Antecedentes:
¿Cómo lo hace Google? Cuando buscas algo en Google, te devuelve los resultados más relevantes y te indica el número aproximado de documentos sobre tu tema, todo ello en menos de un segundo. He aquí algunas indicaciones de alto nivel: https://www.google.com/search/howsearchworks/algorithms/
Las aplicaciones empresariales tienen la misma necesidad, aunque con criterios de búsqueda, ordenación y paginación más complejos.
Veamos el comportamiento de paginación de Google para entender las características básicas de la paginación. A continuación, hablaremos de la implementación de la paginación en una aplicación empresarial, paso a paso.
Paginación de Google:
Busca "N1QL" en Google.
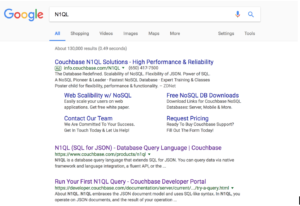
La página que te devuelve, el resultado de la búsqueda tiene la siguiente información.
- Número de páginas cotejadas: 130,000
- La búsqueda se ejecutó en 0,49 segundos
- La página incluye anuncios. En este caso, un anuncio de Couchbase. Naturalmente.
- La primera página de resultset: Enlaces a 12 páginas y algunas líneas de cada página.
- Búsqueda relacionada con "N1QL Algunas sugerencias relacionadas con las búsquedas
- Enlaces a las 10 páginas siguientes de resultados y el enlace a la página SIGUIENTE.
Paginación de la base de datos
Las tareas de la paginación son recuperar y mostrar subconjunto del conjunto de resultados. El subconjunto viene determinado por la especificación de paginación (cuántas filas por página) y el orden de clasificación de la consulta emitida por la aplicación. En paginación de la base de datos, la aplicación intenta explotar las características y optimizaciones que ofrece la gestión de la base de datos.
Veamos cada una de las características de paginación que vimos con Google y exploremos cómo puedes implementar y optimizar las consultas en Couchbase.
En las siguientes secciones, nos centraremos en la paginación de bases de datos utilizando Couchbase.
- Recuento de los resultados totales
- Obtención del tiempo de ejecución de la consulta
- Obtener la primera página
- Creación de enlaces a la página siguiente y a otras páginas
- Obtener la página siguiente o cualquier otra.
No trataremos la selección de anuncios de Google ni las sugerencias de búsquedas relacionadas. Son temas distintos por sí mismos.
Ten en cuenta que este artículo utiliza nuevas funcionalidades como index collation (especificación ASC y DESC para cada clave de índice), offset pushdown y otras optimizaciones en Couchbase 5.0.
Sección 1. Recuento de los resultados totales
Google devolvió lo siguiente:
Unos 130.000 resultados (0,49 segundos)
CUENTA: Número estimado de páginas 130.000
TIEMPO: Cantidad de tiempo que se tardó en hacer la búsqueda. En este caso, 0,49 segundos
En la paginación de bases de datos, ambas pueden ser útiles.
COUNT es útil para determinar el número de enlaces siguientes y anteriores que necesitas generar cuando renderices los resultados en la UI. Es posible que tu consulta de paginación en sí no devuelva el número total de resultados porque el optimizador intentará utilizar los índices y otras técnicas para limitar el número de documentos procesados. Eso impedirá que la consulta conozca el posible número total de documentos del conjunto de resultados.
Si la consulta tiene ORDER BY, puede sortCount en algunos casos. Esto le indica el número total de documentos que ordenamos, aunque sólo devolvamos un documento.
Cuando la consulta explota la ordenación por índices para evitar que la ordenación evalúe una cláusula ORDER BY, el sortCount no está disponible.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY airportname OFFSET 1 LIMIT 1; { "requestID": "709fe2fb-d124-4b0c-b2b4-1c235d3c6f12", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Abilene Rgnl", "city": "Abilene", "country": "United States", "faa": "ABI", "geo": { "alt": 1791, "lat": 32.411319, "lon": -99.681897 }, "icao": "KABI", "id": 3718, "type": "airport", "tz": "America/Chicago" } } ], "status": "success", "metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } } |
Esta consulta aprovecha el índice del campo faa para obtener los datos ordenados y aplicar la cláusula de paginación (OFFSET 50 LIMIT 10) al escaneo del índice. Por lo tanto, sortCount no aparece en el conjunto de resultados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY faa OFFSET 50 LIMIT 10; { "requestID": "5bc38dd1-7285-41a5-80e3-0f1da23df178", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Andrews Afb", "city": "Camp Springs", "country": "United States", "faa": "ADW", "geo": { "alt": 280, "lat": 38.810806, "lon": -76.867028 }, "icao": "KADW", "id": 3552, "type": "airport", "tz": "America/New_York" } }, ... "status": "success", "metrics": { "elapsedTime": "4.167044ms", "executionTime": "4.143152ms", "resultCount": 10, "resultSize": 5033 } } |
En tales casos, puede utilizar un escaneo de índice de cobertura y simplemente obtener el COUNT() de documentos calificados. El método IndexCountScan2 (o IndexCountScan antes de la versión 5.0) simplemente realiza el escaneo del índice y cuenta el número de documentos cualificados y evita toda la transferencia de datos desde el indexador al motor de consultas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
cbq> SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "requestID": "78a3aeae-4dd1-468c-a01c-38610fd87cf4", "signature": { "$1": "number" }, "results": [ { "$1": 1659 } ], "status": "success", "metrics": { "elapsedTime": "2.945555ms", "executionTime": "2.920307ms", "resultCount": 1, "resultSize": 34 } } |
Este es el plan de consulta para obtener COUNT.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cbq> EXPLAIN SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "#operator": "IndexCountScan2", "covers": [ "cover ((`travel-sample`.`faa`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "def_faa", "index_id": "460bd5dad1c6c95d", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "\"4AB\"" } ] } |
Sección 2. Tiempos y otros parámetros
Cada resultado de consulta tiene las métricas básicas sobre la ejecución de la consulta.
|
1 2 3 4 5 6 7 |
"metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } |
tiempo transcurrido es la duración del tiempo de reloj empleado por el servidor tras recibir la consulta. Esto incluye cualquier tiempo de espera. executionTime es estrictamente el tiempo empleado en ejecutar la consulta. resultCount es el número de documentos devueltos. resultSize es el número de bytes del conjunto de resultados. sortCount es el número de documentos ordenados antes de la paginación.
Si la consulta no incluye OFFSET o LIMIT, resultCount es el número total de documentos en el conjunto de resultados. Cuando necesitemos ordenar los datos intermedios, como se ha mencionado antes, sortCount faltará si no se ha realizado ninguna ordenación para evaluar el ORDER BY.
Sección 3. primera página del conjunto de resultados
Centrémonos primero en la primera página.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT * FROM `travel-sample` t WHERE type = “hotel” AND country = “United Kingdom” AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 0 LIMIT 20; CREATE INDEX idx_hotel_ctry_likes ON `travel-sample`(country, ARRAY_LENGTH(public_likes)) WHERE type = “hotel” |
La consulta utilizando este índice se ejecuta en unos 30 milisegundos.
|
1 2 3 4 5 6 7 8 9 |
"status": "success", "metrics": { "elapsedTime": "30.125957ms", "executionTime": "30.110732ms", "resultCount": 20, "resultSize": 181449, "sortCount": 238 } } |
Este índice tiene los tres predicados en el índice. Aunque el índice realiza todo el filtrado, la consulta aún tiene que obtener el conjunto completo de resultados, ordenarlos y, a continuación, proyectar sólo la primera página. En mi máquina, esto se ejecuta en 30 milisegundos. Me gustaría reducirlo aún más para poder ejecutar muchas consultas simultáneamente.
|
1 2 3 4 |
DROP INDEX `travel-sample`.idx_hotel_ctry_likes; CREATE INDEX idx_hotel_ctry_likes_ratings ON `travel-sample` (country, ARRAY_LENGTH(public_likes), ratings DESC) WHERE type = “hotel” |
Vuelva a ejecutar la consulta.
|
1 2 3 4 5 6 7 |
"status": "success", "metrics": { "elapsedTime": "9.449025ms", "executionTime": "9.432752ms", "resultCount": 20, "resultSize": 181449 } |
Para esta consulta e índice, la explicación mostrará que LIMIT 20 se ha desplazado hasta el escaneo del índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
Esta consulta se ejecuta en menos de 10 milisegundos, evitando la obtención y ordenación completas. La forma más rápida de ordenar es evitar la propia ordenación.
Sección 4: Creación de enlaces a la página siguiente y a otras páginas

Cuando se muestra la primera página, Google también ofrece un enlace a la página siguiente y a otras 10 páginas posteriores. Como hemos comentado en la sección 1, el recuento total de resultados potenciales puede obtenerse de múltiples formas. Una vez obtenido el recuento, basta con crear los enlaces con los respectivos OFFSETs necesarios para cada página. Para obtener la página siguiente, simplemente establecemos el OFFSET en 20. Para obtener cada página siguiente o cualquier página aleatoria, basta con calcular el OFFSET con (página# * el número de documentos de una página). Por supuesto, este OFFSET debe ser menor que el número total de documentos potenciales en el conjunto de resultados. Ya hablamos de cómo obtener este recuento total en la sección 1.
Por ejemplo:
Primera página: OFFSET 0 LÍMITE 20;
Segunda página: OFFSET 20 LIMIT 20;
Ocho páginas: OFFSET 160 LÍMITE 20;
Sección 5: Búsqueda de la página siguiente o de cualquier otra página.
En la sección anterior, discutimos la creación de los enlaces con los parámetros de paginación correctos. Una vez que tenga la primera consulta, calcule los OFFSETs para las páginas subsiguientes, tendrá todo lo que necesita para emitir consultas para todas las consultas subsiguientes.
Recupere la segunda página mediante la siguiente consulta:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` t WHERE type = ‘hotel’ AND country = ‘United Kingdom’ AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 20 LIMIT 20; |
Simplemente se obtiene cada página subsiguiente (o una página aleatoria) cambiando el OFFSET.
Comenzando con Couchbase 5.0, cuando el índice puede evaluar el predicado completo y la cláusula ORDER BY, tanto OFFSET como LIMIT son empujados hacia abajo en el escaneo del índice. Esto hará que el escaneo del índice sea eficiente devolviendo el único número LIMITado de filas después de saltarse las filas cualificadas especificadas por OFFSET.
Debería ver un plan de consulta como el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "20", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
Incluso cuando se tiene que crear un índice óptimo (como en esta consulta), el índice todavía tiene que recorrer entradas cualificadas desde OFFSET 0 hasta OFFSET NN para identificar las entradas del índice a devolver. Cuando el valor de offset es grande, esto puede ser costoso. Cuando la consulta no tiene un índice adecuado, el procesamiento del desplazamiento es aún más costoso.
Conclusión
Aunque hemos optimizado el procesamiento de consultas N1QL y los escaneos de índices para optimizaciones, aún puede optimizar estas consultas aún más cuando sus casos de uso principalmente "fetch next". Este es un escenario común e importante. Marks Winand y Lukas Eder han discutido el método de paginación keyset, que mejora el rendimiento aún más. Sus artículos se encuentran en la sección de referencias.
En el próximo artículo, discutiré la implementación de la paginación de conjuntos de claves en Couchbase N1QL.
Referencias:
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/