Esta semana nuestro Blog de escritura comunitaria viene de Nick Cadenhead

Nick Formado originalmente como ingeniero de software, ha dedicado los últimos 15 años a utilizar sus conocimientos técnicos para prestar servicios de consultoría especializada en cuentas clave. Actualmente es Consultor Senior en 9º BIT ConsultingNick es responsable de apoyar al equipo de ventas en el desarrollo de nuevas cuentas y en el mantenimiento de los clientes y socios actuales, proporcionando asistencia preventa y posventa, incluidos servicios profesionales.
Las áreas de especialización de Nick son la integración de middleware, la gestión de reglas empresariales y la inteligencia empresarial (BI), centradas específicamente en presentaciones y demostraciones, la realización de pruebas de concepto y proyectos piloto, así como la asistencia técnica. Le gusta establecer relaciones estratégicas y utiliza sus amplios conocimientos técnicos para ayudar a los clientes a sacar el máximo partido de su inversión. Durante algún tiempo, he estado trabajando con Couchbase Base de datos NoSQL y hasta ahora ha sido un viaje interesante.
Históricamente, no soy un experto en bases de datos, así que no he trabajado mucho con ellas en términos de diseño, construcción y mantenimiento como trabajo a tiempo completo. Sin embargo, conozco los conceptos básicos. Este puesto me ha permitido entrar en la "mentalidad" de Base de datos NoSQL conceptos como no estructuras, no transacciones, desnormalización de datos y más sin tener muchas situaciones conflictivas con los paradigmas del mundo estructurado de SQL y las bases de datos relacionales.
Durante mis actividades de ingeniería de ventas de apoyo a Couchbase prueba de conceptos (POC), siempre existe la necesidad de ingerir datos de forma Cubo Couchbase (piensa en un bucket como una base de datos relacional) para demostrar y destacar las características y capacidades de Couchbase. Normalmente la ingesta de datos requiere que se escriba algún código para ingerir datos en Couchbase. Couchbase proporciona bastantes SDKs (Java, .Net, Node JS y más) para que los desarrolladores habiliten sus aplicaciones para usar Couchbase.
Así que esto me hizo pensar. ¿Por qué no puede haber una forma estándar o una herramienta para ingerir datos en Couchbase en lugar de escribir código todo el tiempo? No me malinterpretes. No hay nada malo en escribir código.
Entonces me encontré con Streamsets.
Streamsets es una plataforma de código abierto para la ingestión de datos en flujo y por lotes en grandes almacenes de datos. Dispone de una consola gráfica basada en web que permite configurar las "tuberías" de datos para gestionar los flujos de datos de origen a destino, supervisar las métricas de flujo de datos en tiempo de ejecución y automatizar la gestión de la desviación de datos.
Los conductos de datos se construyen en la consola web mediante un proceso de arrastrar y soltar. Los conductos se conectan a los orígenes (fuentes) e introducen los datos en los destinos (metas). Entre los orígenes y los destinos hay pasos de procesador que son esencialmente pasos de transformación de datos para enmascarar campos, evaluar campos, buscar datos en una base de datos o en servicios externos en la nube como Salesforce.com, realizar expresiones en campos para enrutar datos, evaluar/manipular datos utilizando JavaScript, Groovy y muchos más.
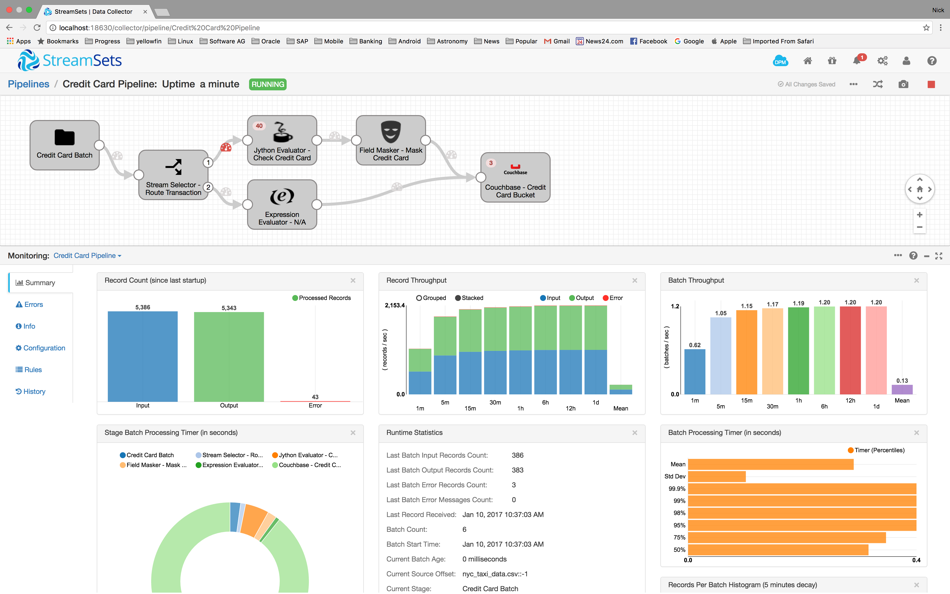
Figura 1: Un canal de Streamset ingiriendo datos en un bucket de Couchbase
Así Streamsets es una gran opción para mis necesidades de ingesta de datos. Es de código abierto y está disponible para su descarga inmediata. Hay un gran número de tecnologías soportadas para la ingesta de datos que van desde bases de datos a archivos planos, registros, servicios HTTP y plataformas de big data como Hadoop, MongoDB y plataformas en la nube como Salesforce.com. Pero había un problema. Couchbase no está en la lista de conectores de datos tecnológicos disponibles para Streamsets. ¡Ningún problema! Decidí escribir mi propio conector de datos para Couchbase.
Aprovechando el conector de datos basado en Java API disponible para la comunidad abierta para ampliar las capacidades de integración de Streamsets, junto con la documentación en línea y guías, he sido capaz de implementar un conector de datos muy rápidamente para Couchbase. La construcción inicial del conector es muy simple; sólo ingesta de datos JSON en un archivo Couchbase bucket. Con el tiempo el conector se ampliará para consultar un cubo Couchbase, mejores capacidades de ingestión y más. Por ahora, sirve a mis necesidades.
Una de las ventajas añadidas de Streamsets es el análisis del flujo de datos. Las funciones de análisis de la consola de Streamsets ofrecen a los usuarios una visión de cómo fluyen los datos desde los orígenes hasta los destinos. Las visualizaciones estándar de la consola de Streamsets ofrecen un análisis detallado del rendimiento de la canalización de datos. El análisis de la canalización me mostró muy rápidamente cómo se estaban ingiriendo mis datos en los buckets de Couchbase y resaltó cualquier error que se produjera a lo largo de las etapas de la canalización de datos. Así que mediante el uso de canalizaciones de datos en Streamsets, me permiten ingerir datos muy rápidamente en Couchbase sin escribir mucho o ningún código en absoluto.
El conector de datos está abierto y puede encontrarse en la siguiente dirección Enlace Git Hub: