Construir una arquitectura de big data no significa elegir entre NoSQL o Hadoop. Se trata de hacer que NoSQL y Hadoop funcionen juntos. Hadoop está diseñado para cargas de trabajo analíticas por lotes y de streaming. Las bases de datos NoSQL están diseñadas para cargas de trabajo operativas de web empresarial, móviles e IoT. El big data operativo de las bases de datos NoSQL es combustible para Hadoop.
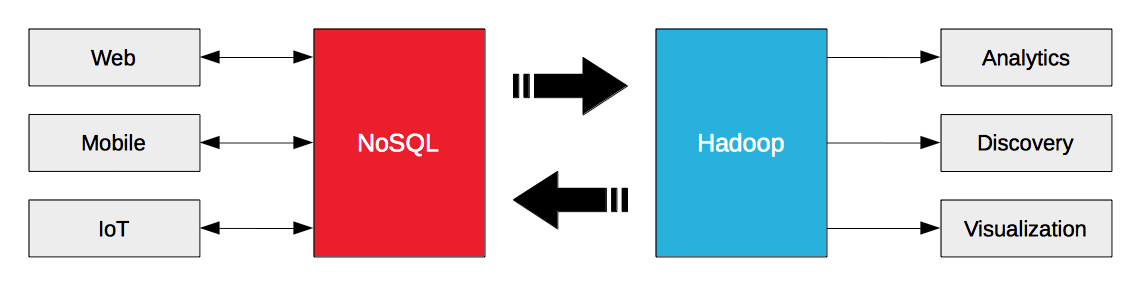
La clave para liberar el valor de los big data operativos es agilizar su flujo entre las bases de datos NoSQL y Hadoop, y por eso Hortonworks y Couchbase han anunciado hoy una asociación estratégica. Couchbase Server 3.0 introdujo el protocolo de cambio de base de datos (DCP) para transmitir datos no sólo a destinos internos (por ejemplo, nodos / clusters), sino también a destinos externos (por ejemplo, Hadoop). Hortonworks Data Platform (HDP) 2.2 no sólo incluye Sqoop para la importación y exportación de datos, sino también Kafka para la mensajería de alto rendimiento y Storm para el procesamiento de flujos.
Couchbase Server puede transmitir datos a destinos externos. HDP puede recibir datos de fuentes externas y procesarlos como un flujo. Estas capacidades permiten a las empresas exportar y transmitir datos a HDP desde Couchbase Server y viceversa.
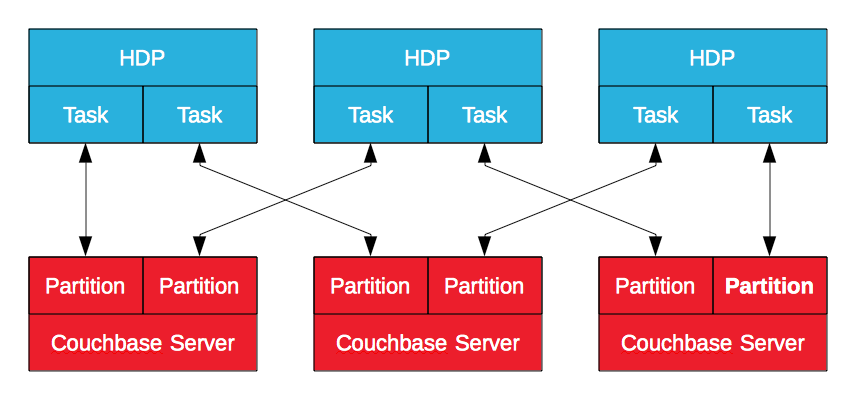
Conector Hadoop de Couchbase Server
El conector Hadoop de Couchbase Server, certificado por Hortonworks, aprovecha MapReduce para exportar datos de Couchbase Server a HDP y viceversa. Los datos en Couchbase Server se almacenan en particiones lógicas con nodos que poseen un subconjunto de ellas. Construido sobre el subproyecto Apache Sqoop, generará un trabajo MapReduce en HDP para importar datos desde o exportar datos a Couchbase Server. Esto permite a Hadoop importar y exportar datos con múltiples tareas, en paraleloconectándose a varios nodos de Couchbase Server. Es un proceso por lotes, pero eficaz, sobre todo cuando el objetivo es enriquecer y refinar datos operativos.
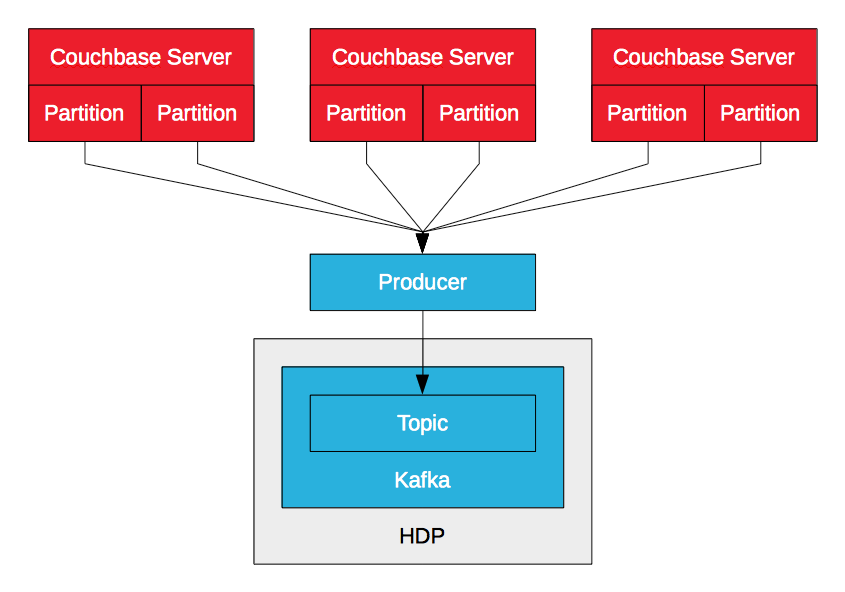
Couchbase Server Kafka Productor
El Couchbase Server Kafka producer aprovecha DCP para transmitir mutaciones de datos (insertar, actualizar, eliminar) en un Couchbase Server a un tema Kafka. El productor recibe múltiples flujos desde múltiples nodos, uno por partición lógica, y los fusiona. A medida que recibe mutaciones, las envía al tema. Esto permite una ingestión de datos de alto rendimiento y baja latencia en HDP a través de Kafka. Mientras que Sqoop permite a las empresas importar datos de Couchbase Server a través de lotes, Kafka les permite importar datos a través de flujos. Los datos pueden escribirse en HDFS con Camus de LinkedIn, por ejemplo, o ser consumidos por Storm o Spark Streaming para su procesamiento en tiempo real.
PayPal open sourced a Couchbase Server Kafka productor para Couchbase Server 2.5.
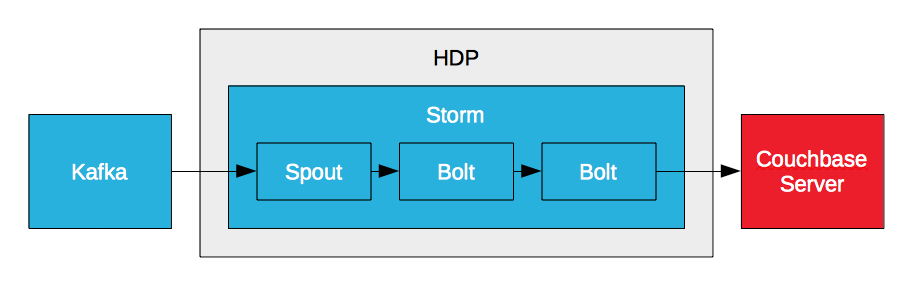
Servidor Couchbase Storm Bolt
Storm puede procesar un flujo de datos en tiempo real, pero no puede persistir los datos y no puede proporcionar acceso a ellos. Sin embargo, puede escribir datos en Couchbase Server a través de un perno. Storm requiere una base de datos de alto rendimiento para satisfacer los requisitos de alto rendimiento y baja latencia. Por eso, empresas como PayPal crean bolts de Couchbase Server. Esto les permite procesar flujos de datos en tiempo real y escribir los datos procesados en Couchbase Server. La clave de la analítica en tiempo real es la baja latencia. Es baja latencia de entrada, analizando datos en movimiento, y baja latencia de salida, accediendo a los resultados para informes y visualización.
Couchbase Server Storm Bolt (Ejemplo #1)
Couchbase Server Storm Bolt (Ejemplo #2)
Big Data en tiempo real
Empresas como PayPal están aprovechando Kafka, Storm y Flume para crear soluciones de big data en tiempo real agilizando el flujo de datos entre Servidor Couchbase y distribuciones de Hadoop como HDP. Es Couchbase Server a Kafka a Storm a HDFS. Es Kafka a Storm a HDFS y Couchbase Server. Depende de ti. HDP incluye todos los componentes necesarios para soportar el flujo de datos hacia y desde Couchbase Server. ¿Cómo será tu arquitectura de big data en tiempo real?
Mundo Strata+Hadoop
Couchbase realizará hoy una presentación con LinkedIn sobre Couchbase Server y Kafka. De Couchbase a Hadoop en Linkedin: Kafka hace posible el Big Data Pipeline
Recursos
Presentación de PayPal en Couchbase Connect 2014
Central de Big Data