Couchbase y XML: ¡sin problemas!
Lo he oído decir docenas de veces: "Oye, Couchbase es genial pero yo uso XML".
Reconozco que rebatir con "Couchbase puede ser tu base de datos XML" es bastante atrevido, especialmente para una base de datos de documentos orientada a JSON. Puede que algunos miembros de la comunidad de Couchbase se lo tomen a mal, pero espero que entiendas lo que quiero decir al final de este post.
Es un hecho que muchas aplicaciones heredadas todavía dependen de XML, pero ¿es Couchbase realmente la solución adecuada para almacenar y procesar tus datos XML? No te preocupes: con respecto a Couchbase y XML puedes tener tu pastel y comértelo también.
Después de introducir algunos conceptos, este artículo te muestra cómo convertir automática e instantáneamente XML en equivalentes JSON dentro de Couchbase con casi cero esfuerzo - todo a través de una función Eventing. Si sólo piensas en JSON como el formato informático intermedio que se utiliza para almacenar tu XML, puede que ya veas a dónde me dirijo.
Cuando transformas tus datos XML en una representación JSON nativa, aprovechas el rico ecosistema de servicios de Couchbase, que incluye N1QLIndexación, Búsqueda de texto completo, Eventosy Analítica.
Couchbase es una base de datos creada específicamente para que la adaptes a tus necesidades. ¿Sólo necesitas una caché rápida? Sólo necesita el servicio de datos o el almacén de valores clave. ¿Desea un acceso de tipo SQL? Añada los servicios de consulta e índice. ¿O tal vez necesite Analytics o Full-Text Search? Sólo tiene que añadir algunos nodos del tipo adecuado.
Cada uno de los servicios anteriores escala de forma independiente para que acabes construyendo, y lo que es más importante, pagando por - sólo lo que necesitas. En el siguiente artículo, utilizo Eventing para transformar Couchbase en una base de datos compatible con XML. Sé que suena demasiado bien para ser verdad, pero créeme que realmente funciona.
Si está familiarizado con Couchbase, XML y JSON, no dude en pase a la sección Requisitos previos.
El modelo de datos de Couchbase
Servidor Couchbase es una plataforma de datos distribuidos de código abierto. Almacena datos como artículoscada uno de los cuales tiene un clave y un valor. Las operaciones de datos en menos de un milisegundo se realizan mediante potentes servicios de consulta e indexación, así como un lenguaje de consulta orientado a documentos y repleto de funciones, N1QL. Múltiples instancias de Couchbase Server pueden combinarse en una sola. grupo.
Claves
Cada valor (binario o JSON) se identifica mediante una clave única, definida por el usuario o la aplicación al guardar el elemento. La clave es inmutable: una vez guardado el ítem, la clave no puede ser cambiada. Ten en cuenta que Couchbase también se refiere a la clave de un ítem como su id.
Cada llave:
-
- Debe ser una cadena UTF-8 sin espacios. Los caracteres especiales, como
(,%,/,"y_son aceptables. - No puede superar los 250 bytes.
- Debe ser único dentro de su cubo.
- Debe ser una cadena UTF-8 sin espacios. Los caracteres especiales, como
Valores
El tamaño máximo de un valor es de 20 MiB. Un valor puede ser:
-
- Binario: Se acepta cualquier forma de binario. Tenga en cuenta que un valor binario no se puede analizar, indexar ni consultar. Sólo se puede recuperar por clave.
- JSON: Un valor JSON, denominado documentopueden ser analizados, indexados y consultados. Cada documento consta de uno o varios atributos, cada uno de los cuales tiene su propio valor. El valor de un atributo puede ser de tipo básico -como un número, una cadena o un booleano- o complejo, como un documento incrustado o una matriz.
JSON es la base de datos
Hablemos más sobre JSON. Puedes analizar, indexar, consultar y manipular documentos JSON. De hecho, Couchbase introdujo el lenguaje de consulta N1QL (pronunciado "nickel") para satisfacer las necesidades de consulta de las bases de datos distribuidas orientadas a documentos. N1QL se utiliza para manipular los datos JSON en Couchbase, igual que SQL manipula los datos en una base de datos relacional (RDBMS). Dispone de SELECCIONE, INSERTAR, ACTUALIZACIÓN, BORRAR y FUSIONAR para operar con datos JSON.
Podrías almacenar XML como una cadena o como un bloque binario, pero ¿dónde está la gracia o la utilidad? ¿Por qué no convertir automáticamente el XML en JSON? Me alegro de que lo preguntes.
XML: Lenguaje de marcado extensible
XML es un lenguaje de marcado introducido en 1996 que define un conjunto de reglas para codificar documentos en un formato legible tanto por humanos como por máquinas. Es una recomendación del Consorcio World Wide Web (W3C).
Los objetivos de diseño de XML hacen hincapié en la simplicidad, la generalidad y la facilidad de uso en Internet. Se trata de un formato de datos textuales con fuerte soporte a través de Unicode para diferentes lenguajes humanos. Aunque el diseño de XML se centra en los documentos, el lenguaje se utiliza ampliamente para la representación de estructuras de datos arbitrarias, como las empleadas en los servicios web.
He aquí un ejemplo de XML:
|
1 2 3 4 5 6 7 8 |
<CD> <TITLE>EmpireBurlesque</TITLE> <ARTIST>BobDylan</ARTIST> <COUNTRY>USA</COUNTRY> <COMPANY>Columbia</COMPANY> <PRICE>10.90</PRICE> <YEAR>1985</YEAR> </CD> |
JSON: Notación de objetos de JavaScript
Creado hacia 2001, JSON es un formato de archivo estándar abierto bastante ligero y un formato de intercambio de datos que utiliza texto legible por humanos para almacenar y transmitir objetos de datos consistentes en pares atributo-valor y matrices (u otros valores serializables).
JSON es un formato de datos muy común, con una diversa gama de aplicaciones, un ejemplo son las aplicaciones web que se comunican con un servidor.
He aquí una muestra de JSON:
|
1 2 3 4 5 6 7 |
{ "email": "testme@example.org", "friends": [ {"name": "rick"}, {"name": "cate"} ] } |
JSON se ha apoderado del mundo
Hoy en día, cuando dos aplicaciones cualesquiera se comunican entre sí a través de Internet, lo más probable es que lo hagan utilizando JSON, especialmente si se comunican en texto legible por humanos.

Si eres un fan de XML, no dispares al mensajero aquí. Estoy seguro de que XML nunca desaparecerá, dado que HTML es un lenguaje de marcado, pero me gusta pensar que las estadísticas no mienten cuando se trata de desarrollar aplicaciones de Internet que necesitan comunicarse entre sí.
Requisitos previos: Aprendizaje del concurso completo
En este artículo vamos a utilizar la última versión de Couchbase - versión 6.6.2 - sin embargo, debería funcionar bien en versiones anteriores también.
Si no estás familiarizado con Couchbase o el servicio Eventing, por favor, consulta los siguientes recursos, incluyendo al menos un ejemplo de Eventing:
-
- Configurar un servidor Couchbase 6.6.2 en funcionamiento siguiendo las instrucciones de "¡Empieza aquí!".
- Comprender cómo desplegar una función básica de Eventing como según las instrucciones del ejemplo de enriquecimiento de datos. Observe el "Caso 2", en el que sólo utilizaremos el cubo "fuente".
- Asegúrese de tener un fuente de al menos 100 MB en la vista de cubos de la interfaz de usuario.
- Asegúrese de que un cubo llamado metadatos de al menos 100 MB en la vista Buckets de la interfaz de usuario.
- Consulte la documentación de pasos detallados para crear un cubo.
Inserción de XML en Couchbase
Ahora deberías tener una aplicación que cargue datos, o puede que hayas utilizado cbimport para cargar tus datos XML en tu cluster Couchbase.
En el código siguiente, cargo mi primer documento con una etiqueta clave xml::1 y un cuerpo consistente en un tipo y el id utilizados en la clave (estos valores son opcionales pero útiles) y, por último, una propiedad in_xml que contiene la propia cadena XML.
|
1 2 3 4 5 |
{ "type": "xml", "id": 1, "in_xml": "<CD><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>" } |
No podemos hacer demasiado con la cadena XML anterior. Claro, podríamos indexar la propiedad in_xml como cadena, pero no obtendremos mucho rendimiento haciendo esto a menos que utilicemos una búsqueda por prefijo, que en mi humilde opinión, lo más probable es que no sirva para nada.
Podríamos pasarlo al producto Full-Text Search (FTS). En este caso, obtendría más utilidad, pero tendría que indexar toda la carga útil XML (no sólo algo importante).
Lo que realmente queremos es la representación JSON de la propiedad XML string in_xmlquizás algo como:
|
1 2 3 4 5 6 7 8 9 10 |
"out_json": { "CD": { "TITLE": "EmpireBurlesque", "ARTIST": "BobDylan", "COUNTRY": "USA", "COMPANY": "Columbia", "PRICE": "10.90", "YEAR": "1985" } } |
Utilización de la nueva propiedad out_jsonAhora vemos las propiedades JSON individuales en una estructura adecuada: algo con lo que N1QL, Indexación, Búsqueda de Texto Completo (FTS), Eventos y Análisis trabajan de forma nativa y eficiente.
Con estos pasos preliminares tras nosotros, podrías pensar en simplemente parsear tus datos y transformarlos a JSON antes de ponerlos en Couchbase. Pero el inconveniente es que ahora tenemos más equipaje que transportar y más infraestructura (fuera de Couchbase) que desplegar a medida que escalamos añadiendo más nodos.
Si podemos evitarlo, no queremos escribir un analizador sintáctico personalizado. Eso no es divertido, y es difícil de mantener como sus requisitos y formatos de datos cambian con el tiempo.
Lo ideal es una solución en el servidor que convierta genéricamente XML a JSON en tiempo real sin afectar a los cargadores de datos.
Conversión de XML a JSON sobre la marcha
Introduzca el servicio de eventos de Couchbase.
Piense en Eventing como un "post trigger" en un documento que responde a cada cambio (o mutación) en sus datos. La idea principal es que cada vez que inserte o actualice su documento (consulte xml::1 arriba) un pequeño fragmento de JavaScript, o lambda, se ejecuta contra el documento y encapsula la lógica de negocio necesaria para manipular el documento y asegurarse de que el documento está en el formato deseado.
En este caso, queremos convertir un documento como el siguiente:
|
1 2 3 4 5 |
{ "type": "xml", "id": 1, "in_xml": "<CD><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>" } |
En tiempo real, queremos convertir el documento anterior en un documento enriquecido como el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "type": "xml", "id": 2, "in_xml": "<CD><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>", "out_json": { "CD": { "TITLE": "EmpireBurlesque", "ARTIST": "BobDylan", "COUNTRY": "USA", "COMPANY": "Columbia", "PRICE": "10.90", "YEAR": "1985" } } } |
El documento enriquecido que se muestra arriba se puede buscar mediante clave-valor o mediante un índice en cualquier campo determinado utilizando N1QL.
Al igual que antes, vemos las propiedades JSON individuales en una estructura adecuada, pero bajo la etiqueta out_json que permite utilizar eficazmente la búsqueda de texto completo (FTS), los análisis e incluso otras funciones de Eventing.
Función: convertXMLtoJSON
Eventing le permite escribir lógica de negocio pura y el servicio Eventing se encarga de toda la infraestructura necesaria para gestionar y escalar su función (horizontal y verticalmente) a través de múltiples nodos de una manera performante y fiable.
Todas las funciones de Eventing tienen dos puntos de entrada OnUpdate(doc,meta) y OnDelete(meta,opciones). Tenga en cuenta que en este ejemplo no nos preocupa este último punto de entrada.
Cuando un documento cambia o muta (insertar, upsert, reemplazar, etc.) una copia del documento y algunos metadatos sobre el documento se pasarán a un pequeño punto de entrada de JavaScript OnUpdate(doc,meta):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function OnUpdate(doc, meta) { // filter out non XML if (!meta.id.startsWith("xml:")) return; // The KEY started with "xml" try to process it // =========================================================== // *** Do other work required here on non .in_xml changes *** // =========================================================== var jsonDoc = parseXmlToJson(doc.in_xml); log(meta.id, "1. INPUT xml doc.in_xml :", doc.in_xml); log(meta.id, "2. OUTPUT doc.out_json :", jsonDoc); doc.out_json = jsonDoc; // =========================================================== // enrich the source bucket with .out_json src_bkt[meta.id] = doc; } |
En OnUpdate(doc,meta) lógica anterior realiza cuatro pasos en cualquier mutación.
-
- En primer lugar, el prefijo del clave si no empieza por
xml:no hacemos nada más. Tenga en cuenta quemeta.ides el clave del doc. - En segundo lugar, simplemente llamamos a una función
parseXmlToJson(doc.in_xml)donde simplemente pasamos la cadena XML a la función. - En tercer lugar, lo que vuelve se añade como un nuevo campo a la copia del documento como la propiedad
out_json. - En cuarto lugar, actualizamos el documento en tiempo real con la representación JSON.
- En primer lugar, el prefijo del clave si no empieza por
El núcleo de la lógica de conversión de XML a JSON
Esta es la lógica central para la conversión de XML a JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// 6.6.0 version no String.matchAll need our own MatchAll function function* MatchAll(str, regExp) { if (!regExp.global) { throw new TypeError('Flag /g must be set!'); } const localCopy = new RegExp(regExp, regExp.flags); let match; while (match = localCopy.exec(str)) { yield match; } } // A simple XML to JSON parser function parseXmlToJson(xml) { const json = {}; for (const res of MatchAll(xml,/(?:<(\w*)(?:\s[^>]*)*>)((?:(?!<\1).)*)(?:<\/\1>)|<(\w*)(?:\s*)*\/>/gm)) { const key = res[1] || res[3]; const value = res[2] && parseXmlToJson(res[2]); json[key] = ((value && Object.keys(value).length) ? value : res[2]) || null; } return json; } |
Gracias al usuario Pieza maestra en Stack Overflow por compartir el método parseXmlToJson(xml) con el mundo. El método utiliza una expresión regular genial sobre la cadena XML y devuelve un objeto JSON de primera clase. (Sí, funciona y es a la vez elegante y compacto.)
Tenga en cuenta que en Couchbase 7.0 el método MatchAll(str, regExp) en nuestro código JavaScript anterior es no necesario porque Couchbase ahora tiene un corredor v8 más actual que incluye el String.prototype.MatchAll() función.
Optimicemos la función Eventing
Lo que tenemos hasta ahora funciona bien, pero hay un problema.
Suponga que sus datos tienen 100.000 mutaciones por segundo, todas con un clave prefijo de xml:. Aunque el in_xml nunca cambia, nuestra función Eventing actual a) realizará 100.000 conversiones de XML a JSON y b) realizará 100.000 escrituras en el servicio de datos (o almacén de valores clave). Además, lo más probable es que tu XML sea mucho más complejo que nuestro ejemplo in_xml y puede tener un anidamiento profundo y miles de campos.
Algunas reflexiones que debemos tener en cuenta:
-
- Convertir un documento XML grande y anidado mediante una rutina recursiva requiere recursos informáticos. El método
parseXmlToJson(xml)se ejecutará en cada mutación aunque el XML no haya cambiado. - Escribir en bases de datos implica E/S, y queremos ahorrar ciclos o escrituras para trabajos más importantes. Con la función Eventing actual, realizaremos una escritura o actualización del documento en el almacén de valores clave en cada mutación, incluso si el XML no ha cambiado.
- Convertir un documento XML grande y anidado mediante una rutina recursiva requiere recursos informáticos. El método
Para solucionar los problemas anteriores, vamos a añadir un poco de lógica para actualizar sólo la propiedad del documento out_xml si el in_xml cambios de datos o si no tenemos ya un out_xml propiedad.
Para llevar a cabo esta optimización, utilizaremos un suma de comprobación a través de Eventing's fast crc64() en el in_xml y almacenarlo en nuestro documento como una propiedad: xmlchksum.
Podemos entonces utilizar este campo para minimizar el trabajo extra de convertir innecesariamente XML a JSON o escribir innecesariamente un documento sin cambios en el servicio de datos.
Aquí está la optimización:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
function OnUpdate(doc, meta) { // filter out non XML if (!meta.id.startsWith("xml:")) return; // The KEY started with "xml" try to process it // =========================================================== // *** Do other work required here on non .in_xml changes *** // =========================================================== // let's see if we need to re-create our json representation. var xmlchksum = crc64(doc.in_xml); // =========================================================== // Don't reprocess if the doc.in_xml has not changed this could be // a big performance win if the doc has other fields that mutate. // We do this via a checksum of the .in_xml property. if (doc.xmlchksum && doc.xmlchksum === xmlchksum) return; // Either this is the first pass, or the .in_xml property changed. var jsonDoc = parseXmlToJson(doc.in_xml); log(meta.id,"1. INPUT xml doc.in_xml :", doc.in_xml); log(meta.id,"2. CHECKSUM doc.in_xml :", xmlchksum); log(meta.id,"3. OUTPUT doc.out_json :", jsonDoc); doc.out_json = jsonDoc; doc.xmlchksum = xmlchksum; // =========================================================== // enrich the source bucket with .out_json and .xmlchksum src_bkt[meta.id] = doc; } |
Esto es lo que hemos añadido al original OnUpdate(doc,meta) punto de entrada.
-
- En primer lugar, calculamos un
suma de comprobaciónen la cadena XML a la que se accede desdedoc.in_xml. - En segundo lugar, lo comparamos con un
suma de comprobación:doc.xmlchksum(si existe). - En tercer lugar, si el
suma de comprobaciónfalta o difiere, convertimos el XML en JSON y almacenamos tanto el nuevosuma de comprobaciónxmlchksumy elout_jsonpropiedades en el documento escribiéndolo de nuevo al Servicio de Datos.
- En primer lugar, calculamos un
La función final completa
Aquí está nuestra función completa Eventing para convertir XML a JSON con todas las optimizaciones antes mencionadas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
function OnUpdate(doc, meta) { // filter out non XML if (!meta.id.startsWith("xml:")) return; // The KEY started with "xml" try to process it // =========================================================== // *** Do other work required here on non .in_xml changes *** // =========================================================== // let's see if we need to re-create our json representation. var xmlchksum = crc64(doc.in_xml); // =========================================================== // Don't reprocess if the doc.in_xml has not changed this could be // a big performance win if the doc has other fields that mutate. // We do this via a checksum of the .in_xml property. if (doc.xmlchksum && doc.xmlchksum === xmlchksum) return; // Either this is the first pass, or the .in_xml property changed. var jsonDoc = parseXmlToJson(doc.in_xml); log(meta.id,"1. INPUT xml doc.in_xml :", doc.in_xml); log(meta.id,"2. CHECKSUM doc.in_xml :", xmlchksum); log(meta.id,"3. OUTPUT doc.out_json :", jsonDoc); doc.out_json = jsonDoc; doc.xmlchksum = xmlchksum; // =========================================================== // enrich the source bucket with .out_json and .xmlchksum src_bkt[meta.id] = doc; } // 6.6.0 version no String.matchAll need our own MatchAll function function* MatchAll(str, regExp) { if (!regExp.global) { throw new TypeError('Flag /g must be set!'); } const localCopy = new RegExp(regExp, regExp.flags); let match; while (match = localCopy.exec(str)) { yield match; } } // A simple XML to JSON parser function parseXmlToJson(xml) { const json = {}; for (const res of MatchAll(xml,/(?:<(\w*)(?:\s[^>]*)*>)((?:(?!<\1).)*)(?:<\/\1>)|<(\w*)(?:\s*)*\/>/gm)) { const key = res[1] || res[3]; const value = res[2] && parseXmlToJson(res[2]); json[key] = ((value && Object.keys(value).length) ? value : res[2]) || null; } return json; } |
Despliegue de la función de eventos
Ahora es el momento de desplegar la función Eventing. Hemos revisado un poco el código y el diseño del traductor de XML a JSON, y ahora es el momento de ver cómo funciona todo junto.
En este punto, tenemos una función en JavaScript así que necesitamos añadirla a tu cluster de Couchbase y desplegarla en un estado activo.
Este ejemplo requiere dos cubos: fuente (es decir, su almacén de documentos) y metadatos (es decir, un bloc de notas para Eventing que puede compartirse con otras funciones de Eventing). El sitio fuente debe tener un tamaño de al menos 100 MB (si desea realizar pruebas con más de 10 millones de documentos, es posible que desee hacer que el archivo fuente cubo más grande). El metadatos debe tener un tamaño mínimo de 100 MB. Ambos cubos deben existir ya como según los requisitos previos anteriores.
-
- Verifique la configuración actual de su cubo accediendo a la página Consola Web de Couchbase > Cubos página:
- Verifique la configuración actual de su cubo accediendo a la página Consola Web de Couchbase > Cubos página:
Añadir manualmente la función convertXMLtoJSON
Para añadir la primera función de Eventing desde Consola Web de Couchbase > Eventos haga clic en AÑADIR FUNCIÓNpara añadir una nueva función. La dirección AÑADIR FUNCIÓN Aparece entonces el diálogo
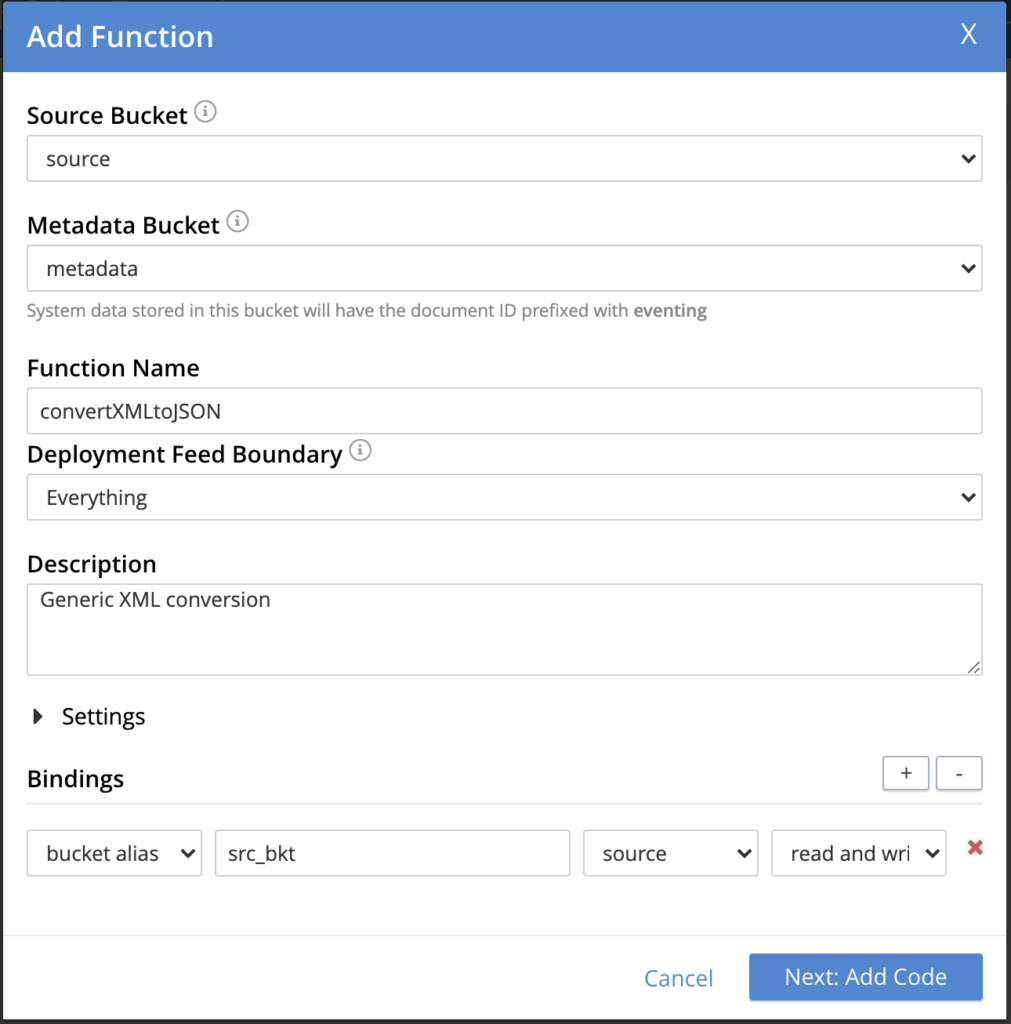
En el AÑADIR FUNCIÓN diálogo, facilite la siguiente información para cada uno de los elementos de la función:
-
-
- Para el Cubo de origen en el menú desplegable fuente.
- Para el Cubo de metadatos en el menú desplegable metadatos.
- Asegúrese de que
convertXMLtoJSONes el nombre de la función que se está creando en el directorio Nombre de la función cuadro de texto. - [Paso opcional] Introduzca el texto Conversión XML genéricaen el Descripción cuadro de texto.
- Para el Ajustes utilice los valores por defecto.
- Para el Fijaciones crear dos enlaces:
- Para la encuadernación, el alias de cubo, especifica
src_bktcomo el nombre de alias del cubo y seleccione fuente como cubo asociado, y el modo debe ser leer y escribir. - Una vez configurados los ajustes, el diálogo debería tener este aspecto:
- Tras facilitar toda la información requerida en el AÑADIR FUNCIÓN pulse Siguiente Añadir código. En
cron_impl_2func_651aparece el diálogo. La direcciónconvertXMLtoJSONcontiene inicialmente un bloque de código de marcador de posición. Tendrá que sustituir el código JavaScript que hemos desarrollado en este bloque. 
- Copie el siguiente código fuente JavaScript de la función Eventing (48 líneas) y péguelo en el bloque de código del marcador de posición de
convertXMLtoJSON:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748function OnUpdate(doc, meta) {// filter out non XMLif (!meta.id.startsWith("xml:")) return;// The KEY started with "xml" try to process it// ===========================================================// *** Do other work required here on non .in_xml changes ***// ===========================================================// let's see if we need to re-create our json representation.var xmlchksum = crc64(doc.in_xml);// ===========================================================// Don't reprocess if the doc.in_xml has not changed this could be// a big performance win if the doc has other fields that mutate.// We do this via a checksum of the .in_xml property.if (doc.xmlchksum && doc.xmlchksum === xmlchksum) return;// Either this is the first pass, or the .in_xml property changed.var jsonDoc = parseXmlToJson(doc.in_xml);log(meta.id,"1. INPUT xml doc.in_xml :", doc.in_xml);log(meta.id,"2. CHECKSUM doc.in_xml :", xmlchksum);log(meta.id,"3. OUTPUT doc.out_json :", jsonDoc);doc.out_json = jsonDoc;doc.xmlchksum = xmlchksum;// ===========================================================// enrich the source bucket with .out_json and .xmlchksumsrc_bkt[meta.id] = doc;}// 6.6.0 version no String.matchAll need our own MatchAll functionfunction* MatchAll(str, regExp) {if (!regExp.global) {throw new TypeError('Flag /g must be set!');}const localCopy = new RegExp(regExp, regExp.flags);let match;while (match = localCopy.exec(str)) {yield match;}}// A simple XML to JSON parserfunction parseXmlToJson(xml) {const json = {};for (const res of MatchAll(xml,/(?:<(\w*)(?:\s[^>]*)*>)((?:(?!<\1).)*)(?:<\/\1>)|<(\w*)(?:\s*)*\/>/gm)) {const key = res[1] || res[3];const value = res[2] && parseXmlToJson(res[2]);json[key] = ((value && Object.keys(value).length) ? value : res[2]) || null;}return json;} - Después de pegar, aparece la pantalla que se muestra a continuación:
- Haga clic en Guardar.
- Para volver a la pantalla de Eventos, pulse el botón < volver a Concurso completo (debajo del editor) o haga clic en el enlace Eventos opción.
- Para la encuadernación, el alias de cubo, especifica
-
Despliegue de la función
Ahora estamos listos para iniciar las funciones de Eventing. Desde el Consola Web de Couchbase > Eventos siga estos pasos:
-
-
-
- Haga clic en el nombre de la función
convertXMLtoJSONpara expandir y exponer los controles de función.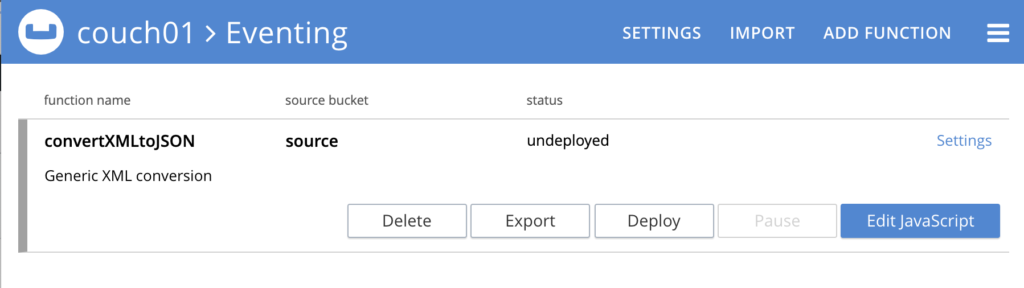
- Haga clic en Despliegue.
- En el Confirmar función de despliegue seleccione Función de despliegue de la opción Límite de alimentación.
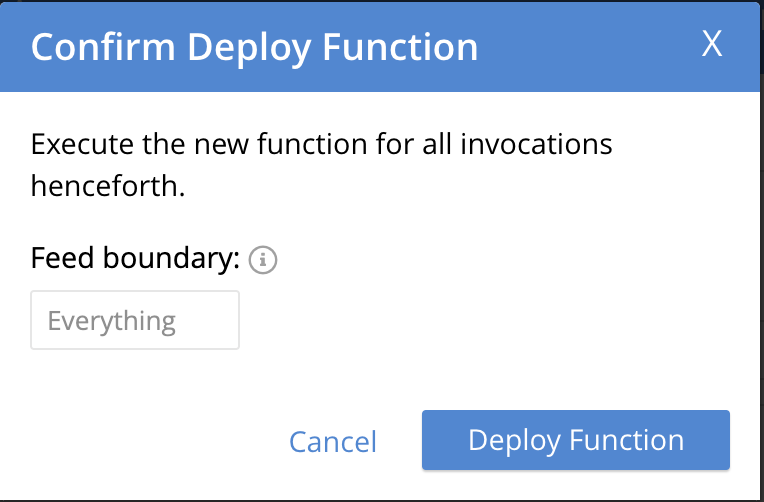
- El despliegue de su función tardará unos 18 segundos en activarse.
- Haga clic en el nombre de la función
-
-
Probar la función de marcha
En este punto tenemos una lambda en ejecución que actualizará cualquier documento con una etiqueta clave prefijo de xml: y una propiedad XML de in_xml.
Para ejercitar la función Eventing convertXMLtoJSONvaya a la página Documentos en la interfaz de usuario y haga lo siguiente:
-
-
-
- Haga clic en AÑADIR DOCUMENTO.
- Introduzca un clave de
xml::1(asegúrese de que el prefijo esxml:) - Haga clic en Guardar.
- Introduzca un cuerpo como sigue:
12345{"type": "xml","id": 1,"in_xml": "<CD><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>"} - Haga clic en Guardar.
- Edite el documento que acaba de guardar; observará que se ha actualizado en tiempo real
12345678910111213141516{"type": "xml","id": 1,"in_xml": "<CD><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>","out_json": {"CD": {"TITLE": "EmpireBurlesque","ARTIST": "BobDylan","COUNTRY": "USA","COMPANY": "Columbia","PRICE": "10.90","YEAR": "1985"}},"xmlchksum": "02087b7be275d0d8"} - Ajuste el
in_xml. Quizás añadir FEBRERO</MES antes del título.
1"in_xml": "<CD><MONTH>FEB</MONTH><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>", - Haga clic en Guardar.
- De nuevo, edite el documento que acaba de guardar. Verás que se ha vuelto a actualizar en tiempo real:
1234567891011121314151617{"type": "xml","id": 1,"in_xml": "<CD><MONTH>FEB</MONTH><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>","out_json": {"CD": {"MONTH": "FEB","TITLE": "EmpireBurlesque","ARTIST": "BobDylan","COUNTRY": "USA","COMPANY": "Columbia","PRICE": "10.90","YEAR": "1985"}},"xmlchksum": "06b5b40b276f160b"} - Añade una nueva propiedad arriba
tipocomo"otro": "esto es divertido", - Haga clic en Guardar.
- Una vez más, edite el documento. Tenga en cuenta que el
suma de comprobaciónno se actualizará
123456789101112131415161718{"other": "this is fun","type": "xml","id": 1,"in_xml": "<CD><MONTH>FEB</MONTH><TITLE>EmpireBurlesque</TITLE><ARTIST>BobDylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR></CD>","out_json": {"CD": {"MONTH": "FEB","TITLE": "EmpireBurlesque","ARTIST": "BobDylan","COUNTRY": "USA","COMPANY": "Columbia","PRICE": "10.90","YEAR": "1985"}},"xmlchksum": "06b5b40b276f160b"}
-
-
Procesemos 100.000 registros XML
Ahora que ya has visto cómo funcionan las cosas, vamos a volcar un montón de datos en la función. En primer lugar, tenemos que generar algunos datos.
-
-
-
- Utilizaré un sencillo script Perl llamado
xml_data_gen.plque escribí para esta entrada del blog:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556#!/usr/bin/perluse Getopt::Long qw(GetOptions);sub randi {($lower_limit,$upper_limit) = @_;return int(rand($upper_limit-$lower_limit)) + $lower_limit;}my $blk = 0;my $num = 0;my $help = 0;GetOptions('blk=i' => \$blk,'num=i' => \$num,'help' => \$help,) or die "Usage: $0 --blk # --num #\n";if ($num == 0 || $help != 0 || $blk < 1) {printf stderr "Usage: $0 --blk # --num #\n";printf stderr "examples:\n";printf stderr "./xml_data_gen.pl --blk 1 --num 100000 > data.json\n";printf stderr "cbimport json -c couchbase://127.0.0.1 -u \$CB_USERNAME " ."-p \$CB_PASSWORD -b source -d file://./data.json -f lines -t 4 -g xml::%%id%%\n";exit(1);}@artist = ("Elton John", "Lisa Lobb", "Sting", "Clash", "The Smiths","Bob Dylan", "The Yard Birds", "Journey", "Led Zeppelin", "Adele");@title = ("Empire Burlesque", "Greatest Hits", "Songs Vol 1.", "Songs Vol 2.","Songs Vol 3.", "Classics", "Hidden Tracks");@country = ("USA", "UK", "AU", "AR", "ES", "MO");@company = ("Columbia", "Capital", "Dog Boys", "Epic", "Home Brew", "EMG");$template = '{"type":"xml","id":_XXX_,"in_xml":"<CD><TITLE>_TTT_</TITLE>' .'<ARTIST>_AAA_</ARTIST><COUNTRY>_CCC_</COUNTRY><COMPANY>_OOO_</COMPANY>' .'<PRICE>_PPP_</PRICE><YEAR>_YYY_</YEAR></CD>"}';my $beg = 1 + ($blk-1) * $num;my $max = $beg + $num - 1;my $wrk = "";for ($j=$beg; $j<=$max; $j=$j+1) {$wrk = $template; $wrk =~ s/_XXX_/$j/;$tmp = $artist[randi(0,$#artist-1)]; $wrk =~ s/_AAA_/$tmp/;$tmp = $title[randi(0,$#title-1)]; $wrk =~ s/_TTT_/$tmp/;$tmp = $country[randi(0,$#country-1)]; $wrk =~ s/_CCC_/$tmp/;$tmp = $company[randi(0,$#company-1)]; $wrk =~ s/_OOO_/$tmp/;$tmp = randi(850,1765)/100; $wrk =~ s/_PPP_/$tmp/;$tmp = randi(1,30)+1981; $wrk =~ s/_YYY_/$tmp/;printf $wrk . "\n";} - Para probar el script generador anterior
xml_data_gen.plsimplemente corre:./xml_data_gen.pl --blk 1 --num 5 - Deberías ver algo como:
12345{"type":"xml","id":1,"in_xml":"<CD><TITLE>Songs Vol 3.</TITLE><ARTIST>Elton John</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Epic</COMPANY><PRICE>10.64</PRICE><YEAR>2003</YEAR></CD>"}{"type":"xml","id":2,"in_xml":"<CD><TITLE>Songs Vol 1.</TITLE><ARTIST>Clash</ARTIST><COUNTRY>AU</COUNTRY><COMPANY>Epic</COMPANY><PRICE>12.69</PRICE><YEAR>1989</YEAR></CD>"}{"type":"xml","id":3,"in_xml":"<CD><TITLE>Empire Burlesque</TITLE><ARTIST>Journey</ARTIST><COUNTRY>AU</COUNTRY><COMPANY>Epic</COMPANY><PRICE>15.25</PRICE><YEAR>1999</YEAR></CD>"}{"type":"xml","id":4,"in_xml":"<CD><TITLE>Songs Vol 1.</TITLE><ARTIST>Bob Dylan</ARTIST><COUNTRY>AR</COUNTRY><COMPANY>Dog Boys</COMPANY><PRICE>15.43</PRICE><YEAR>1997</YEAR></CD>"}{"type":"xml","id":5,"in_xml":"<CD><TITLE>Greatest Hits</TITLE><ARTIST>Journey</ARTIST><COUNTRY>UK</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>10.71</PRICE><YEAR>1983</YEAR></CD>"} - Para crear un registro de 100K
xml_data_gen.plpara después cargarlo en tu cluster de Couchbase sólo tienes que ejecutarlo:./xml_data_gen.pl --blk 1 --num 100000 > data.json - Ahora tenemos que cargar los datos. Utilizaré la función
cbimportsituado en la./binde tu instalación de Couchbase en uno de tus nodos. Asumo que tienes acceso shell a tu cluster de Couchbase y las credenciales requeridas.
1cbimport json -c couchbase://127.0.0.1 -u $CB_USERNAME -p $CB_PASSWORD -b source -d file://./data.json -f lines -t 4 -g xml::%id% - Eche un vistazo. Todos los artículos 100K se habrán convertido instantáneamente a medida que se cargan (en la mutación causada por la inserción).
- Utilizaré un sencillo script Perl llamado
-
-
Si quieres más rendimiento, puedes escalar verticalmente aumentando el número de trabajadores en la configuración de funciones o añadiendo más nodos Eventing. Si quieres cargar más datos y mantener la residencia de memoria 100%, puede que necesites aumentar el tamaño de tu bucket.
Reflexiones finales
Espero que esta guía te haya resultado instructiva y que hayas aprendido a apreciar mejor el el servicio de eventos Couchbase en su conjunto.
Antes optimizábamos la Función para utilizar menos recursos de computación. También podríamos optimizar el espacio de almacenamiento. Tenga en cuenta que tenemos tanto un in_xml y un out_json en nuestros documentos después de enriquecerlos. Con un pequeño retoque (añadiendo dos líneas) podríamos eliminar la propiedad in_xml y eliminar el almacenamiento redundante (me ahorra 30% de espacio en disco). He optado por dejar esto fuera del ejemplo para resaltar mejor cómo se ejecutaba la función, pero te invito a que experimentes tú mismo con ella utilizando lo siguiente:
|
1 2 3 4 5 6 7 8 9 10 |
function OnUpdate(doc, meta) { // filter out non XML if (!meta.id.startsWith("xml:")) return; if (!doc.in_xml) return; // optimize for storage space // ALL OTHER LINES THE SAME delete doc.in_xml; // optimize for storage space src_bkt[meta.id] = doc; } |
He colocado este ejemplo en el sitio principal de documentación de Couchbase como el ejemplo Scriptlet: Función: convertXMLtoJSON. No traducirá los atributos XML, pero eso fue fácil de añadir (véase el párrafo siguiente). Sin embargo, el método simple parseXmlToJson() que utilicé se ajustaba perfectamente a los datos iniciales.
Durante el desarrollo, empecé de forma sencilla y probé algunos documentos XML masivos pero, por supuesto, puede que no haya cubierto toda la gama de construcciones XML. Desarrollé el segundo Scriptlet convertAdvXMLtoJSON (que no aparece en este artículo), ya que enseguida descubrí que muchos documentos XML utilizan atributos y tienen algunas variantes sintácticas interesantes.
|
1 2 3 4 5 6 7 8 |
<DOC_WITH_ATTRS> <ADVELEM1 adv_attrA="adv_valA" /> <ADVELEM2 adv_attrA="adv_valA" adv_attrB="adv_valB"> <SUB> SUBDATA </SUB> </ADVELEM2> </DOC_WITH_ATTRS> |
Esto me llevó a crear una función Eventing más extensa que traduce atributos XML y las variantes de sintaxis que encontré. También encontrarás la fuente de esta función Eventing más larga y capaz en el sitio de documentación principal de Couchbase como el Scriptlet de ejemplo: Función: convertAdvXMLtoJSON. Esta versión más avanzada ha convertido con éxito documentos XML de gran tamaño, incluidos "archivos de geometría de OpenStreetmap" y también "mediciones operativas celulares de Huawei".
Te reto a que pruebes a hacer lo siguiente:
-
-
-
- Escribe una función inversa: En lugar de
convertXMLtoJSON, digamosconvertJSONtoXML - Alter
convertAdvXMLtoJSONpara anteponer cualquier nombre de propiedad comoatr_para ayudarle a identificar los atributos XML en la conversión final a JSON. - Añadir un mapa JavaScript opcional y una rutina para convertir genéricamente las propiedades por nombre en números reales y booleanos (en lugar del tipo de cadena predeterminado).
- Implementar una mejora para aplicar una "Document Type Definition" o DTD a los datos de entrada, donde se lee la DTD de otro documento.
- Crear un traductor para que las consultas XPath se dirijan (apunten) a diferentes partes de una representación JSON del documento convertido.
- Escribe una función inversa: En lugar de
-
-
No olvides experimentar con SQL++ (N1QL) en el Query Workbench y utilizar el Index Advisor para consultar y crear índices óptimos para acceder a tus datos XML (transformados a JSON).
Recursos
-
-
-
- Descargar: Descargar Couchbase Server 6.6.2
- Scriptlet de Eventing: Función:
convertXMLtoJSON. - Scriptlet de Eventing: Función:
convertAdvXMLtoJSON.
-
-
Referencias
Espero haberte convencido de que Couchbase via Eventing es una base de datos XML.
Me encantaría que me contaras qué te han parecido las capacidades de Couchbase y Eventing y cómo benefician a tu negocio de cara al futuro. Por favor, comparte tu opinión a través de los comentarios de abajo o en los foros de Couchbase.