Capella AI Services junto a NVIDIA AI Enterprise
Couchbase está trabajando con NVIDIA para ayudar a las empresas a acelerar el desarrollo de aplicaciones de IA agéntica añadiendo soporte para NVIDIA AI Enterprise incluidas sus herramientas de desarrollo, Marco de modelos neuronales (NeMo) y Microservicios NVIDIA Inference (NIM). Capella añade soporte para NIM dentro de su Servicios de modelos de IA y añade acceso a NVIDIA NeMo Framework para crear, entrenar y ajustar modelos lingüísticos personalizados. El marco admite la curación de datos, el entrenamiento, la personalización de modelos y los flujos de trabajo RAG para empresas.
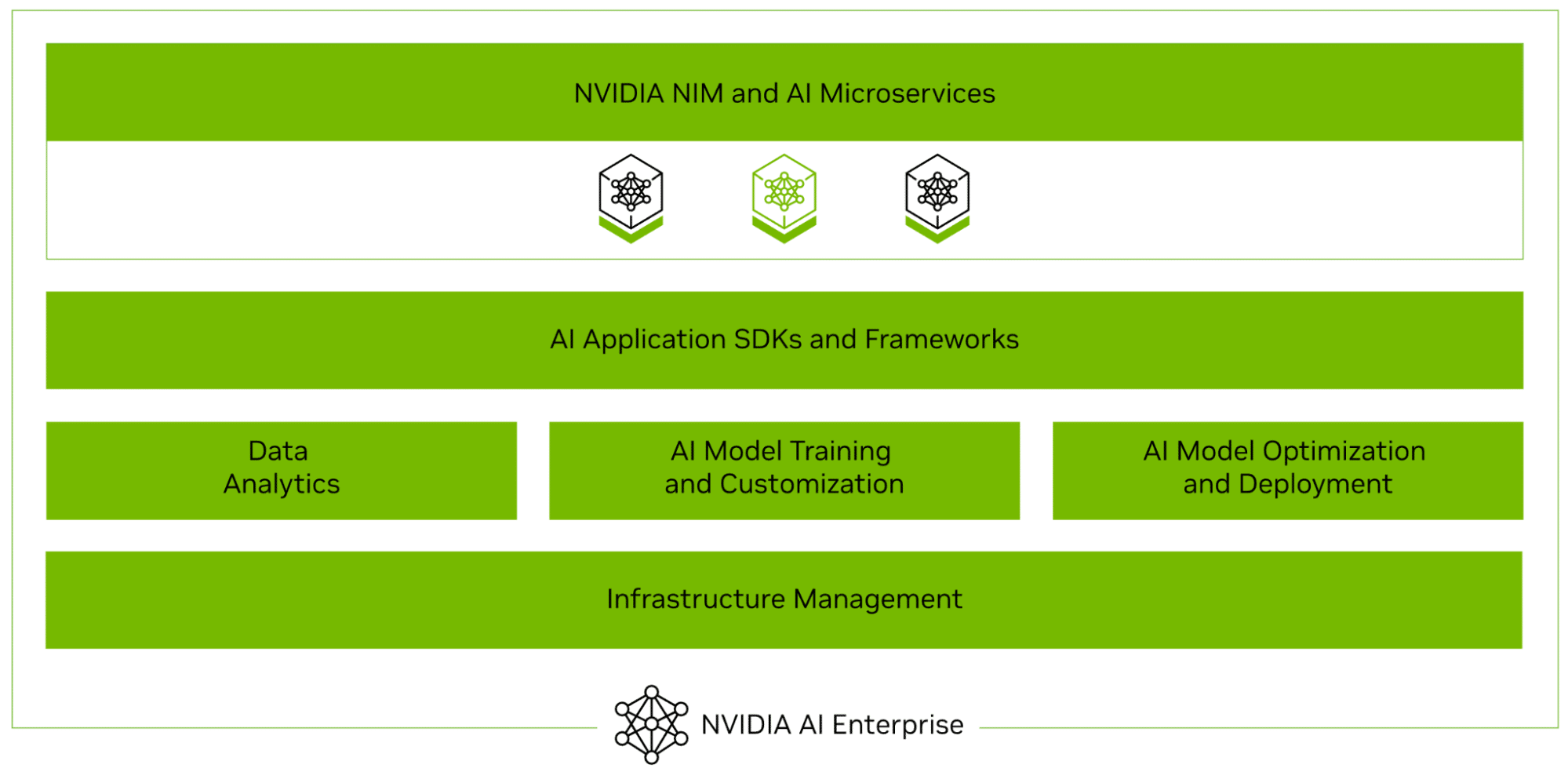
Los servicios de IA de Capella con NVIDIA AI Enterprise soportan el ciclo de vida completo de la entrega de agentes
A diferencia de las bases de datos que soportan exclusivamente la búsqueda de vectores sin proporcionar asistencia para la creación y utilización de los mismos, Couchbase Capella gestiona datos operativos, analíticos, de IA y móviles, a la vez que simplifica la utilización de esos datos para los flujos de trabajo de IA.dentro de la misma plataforma.
En estos flujos de trabajo de datos de IA es donde se ha trasladado la complejidad para los desarrolladores, ya que incluyen:
-
- preparación de datos
- vectorización
- ingeniería rápida y almacenamiento en caché
- interacciones del modelo, incluido el dispositivo
- caché de respuesta
- almacenamiento de transcripciones
- validación de la respuesta
- gestión de barandillas

- gobierno de los agentes

La solución combinada mejora, a la vez que simplifica, las capacidades de generación aumentada por recuperación (RAG) de Capella, lo que permite a los clientes potenciar de forma eficiente aplicaciones de IA de alto rendimiento, manteniendo al mismo tiempo la flexibilidad del modelo. Con el acceso al marco NeMo, los desarrolladores obtienen una gran cantidad de herramientas de productividad y modelos en un solo entorno.
A continuación, tienen acceso a más de 30 modelos de BigCode, Microsoft, NVIDIA, Mistral, Meta y Google a través de NIM. Con NVIDIA AI Enterprise, los desarrolladores pueden crear, entrenar y ajustar modelos para aplicaciones específicas y, a continuación, disfrutar de las ventajas de la aceleración en la GPU durante la implantación.
Las empresas tienen dificultades para confiar en la IA por varias razones
Las organizaciones que crean y despliegan aplicaciones de IA de alto rendimiento se enfrentan al reto de garantizar la fiabilidad y el cumplimiento de los agentes y evitar que se desvíen de su ruta operativa prevista. Esta desviación se produce por una serie de razones que van más allá de las obvias, como las fugas de datos PII o las alucinaciones basadas en modelos. La deriva puede producirse con el tiempo, ya que los modelos pueden simplemente cambiar su opinión y, por tanto, sus respuestas y conclusiones, basándose en la evolución de su entrenamiento, así como en la evolución de los datos contenidos en sus indicaciones.
No sólo eso, sino que los modelos a menudo mantienen por error un contexto conversacional que ya no es válido, dentro de una conversación activa. Capella y NVIDIA AI Enterprise pueden ayudar a los desarrolladores a crear guardarraíles más estrictos y agentes más intencionados que se desvíen con menos frecuencia, mantengan el contexto adecuado a lo largo del tiempo y, por tanto, funcionen como sus autores esperaban. Por ejemplo, las transcripciones de las conversaciones de los agentes deben capturarse y compararse en tiempo real dentro de NIM para evaluar la precisión de la respuesta del modelo.
IA segura sin compromisos
Nuestra solución conjunta ofrece a las organizaciones una forma segura y rápida de crear, implantar y desarrollar aplicaciones basadas en IA. La solución de NVIDIA aprovecha LLM y herramientas previamente probadas que incluyen NVIDIA NeMo Guardrails para ayudar a las organizaciones a acelerar el desarrollo de la IA y, al mismo tiempo, aplicar políticas y salvaguardas contra las alucinaciones de la IA, mientras que Capella ayuda a mantener la memoria a corto y largo plazo de la IA mediante el almacenamiento en caché y en transcripciones, al tiempo que su rendimiento y proximidad tanto a los modelos como a la infraestructura de ejecución reduce las latencias de conversación, lo que resulta crítico para el despliegue de agentes. La ejecución en los microservicios NIM de NVIDIA, rigurosamente probados y listos para la producción, permite a las empresas cumplir los requisitos de privacidad, rendimiento, escalabilidad y latencia con sus aplicaciones de agentes.
Una última ventaja
Matt McDonough, Vicepresidente Senior de Producto y Socios, destaca el valor de nuestra colaboración:
Las empresas necesitan una plataforma de datos unificada y de alto rendimiento para apuntalar sus esfuerzos de IA y respaldar el ciclo de vida completo de las aplicaciones, desde el desarrollo hasta la implantación y la optimización. Al integrar los microservicios NVIDIA NIM en Capella AI Model Services, ofrecemos a los clientes la flexibilidad necesaria para ejecutar sus modelos de IA preferidos de forma segura y gobernada, al tiempo que proporcionamos un mejor rendimiento para las cargas de trabajo de IA y una integración perfecta de la IA con datos transaccionales, analíticos, de IA y móviles. Capella AI Services permite a los clientes acelerar sus aplicaciones RAG y agentic con confianza, sabiendo que pueden escalar y optimizar sus aplicaciones a medida que evolucionan las necesidades del negocio.
Esta solución combinada NVIDIA/Couchbase no sólo ayuda a los desarrolladores a desplegar, escalar y optimizar las aplicaciones agénticas de forma más rápida y segura, sino que también ayudamos a DevOps a acelerar y gestionar AgentOps: el despliegue de agentes junto con modelos optimizados, rendimiento de baja latencia, seguridad empresarial, gobernanza, observabilidad y seguridad. Y para los responsables de proyectos y responsables de presupuestos, nuestra solución combinada permite a sus organizaciones maximizar el ROI de estas inversiones en IA al combinar las ventajas de rendimiento y consolidación de datos de Capella con la proximidad al entorno NVIDIA AI Enterprise, todo ello mientras se opera en una infraestructura acelerada por NVIDIA. Puede que no haya una combinación mejor para maximizar el ROI de la inteligencia artificial.
Nos vemos en la Conferencia sobre Tecnología para la GPU de NVIDIA

Más información Servicios de IA de Capella e inscríbase en el vista previa privada.
Recursos adicionales
-
- Más información esta integración acelera el desarrollo de aplicaciones de IA agéntica
- Más información Los servicios de inteligencia artificial de Capella permiten a los desarrolladores crear aplicaciones agénticas
- Explore NVIDIA NeMo Guardrails
- Utilizar con seguridad los LLM con propiedad Datos empresariales en NVIDIA NeMo