Hoy estamos encantados de anunciar el lanzamiento de las soluciones Couchbase y Unstructured.io que agiliza el proceso de ingesta de datos no estructurados en tu pipeline RAG construido sobre Couchbase como almacén de vectores. Gracias a este conector, ahora puedes convertir documentos no estructurados y poco estructurados en archivos JSON y dejarlos listos para ser consumidos por aplicaciones RAG mediante la generación de incrustaciones vectoriales en tan solo unas líneas de código.
¿Por qué es importante para los desarrolladores la ingestión de datos no estructurados?
Una cantidad abrumadora de datos empresariales no está estructurada y es poco probable que esto cambie en un futuro previsible. La presencia de datos en formatos no estructurados tiene implicaciones para los desarrolladores que van más allá del tiempo y el coste. Significa que la toma de decisiones en las empresas se basa en la cantidad limitada de datos consumibles y estructurados, en lugar de en todos los datos que residen en ella. Además, significa que una gran variedad de flujos de trabajo empresariales (internos y de cara al cliente) requieren intervención manual, lo que los hace más costosos, lentos y propensos a errores. Es probable que este problema se agrave a medida que aumente la huella de datos de las empresas.
¿Cómo aprovechan los desarrolladores los datos no estructurados?
Una de las formas más eficaces de aprovechar los datos no estructurados es introducirlos en una canalización RAG, lo que permite recuperarlos a través de búsquedas vectoriales. Esto tiene amplias aplicaciones en diversos sectores. Las aplicaciones RAG pueden aprovecharse para impulsar la eficiencia operativa facilitando el acceso a documentos más relevantes, lo que se traduce en tiempos de resolución más rápidos y costes más bajos. Algunos de los casos de uso que pueden resolverse son:
-
- Permite a los equipos de atención al cliente de todos los sectores encontrar los documentos pertinentes para la resolución de problemas.
- Permitir a los profesionales de la medicina extraer artículos relevantes y expedientes de pacientes almacenados en bases de datos documentales para ayudar en el diagnóstico y la planificación del tratamiento.
- Sistemas de recomendación que aprovechan los datos del cliente para sugerirle el producto más adecuado.
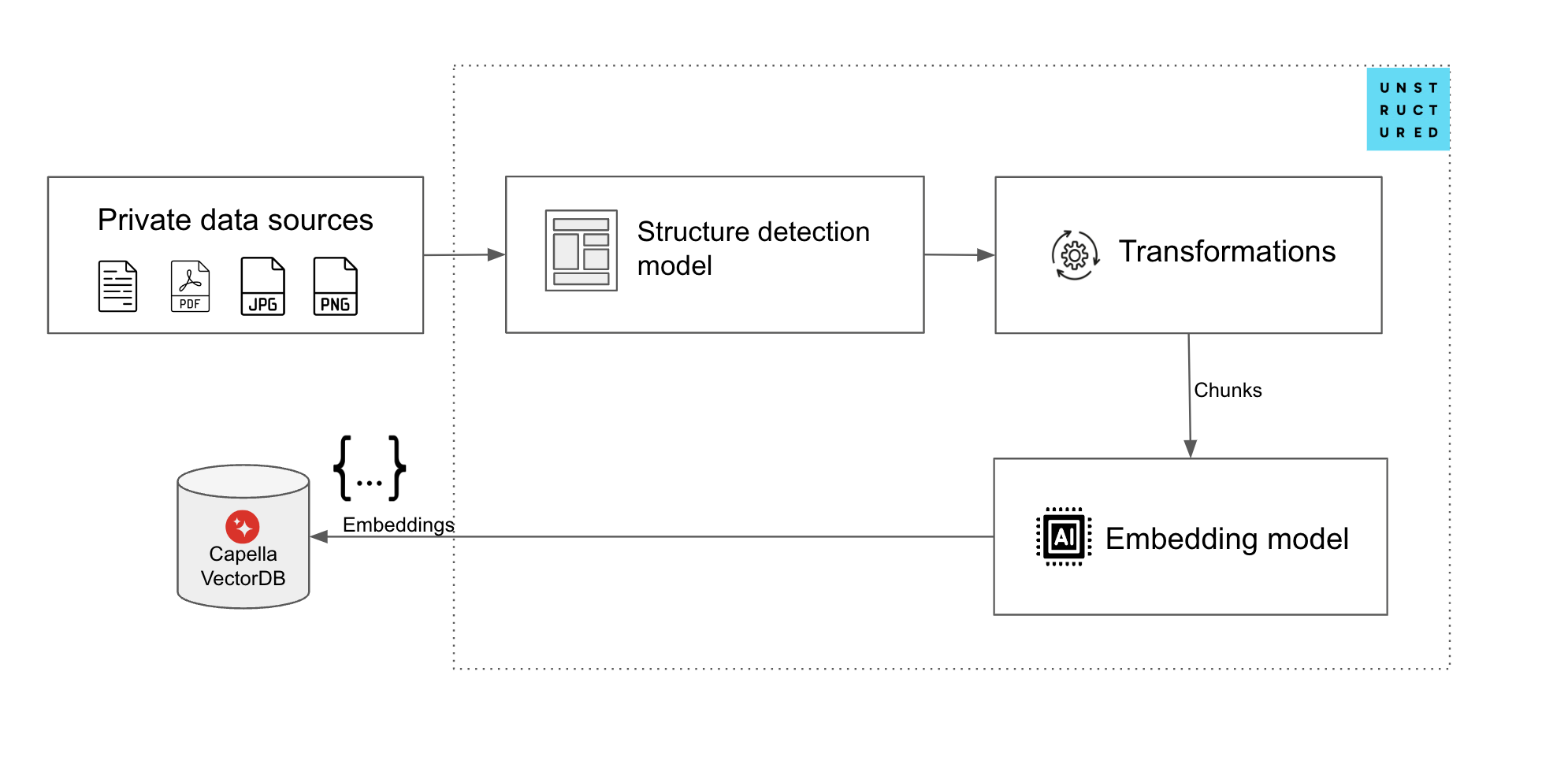
Fig. 1. Canal de ingesta de datos no estructurados con unstructured.io y Capella VectorDB
¿Cómo se procesan actualmente los datos no estructurados?
La forma actual de lograr esto (ingesta de datos no estructurados para aplicaciones RAG) con Couchbase Capella, requeriría que los desarrolladores escribieran aplicaciones para conectarse a un extractor de datos no estructurados, analizar su salida, trocearla, y luego enviarla a un modelo de incrustación para generar vectores que luego tendrían que ser enviados a una DB de vectores en Couchbase Capella.
¿Cómo mejora nuestro conector el método actual de ingesta de datos no estructurados?
Los conectores unstructured.io - Couchbase simplifican el proceso de conexión de los dos elementos primarios antes mencionados de la canalización de la ingesta, facilitando:
-
- Convierta datos de texto no estructurados en documentos JSON estructurados
- Generar los vectores correspondientes
- Insértelos en Couchbase Capella
En conector de origen ayuda a obtener los datos de Couchbase Capella antes de que se agrupen en trozos (y, opcionalmente, se vectoricen), mientras que la función conector de destino ayuda a ingerir datos procesados de unstructured.io en Couchbase Capella.
Capella es una base de datos vectorial de alto rendimiento que le permite configurar, indexar y consultar rápidamente una base de datos vectorial. A continuación te explicamos cómo aprovechar los conectores para empezar a procesar tus documentos con tan solo unas líneas de código.
Paso 1: Requisitos previos
Antes de empezar a utilizar el conector, deberás cumplir una serie de requisitos previos. Necesitará:
-
- En Clave API de unstructured.io que puede obtenerse creando una cuenta en unstructured.io
- Una cuenta Capella activa con un clúster y una base de datos configurados, así como un ámbito y unas colecciones definidos dentro de la base de datos.
- Para configurar el clúster para que utilice su dirección IP
- Para configurar las credenciales de la base de datos
Paso 2: Definir el origen de los datos no estructurados y su destino
Una vez establecidos los requisitos previos, puede definir la fuente de los documentos que desea procesar y utilizar como entradas para su canalización RAG de producción. El conector soporta la ingesta desde varias fuentes: Couchbase, directorios locales, buckets S3 y otros servicios de almacenamiento. Unstructured.io admite una amplia variedad de formatos de documentos no estructurados incluidos PDF, archivos de imagen (JPEG, PNG), documentos de texto (DOCX, DOC), correos electrónicos, hojas de cálculo y formatos de archivo de presentación (PPT).
Del mismo modo, define la ubicación intermedia que se utilizará para almacenar la salida generada por unstructured.io antes de vectorizar el texto. Esto puede ser una colección en una base de datos escalable y de alto rendimiento en Couchbase o cualquier otro servicio de almacenamiento que estés utilizando actualmente. A continuación, puede definir la colección de base de datos de vectores en Couchbase donde se almacenarán los documentos JSON que contienen el texto original, los metadatos y el vector de incrustación correspondiente.
Paso 3: Defina su estrategia de fragmentación y seleccione un modelo de incrustación para la generación de incrustaciones vectoriales.
Una vez definidas las ubicaciones de entrada y salida, puede seleccione una de las estrategias de fragmentación con el apoyo de unstructured.io y elegir un modelo de incrustación de su elección. Unstructured.io admite la incrustación de modelos de varios proveedores, como Huggingface, OpenAI y Bedrock, entre otros.
Paso 4: Ejecute su aplicación
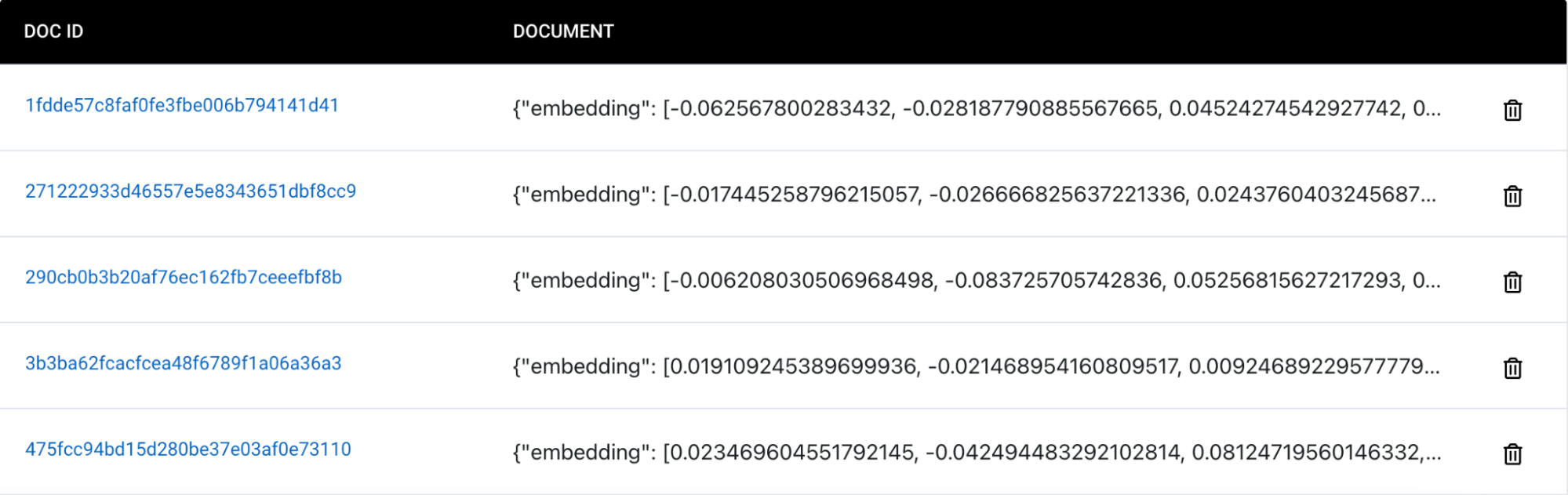
Pruebe su aplicación. Deberías poder ver los nuevos documentos JSON estructurados insertados en tu colección Capella después de todos los pasos de procesamiento ejecutados a través de unstructured.io. A continuación se muestra un ejemplo de los archivos que convertimos de PDF a JSON e ingerimos en una colección Capella de Couchbase. Para una guía paso a paso junto con el código de cómo hacer esto, echa un vistazo a nuestro tutorial completo aquí. También puedes utilizar nuestro cuaderno para seguirnos.
Ejemplo de documento no estructurado:

Salida de unstructured.io:

Documentos introducidos en Capella:
Ahora puede ejecutar su aplicación para procesar documentos de texto no estructurados, identificar los componentes, extraerlos como documentos JSON y generar incrustaciones vectoriales antes de insertarlos en su colección Capella.
Recursos

