Como ingeniero de campo, trabajo con clientes y a menudo veo que utilizan Couchbase con un enfoque "creativo".
Una de esas funciones que veo que se utiliza de forma más creativa es Índice Secundario Global (IGS) particiones. Hablemos primero de GSI y de las consultas y luego de las particiones para ponernos al día.
¿Qué es un índice secundario global?
Según la documentación de Couchbase, un Índice Secundario Global (GSI) apoya las consultas realizadas por el Servicio de consulta en los atributos de los documentos. Permite un filtrado exhaustivo.
Los índices secundarios globales proporcionan lo siguiente:
-
- Escalado avanzado: Los GSI pueden asignarse independientemente a nodos seleccionados sin que las cargas de trabajo existentes se vean afectadas.
- Rendimiento predecible: Las operaciones basadas en claves mantienen una baja latencia predecible, incluso en presencia de un gran número de índices. El mantenimiento de índices no compite con las operaciones basadas en claves, incluso cuando las cargas de trabajo de mutación de datos son elevadas.
- Consultas de baja latencia: Los GSI realizan particiones independientes en los nodos Index Service: No tienen que seguir la partición hash de datos en vBuckets. Las consultas que utilizan GSI pueden lograr tiempos de respuesta de baja latencia incluso cuando el clúster se amplía, ya que los GSI no requieren una amplia distribución a todos los nodos de servicio de datos.
- Partición independiente: El Servicio de Índices proporciona independencia de particiones: Los datos y sus índices pueden tener diferentes claves de partición. Cada índice puede tener su propia clave de partición, por lo que cada uno puede particionarse independientemente para ajustarse a la consulta específica. A medida que surjan nuevas necesidades, la aplicación también podrá crear un nuevo índice con una nueva clave de partición, sin que ello afecte al rendimiento de las consultas existentes.
Partición GSI
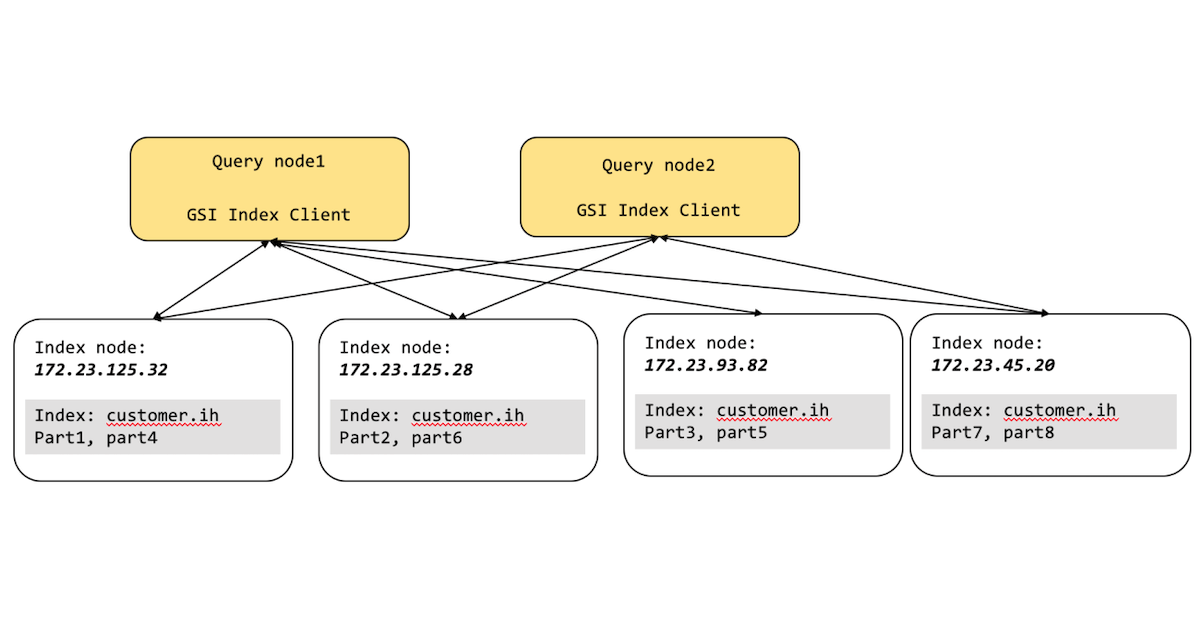
En el diagrama anterior, la orquestación de consulta a índice es manejada por el Servicio de Consulta y el Servicio de Índice sin problemas, no sólo para el desarrollador de la aplicación, sino también para el administrador de Couchbase.
La partición de índices aumenta el rendimiento de las consultas dividiendo y distribuyendo un gran índice de documentos entre varios nodos. Esta característica sólo está disponible en Couchbase Server Enterprise Edition. Los beneficios incluyen:
-
- Capacidad de ampliación horizontal a medida que aumenta el tamaño del índice.
- Transparencia en las consultas, sin necesidad de modificar las existentes.
- Reducción de la latencia de las consultas grandes y agregadas, ya que las particiones se pueden escanear en paralelo.
- Provisión de una consulta de rango de baja latencia, al tiempo que permite escalar los índices según sea necesario.
Para más información, consulte Documentación de Couchbase sobre particionamiento de índices.
El particionamiento de índices proporciona muchas funciones que facilitan la gestión de índices, como se ha mencionado anteriormente, pero ¿por qué no utilizar el particionamiento de índices para más que la simple partición?
Más información sobre la partición de índices
En esta entrada de blog, nos centraremos en casos de uso básicos, pero PARTICIÓN POR HASH es una característica muy poderosa que puede ser dirigida y cuantificada para el tamaño del índice y el rendimiento.
El particionamiento de índices ofrece muchas posibilidades para personalizar los índices con el fin de gestionar el almacenamiento, el rendimiento o la escalabilidad.
La forma más sencilla de crear un índice particionado es utilizar la clave de documento como clave de partición:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX idx_pe1 ON `travel-sample`(country, airline, id) PARTITION BY HASH(META().id); SELECT airline, id FROM `travel-sample` WHERE country="United States" ORDER BY airline; |
Con meta().id como clave de partición, las claves de índice se distribuirán uniformemente entre todas las particiones. Cada consulta reunirá las claves de índice cualificadas de todas las particiones.
Selección de claves de partición para la consulta de rangos
Una aplicación también tiene la opción de elegir la clave de partición que puede minimizar la latencia en la consulta de rango para el índice particionado.
Por ejemplo, supongamos que una consulta tiene un predicado de igualdad basado en el campo fuenteaeropuerto y destinoaeropuerto. Si el índice también está particionado por las claves de índice en fuenteaeropuerto y destinoaeropuertoentonces la consulta sólo necesitará leer una única partición para el par dado de fuenteaeropuerto y destinoaeropuerto.
En este caso, la aplicación puede mantener una latencia de consulta baja, al tiempo que permite que el índice particionado se amplíe según sea necesario.
Las claves de partición no tienen que ser las claves de índice principales para seleccionar particiones cualificadas. Siempre que las claves de índice principales se proporcionen junto con las claves de partición en el predicado, la consulta puede seleccionar las particiones cualificadas para el escaneo del índice. El siguiente ejemplo escaneará una única partición con un par dado de claves de índice fuenteaeropuerto y destinoaeropuerto.
Creación de un índice particionado con claves de partición que coinciden con el predicado de igualdad de la consulta:
|
1 2 3 4 5 6 7 |
# Lookup all airlines with non-stop flights from SFO to JFK CREATE INDEX idx_pe2 ON `travel-sample` (sourceairport, destinationairport,stops, airline, id) PARTITION BY HASH (sourceairport, destinationairport); SELECT airline, id FROM `travel-sample` WHERE sourceairport="SFO" AND destinationairport="JFK" AND stops == 0 ORDER BY airline; |
Número de particiones
El número de particiones del índice se fija cuando se crea el índice.
Por defecto, cada índice tendrá ocho particiones. El administrador puede anular el número de particiones en creación de índices tiempo.
Colocación de particiones
Cuando se crea un índice particionado, las particiones se delinean a través de los nodos de índice disponibles. Durante la colocación del nuevo índice, el indexador asumirá que cada partición tiene el mismo tamaño, y colocará las particiones según la disponibilidad de recursos en cada nodo.
Por ejemplo, si un nodo indexador tiene más memoria libre disponible que los otros nodos, asignará más particiones a este nodo indexador. Si el índice tiene una réplica, la partición de la réplica no se colocará en el mismo nodo.
Alternativamente, los usuarios pueden especificar la lista de nodos para restringir el conjunto de nodos disponibles para la colocación, utilizando un comando similar al siguiente ejemplo:
Creación de un índice particionado en puertos específicos de un nodo:
|
1 |
CREATE INDEX idx_pe12 ON `travel-sample`(airline, sourceairport, destinationairport) PARTITION BY KEY(airline) WITH {"nodes":["127.0.0.1:9001", "127.0.0.1:9002"]}; |
Dado que hay casos en los que los índices pueden ser mayores de lo que el nodo puede almacenar, la intención original de la partición de índices era escalar índices "grandes" a través de múltiples particiones, es decir, nodos, en un clúster.
Pero algunos clientes ven las particiones GSI de otra manera.
Un caso que estoy viendo con más frecuencia es el uso del particionamiento como distribución de la carga de trabajo entre nodos. Los índices en sí no son grandes, pero repartir todas las particiones indexadas entre varios nodos aprovecha la arquitectura del particionado, donde los índices se pueden escanear en paralelo. Esto distribuirá uniformemente el escaneo de índices a través de todas las particiones/nodos en lugar de sólo uno.
Algunos clientes incluso colocan juntos servicios como Data, Index y Query y no ven ninguna degradación del rendimiento en comparación con el aislamiento de servicios como Index/Query en nodos separados. Una advertencia a este enfoque es asegurarse de que hay suficiente CPU, memoria y espacio en disco para que todos estos servicios se ejecuten junto con el propio sistema operativo.
Los servicios de datos e índices están limitados por la memoria y las cuotas se definen a través de la configuración del clúster. El servicio de Consulta no está limitado por la memoria pero la utilizará. El administrador de Couchbase deberá tener en cuenta la memoria disponible y las cuotas para los servicios de datos e índices, así como reservar suficiente memoria libre para el servicio de consultas y el sistema operativo.
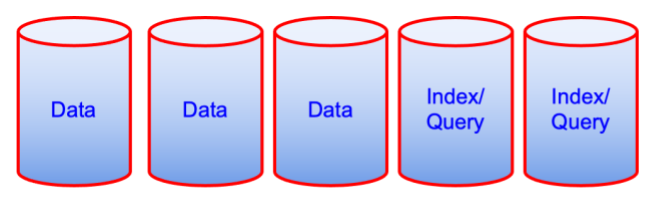
Antes de
En
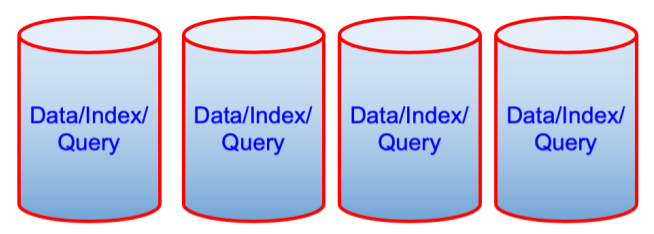
El par de diagramas anteriores puede parecer contraintuitivo desde el punto de vista del rendimiento, pero desde el punto de vista del coste de propiedad, es una máquina menos. A veces eso es un factor determinante.
¿Qué otras estrategias de particionamiento existen? Normalmente, las consultas se rigen por la latencia y el rendimiento, pero también por los SLA y las particularidades de su caso de uso. Por ejemplo, algunos clientes ejecutan una consulta una o dos veces al día para elaborar informes. ¿Es necesario que sea de alto rendimiento? La verdad es que no. ¿Cuál es la mejor estrategia para este tipo de consulta?
Digamos que hay 20 consultas con diferentes DONDE por ejemplo, una consulta para saber cuántas facturas se generan al día en un lugar determinado. ¿Es prudente crear 20 índices diferentes para cada ubicación para la consulta de facturas? ¿Y si hay otras consultas que utilizarán los mismos datos en su conjunto (es decir, datos redundantes)? Tal vez algunos de los datos sean específicos de un país, y 10 de las ubicaciones se encuentren en el mismo país.
Si se tratara de una consulta que se ejecuta con frecuencia o de una parte crítica de la aplicación, como la visualización de productos, entonces un índice dedicado podría ser apropiado. Pero en este caso, quizás un índice grande sea más eficiente en cuanto a almacenamiento y recursos. Por lo tanto, las particiones de índices serían más apropiadas.
Segregación de responsabilidades de mando y consulta (CQRS)
Otro uso más eficaz de las particiones son las cargas de trabajo con mucha escritura, en las que las escrituras dominan las operaciones. Un patrón es la segregación de responsabilidad de comandos y consultas (CQRS).
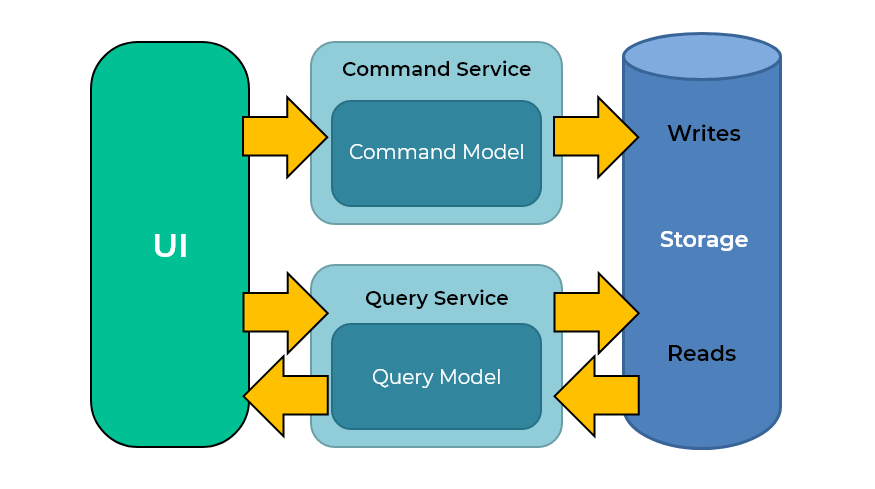
Aquí es donde muchos documentos se escriben en una base de datos y requieren una consulta rápida. Por lo general, se trata de eventos de la aplicación, como la interacción del usuario con la aplicación, los clics, etc. Estos eventos se escriben en grandes volúmenes y se consultan con frecuencia. Con la partición de índices, el equilibrio de la escritura de las claves de los documentos en el índice no se aísla en un nodo, sino que se distribuye entre los nodos del índice. CQRS es un buen caso de uso para las particiones de índices.
Conclusión
Hemos cubierto sólo unos pocos usos de la partición del Índice Secundario Global. Es una de las características más infravaloradas e infrautilizadas de GSI que podría ajustarse para casos de uso específicos.
Más información Índices secundarios globales (GSI) en la documentación de Couchbase.
