"Apps sin búsqueda es como la página de inicio de Google sin la barra de búsqueda".

Es difícil diseñar una aplicación sin una buena búsqueda. Hoy en día, también es difícil encontrar una base de datos sin una búsqueda integrada. De MySQL a NoSQL, de Sybase a Couchbase, todas las bases de datos tienen soporte de búsqueda de texto, incorporado como Couchbase o a través de la integración con Elastic, como es el caso de Cassandra. A diferencia de SQL, la funcionalidad de búsqueda de texto no está estandarizada. Cada aplicación necesita la mejor búsqueda, pero no todas las bases de datos proporcionan la misma funcionalidad de búsqueda de texto. Es importante entender la funcionalidad disponible, el rendimiento de cada implementación de búsqueda de texto y elegir lo que se adapte a la necesidad de su aplicación. Después de motivar la búsqueda de texto, aprenderás sobre las características de búsqueda de texto que necesitarías para una búsqueda efectiva, comparar y contrastar esas características en MongoDB y Couchbase con ejemplos.
Veamos los requisitos de búsqueda a nivel de aplicación.
-
Búsqueda exacta: (WHERE item_id = "ABC482")
-
Búsqueda por rango: (WHERE item_type = "shoes" and size = 6 and price between 49.99 and 99.99)
-
Búsqueda por cadena:
-
(WHERE lower(nombre) LIKE "%joe%")
-
(WHERE lower(name) LIKE "%joe%" AND state = "CA")
-
-
Búsqueda de documentos:
-
Buscar joe en cualquier campo del documento JSON
-
Buscar documentos que coincidan con el número de teléfono (408-956-2444) en cualquier formato (+1 (408) 956-2444, +1 510.956.2444, (408) 956 2444)
-
-
Búsqueda compleja: (WHERE lower(title) LIKE "%dictator%" and lower(actor) LIKE "%chaplin" and year < 1950)
Las búsquedas por rangos en los casos (1) y (2) pueden manejarse con índices B-Tree típicos de forma eficiente. Los datos están bien organizados por los datos completos que se buscan. Cuando se empieza a buscar el fragmento de palabra "joe" o se buscan números de teléfono con varios patrones en un documento más grande, los índices basados en B-Tree se resienten. Simple tokenizaciones y el uso de índices basados en B-Tree puede ayudar en casos sencillos. Necesitas nuevos enfoques para tus casos de búsqueda en el mundo real.
La sección de apéndices de este blog contiene más detalles sobre cómo se organizan los índices de árbol invertido y por qué se utilizan para la búsqueda empresarial en Lucene y Bleve. Bleve potencia la búsqueda de texto completo de Couchbse. MongoDB utiliza índices basados en B-Tree incluso para la búsqueda de texto.
Centrémonos ahora en el soporte de búsqueda de texto en MongoDB y Couchbase.
El conjunto de datos que he utilizado es de https://github.com/jdorfman/awesome-json-datasets#movies
MongoDB: https://docs.mongodb.com/manual/text-search/
Couchbase: https://docs.couchbase.com/server/6.0/fts/full-text-intro.html
Visión general de la búsqueda de texto en MongoDB: Crear y consultar índice de búsqueda de texto en cadenas de documentos MongoDB. El índice parece ser simples índices B-tree con capas adicionales para el analizador incorporado. Esto conlleva muchos problemas de tamaño y rendimiento que discutiremos más adelante. El índice de búsqueda de texto está estrechamente integrado en la infraestructura de la base de datos MongoDB y su API de consulta.
MongoDB proporciona índices de texto para soportar consultas de búsqueda de texto sólo sobre cadenas. Sus índices de texto solo pueden incluir campos cuyo valor sea una cadena o una matriz de elementos de cadena. Una colección sólo puede tener un índice de búsqueda de texto, pero ese índice puede abarcar varios campos.
Visión general de Couchbase FTS (Búsqueda de texto completo): La búsqueda de texto completo ofrece amplias posibilidades de consulta en lenguaje natural. Bleve, implementado como un índice invertido, alimenta el índice de texto completo de Couchbase. El índice se despliega como uno de los servicios y puede desplegarse en cualquiera de los nodos del clúster.
MongoDB |
Couchbase |
|||
Nombre |
Búsqueda de texto - 4.x |
Búsqueda de texto completo (FTS) - 6.x. |
||
Funcionalidad |
Búsqueda de texto simple para indexar campos de cadena y buscar una cadena sólo en uno o más campos de cadena. Utiliza su Índices B-Tree para el índice de búsqueda de texto.Busca en toda la cadena compuesta y no puede separar los campos específicos. |
Búsqueda de texto completo para encontrar cualquier cosa en sus datos. Admite todos los tipos de datos JSON (cadena, numérico, booleano, fecha/hora); la consulta admite expresiones booleanas complejas, expresiones difusas en cualquier tipo de campos. Utiliza la índice invertido para el índice de búsqueda de texto. |
||
Instalación |
Búsqueda de texto: Disponible con la instalación de MongoDB. Sin opción de instalación por separado. |
Disponible con la instalación de Couchbase. Puede instalarse con otros servicios (datos, consulta, índice, etc.) o por separado en distintos nodos de búsqueda. |
||
Creación de índices en un solo campo |
db.films.createIndex({ título: "texto" }); |
curl -u Administrador:contraseña -XPUT https://localhost:8094/api/index/films_title -H 'cache-control: no-cache' -H 'content-type: application/json' -d '{ "name": "films_title", "type": "fulltext-index", "params": { "mapping": { "default_field": "title" } }, "sourceType": "couchbase", "sourceName": "films" }' |
||
Creación de índices en varios campos |
db.films.createIndex({ título: "texto", géneros: "texto"});Antes de crear este índice, tienes que eliminar el índice anterior. Sólo puede haber un índice de texto en una colección. Se necesita su nombre, que se obtiene mediante: db.films.getIndexes() o especificando el nombre al crear el índice.db.films.dropIndex("texto_título"); |
Puede crear múltiples índices en un bucket (o espacio de claves) sin restricciones.curl -u Administrador:contraseña -XPUT https://localhost:8094/api/index/films_title_genres -H 'cache-control: no-cache' -H 'content-type: application/json' -d '{ "name": "films_title_genres", "type": "fulltext-index", "params": { "mapping": { "types": { "genres": { "enabled": true, "dynamic": false }, "title": { "enabled": true, "dynamic": false }}}}, "sourceType": "couchbase", "sourceName": "films" }' |
||
Utilización de pesos |
db.films.createIndex({ título: "texto", géneros: "texto"}, {weights:{título: 25}, name : "txt_título_géneros"}); |
Hecho dinámicamente a través de refuerzo utilizando el ^ mofidier.curl -XPOST -H "Content-Type: application/json" \ https://172.23.120.38:8094/api/index/films_title_genres/query \ -d '{ "explain": true, "fields": [ "*" ], "highlight": {}, "query": { "query": "title:charlie^40 genres:comedy^5" } }' |
||
Opción de idioma |
El idioma por defecto es el inglés. Introduce un parámetro para cambiarlo.db.films.createIndex({ title: "text"}, { default_language: "french" }); |
Los analizadores están disponibles en 24 idiomas. Puede cambiar es mientras se crea el índice cambiando el siguiente parámetro."default_analyzer": "fr", |
||
Índice de texto sin distinción entre mayúsculas y minúsculas |
No distingue entre mayúsculas y minúsculas por defecto. Ampliado a nuevos idiomas. |
No distingue entre mayúsculas y minúsculas por defecto. |
||
insensible a los diacríticos |
Con la versión 3, el índice de texto es insensible a los diacríticos. |
Sí. Se activa automáticamente en el analizador correspondiente (por ejemplo, francés). |
||
Delimitadores |
Guión, guión, sintaxis_patrón, comillas, puntuación_terminal y espacio_en_blanco. |
Cada obra se analiza en función del lenguaje y la especificación del analizador. |
||
Idiomas |
15 idiomas:alemán, danés, español, finés, francés, holandés, húngaro, inglés, italiano, noruego, portugués, rumano, ruso, sueco, turco |
Los filtros de tokens son compatibles con los siguientes idiomas.
Árabe, catalán, chino, japonés, coreano, kurdo, danés, alemán, griego, inglés, español (castellano), vasco, persa, finés, francés, gaélico, español (gallego), hindi, húngaro, armenio, indonesio, italiano, neerlandés, noruego, portugués, rumano, ruso, sueco y turco. |
||
Tipo de índice |
Índice de árbol B simple que contiene una entrada por cada palabra con raíz en cada documento.Los índices de texto pueden ser grandes. Contienen una entrada de índice por cada palabra única pospuesta en cada campo indexado de cada documento insertado. |
Índice invertido. Una entrada por palabra con raíz en TODO el índice (por partición del índice). Por lo tanto, los tamaños de índice son significativamente más pequeños. Cuanto más grande sea el conjunto de datos, el índice FTS de Couchbase es mucho más eficiente comparado con el índice de texto de MongoDB. |
||
Efecto de la creación de índices sobre los INSERTOS. |
Afectará negativamente a la tasa de INSERTOS. |
Las tarifas INSERT/UPSERT no se verán afectadas |
||
Índice Mantenimiento |
Sincrónicamente mantenido. |
Se mantiene de forma asíncrona. Las consultas pueden especificar la caducidad mediante el parámetro de consistencia. |
||
consultas de frase |
Soportado, pero lento.Las búsquedas de frases se ralentizan porque el índice de texto no incluye los metadatos necesarios sobre la proximidad de las palabras en los documentos. En consecuencia, las consultas de frases se ejecutarán de forma mucho más eficaz cuando toda la colección quepa en la memoria RAM. |
Soportado y rápido.
Incluir los vectores de términos durante la creación del índice. |
||
Búsqueda de texto |
db.films.find({$text: {$search: "charlie chaplin"}})Esto encontrar todos los documentos que contienen Charlie o Chaplin. Si contiene tanto charlie como chaplin obtendrá una puntuación más alta. Como sólo puede haber UN índice de texto por colección, esta consulta utiliza ese índice independientemente del campo que indexe. Por lo tanto, es importante decidir cuál de los campos debe estar en el índice. |
|
||
Búsqueda por frase exacta |
db.films.find({$text: {$search: "\"charlie chaplin\""}}) |
|
||
| Exclusión exacta | db.films.find({$text: {$search: "charlie -chaplin"}});
Toda la película con "charlie", pero sin "chaplin". |
|
||
| Orden de resultados. |
Desordenado por defecto.Proyecta y ordena por puntuación cuando lo necesites.db.films.find({$text: {$search: "charlie chaplin"}}, {score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}) |
Ordenado por puntuación (descendente) por defecto. Se puede ordenar por cualquier campo o metadato. Ordenado por título y puntuación (descendente)
|
||
| Búsqueda específica por idioma |
db.articles.find({ $text: { $search: "leche", 1TP4Idioma: "es" } }) |
El analizador lingüístico habrá determinado las características del índice y de la consulta. | ||
| Búsqueda sin distinción entre mayúsculas y minúsculas |
db.film.find( { $text: { $search: "Lawrence", $caseSensitive: true } } )
|
Determinado por el analizador. Utilice el filtro to_lower token para que las búsquedas no distingan entre mayúsculas y minúsculas. Más información en: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html | ||
| Limitación del conjunto de resultados devueltos. |
db.films.find({$text: {$search: "charlie chaplin"}},{score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}).limit(10) |
Soporta los equivalentes de LIMIT y SKIP en SQL utilizando los parámetros "size" y "from" respectivamente.
|
||
| Clasificación compleja |
db.films.find({$text: {$search: "charlie chaplin"}},{score: {$meta: "searchscore"}}).sort({year : 1, $meta: "searchscore"}).limit(10) |
Ordenado por puntuación (descendente) por defecto. Puede ordenar por cualquier campo o metadato. Ordena por título (ascendente), año (descendente) y puntuación (descendente).
|
||
| Consulta compleja |
Utilizar el marco de agregación. La búsqueda $text puede utilizarse en un marco de agregación con algunas restricciones.db.articles.aggregate(
|
Como has visto hasta ahora, la consulta FTS en sí es bastante sofisticada. Además, FTS admite facetas para la agrupación y el recuento sencillos. https://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html
En la próxima versión, N1QL (SQL para JSON) utilizará el índice FTS para los predicados de búsqueda.
|
||
| Índice completo de documentos | No admite la indexación completa de documentos. Todos los campos de cadena tendrán que especificarse en la llamada a createIndex.
db.films.createIndex({ título: "texto", géneros: "texto", reparto: "texto", año: "texto"});
|
Por defecto, permite indexar el documento completo, reconoce automáticamente el tipo de campo y los indexa en consecuencia. | ||
| Tipos de consulta |
Búsqueda básica, debe tener, no debe tener. |
Consultas de coincidencia, frase coincidente, ID de documento y prefijoConsultas de conjunción, disyunción y campos booleanosConsultas de rango numérico y rango de fechasConsultas geoespacialesConsultas de cadenas de consulta, que emplean una sintaxis especial para expresar los detalles de cada consulta (para más información, consulte Consultas de cadenas de consulta) |
||
| Analizadores disponibles | Sólo analizadores integrados. | Analizadores integrados y personalizables. Más información en: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html#character-filters/token-filters |
||
Crear y buscar a través de la interfaz de usuario |
No en el producto base. |
Integrado en la consola |
||
| API REST |
No disponible. |
Disponible.
https://docs.couchbase.com/server/6.0/fts/fts-searching-with-the-rest-api.html https://docs.couchbase.com/server/6.0/rest-api/rest-fts.html |
||
SDK |
La búsqueda de texto está integrada en la mayoría de los SDK de Mongo. Por ejemplo, https://mongodb.github.io/mongo-java-driver/ |
https://docs.couchbase.com/java-sdk/2.7/full-text-searching-with-sdk.html |
||
| Tipos de datos admitidos | Sólo cadenas. No se admite ningún otro tipo de dato. | Todos los tipos de datos JSON y fechas y horas.
String, numeric, boolean, datetime, object y arrays. GEOPOINT para consultas al vecino más próximo. Véase : https://docs.couchbase.com/server/6.0/fts/fts-geospatial-queries.html |
||
| Vectores de término. | No compatible. | Disponibles. Los vectores de términos son muy útiles en la búsqueda de frases. | ||
| Facetado | Sin soporte |
Término FacetFacetas de rango numéricoFaceta de intervalo de fechashttps://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html |
||
| Consultas AND avanzadas (conjuntos) | No compatible. |
curl -u Administrador:contraseña -XPOST -H "Content-Type: application/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{"explicar": true,"fields": [“*”],"highlight": {},"consulta": {"conjuncts":[ {"field": "title", "match": "kid"}, {"field": "cast", "match": "chaplin"}]}}’ |
||
| Consultas OR avanzadas (disyuntos) | No compatible. |
curl -u Administrador:contraseña -XPOST -H "Content-Type: application/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{"explicar": true,"fields": [“*”],"highlight": {},"consulta": {"disjuncts":[ {"field": "title", "match": "kid"}, {"field": "cast", "match": "chaplin"}]}}’ |
||
| Consulta de intervalos de fechas | No compatible.
Necesita postprocesado, lo que podría afectar al rendimiento. |
Compatible con FTS.
{
|
||
| Consultas de rangos numéricos | No compatible. | curl -u Administrador:contraseña -XPOST -H "Content-Type: application/json" https://172.23.120.38:8094/api/index/filmsearch/query -d '{ "explicar": true, "fields": [ “*” ], "highlight": {}, "consulta": { "campo": "año", "min":1999, "max":1999, "inclusive_min": true, "inclusive_max":true } }’ |
Rendimiento:
Aunque aún está pendiente una comparación de rendimiento más detallada, hemos realizado una comparación rápida con 1 millón de documentos de wikipedia. Esto es lo que vimos:
Tamaños de índice.
| Couchbase (6.0) | MongoDB (4.x) | |
| Tamaño de indexación | 1 GB (chamuscado) | 1,6 GB |
| Tiempo de indexación | 46 segundos | 7,5 min |
Rendimiento de las consultas de búsqueda (consultas por segundo):
Couchbase Mongodb
Términos de alta frecuencia 395 79
Med términos de frecuencia 6396 201
Bajo términos de frecuencia 24600 643
Alta o Alta términos 145 82
Alta o Media términos 258 78
Búsqueda de frases 107 50
Resumen:
MongoDB proporciona un índice de búsqueda de cadenas simple y APIs para realizar búsquedas de cadenas. El índice de árbol B que crea para la búsqueda de cadenas también puede ser bastante grande. La búsqueda de texto, no.
El índice de texto de Couchbase se basa en un índice invertido y es un índice de texto completo con un número significativamente mayor de funciones y un mejor rendimiento.
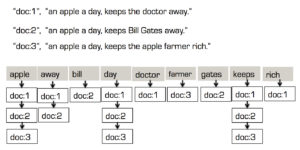
¿Por qué un índice invertido?
Las búsquedas simples, exactas y por rango, pueden realizarse mediante Árbol B como índices para una exploración eficaz. Las búsquedas de texto, sin embargo, exigen un uso más amplio de stemming, stopwords, analizadores, etc. Esto requiere no sólo un planteamiento de indexación diferente, sino también un filtrado previo, herramientas de análisis personalizadas, separaciones de palabras en función del idioma e insensibilidad a las mayúsculas y minúsculas.
El índice de búsqueda puede crearse utilizando el árbol B tradicional. Pero, a diferencia de los índices B-tree sobre valores escalares, el índice de texto tendrá múltiples entradas de índice para cada documento. Un índice de texto sólo en este documento podría tener hasta 12 entradas: 8 para nombres de reparto, una para géneros, dos para el título tras eliminar la palabra de parada (in) y el año. Si el número de documentos es mayor, el tamaño del índice de texto aumentará exponencialmente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "cast": [ "Whoopi Goldberg", "Ted Danson", "Will Smith", "Nia Long" ], "genres": [ "Comedy" ], "title": "Made in America", "year": 1993 } } |
Solución: Aquí viene el árbol invertido. El árbol invertido tiene los datos (término de búsqueda) en la parte superior (raíz) y tiene varias claves de documentos en los que existe el término en la parte inferior, haciendo que la estructura parezca un árbol invertido. Índices de texto populares en Lucene, Bleve se implementan como índices invertidos.