La supervisión ha descubierto al acaparador de recursos. ¿Y ahora qué?
Couchbase Server 4.5 introdujo un mecanismo para mantener un ojo en la ejecución de las solicitudes, por lo que los lentos podrían ser destacados.
Este artículo de DZone cubre el tema de la vigilancia de N1QL con gran detalle, pero la cuestión ahora es: tenemos a los alborotadores, ¿cómo controlamos sus demandas?
En términos generales, todos los motores de bases de datos proporcionan medios para analizar el plan de consulta utilizado por una petición para devolver datos, en forma de algún tipo de sentencia EXPLAIN, pero ésta hace exactamente lo que dice la palabra: explica el plan, pero no dice realmente qué parte del plan se está comportando mal, utilizando números concretos.
Los administradores de bases de datos experimentados pueden decir, utilizando una mezcla de experiencia, heurística y corazonadas, cómo podría mejorarse un plan específico, pero este conjunto de habilidades específicas requiere una cantidad sustancial de formación y, para ser justos, también implica un cierto grado de conjeturas.
¿Podemos hacerlo mejor?
Introducir perfiles
Couchbase 5.0 introduce, entre otras cosas, la capacidad de recopilar métricas sobre todas las partes móviles de las solicitudes individuales.
Cuando la función está activada, la información sobre perfiles es devuelta por la solicitud a continuación del documento de resultados, y está disponible en los espacios de claves del sistema para su posterior procesamiento.
Esta métrica muestra el árbol de ejecución en detalle, con información como el tiempo empleado en cada operador y en cada fase de procesamiento, así como los documentos ingeridos y digeridos.
Con estos datos, los administradores de bases de datos pueden identificar fácilmente los operadores costosos en una solicitud y abordar el problema, por ejemplo, creando el índice adecuado para minimizar el número de claves cualificadas devueltas por la exploración del índice.
Pero empecemos por el principio.
Activar la creación de perfiles
El uso más frecuente de la creación de perfiles es comprender por qué una determinada sentencia es lenta.
Como tal, la sentencia lenta ya ha sido identificada y probablemente está siendo probada en un entorno sandbox - la única información necesaria es el texto de la sentencia culpable y no hay necesidad de recopilar perfiles de nada más.
Por el contrario, un nodo de producción puede estar atravesando una fase lenta.
No se ha identificado la petición culpable y es importante recopilar inmediatamente toda la información de diagnóstico disponible para que, una vez identificada la petición lenta, ya esté disponible el perfil sin tener que volver a ejecutar la sentencia infractora.
A nivel de solicitud
Esto puede hacerse con la función perfil parámetro de la API REST de solicitud, que se pasa al servicio de consulta junto con la sentencia de solicitud, ideal para investigar sentencias individuales.
Esto podría ser al nivel más bajo posible, como se ejemplifica con esto rizo ejemplo
|
1 |
curl https://localhost:8093/query/service -d 'statement=select * from `travel-sample`&profile=timings' -u Administrator:password |
O más sencillamente de una sesión de cbq shell
|
1 |
cbq> \set -profile timings; |
Query Workbench habilita la creación de perfiles por defecto, como veremos más adelante.
En perfil toma tres valores: fuera de (por defecto), fasesy horarios.
La primera, como era de esperar, simplemente desactiva la función.
La segunda permite obtener un resumen de los tiempos de ejecución para cada fase de solicitud, mientras que la última ofrece el mayor nivel de información disponible: tiempos completos por operador de ejecución.
A nivel de servicios
Cuando se requiere la creación de perfiles en todas las peticiones, se puede activar al iniciar el nodo mediante la opción -perfil parámetro de línea de comandos.
Toma los mismos argumentos que el parámetro query de la API REST, con el mismo significado.
Cualquier solicitud que no especifique ningún nivel de perfilado a nivel de la API REST toma el valor del argumento de la línea de comandos como la opción seleccionada.
Sobre la marcha
Cuando los clusters de producción muestran signos de fatiga, es posible cambiar la configuración del perfil de servicio de consulta sobre la marcha a través del punto final REST /admin/settings, por ejemplo
|
1 |
curl https://localhost:8093/admin/settings -d '{ "profile": "timings"}' -u Administrator:password |
Esto tiene el mismo efecto que inicializar el servicio de consulta utilizando la función -perfil sin embargo, también se aplica a las peticiones que ya se han iniciado, lo que significa que cuando las peticiones no especifican un ajuste de perfil de nivel de consulta, tomará el nuevo nivel establecido como la opción seleccionada.
Es importante saber que la información sobre perfiles se recopila en todo momento; los interruptores anteriores sólo determinan si se comunica información y cuánta.
Por lo tanto, es posible activar retroactivamente la creación de perfiles para las solicitudes que ya se han iniciado, lo que significa que cuando se observa una ralentización del sistema, un DBA puede crear un perfil de todas las solicitudes que ya se están ejecutando, sin tener que volver a enviar ninguna de las solicitudes o investigar primero cuál es la que está funcionando mal.
Obtención de información sobre perfiles
La información sobre el perfil de las solicitudes individuales está disponible como un subdocumento json que detalla el árbol de ejecución.
En términos generales, se trata de una estructura con el mismo formato y contenidos muy parecidos a los del EXPLICAR pero con estadísticas de ejecución.
La aplicación cliente puede acceder a ella a través del documento de respuesta (lo que resulta útil para investigaciones puntuales), y terceros, a través de los espacios de claves del sistema, lo que resulta útil, por ejemplo, para comparar diferentes variaciones de la misma sentencia, o la ejecución de la misma sentencia con diferentes valores para los marcadores de posición.
De la respuesta a la solicitud
El siguiente ejemplo muestra la ejecución de una sentencia en cbq, con el perfil activado
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 |
cbq> \set -profile timings; cbq> select * from `travel-sample` limit 1; { "requestID": "eff5d221-fc0d-459f-9de3-727747368a3e", "signature": { "*": "*" }, "results": [ { "travel-sample": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ], "status": "success", "metrics": { "elapsedTime": "65.441768ms", "executionTime": "65.429661ms", "resultCount": 1, "resultSize": 300 }, "profile": { "phaseTimes": { "authorize": "1.544104ms", "fetch": "1.776843ms", "instantiate": "777.209µs", "parse": "840.796µs", "plan": "53.121896ms", "primaryScan": "6.741329ms", "run": "10.244259ms" }, "phaseCounts": { "fetch": 1, "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "executionTimings": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "3.41µs", "kernTime": "10.23877ms" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 4, "execTime": "3.268µs", "kernTime": "8.651859ms", "servTime": "1.540836ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 3, "execTime": "8.764µs", "kernTime": "8.639269ms" }, "~children": [ { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "8.037µs", "kernTime": "8.591094ms" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "6.254658ms", "kernTime": "1.609µs", "servTime": "486.671µs" }, "index": "def_primary", "keyspace": "travel-sample", "limit": "1", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "48.055µs", "kernTime": "6.766558ms", "servTime": "1.728788ms" }, "keyspace": "travel-sample", "namespace": "default" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 5, "execTime": "1.675µs", "kernTime": "8.580305ms" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "4.113µs", "kernTime": "8.555317ms" }, "result_terms": [ { "expr": "self", "star": true } ] }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "2.201µs", "kernTime": "8.570215ms" } } ] } ] }, { "#operator": "Limit", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "3.244µs", "kernTime": "8.621338ms" }, "expr": "1" } ] } }, { "#operator": "Stream", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "8.647µs", "kernTime": "10.225903ms" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } } |
Observe que la respuesta incluye ahora un perfil con información sobre las fases, como phaseTimes, phaseCounts, phaseOperators (respectivamente, el tiempo de ejecución de cada fase, el número de documentos procesados por fase y el número de operadores que ejecutan cada fase), la única información que se proporciona cuando perfil se establece en fases - así como un executionTimings subsección.
De los espacios de claves del sistema
Las consultas a los espacios de claves del sistema pueden devolver información sobre el perfil de las solicitudes, siempre que el perfil esté activado para dichas solicitudes en el momento de la consulta.
He aquí un ejemplo rápido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
cbq> select * from system:active_requests; { "requestID": "7f500733-faba-45dc-8015-3127e305e86e", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "87.698587ms", "executionTime": "87.651658ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "1.406584ms", "fetch": "15.793µs", "instantiate": "50.802µs", "parse": "438.25µs", "plan": "188.113µs", "primaryScan": "75.53238ms" }, "remoteAddr": "127.0.0.1:57711", "requestId": "7f500733-faba-45dc-8015-3127e305e86e", "requestTime": "2017-10-09 19:36:04.317448352 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "88.016701ms", "executionTime": "87.969113ms", "resultCount": 1, "resultSize": 1220 } } |
El registro para la selección en sistema:solicitudes_activas es información de fase deportiva.
Si el perfilado está configurado en horariosel árbol de ejecución detallado se presenta como plan accesible a través de la página meta() función:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 |
cbq> select *, meta().plan from system:active_requests; { "requestID": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "signature": { "*": "*", "plan": "json" }, "results": [ { "active_requests": { "elapsedTime": "58.177768ms", "executionTime": "58.163366ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "674.937µs", "fetch": "8.26µs", "instantiate": "20.294µs", "parse": "985.136µs", "plan": "69.766µs", "primaryScan": "47.460796ms" }, "remoteAddr": "127.0.0.1:57817", "requestId": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "requestTime": "2017-10-09 19:36:31.374286818 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select *, meta().plan from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" }, "plan": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "818ns", "kernTime": "57.105844ms", "state": "kernel" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "3.687µs", "kernTime": "56.428974ms", "servTime": "671.25µs", "state": "kernel" }, "privileges": { "List": [ { "Priv": 4, "Target": "#system:active_requests" } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "1.35µs", "kernTime": "56.439225ms", "state": "kernel" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "19.430376ms", "kernTime": "2.821µs", "servTime": "28.03042ms" }, "index": "#primary", "keyspace": "active_requests", "namespace": "#system", "using": "system" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "638ns", "kernTime": "56.466039ms", "state": "kernel" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.402µs", "kernTime": "56.471719ms", "state": "kernel" }, "result_terms": [ { "expr": "self", "star": true }, { "expr": "(meta(`active_requests`).`plan`)" } ] }, { "#operator": "FinalProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.105µs", "kernTime": "56.49816ms", "state": "kernel" } } ] } ] } }, { "#operator": "Stream", "#stats": { "#phaseSwitches": 1, "execTime": "366ns", "kernTime": "57.250988ms", "state": "kernel" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } ], "status": "success", "metrics": { "elapsedTime": "59.151099ms", "executionTime": "59.136024ms", "resultCount": 1, "resultSize": 6921 } } |
La información mostrada aquí en sistema:solicitudes_activas también es accesible desde sistema:solicitudes_realizadassuponiendo que la solicitud en cuestión, una vez completada, cumpla los requisitos para su almacenamiento en sistema:solicitudes_realizadas y se activó la creación de perfiles.
Tenga en cuenta que la información de temporización devuelta por sistema:solicitudes_activas es actuallo que significa que incluye los tiempos de ejecución acumulados hasta ahora: una segunda selección en sistema:solicitudes_activas puede utilizarse para determinar el coste de un operador concreto en el intervalo de tiempo transcurrido entre las dos selecciones.
Información facilitada
Como se muestra en el siguiente ejemplo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" } |
el documento del árbol de ejecución informa, para cada operador, del número de documentos ingeridos y digeridos (1TP5ArtículosEn y #itemsOut), tiempo de ejecución del código del operador (execTime), en espera de ser programado (kernTime) y esperar a que los servicios suministren datos (servTime), el número de veces que el operador ha cambiado de estado (ejecutando, a la espera de ser programado, a la espera de datos) y el estado actual (suponiendo que la solicitud aún no haya finalizado).
Las estadísticas del operador son muy detalladas a propósito: se sabe que cada medida individual ha destacado de forma prominente durante investigaciones específicas de rendimiento, ¡y no me avergüenza decir que también se han utilizado provechosamente durante mis propias sesiones de depuración!
Para hacernos una idea de lo que se puede conseguir, pensemos en lo siguiente interruptores de fase.
Supongamos que, tras reunir los perfiles dos veces, el número de interruptores de fase para un operador concreto no ha aumentado.
Es posible que ese operador en concreto no esté funcionando correctamente: ¿debería el estado estar atrapado en "servicios"dependiendo del operador, puede estar esperando en el almacén de documentos (para una búsqueda) o en el servicio de indexación (para una búsqueda).
¿Quizá el servicio correspondiente no funciona o está atascado?
Por el contrario, si está atrapado en "núcleo"En ese caso, es posible que un consumidor no esté aceptando datos, o que la máquina esté tan cargada que el programador no esté encontrando franjas horarias para el operador.
La siguiente sección tratará algunos signos reveladores de algunos escenarios comunes, primero los escenarios más probables.
Interpretar perfiles
Cualquier operador: tiempo de núcleo alto
Se trata de un cuello de botella en un operador más adelante.
Busque un operador con un alto tiempo de ejecución o de servicios.
Si no se encuentra ninguno, el núcleo de ejecución tiene problemas para programar los operadores: el nodo de consulta está sobrecargado y añadir uno nuevo podría resultar útil.
Fetches, Joins, Scans: tiempos de servicio elevados
Esto puede indicar un servicio externo estresado.
Una confirmación de esto vendría de una baja tasa de cambio en #itemsOut, aunque esto requiere tomar el mismo perfil más de una vez, lo que puede resultar inconveniente (o imposible, si la solicitud ya ha finalizado).
Como alternativa, busque los síntomas que se describen a continuación.
Fetches y Joins: alto tiempo de servicio por documento entrante
Las búsquedas de documentos individuales deben ser rápidas.
Dividir servTime por #itemsOut debería producir siempre tiempos de búsqueda sustancialmente inferiores a un milisegundo.
Si no es así, es que el almacén de documentos está bajo tensión.
Para que quede claro, no es necesariamente la solicitud que se está perfilando la que está sometiendo a estrés al almacén: lo más probable es que el problema sea la carga general del servicio.
Una forma de asegurarse de que el problema es la carga global, al menos mientras se realizan pruebas de estrés, es reducir el número de clientes trabajadores: en un almacén sobrecargado, los tiempos de obtención individuales se mantienen constantes a medida que disminuye el número de clientes, y sólo empiezan a mejorar cuando la carga llega a un nivel que puede manejarse más fácilmente.
Fetches: alto número de documentos ingestados
Un buen plan de consulta debe utilizar un índice que produzca sólo las claves de documentos que sean relevantes para la solicitud.
Si el número de claves pasadas al operador Fetch es mucho mayor que el número final de documentos devueltos al cliente, el índice elegido no es lo suficientemente selectivo.
Escaneados: elevado número de documentos producidos
Es la contrapartida del síntoma anterior: el índice elegido no es suficientemente selectivo. Considere la posibilidad de crear un índice para que los predicados adicionales puedan ser empujados a la exploración del índice.
Uniones: pocos documentos ingeridos, muchos documentos producidos
De nuevo, se trata sin duda de una ruta de índice incorrecta: ¿se supone que la unión debe producir tantos resultados en primer lugar?
Filtros: muchos documentos ingeridos, pocos documentos producidos
Otro indicador de "índice elegido definitivamente no lo suficientemente selectivo".
Filtros: tiempo de ejecución elevado
Esto no debería ocurrir nunca, y si ocurre, lo más probable es que vaya acompañado del síntoma anterior.
No sólo el índice no era suficientemente selectivo y devolvía demasiadas claves de documentos, sino que evaluar todas las expresiones de la cláusula WHERE para tantos documentos está resultando bastante caro.
Proyección: tiempo de ejecución elevado
De nuevo, una improbable: el servicio de consulta se esfuerza por reunir los documentos de resultados para la solicitud.
¿Cuántos términos tiene en la cláusula de proyección de la sentencia SELECT? ¡Afeite unos cuantos!
¿Tiene expresiones complejas?
Stream: tiempo de ejecución elevado
La solicitud se esfuerza por convertir el resultado en forma JSON y enviarlo al cliente.
En bonito El parámetro REST puede haberse configurado como verdadero por error.
La lista de proyección puede tener demasiados términos.
Otra posibilidad es que haya un problema en la red o que los documentos enviados sean demasiado grandes para que la red pueda soportarlos.
Controla
Muchas veces, el comportamiento de las solicitudes depende de los valores de los marcadores de posición, por lo que sería muy útil capturar los valores de los marcadores de posición junto con los perfiles.
Esto puede hacerse con la función controla consulta REST API, parámetro de línea de comandos y /admin/configuración REST, que toma un verdadero o falso valor.
Su comportamiento es exactamente el mismo que el de perfil y puede establecerse para cada solicitud, al inicio, sobre la marcha o para todo el servicio. También puede aplicarse retrospectivamente a las solicitudes en ejecución que no hayan especificado una configuración.
Los parámetros de nombre y posición se indicarán en la salida de la solicitud en su propia sección de control:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cbq> \set -controls true; cbq> \set -$a 1; cbq> select * from default where a = $a; { "requestID": "bf6532d6-f009-4e55-b333-90e0b1d17283", "signature": { "*": "*" }, "results": [ ], "status": "success", "metrics": { "elapsedTime": "9.864639ms", "executionTime": "9.853572ms", "resultCount": 0, "resultSize": 0 }, "controls": { "namedArgs": { "a": 1 } } } |
así como en los espacios de claves del sistema (aunque, a diferencia de los perfiles, no es necesario acceder a ningún archivo adjunto a través de la función meta() función):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
cbq> select * from system:active_requests; { "requestID": "dced4ef6-7a31-4291-a15d-030ac67b033c", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "69.458652ms", "executionTime": "69.434706ms", "namedArgs": { "a": 1 }, "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "remoteAddr": "127.0.0.1:63095", "requestId": "dced4ef6-7a31-4291-a15d-030ac67b033c", "requestTime": "2017-10-09 20:51:33.400550619 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "69.62242ms", "executionTime": "69.597934ms", "resultCount": 1, "resultSize": 977 } } |
Perfiles visuales
Una forma bastante sencilla de acceder a información detallada sobre perfiles de extractos individuales, sin tener que hacer nada especial, es a través de la pestaña Consulta de la interfaz de usuario de Admin Console.
Query WorkBench activa la creación de perfiles por defecto y, una vez finalizada la solicitud, los tiempos y el recuento de documentos están fácilmente disponibles en forma pictórica, haciendo clic en el botón "plan".
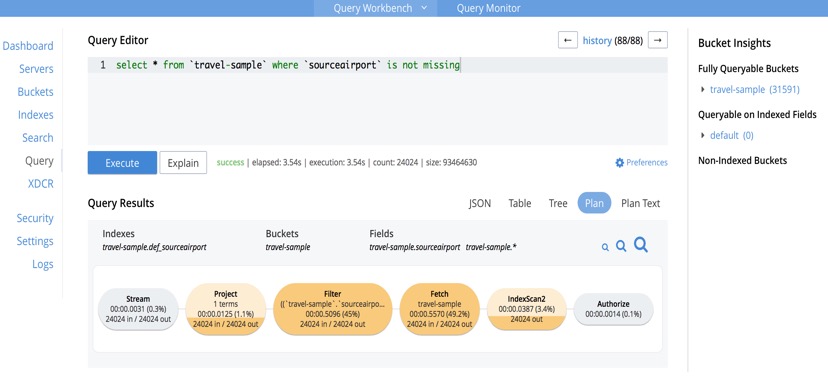
Los operadores están ordenados por colores según su coste, y al pasar el ratón por encima de cada uno de ellos aparecerá abundante información sobre los tiempos en bruto.
Las Preferencias permiten cambiar los ajustes de perfilado, así como otros ajustes como los parámetros de nombre y posición.
Perfilar es mucho más que perfilar
La información sobre perfiles y controles también puede utilizarse para un seguimiento más detallado.
Por ejemplo, para encontrar solicitudes con cualquier operador que produzca cantidades excesivas de documentos, se podría utilizar
|
1 2 |
select * from system:active_requests where any o within meta().plan satisfies o.`#itemsOut` > 100000 end; |
(modifique el umbral de los documentos de salida en función de sus necesidades).
El ejemplo es bastante simplista, y en realidad podría hacerse más fácilmente utilizando phaseCountspero cambiando la cláusula ANY por
|
1 2 3 |
o.`#operator` = "Fetch" and o.keyspace = "travel-sample" and o.`#stats`.`#itemsOut` > 100000 |
y ¡listo!, se revelan las peticiones que cargan un espacio clave específico.
Del mismo modo, la búsqueda de cualquier solicitud que utilice un valor específico para cualquier parámetro con nombre se puede lograr con
|
1 2 |
select * from system:active_requests where namedArgs.`some parameter` = "target value"; |
(sustituya "algún parámetro" y "valor objetivo" por los valores requeridos)
Las posibilidades son infinitas.
Una última consideración
La información de perfiles se almacena en el propio árbol de ejecución, que consume bastante memoria.
Esto en sí mismo no es un problema, sin embargo, tenga en cuenta que cuando una solicitud de ejecución lenta se convierte en elegible para el almacenamiento en sistema:solicitudes_realizadas y perfil se establece en horariostambién se almacenará todo el árbol de ejecución.
Esto, de nuevo, no es un problema en sí mismo. Sin embargo, puede convertirse en un problema si sistema:solicitudes_realizadas está configurado para registrar todas las peticiones, no tiene límite, y todas las peticiones tienen perfil ajustado a horariosEn este caso, el uso de memoria puede crecer más allá de lo razonable, ya que se están almacenando todos los tiempos de todas las peticiones ejecutadas desde el principio de los tiempos.
Afortunadamente, la configuración por defecto de sistema:solicitudes_realizadas El registro significa que no te meterás en problemas sin saberlo y, de todos modos, no estoy sugiriendo que seas ahorrativo con la cantidad de tiempos que registras, pero este es un caso en el que el exceso puede ser doloroso.
Estás avisado.
Conclusiones
A partir de la versión 5.0 de Couchbase Server, N1QL ofrece herramientas especializadas para analizar en profundidad los tiempos de ejecución.
Se han dado ejemplos de cómo acceder a la funcionalidad e interpretar los datos recogidos.