos bloques: la generación de la consulta y la gestión de los resultados.
Consultas con SQL
CBAS utiliza SQL. Desarrollado en colaboración con UC San Diego, UC Irvine y Couchbase, SQL++ es un lenguaje de consulta avanzado diseñado para el formato JSON, pero compatible con SQL.
La consulta se realiza a partir de dos tipos de documentos: Enfermedades y Pacientes. Lo que queremos representar gráficamente es el número de pacientes con una enfermedad, ordenados por mes y año de inicio de la enfermedad y por edad. Al examinar la consulta, vemos que estamos obteniendo exactamente eso del tipo de documento SELECCIONE cláusula.
En DESDE puede parecer un poco sorprendente. Si echas un vistazo a la configuración, verás que hemos configurado dos conjuntos de datos, condición y paciente. Se trata simplemente de buckets analíticos que comprenden los tipos de documentos correspondientes.
A continuación tenemos una serie de selectores que son el verdadero corazón de la consulta. La primera condición substring_after(c.subject.reference, "uuid:") /*+ indexnl */ = meta(p).id es especialmente interesante. Esto limita los resultados a sólo aquellos documentos en los que el sujeto (es decir, el paciente) del registro de condición coincide con el id de paciente del documento de paciente. En otras palabras, está realizando un inner join.
En CBAS, las uniones internas utilizan por defecto un algoritmo hash. La secuencia corta que parece un comentario (/*+ indexnl */) es en realidad una sugerencia al compilador de consultas para que intente realizar una unión de bucles anidados con índice. Esto puede ser más eficiente que un hash, pero requiere un índice. En este caso, el índice viene gratis en forma de claves de documento (id de documento) de los registros de pacientes.
El resto de la consulta hace cosas como filtrar por condición, limitar los datos a un intervalo de 10 años, agrupar y ordenar la salida y dividirla en trozos de 30 años por edad del paciente. Sólo se desvía del SQL normal en otro punto. Un paciente puede tener más de una dirección.
Queremos filtrar por ciudad, si el usuario lo desea. Podemos hacerlo directamente, aunque las direcciones de los pacientes se guarden en un array. En este caso, con el fragmento AND p.address[0].city = '${req.query.city}'puedes ver que hemos elegido la primera dirección. Otros operadores le ofrecen formas más sofisticadas de manejar esto. Por ejemplo, puedes generar resultados separados para cada entrada del array.
Optimización de consultas
Optimizar las consultas puede ser fundamental para el éxito de una aplicación. Con esto en mente, quiero profundizar un poco más en el join. La consola de administración de Couchbase puede mostrar un plan de consulta, esencialmente un desglose de las operaciones que el planificador de consultas traza.
No vamos a repasar un plan entero. En lugar de eso, echemos un vistazo a la diferencia que marca la sugerencia. He aquí una comparación de la misma consulta, con y sin la sugerencia.
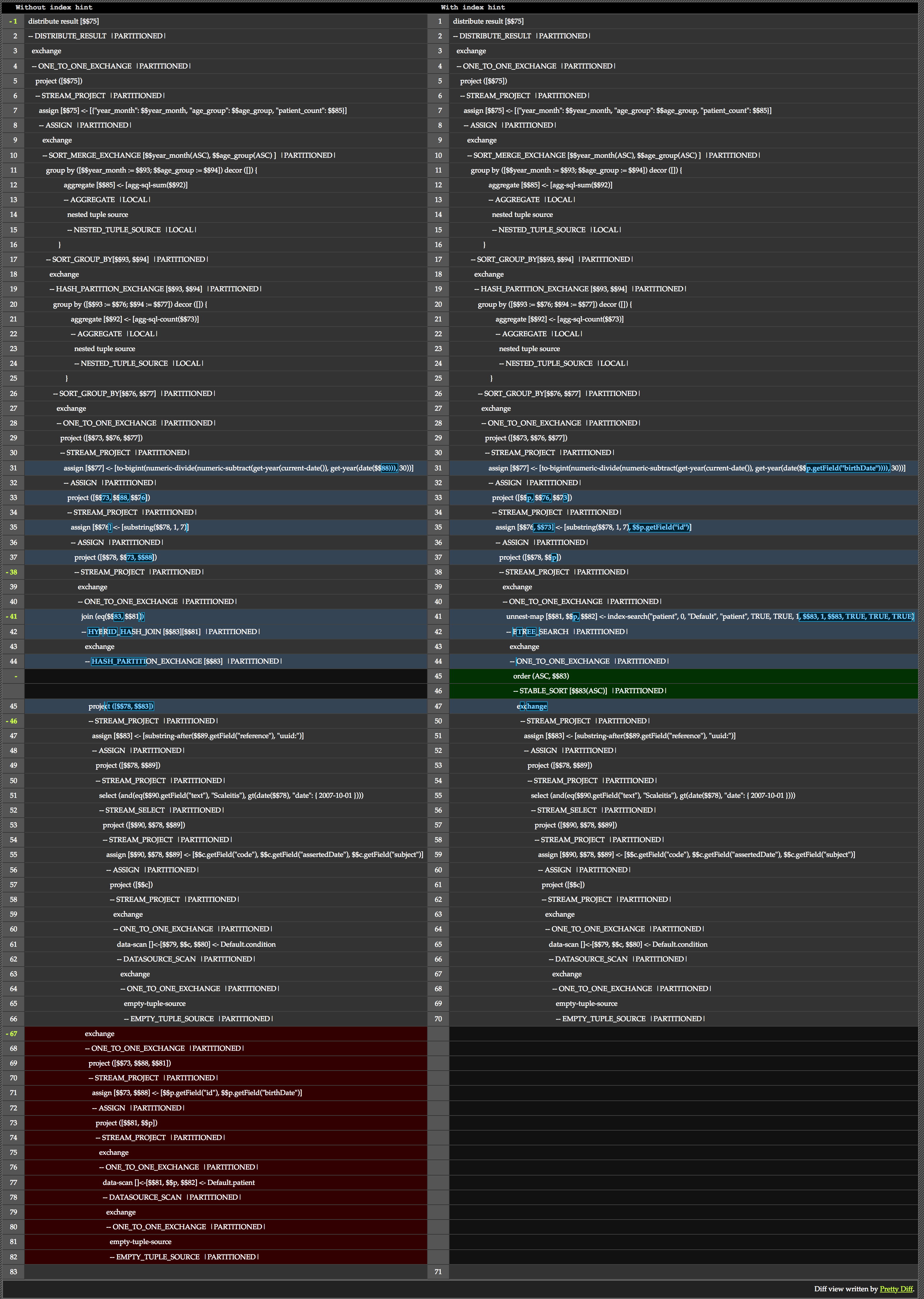
Podemos ver el núcleo de la diferencia que hace la pista en las líneas 41-45. Como prometí, podemos ver que la versión sin la pista utiliza hashing, mientras que la que tiene la pista puede utilizar una búsqueda en el árbol B.
Además, en la parte inferior de la comparación vemos que la versión sin pistas realizó exploraciones y proyecciones de datos adicionales para obtener la información necesaria.
Quiero mencionar otro dato que me ayuda a leer estos planes. Al hojearlos, se ven muchas secciones que hacen referencia a un intercambiar operación. En términos generales, las operaciones de intercambio indican dónde se particionan los datos y se procesan en paralelo. Puede leer más sobre ellas en esta entrada del blog. Para una comprensión aún más completa, lea la sección D, parte 2 sobre conectores en la Biblioteca Hyracks aquí.
Resultados de la consulta y respuesta REST
Una vez que tenemos la consulta SQL++ completa en forma de cadena, utilizamos el subobjeto CbasQuery del objeto couchbase para convertirla en una consulta que podamos entregar al clúster.
El código que sigue manipula los resultados en la forma utilizada por Chart.js. El código puede parecer un poco enrevesado. Esto se debe a que sólo queremos representar los meses en los que al menos un paciente tiene un diagnóstico. También tenemos que tener en cuenta los conjuntos de resultados en los que el mismo mes puede tener pacientes de diferentes grupos de edad. He aquí una pequeña muestra del aspecto de los datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ ... { "año_mes": "2008-12", "grupo_de_edad": 2, "recuento_pacientes": 1 }, { "año_mes": "2009-02", "grupo_de_edad": 0, "recuento_pacientes": 1 }, { "año_mes": "2009-02", "grupo_de_edad": 1, "recuento_pacientes": 3 }, ... ] |
Como puede verse, en febrero de 2009 no hubo incidentes, mientras que en enero hubo pacientes de dos franjas de edad diferentes.
Volviendo al código, vemos que el primer bucle crea dos estructuras de datos.
En etiquetas dará el texto a lo largo del eje x de nuestro gráfico con el año y el mes del inicio de la condición. El código sólo añade entradas para las fechas incluidas en el conjunto de resultados. Es posible que no incluya todos los meses del intervalo abarcado. (En esencia, estamos eliminando del gráfico los meses en los que ningún paciente contrajo una afección).
En Estadísticas es una matriz bidimensional que suma el número de pacientes de cada grupo de edad y año/mes de inicio. Estos serán los datos reales representados.
Una vez que tenemos los datos en esta forma, el segundo bucle itera sobre las estadísticas y crea la estructura que Chart.js espera.
Conclusión
El resto del código y las consultas de Analytics son muy similares a las partes que hemos examinado. Para más información y ejemplos, eche un vistazo al manual de Analytics aquí. Utiliza datos de ejemplo distribuidos con cada versión de Couchbase.
Para saber más sobre esta aplicación de ejemplo, vea el vídeo de la keynote aquíjunto con estos otros puestos.
Posdata
Couchbase es de código abierto y probar gratis.
Empezar con código de ejemplo, consultas de ejemplo, tutoriales y mucho más.
Más recursos en nuestra portal para desarrolladores.
Síguenos en Twitter @CouchbaseDev.
Puede enviar preguntas a nuestro foros.
Participamos activamente en Stack Overflow.
Envíame tus preguntas, comentarios, temas que te gustaría ver, etc. a Twitter. @HodGreeley