![]()
이전 프리뷰 릴리스에서는 Couchbase Connect 실리콘 밸리 기술 데모에 사용되었습니다. 이 게시물에서는 사용된 코드와 쿼리를 살펴보는 등 자세한 내용을 살펴볼 것입니다.
여기에서 데모 동영상(분석 부분으로 전달됨)을 볼 수 있습니다.
CBAS란 무엇이며 "표준" 카우치베이스와 어떻게 다른가요?
운영 데이터베이스에서는 일반적으로 지원 인덱스를 사용하여 최적화된 사전 정의된 쿼리를 수행하는 반면, CBAS는 대규모 데이터 세트에 대해 복잡하고 종종 임시 쿼리를 효율적으로 실행하도록 설계되었습니다. CBAS를 독립적으로 확장 가능한 별도의 서비스에서 카우치베이스 데이터 플랫폼 는 운영 처리량에 영향을 주지 않으면서도 과중한 분석 작업을 처리할 수 있습니다.
카우치베이스 애널리틱스 서비스에 대한 자세한 소개를 보려면 여기를 클릭하세요. 링크.
데이터 및 구성 예시
당사는 다음을 기반으로 1억 개 이상의 합성 의료 데이터 문서를 생성했습니다. FHIR 표준을 데모에 사용했습니다. 물론 실제 배포는 테라바이트급 데이터에 이르는 경우가 많습니다. 이 세트의 크기는 최적화와 관련하여 여전히 현실적인 문제에 직면해야 한다는 것을 의미했습니다.
이 애플리케이션에 대한 CBAS 구성은 매우 간단합니다. 데모 설정에 대한 전체 지침은 다음에서 확인할 수 있습니다. 이 블로그 게시물 그리고 이 비디오. 더 작은 데이터 세트는 GitHub 리포지토리 프로젝트의 경우
특히 분석 부분의 경우, 버킷을 만들고 몇 개의 섀도 데이터 세트를 지정하기만 하면 됩니다. 상호 운용은 마지막 "CONNECT" 명령으로 시작됩니다. 이 명령은 모두 분석 쿼리 엔진에서 실행됩니다. (이 명령은 다른 를 실행합니다. 관리자 콘솔을 사용하는 경우 분석 섹션에서 실행해야 합니다.)
(중요: 이러한 명령은 Couchbase 6.0.0 베타 버전부터 작동합니다. 다른 버전의 업데이트 및 변경 사항에 대한 자세한 내용은 다음을 참조하세요. 카우치베이스 애널리틱스 서비스 변경 사항.)
|
1 2 3 4 |
CREATE DATASET patient ON health WHERE resourceType = "Patient" CREATE DATASET condition ON health WHERE resourceType = "Condition" CREATE DATASET encounter ON health WHERE resourceType = "Encounter" CONNECT LINK Local |
주목할 점은 ETL 관련. 물론 다른 비즈니스 문제도 어떤 식으로든 데이터를 조정해야 할 수 있지만, 통합 플랫폼이 있으면 툴링에 대한 고민을 크게 줄일 수 있습니다.
코드 및 쿼리
웹 클라이언트
프론트엔드 UI 코드는 웹/클라이언트/src/컴포넌트/views/Analytics.vue. 여기에는 쿼리를 매개변수화하는 몇 가지 선택기와 결과에 대한 몇 가지 시각화 구성 요소가 있습니다.
데이터를 시각화하는 방법은 두 가지입니다. 하나는 선 그래프를 사용하여 집계 값을 표시하는 것입니다. (우리는 Chart.js 를 클릭하세요.) 그래프는 대화형입니다. 집계 지점을 클릭하면 세부 정보가 포함된 표가 나타납니다. 여기서는 더 자세히 설명하지 않겠습니다. 대부분의 작업은 서버 측에서 이루어집니다. 클라이언트가 쉽게 사용할 수 있는 방식으로 정보가 준비됩니다.
웹 서버 및 쿼리
데이터는 Node.js로 작성된 REST 엔드포인트를 통해 검색됩니다. 다른 REST 엔드포인트와 마찬가지로, Node 서버 측 코드는 대부분 데이터베이스에 대한 쿼리를 래핑합니다.
저희는 네 가지 엔드포인트를 통해 이를 구성하기로 했습니다: 연령별 분석, 분석 연령별 세부 정보, 분석소셜및 분석소셜세부 정보.
그룹화(연령, 소셜 미디어)를 위한 코드도 비슷합니다. 다음을 살펴보겠습니다. 연령별 분석. 코드는 웹/서버/컨트롤러/검색컨트롤러.js.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
var express = require('express'); var randomHexColor = require('random-hex-color'); var router = express.Router(); // Based on Couchbase colors (TM) const palette = [ '#E72731', '#0074e0', '#f0ce0f', '#b26cda', '#00b6bd', '#00a1db', '#eb242a', '#fd9d0d' ]; const searchKeyAllGenders = 'All Genders'; const searchKeyAllCities = 'All Cities'; ... exports.analyticsByAge = async function(req, res, next) { let couchbase = req.app.locals.couchbase; let cluster = req.app.locals.cluster; let CbasQuery = couchbase.CbasQuery; let query = `SELECT year_month, age_group, count(p.id) as patient_count FROM condition c, patient p WHERE substring_after(c.subject.reference, "uuid:") /*+ indexnl */ = meta(p).id AND c.code.text = '${req.query.diagnosis}' AND date(c.assertedDate) > date('2007-10-01') `; if (!searchAllGenders(req.query.gender)) { query += `AND p.gender = '${req.query.gender.toLowerCase()}' `; } if (!searchAllCities(req.query.city)) { query += `AND p.address[0].city = '${req.query.city}' `; } query += `GROUP BY substring(c.assertedDate, 0, 7) as year_month, to_bigint((get_year(current_date()) - get_year(date(p.birthDate))) / 30) as age_group ORDER BY year_month` query = CbasQuery.fromString(query); cluster.query(query, (error, result) => { if (error) { return res.status(500).send({ code: error.code, message: error.message }); } let groups = [0, 1, 2, 3]; let stats = {}; let datasets = []; let labels = []; groups.forEach(group => stats[group] = {}); for (const record of result) { if (!stats[record.age_group]) stats[record.age_group] = {}; if (!labels.includes(record.year_month)) { labels.push(record.year_month); groups.forEach(group => stats[group][record.year_month] = 0); } stats[record.age_group][record.year_month] += record.patient_count; } let knife = 0; for (const key in stats) { if (stats.hasOwnProperty(key)) { var entries = []; for (let nn = 0; nn < labels.length; ++nn) { entries.push(stats[key][labels[nn]]); } datasets.push({ data: entries, label: `${30*key} - ${30*key + 29}`, fill: false, backgroundColor: 'rgba(0, 0, 0, 0)', borderColor: palette[knife], pointBackgroundColor: palette[knife] }); } knife = (knife + 1) % palette.length; } res.send({ labels: labels, datasets: datasets }); }); } |
Express 설정 코드( app.js)는 클러스터에 연결하는 작업을 처리합니다. 이는 전역적으로 공유 가능한 두 개의 제어 객체, 즉 카우치베이스객체와 몇 가지 일반적인 인터페이스를 제공하는 클러스터객체를 단일 클러스터에 한정하여 사용할 수 있습니다.
그 이후에는 위의 목록이 두 개의 블록으로 나뉘어 쿼리를 생성한 다음 결과를 처리합니다.
SQL++로 쿼리하기
CBAS 사용 SQL++. UC 샌디에이고, UC 어바인, Couchbase와 공동으로 개발한 SQL++는 JSON 형식용으로 설계된 고급 쿼리 언어이지만 SQL과 역호환이 가능합니다.
이 쿼리는 조건과 환자라는 두 가지 문서 유형에서 가져옵니다. 그래프로 표시하고 싶은 것은 질환이 시작된 월과 연도별로 나열된 질환 환자 수이며, 연령별로 구분되어 있습니다. 쿼리를 살펴보면, 우리는 바로 그 데이터를 선택 절을 사용합니다.
그리고 FROM 절이 조금 의외로 보일 수 있습니다. 구성을 다시 살펴보면 두 개의 데이터 집합을 설정한 것을 볼 수 있습니다, 조건 그리고 환자. 이는 해당 문서 유형으로 구성된 분석 버킷일 뿐입니다.
그런 다음 쿼리의 실제 핵심인 일련의 선택자가 있습니다. 첫 번째 조건 substring_after(c.subject.reference, "uuid:") /*+ indexnl */ = meta(p).id 는 특히 흥미롭습니다. 이렇게 하면 상태 기록의 주체(즉, 환자)가 환자 문서의 환자 ID와 일치하는 문서로만 결과가 제한됩니다. 즉, 내부 조인을 수행하는 것입니다.
CBAS에서 내부 조인은 기본적으로 해시 알고리즘을 사용합니다. 주석처럼 보이는 짧은 시퀀스(/*+ indexnl */)는 실제로 쿼리 컴파일러가 인덱스 중첩 루프 조인을 수행해야 한다는 힌트입니다. 이것은 해시보다 더 효율적일 수 있지만 인덱스가 필요합니다. 여기서 인덱스는 환자 기록의 문서 키(문서 ID) 형태로 무료로 제공됩니다.
나머지 쿼리는 조건별 필터링, 10년 범위로 데이터 제한, 출력 그룹화 및 순서 지정, 환자 연령별로 30년 단위로 분할 등의 작업을 수행합니다. 이 쿼리는 다른 한 곳에서만 일반 SQL과 다릅니다. 환자는 주소를 두 개 이상 가질 수 있습니다.
사용자가 원하는 경우 도시별로 필터링하고 싶습니다. 환자 주소가 배열로 유지되더라도 직접 필터링할 수 있습니다. 이 경우 스니펫을 사용하여 AND p.address[0].city = '${req.query.city}'에서 첫 번째 주소를 선택하도록 하드코딩한 것을 볼 수 있습니다. 다른 연산자를 사용하면 더 정교한 방식으로 처리할 수 있습니다. 예를 들어 각 배열 항목에 대해 별도의 결과를 생성할 수 있습니다.
쿼리 최적화
쿼리 최적화는 애플리케이션 성공에 매우 중요할 수 있습니다. 이를 염두에 두고 조인에 대해 좀 더 자세히 살펴보고자 합니다. Couchbase 관리 콘솔은 쿼리 계획, 즉 쿼리 플래너가 매핑하는 작업의 세부 사항을 표시할 수 있습니다.
여기서는 전체 요금제를 살펴보지는 않겠습니다. 대신 힌트가 어떤 차이를 만드는지 살펴보겠습니다. 다음은 동일한 쿼리를 힌트가 있는 경우와 없는 경우의 차이를 나란히 비교한 것입니다.
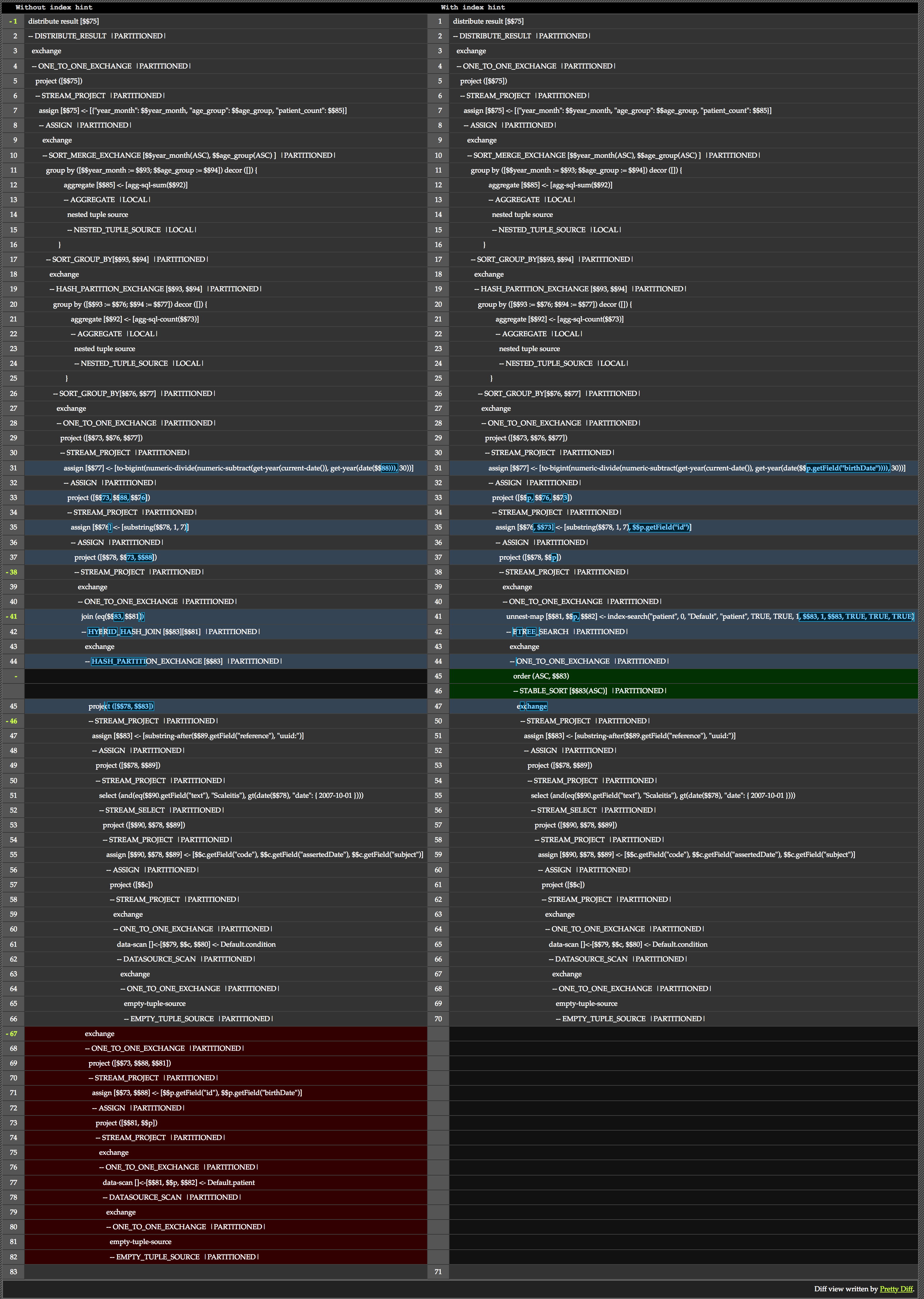
41~45줄에서 힌트가 가져온 차이의 핵심을 확인할 수 있습니다. 약속한 대로 힌트가 없는 버전은 해싱을 사용하는 반면, 힌트가 있는 버전은 B-트리 검색을 사용하는 것을 볼 수 있습니다.
또한 비교의 맨 아래에서 힌트가 없는 버전이 추가 데이터 스캔 및 예측을 실행하여 필요한 정보를 가져온 것을 확인할 수 있습니다.
쿼리 결과 및 REST 응답
완전한 SQL++ 쿼리를 문자열로 얻으면, 카우치베이스 객체의 CbasQuery 하위 객체를 사용하여 이를 클러스터에 전달할 수 있는 쿼리로 변환합니다.
다음 코드는 결과를 Chart.js에서 사용하는 형식으로 조작합니다. 코드가 약간 복잡해 보일 수 있습니다. 이는 적어도 한 명의 환자가 진단을 받은 달만 플롯하고 싶기 때문입니다. 또한 같은 달에 다른 연령대의 환자가 있을 수 있는 결과 집합도 고려해야 합니다. 다음은 데이터가 어떻게 보이는지 보여주는 작은 샘플입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ ... { "year_month": "2008-12", "age_group": 2, "patient_count": 1 }, { "year_month": "2009-02", "age_group": 0, "patient_count": 1 }, { "year_month": "2009-02", "age_group": 1, "patient_count": 3 }, ... ] |
보시다시피 2009년 2월에는 사고가 발생하지 않은 반면 1월에는 두 가지 연령대에 해당하는 환자가 발생했습니다.
코드로 돌아가서 첫 번째 루프가 두 개의 데이터 구조를 생성하는 것을 볼 수 있습니다.
그리고 레이블 배열은 그래프의 X축을 따라 조건이 시작된 연도와 월이 포함된 텍스트를 제공합니다. 이 코드는 결과 집합에 포함된 날짜에 대한 항목만 추가합니다. 범위의 모든 월이 포함되지 않을 수도 있습니다. (본질적으로 그래프에서 질환에 걸린 환자가 없는 달은 제거합니다.)
그리고 통계 변수는 사실상 각 연령대 및 발병 연도/월별 환자 수를 합산하는 2차원 배열입니다. 이것이 플로팅된 실제 데이터가 됩니다.
이 형식의 데이터를 확보하면 두 번째 루프는 통계를 반복하여 Chart.js가 예상하는 구조를 생성합니다.