Couchbase sigue a la cabeza de la analítica de datos de alto rendimiento con la introducción de SDK para Capella Columnarsu base de datos analítica de última generación, diseñada para análisis JSON en tiempo real sin ETL y con opciones de escritura operativa. Para los desarrolladores que necesitan un acceso rápido y fiable a bases de datos columnares, estos SDK ofrecen una integración perfecta en múltiples lenguajes de programación. Tanto si desarrolla en Java, Pythono Node.js, los SDK Columnar de Capella le permiten aprovechar las capacidades avanzadas de la base de datos analítica de Couchbase con un esfuerzo mínimo.
En esta entrada del blog, exploraremos las principales características, ventajas y casos de uso del recién lanzado SDK de columnas Capella-mostrando cómo simplifican las operaciones de datos para los desarrolladores que trabajan en aplicaciones intensivas en datos. También mostramos ejemplos de código para ilustrar la sencillez y coherencia de nuestro enfoque.
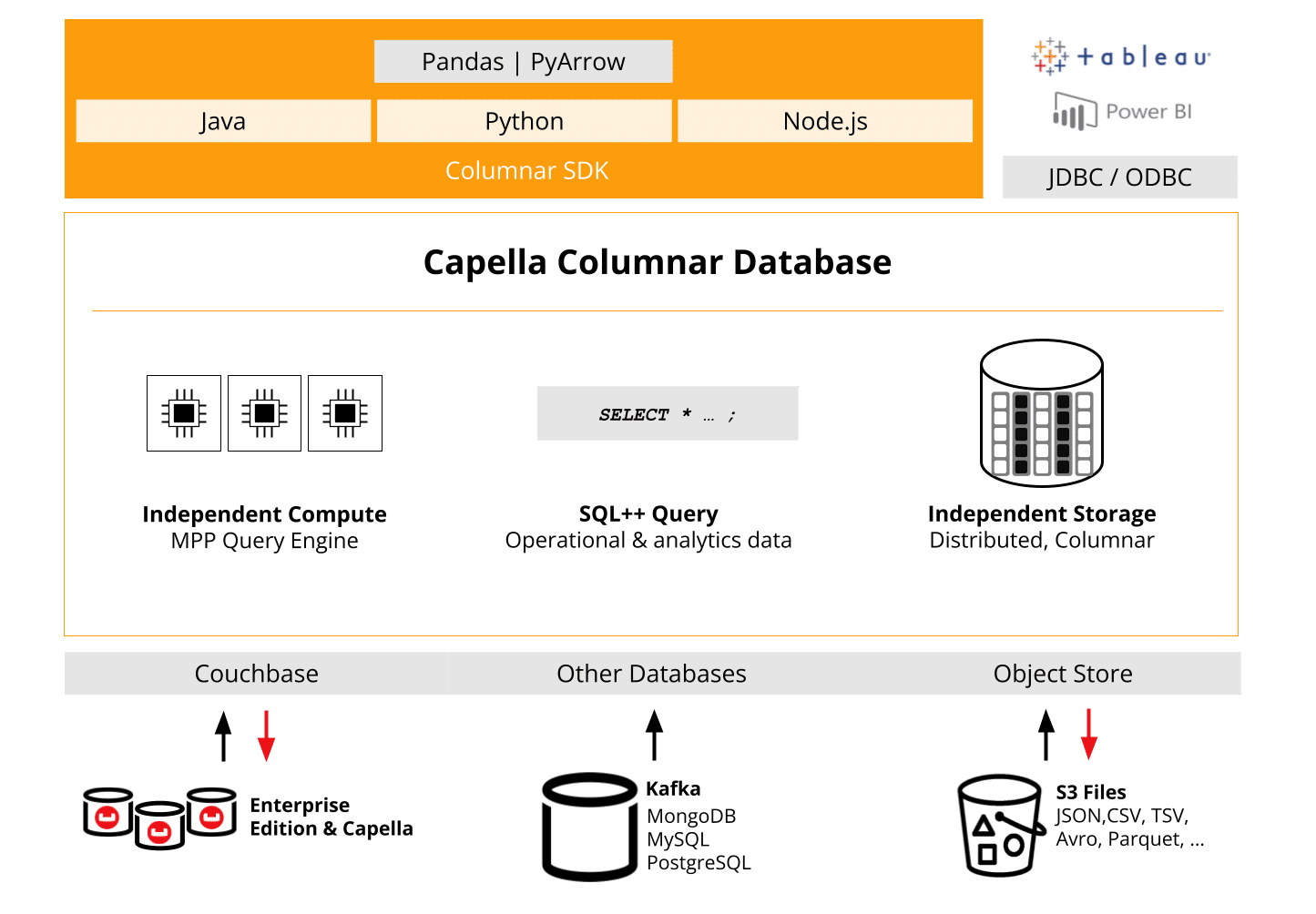
SDK específicos para análisis en tiempo real
Uno de los principales puntos fuertes de los SDK Columnar de Capella es su capacidad para optimizar el acceso a los datos y el rendimiento de las consultas, lo que los hace ideales para cargas de trabajo analíticas a gran escala. A medida que las organizaciones dependen cada vez más de la analítica de datos en tiempo real y del procesamiento por lotes, la eficiencia de las consultas y la gestión de recursos se convierten en aspectos críticos.
Los SDK de Capella Columnar se han diseñado teniendo en cuenta estas necesidades y ofrecen una serie de funciones que ayudan a los desarrolladores a ajustar las interacciones de datos y garantizar un alto rendimiento, incluso en condiciones exigentes. Los SDK se han construido desde cero específicamente para ofrecer un alto rendimiento y fiabilidad sin tomar atajos (como envoltorios sobre API, etc.).
Los SDK de Capella Columnar se basan en tres pilares fundamentales:
- Facilidad de desarrollo
Los desarrolladores pueden interactuar con la base de datos columnar de Couchbase dentro de su pila tecnológica existente sin necesidad de herramientas o configuraciones adicionales. Los SDKs soportan nativamente cada lenguaje, ofreciendo API idiomáticas que resulten naturales para los desarrolladores. - API detectables
Los SDK están diseñados con una API totalmente detectable. Esto significa que dentro de su IDEObtendrá autocompletado automático y sugerencias para funciones, clases y parámetros, lo que acelerará su ciclo de desarrollo. Ya no tendrás que buscar los métodos adecuados: el SDK te guiará mientras construyes. - Robustez
Creados pensando en el rendimiento, los SDK ofrecen funciones avanzadas como gestión de conexiones, tratamiento de errores, tiempos de esperay reintentos. Estas capacidades garantizan que su aplicación permanezca estable incluso en entornos de alta carga o tolerantes a fallos.
Plataformas e idiomas
Los SDK de Capella Columnar admiten un conjunto diverso de plataformas y lenguajes, entre los que se incluyen:
- Idiomas: Java (17+), Python (3.9-3.12), Node.js (v20, v22)
- Sistemas operativos: Linux, Windows, macOS (incluida la compatibilidad con procesadores ARM como AWS Graviton y Apple M1).
Al ofrecer compatibilidad con todas estas plataformas, Couchbase garantiza que los desarrolladores puedan implantar sus aplicaciones en diversos entornos, desde infraestructuras en la nube hasta sistemas locales.
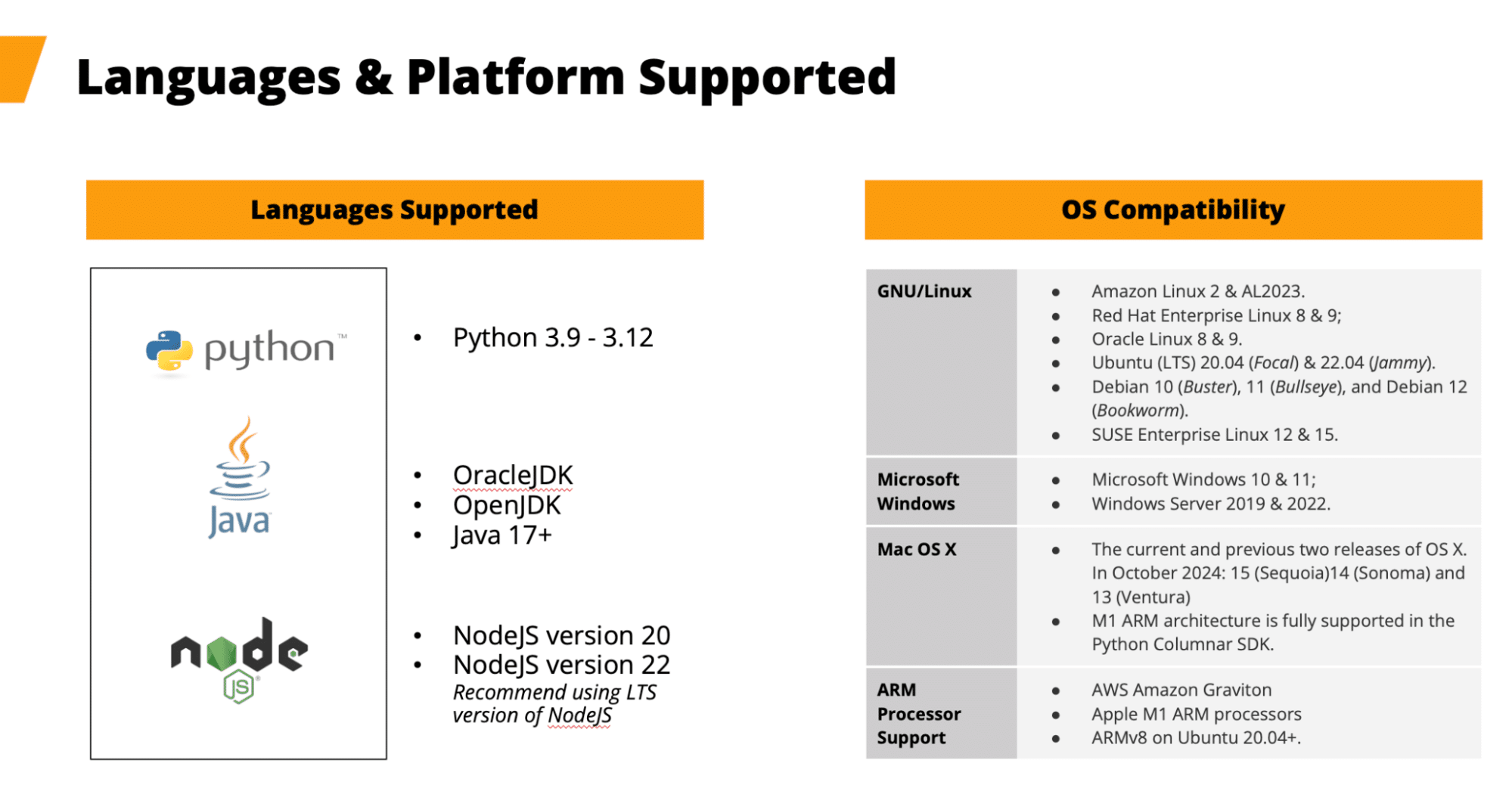
Figura 2. Consulte la documentación del SDK para conocer cualquier cambio en el soporte de idiomas/plataformas
Couchbase da prioridad a la preparación para el futuro manteniendo la compatibilidad con versiones anteriores del SDK, lo que permite a los desarrolladores actualizar sus aplicaciones sin temor a romper los cambios. Este compromiso garantiza que, a medida que se introducen nuevas características y mejoras, las funcionalidades existentes permanecen intactas, lo que permite a las organizaciones aprovechar las últimas capacidades al tiempo que preservan sus flujos de trabajo establecidos.
Cómo ayudan los SDK Columnar de Capella a los datos maestros a escala
En SDK de columnas de Couchbase Capella ofrecen un completo conjunto de herramientas para gestionar eficazmente el análisis de datos a gran escala, centrándose en la coherencia, el rendimiento y la escalabilidad.
He aquí un resumen de las principales características:
API unificada en todos los idiomas
Los SDK de Capella Columnar proporcionan un API coherente en idiomas como Java, Pythony Node.jssimplificando la colaboración entre equipos y permitiendo a los desarrolladores cambiar de un idioma a otro manteniendo una experiencia de desarrollo unificada.
Gestión de datos y ejecución de consultas simplificadas
Estos SDK ofrecen un acceso intuitivo a ámbitos y coleccionescon soporte tanto para llamadas a la API síncronas y asíncronas. Para la ejecución de consultas, permiten consultas SQL++ flexibles con opciones para Lecturas con búfer (para conjuntos de datos en memoria) y Lecturas en streaming (para el procesamiento en tiempo real de grandes conjuntos de datos), optimizando el rendimiento en función de las necesidades operativas.
Gestión de conexiones resistentes y tratamiento de errores
Los SDK se ajustan automáticamente a cambios en la topología de la base de datos, garantizando un funcionamiento sin problemas durante failovers o reequilibra. También cuentan con reintentos automáticos de consulta y proporcionar borrar mensajes de error alineado con Couchbase Códigos de error de Analytics para ayudar a resolver rápidamente los problemas.
Compatibilidad multiplataforma y flexibilidad de versiones
Con soporte para múltiples entornos como Linux, Windows, MacOSy Procesadores ARMLos SDK ofrecen flexibilidad en todas las infraestructuras. Su sitio marco de API versionada garantiza la compatibilidad con las nuevas funciones de Couchbase, lo que permite a los desarrolladores integrar las actualizaciones sin problemas de compatibilidad.
Escalabilidad y arquitectura distribuida
Los SDK de Capella Columnar aprovechan la tecnología de Couchbase arquitectura distribuida para la partición automática de datos y Replicación entre centros de datos (XDCR). Esto permite un escalado sin fisuras a través de múltiples nodos y regiones, garantizando alta disponibilidad y eficiente distribución mundial de datos a medida que crecen las aplicaciones.
Casos prácticos para Capella Columnar SDKs
Análisis de datos en tiempo real
Para las organizaciones que realizan análisis en tiempo real, los SDK Columnar de Capella simplifican el procesamiento de datos. Con soporte de consultas en tiempo reallos desarrolladores pueden procesar los datos entrantes fila por fila, lo que resulta perfecto para situaciones como las siguientes análisis de registros, Datos de sensores IoTo transacciones financieras en tiempo real.
Ejemplo de uso de la orientación publicitaria
Un caso de uso de análisis en tiempo real con los SDK de Capella Columnar podría implicar la integración de datos de flujo de clics o interacción web desde, por ejemplo, un bucket de S3 para impulsar la entrega de anuncios justo a tiempo. En este escenario, los datos de flujo de clics, que capturan las interacciones del usuario en tiempo real en un sitio web, se transmiten a Capella Columnar mediante configuraciones de enlaces externos. Los SDK permiten una consulta rápida y eficiente de estos datos a medida que llegan, utilizando consultas SQL++ flexibles para analizar el comportamiento del usuario sobre la marcha.
Al mismo tiempo, los datos de perfil de usuario almacenados en una base de datos NoSQL o relacional se introducen en el sistema a través de conectores Kafka, lo que permite una visión unificada de las preferencias y el historial de cada usuario. Combinando estos flujos de datos con el código utilizado en los SDK de Columnar, las empresas pueden optimizar su estrategia de segmentación publicitaria, ofreciendo anuncios personalizados basados en las últimas interacciones y preferencias históricas del usuario, todo ello procesado rápidamente y a escala utilizando la arquitectura distribuida de Capella Columnar.
Los modelos de ciencia de datos podrían aplicarse utilizando otras herramientas, para encontrar tendencias y construir resultados analíticos que impulsen experiencias adecuadas para el usuario final. Esto permite ofrecer anuncios oportunos y relevantes, maximizando el compromiso y las tasas de conversión a través de aplicaciones creadas en los SDK.
Tratamiento de datos por lotes
Para cargas de trabajo analíticas más tradicionales en las que los datos se procesan en masa, el modo de consulta en búfer garantiza un uso eficiente de la memoria durante la carga de conjuntos de datos en memoria. Casos de uso como Procesos ETL, inteligencia empresarialy almacenamiento de datos pueden beneficiarse de esta capacidad. Gracias a la potencia de SQL++, las herramientas de BI pueden extraer rápidamente información de gran valor sin necesidad de recurrir a tantas herramientas analíticas de terceros.
Operaciones de datos entre idiomas
En API unificada permite a los equipos de desarrollo cambiar fácilmente de un lenguaje de programación a otro sin necesidad de aprender nuevos patrones. Esto es especialmente útil para los equipos que trabajan en arquitecturas de microserviciosdonde los distintos componentes pueden estar escritos en lenguajes diferentes (por ejemplo, Java para los servicios backend, Node.js para las API en tiempo real).
Panorama técnico: primeros pasos
Para que te hagas una idea de lo fácil que es empezar a utilizar todos los SDKs de Capella Columnar, aquí tienes un ejemplo de conexión a un cluster de Capella Columnar utilizando el comando SDK de PythonVer la documentación de Java y Node.js ejemplos:

Figura 3. Ejemplo de código de gestión de conexiones en Python
El proceso es similar en todos los todos los SDKgarantizando una experiencia coherente con independencia del idioma. Una vez conectado, puede ejecutar consultas SQL, gestionar ámbitos y trabajar con colecciones.
Ejecución asíncrona de consultas
El SDK de Python es compatible con las APIs de Streaming Sync y Async. Las aplicaciones que necesitan operaciones no bloqueantes también pueden realizar consultas asíncronas utilizando la API de Python asyncio framework. Esto permite ejecutar consultas sin esperar a que finalicen, lo que aumenta el rendimiento, especialmente cuando se manejan grandes conjuntos de datos u operaciones lentas. Este ejemplo también muestra el acceso a datos en buffer frente al streaming.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from acouchbase_columnar import get_event_loop from acouchbase_columnar.cluster import AsyncCluster query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM `travel-sample`.inventory.route GROUP BY airline ORDER BY route_count DESC """ res = await cluster.execute_query(query) # Buffered: Execute a query and buffer all result rows in client memory. all_rows = await res.get_all_rows() # NOTE: all_rows is a list, _do not_ use `async for` for row in all_rows: print(f'Found row: {row}') # Streaming: Execute a query and process rows as they arrive from server. res = await cluster.execute_query(statement) async for row in res.rows(): print(f'Found row: {row}') |
En este ejemplo, el asyncio se utiliza para gestionar consultas de forma asíncrona, lo que permite a la aplicación realizar otras tareas mientras espera los resultados de la consulta.
Consultas parametrizadas
Las consultas parametrizadas ayudan a proteger su aplicación de Ataques de inyección SQL separando la lógica de consulta de la entrada de datos. Esto es especialmente importante cuando se manejan datos proporcionados por el usuario.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Positional Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$1 AND distance>=$2 GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(positional_parameters=['SFO', 1000])) # Named Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$source_airport AND distance>=$min_distance GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(named_parameters={'source_airport': 'SFO', 'min_distance': 1000})) |
En este ejemplo, pasamos el código del aeropuerto como parámetro, lo que garantiza que la consulta sigue siendo segura y evita los riesgos asociados a la inyección SQL.
Utilización de los resultados de las consultas en las bibliotecas de análisis de datos
Couchbase Columnar SDK se integra a la perfección con las bibliotecas de análisis de datos más populares de Python, como Pandas y PyArrowLas herramientas de análisis de datos son las preferidas para la ciencia de datos y los proyectos de IA/ML, lo que facilita la incorporación de los resultados de las consultas al flujo de trabajo analítico.
Importación de los resultados de la consulta a un DataFrame de Pandas
Este ejemplo muestra cómo los resultados de una consulta Couchbase pueden convertirse fácilmente en Pandas DataFramesque permite manipular y explorar los datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd res = scope.execute_query(query) df = pd.DataFrame.from_records(res.rows(), index='airline') print(df.head()) # airline route_count avg_route_distance # AA 2354 2314.884359 # UA 2180 2350.365407 # DL 1981 2350.494112 # US 1960 2101.417609 # WN 1146 1397.736500 |
Importar resultados de consulta a una tabla PyArrow
Para tareas de rendimiento intensivo, los resultados de Couchbase pueden utilizarse en Tablas PyArrowque facilita el análisis en memoria y la integración con sistemas de almacenamiento en columnas.
|
1 2 3 4 5 6 7 8 9 10 |
import pyarrow as pa res = scope.execute_query(query) table = pa.Table.from_pylist(res.get_all_rows()) print(table.to_string()) # pyarrow.Table # route_count: int64 # avg_route_distance: double # airline: string |
Al ser compatible con las bibliotecas Pandas y PyArrow, el SDK Python de Couchbase Columnar simplifica la integración en los procesos existentes de ciencia de datos y análisis de datos, permitiendo un análisis y procesamiento de datos eficientes.
Estos ejemplos muestran cómo ejecutar consultas en buffer, streaming, asíncronas y parametrizadas usando los SDKs de Couchbase, lo que le permite adaptar la ejecución de consultas a los requisitos de su aplicación.
Conclusión
Los SDK de Capella Columnar son un potente complemento para los desarrolladores que trabajan con análisis de datos a gran escala. Con un sólido soporte para múltiples lenguajes, ejecución de consultas optimizada y compatibilidad multiplataforma, estos SDK proporcionan la flexibilidad, el rendimiento y la fiabilidad necesarios para manejar las cargas de trabajo de datos modernas. Tanto si procesa flujos de datos en tiempo real como si ejecuta consultas analíticas complejas, los SDK de Capella Columnar están diseñados para mejorar su experiencia de desarrollo.
Explore las posibilidades y empiece a crear aplicaciones más inteligentes y rápidas con Capella Columnar hoy mismo.
Recursos
-
- Documentación e instrucciones de instalación: Python – Node.js – Java
- Más información Capella Columnar y sus casos de uso
- Empieza a utilizar Capella, gratis, hoy mismo: inscríbete