Un RoSe en cualquier otro caso olería igual de dulce. William Shakespeare
Debes haber aprendido normas de capitalización en su escuela de gramática, pero la búsqueda en el mundo real no es tan sensible a las mayúsculas. Charles de Gaulle utiliza minúsculas para la "de" intermedia, Tony La Russa utiliza mayúsculas para "La" - puede haber razones etimológicas para ello, pero es poco probable que su agente de servicio al cliente lo recuerde. Las bases de datos tienen varias sensibilidades. SQL, por defecto, no distingue entre mayúsculas y minúsculas en los identificadores y palabras clave, pero sí en los datos. JSON distingue entre mayúsculas y minúsculas tanto en los nombres de campo como en los datos. Lo mismo ocurre con N1QL. JSON puede tener lo siguiente. N1QL select-join-proyectará cada campo y valor como un campo y valor distintos.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECCIONE {"Ciudad": "San Francisco", "ciudad": "san francisco", "citY": "saN fanciscO"} [ { "$1": { "Ciudad": "San Francisco", "citY": "saN fanciscO", "ciudad": "san francisco" } } ] |
En este artículo hablaremos de cómo hacer frente a distinción entre mayúsculas y minúsculas en los datos. Sus referencias de campo siguen siendo distingue entre mayúsculas y minúsculas. Si usa el caso incorrecto para el nombre del campo, N1QL asume que este es un campo faltante y asigna el valor FALTANTE a ese campo.
Consideremos un predicado simple en N1QL para buscar todas las permutaciones de casos.
|
1 |
DONDE nombre en ["joe", "joE", "jOe", "Joe", "JoE", "JOe", "JOE"] |
Esto requiere siete búsquedas diferentes en el índice. "John" requiere más búsquedas en el índice y "Fitzerald" aún más. Existe una forma estándar de hacerlo. Basta con crear un índice bajando el caso del campo y el literal.
|
1 |
DONDE BAJO(nombre) = "joe" |
Esta búsqueda puede hacerse más rápida creando el índice con la expresión correcta.
|
1 |
CREAR ÍNDICE i1 EN cliente(BAJO(nombre)); |
Asegúrese de que su consulta está recogiendo el índice correcto y empuja el predicado a la exploración del índice. Y esa es la idea. Las consultas que tienen predicados empujados a la exploración del índice se ejecutan mucho más rápido que las consultas que no. Esto es cierto para los predicados y cierto empuje agregado también.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
EXPLICAR SELECCIONE * DESDE cliente DONDE BAJO(nombre) = "joe"; { "#operator": "IndexScan3", "índice": "i1", "index_id": "c117bdf583c2e276", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "cliente", "espacio de nombres": "por defecto", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"joe\"", "inclusión": 3, "bajo": "\"joe\"" } ] } ], |
Insensibilidad a los casos en un escenario de índice compuesto.
|
1 2 3 4 5 |
DONDE BAJO(nombre) = "joe" Y zip = 94821 Y salario > 500 Y fecha_unión <= "2017-01-01" Y BAJO(condado) COMO "san%" |
|
1 2 3 4 5 |
CREAR ÍNDICE i2 EN cliente(BAJO(nombre), cremallera, BAJO(condado), join_date, salario) |
Insensibilidad a mayúsculas y minúsculas en funciones Array.
Funciones de cadena como SPLIT(), SUFFIXES(), muchas de las funciones de matriz y funciones del objeto sí devuelven matrices. Entonces, ¿cómo utilizarlos sin distinguir entre mayúsculas y minúsculas?
Seguimos el mismo principio que antes. Crea primero una expresión para minusvalorar los valores antes de procesarlos mediante estas funciones.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECCIONE DIVIDIR("Buenos días, Joe") como splitresult; "splitresult": [ "Bien", "Buenos días", "Joe" ] SELECCIONE DIVIDIR(BAJO("Good Por la mañana, Joe")); "splitresult": [ "bueno", "mañana,", "joe" ] |
Ahora, lo que realmente quieres es filtrar en base a un valor dentro de la cadena.
|
1 |
DONDE BAJO(xyz) COMO "%good%"; |
Este es probablemente el peor predicado en SQL - en términos de rendimiento.
|
1 2 |
SELECCIONE * DESDE cliente DONDE x EN DIVIDIR(BAJO(xyz)) SATISFACE x = "bueno" FIN |
Ahora, ¿qué índice crearías para esto? CONSEJO es muy útil.
|
1 2 |
CREAR ÍNDICE adv_DISTINCT_split_lower_xyz EN cliente (DISTINTO ARRAY `x` PARA x en dividir(inferior((`xyz`))) FIN) |
Como de costumbre, verifique su explicación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "DistinctScan", "escanear": { "#operator": "IndexScan3", "índice": "adv_DISTINCT_split_lower_xyz", "index_id": "552ab6c643616fbc", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "cliente", "espacio de nombres": "por defecto", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"good\"", "inclusión": 3, "bajo": "\"good\"" } ] } ], |
Si desea utilizar UNNEST y una cláusula WHERE sencilla, utilice esta consulta. Verifique siempre su explicación para asegurarse de que los predicados son empujados a la exploración del índice.
|
1 2 3 |
SELECCIONE * DESDE cliente UNNEST DIVIDIR(BAJO(xyz)) AS x DONDE x = "bueno" |
Uso de fichas
La función TOKENS() simplifica la obtención de las minúsculas tomando esa opción como argumento. Véase el artículo Más que LIKE: Búsqueda eficiente en JSON con N1QL para más detalles y ejemplos
Expresiones complejas.
|
1 2 3 4 |
SELECCIONE * DESDE cliente DONDE inferior(fname) || inferior(mname) || inferior(lname) = "JoeMSmith" |
¿Cómo podemos optimizarlo? Index Advisor al rescate. Otra vez.
|
1 2 |
CREAR ÍNDICE adv_lower_fname_concat_lower_mname_concat_lower_lname EN `cliente`(inferior((`nombre`))|||inferior((`nombre`))|||inferior((`nombre`))) |
Explicar para confirmar el plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "IndexScan3", "índice": "adv_lower_fname_concat_lower_mname_concat_lower_lname", "index_id": "aaa14cbdf14e9cd8", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "cliente", "espacio de nombres": "por defecto", "vanos": [ { "exacto": verdadero, "rango": [ { "alto": "\"JoeMSmith\"", "inclusión": 3, "bajo": "\"JoeMSmith\"" } ] } ], "usando": "gsi" }, |
Búsqueda de textos completos
Como te habrás dado cuenta, se trata de un problema de procesamiento y consulta de texto. El FTS puede escanear, almacenar y buscar texto de varias maneras. La búsqueda insensible a mayúsculas y minúsculas es una de ellas. Veamos el plan para una simple consulta de búsqueda.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
seleccione * de cliente donde busque en (nombre, "joe") "~niños": [ { "#operator": "PrimaryScan3", "índice": "#primary", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "cliente", "espacio de nombres": "por defecto", "usando": "gsi" }, { "#operator": "Fetch", "espacio clave": "cliente", "espacio de nombres": "por defecto" }, { "#operator": "Paralelo", "~niño": { "#operator": "Secuencia", "~niños": [ { "#operator": "Filtro", "condición": "search((`cliente`.`nombre`), \"joe\")" }, { "#operator": "ProyectoInicial", "result_terms": [ { "expr": "yo", "estrella": verdadero } ] } ] } } ] } |
Este NO es el plan que quieres... ¡Esto es usar un escáner primario!
Después de crear el índice de texto en el cliente cubo, las cosas van mucho mejor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
seleccione * de cliente donde busque en (nombre, "joe") { "#operator": "Secuencia", "~niños": [ { "#operator": "IndexFtsSearch", "índice": "trname", "index_id": "3bdb61e5010e8838", "espacio clave": "cliente", "espacio de nombres": "por defecto", "search_info": { "campo": "\"`nombre`\"", "outname": "fuera", "consulta": "\"joe\"" }, "usando": "fts" }, |
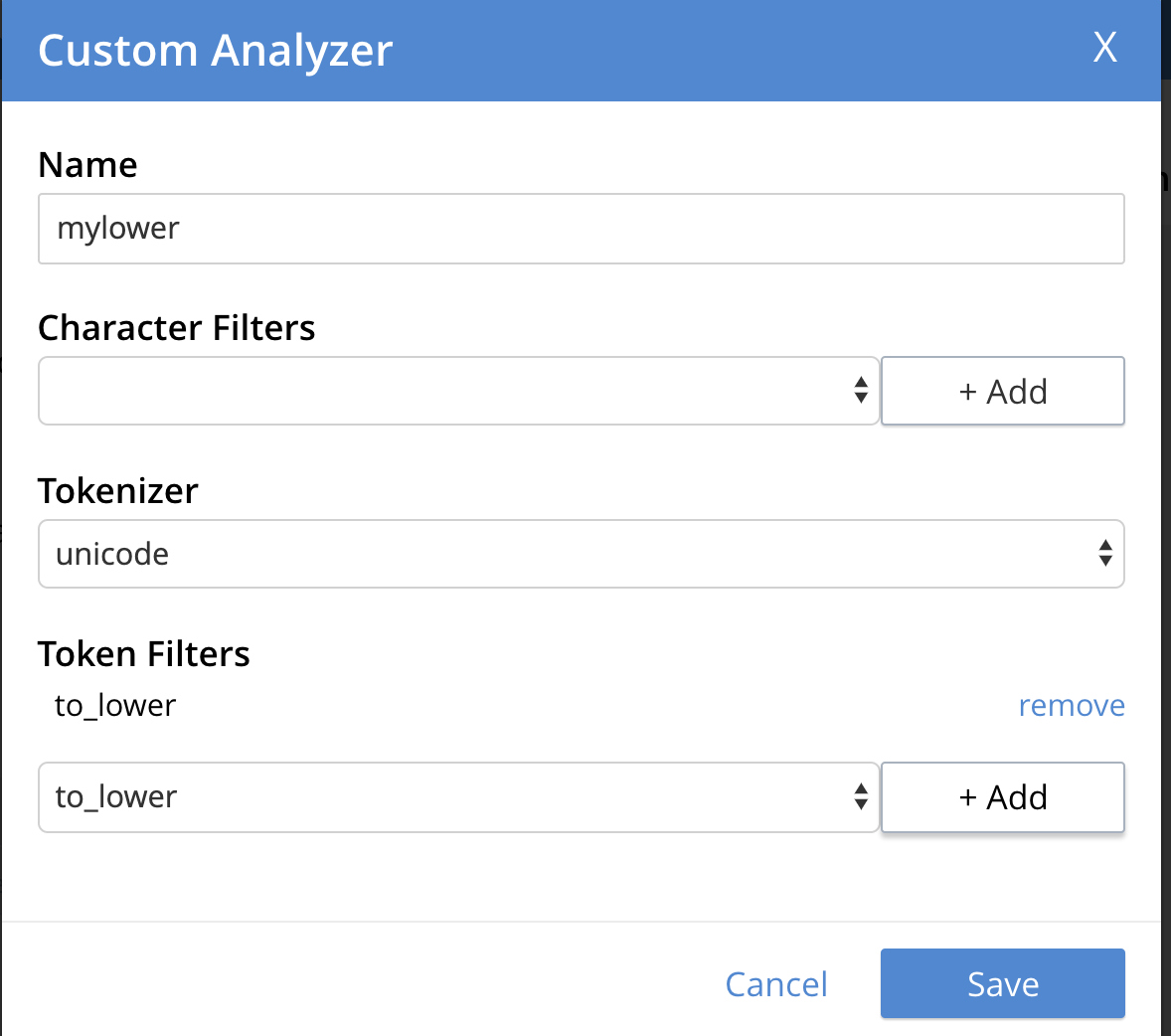
El analizador estándar por defecto baja todos los tokens y por lo tanto encontrará todos los "joe "s : JOE, joe, Joe, JOe, etc. Puede definir un analizador personalizado y proporcionar instrucciones específicas para minusvalorar los tokens. He aquí un ejemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"mapeo": { "análisis": { "analizadores": { "mylower": { "token_filters": [ "to_lower" ], "tokenizer": "unicode", "tipo": "personalizado" } } }, |
Así es como se añade en la interfaz de usuario. Ver blog fino 8 formas de personalizar los índices de búsqueda de texto completo de Couchbase para más detalles sobre las distintas formas de personalizar el índice FTS.