![]()
Com o lançamento do Servidor Couchbase versão 6.0 BetaNo dia 15 de junho de 2010, o Couchbase Analytics Service (CBAS) deu oficialmente mais um passo em direção à disponibilidade geral.
Usamos uma versão prévia anterior para a demonstração técnica do Couchbase Connect Silicon Valley. Esta postagem se aprofundará nos detalhes, incluindo a análise do código e das consultas usadas.
Você pode ver um vídeo da demonstração (encaminhado para a parte analítica) aqui.
O que é o CBAS e como ele se compara ao Couchbase "padrão"?
Enquanto em um banco de dados operacional você normalmente realiza consultas otimizadas e predefinidas com índices de suporte, o CBAS foi projetado para executar com eficiência consultas complexas, muitas vezes ad hoc, em grandes conjuntos de dados. Ao adicionar o CBAS como um serviço separado e escalável de forma independente, o Plataforma de dados Couchbase pode lidar com trabalhos analíticos pesados sem afetar o rendimento operacional.
Para obter uma introdução detalhada ao Couchbase Analytics Service, clique aqui link.
Exemplo de dados e configuração
Criamos mais de 100 milhões de documentos de dados médicos sintetizados com base na FHIR padrão para uso na demonstração. É claro que as implementações reais geralmente atingem terabytes de dados. O tamanho desse conjunto significava que ainda tínhamos que enfrentar problemas realistas com a otimização.
A configuração do CBAS para esse aplicativo é bastante fácil. Você pode encontrar instruções completas para configurar a demonstração em esta postagem do blog e este vídeo. Há um conjunto de dados menor fornecido na seção Repositório do GitHub para o projeto.
Para a parte analítica especificamente, precisamos apenas criar um bucket e designar alguns conjuntos de dados shadow. A interoperação é iniciada com o comando final "CONNECT". Todos eles são executados no mecanismo de consulta de análise. (Observe que isso é diferente do N1QL. Se estiver usando o console de administração, deverá executá-los na seção de análise).
(Importante: Esses comandos funcionam a partir do Couchbase 6.0.0 Beta. Para obter atualizações e informações sobre mudanças significativas em outras versões, consulte Alterações no Couchbase Analytics Service.)
|
1 2 3 4 |
CREATE DATASET patient ON health WHERE resourceType = "Patient" CREATE DATASET condition ON health WHERE resourceType = "Condition" CREATE DATASET encounter ON health WHERE resourceType = "Encounter" CONNECT LINK Local |
Observe que não há ETL envolvidos. É claro que outras preocupações comerciais podem exigir o condicionamento dos dados de alguma forma, mas ter uma plataforma integrada pode evitar muitas dores de cabeça com ferramentas.
Código e consultas
Cliente Web
O código da interface do usuário front-end está em web/client/src/components/views/Analytics.vue. Ele tem alguns seletores para parametrizar as consultas e alguns componentes de visualização para os resultados.
Visualizamos os dados de duas maneiras. Uma delas usa um gráfico de linhas para mostrar valores agregados. (Usamos Chart.js para isso). O gráfico é interativo. Ao clicar em um ponto agregado, é exibida uma tabela com detalhes. Não entraremos em mais detalhes aqui. A maior parte do trabalho é feita no lado do servidor. As informações são preparadas lá de uma forma que possa ser facilmente consumida pelo cliente.
Servidor Web e consultas
Os dados são recuperados por meio de pontos de extremidade REST escritos em Node.js. Assim como os outros pontos de extremidade REST, o código do lado do servidor do Node envolve principalmente as consultas ao banco de dados.
Optamos por organizar isso por meio de quatro pontos finais: analyticsByAge, analyticsByAgeDetails, analíticaSociale analyticsSocialDetails.
O código para um agrupamento (idade, mídia social) é semelhante. Vamos dar uma olhada em analyticsByAge. O código está em web/server/controladores/searchController.js.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
var express = require('express'); var randomHexColor = require('random-hex-color'); var router = express.Router(); // Based on Couchbase colors (TM) const palette = [ '#E72731', '#0074e0', '#f0ce0f', '#b26cda', '#00b6bd', '#00a1db', '#eb242a', '#fd9d0d' ]; const searchKeyAllGenders = 'All Genders'; const searchKeyAllCities = 'All Cities'; ... exports.analyticsByAge = async function(req, res, next) { let couchbase = req.app.locals.couchbase; let cluster = req.app.locals.cluster; let CbasQuery = couchbase.CbasQuery; let query = `SELECT year_month, age_group, count(p.id) as patient_count FROM condition c, patient p WHERE substring_after(c.subject.reference, "uuid:") /*+ indexnl */ = meta(p).id AND c.code.text = '${req.query.diagnosis}' AND date(c.assertedDate) > date('2007-10-01') `; if (!searchAllGenders(req.query.gender)) { query += `AND p.gender = '${req.query.gender.toLowerCase()}' `; } if (!searchAllCities(req.query.city)) { query += `AND p.address[0].city = '${req.query.city}' `; } query += `GROUP BY substring(c.assertedDate, 0, 7) as year_month, to_bigint((get_year(current_date()) - get_year(date(p.birthDate))) / 30) as age_group ORDER BY year_month` query = CbasQuery.fromString(query); cluster.query(query, (error, result) => { if (error) { return res.status(500).send({ code: error.code, message: error.message }); } let groups = [0, 1, 2, 3]; let stats = {}; let datasets = []; let labels = []; groups.forEach(group => stats[group] = {}); for (const record of result) { if (!stats[record.age_group]) stats[record.age_group] = {}; if (!labels.includes(record.year_month)) { labels.push(record.year_month); groups.forEach(group => stats[group][record.year_month] = 0); } stats[record.age_group][record.year_month] += record.patient_count; } let knife = 0; for (const key in stats) { if (stats.hasOwnProperty(key)) { var entries = []; for (let nn = 0; nn < labels.length; ++nn) { entries.push(stats[key][labels[nn]]); } datasets.push({ data: entries, label: `${30*key} - ${30*key + 29}`, fill: false, backgroundColor: 'rgba(0, 0, 0, 0)', borderColor: palette[knife], pointBackgroundColor: palette[knife] }); } knife = (knife + 1) % palette.length; } res.send({ labels: labels, datasets: datasets }); }); } |
O código de configuração do Express (em app.js) cuida da conexão com o cluster. Ele passa dois objetos de controle globalmente compartilháveis, o couchbaseque fornece algumas interfaces gerais, e o objeto agrupamentoque é específico de um único cluster.
Depois disso, a listagem acima se divide em dois blocos, gerando a consulta e, em seguida, tratando os resultados.
Consultas com SQL++
O CBAS usa SQL++. Desenvolvido em colaboração com a UC San Diego, UC Irvine e Couchbase, o SQL++ é uma linguagem de consulta avançada projetada para o formato JSON, mas é compatível com o SQL.
A consulta extrai de dois tipos de documentos, condições e pacientes. O que queremos representar graficamente é o número de pacientes com uma condição, listados pelo mês e pelo ano em que a condição começou, classificados por idade. Percorrendo a consulta, vemos que estamos obtendo exatamente isso do tipo SELECIONAR cláusula.
O DE pode parecer um pouco surpreendente. Se você olhar para trás na configuração, verá que definimos dois conjuntos de dados, condição e paciente. Esses são apenas compartimentos de análise que incluem os tipos de documentos correspondentes.
Em seguida, temos uma série de seletores que são o verdadeiro coração da consulta. A primeira condição substring_after(c.subject.reference, "uuid:") /*+ indexnl */ = meta(p).id é especialmente interessante. Isso limita os resultados a apenas os documentos em que o assunto (ou seja, o paciente) no registro de condição corresponde ao ID do paciente do documento do paciente. Em outras palavras, ele está realizando uma junção interna.
No CBAS, as junções internas, por padrão, usam um algoritmo de hash. A sequência curta que se parece com um comentário (/*+ indexnl */) é, na verdade, uma dica para o compilador de consultas de que ele deve tentar executar uma junção de loop aninhado com índice. Isso pode ser mais eficiente do que um hash, mas requer um índice. Aqui, o índice vem gratuitamente na forma de chaves de documento (id do documento) dos registros do paciente.
O restante da consulta faz coisas como filtrar por condição, limitar os dados a um intervalo de 10 anos, agrupar e ordenar o resultado e dividi-lo em partes de 30 anos por idade do paciente. Ela só se desvia do SQL regular em um outro ponto. Um paciente pode ter mais de um endereço.
Queremos filtrar por cidade, se o usuário escolher. Podemos fazer isso diretamente, mesmo que os endereços dos pacientes sejam mantidos em uma matriz. Nesse caso, com o snippet AND p.address[0].city = '${req.query.city}'Se você não tiver o endereço de destino, poderá ver que codificamos a escolha do primeiro endereço. Outros operadores oferecem maneiras mais sofisticadas de lidar com isso. Por exemplo, você pode gerar resultados separados para cada entrada do array.
Otimização de consultas
A otimização das consultas pode ser fundamental para o sucesso do aplicativo. Com isso em mente, quero me aprofundar um pouco mais na junção. O console de administração do Couchbase pode exibir um plano de consulta, basicamente um detalhamento das operações que o planejador de consultas mapeia.
Não analisaremos um plano inteiro. Em vez disso, vamos dar uma olhada na diferença que a dica faz. Aqui está uma comparação lado a lado da mesma consulta, com e sem a dica.
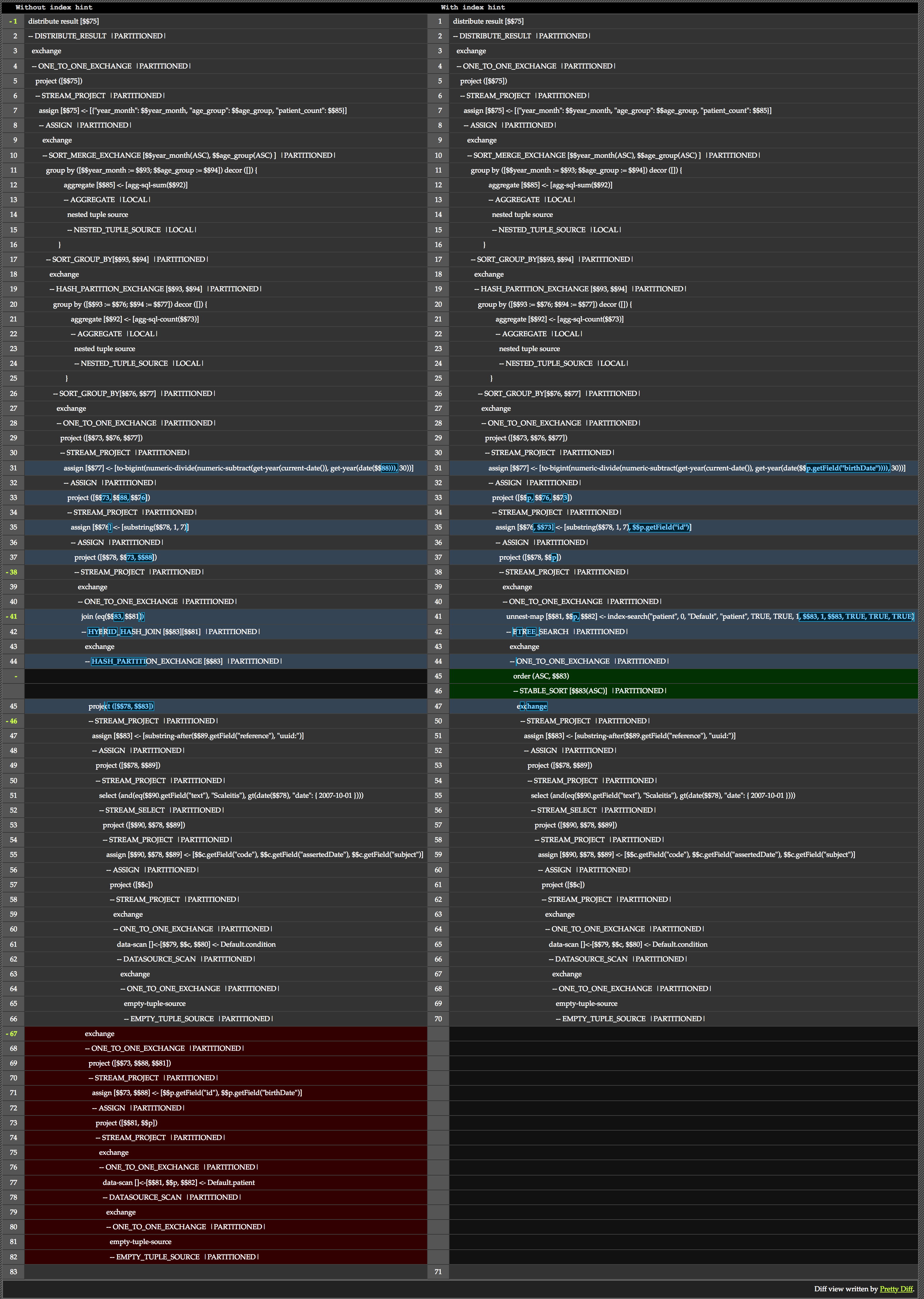
Podemos ver o núcleo da diferença que a dica faz nas linhas 41-45. Como prometido, podemos ver que a versão sem a dica usa hashing, enquanto a versão com a dica pode usar uma pesquisa em árvore B.
Além disso, vemos na parte inferior da comparação que a versão sem dicas executou varreduras e projeções de dados adicionais para obter as informações necessárias.
Gostaria de mencionar outra informação que me ajuda a ler esses planos. Ao ler, você vê muitas seções que se referem a um troca operação. Em termos gerais, as operações de troca indicam onde os dados são particionados e processados em paralelo. Você pode ler mais sobre elas em esta postagem do blog. Para uma compreensão ainda mais completa, leia a seção D, parte 2 sobre conectores na Biblioteca Hyracks aqui.
Resultados da consulta e resposta REST
Quando tivermos a consulta SQL++ completa como uma cadeia de caracteres, usaremos o subobjeto CbasQuery do objeto couchbase para transformá-la em uma consulta que poderemos entregar ao cluster.
O código a seguir manipula os resultados na forma usada pelo Chart.js. O código pode parecer um pouco complicado. Isso se deve ao fato de que queremos plotar apenas os meses em que pelo menos um paciente teve um diagnóstico. Também temos de levar em conta os conjuntos de resultados em que o mesmo mês pode ter pacientes em diferentes faixas etárias. Aqui está uma pequena amostra da aparência dos dados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ ... { "year_month": "2008-12", "age_group": 2, "patient_count": 1 }, { "year_month": "2009-02", "age_group": 0, "patient_count": 1 }, { "year_month": "2009-02", "age_group": 1, "patient_count": 3 }, ... ] |
Como você pode ver, fevereiro de 2009 não teve incidentes, enquanto janeiro teve pacientes que se enquadraram em duas faixas etárias diferentes.
Voltando ao código, vemos que o primeiro loop cria duas estruturas de dados.
O rótulos fornecerá o texto ao longo do eixo x do nosso gráfico com o ano e o mês do início da condição. O código só adiciona entradas para datas incluídas no conjunto de resultados. Isso pode não incluir todos os meses do intervalo abrangido. (Em essência, estamos removendo do gráfico os meses em que nenhum paciente contraiu uma doença).
O estatísticas é efetivamente uma matriz bidimensional que totaliza o número de pacientes para cada faixa etária e ano/mês de início. Esses serão os dados reais plotados.
Quando tivermos os dados nesse formulário, o segundo loop itera sobre as estatísticas e cria a estrutura que o Chart.js espera.
Conclusão
O restante do código e das consultas do Analytics é muito semelhante às partes que examinamos. Para obter mais informações e exemplos, dê uma olhada na cartilha do Analytics aqui. Ele usa dados de amostra distribuídos com todas as versões do Couchbase.
Para saber mais sobre esse aplicativo de amostra, assista ao vídeo da palestra aqui, juntamente com esses outros postagens.
Pós-escrito
O Couchbase é de código aberto e grátis para experimentar.
Comece a usar com código de amostra, consultas de exemplo, tutoriais e muito mais.
Encontre mais recursos em nosso portal do desenvolvedor.
Siga-nos no Twitter @CouchbaseDev.
Você pode postar perguntas em nosso fóruns.
Participamos ativamente de Estouro de pilha.
Entre em contato comigo pelo Twitter com perguntas, comentários, tópicos que você gostaria de ver etc. @HodGreeley