El principal objetivo de este blog es enseñarte cómo puedes migrar fácilmente tus datos relacionales a Couchbase, reduciendo tu coste total de propiedad y potenciando tu plataforma de datos para responder a los rápidos ciclos de publicación que conocemos y amamos. Mientras migras puedes incluso conservar los nombres/espacios de claves individuales que ya tienes estructurados usando ámbitos y colecciones. Este blog es una especie de amalgama de las nuevas características explicadas en otros blogs y actualizaciones recientes, pero a diferencia de esos blogs incluye algunos ejemplos de cómo puedes migrar tus datos relacionales a Couchbase.
Una de las cosas brillantes de Couchbase es que realmente escuchamos las necesidades de nuestra comunidad y continuamos desarrollando nuestros productos para ofrecer la mejor experiencia posible a nuestros clientes. Escribí este blog como "práctico" si quieres seguirlo, pero también puedes saltarte el paso de extracción y simplemente trabajar con un TSV que te he proporcionado.
Si nos estás siguiendo, los prerrequisitos son un RDBMS del que extraer datos, un intérprete de python y un servidor Couchbase (ya sea en Docker, VM, físico, etc.).
Voy a utilizar un ejemplo en línea para nuestra base de datos de demostración. Enlace aquí es la base de datos de ejemplo con tres tablas: clientes, agentes y pedidos.
Migrar datos a Couchbase es realmente fácil, vamos a imitar nuestra estructura de tablas utilizando nuestra nueva función de ámbitos y colecciones. Para empezar necesitamos un espacio de almacenamiento lógico, en este ejemplo estamos utilizando un bucket por base de datos, por lo que sólo tenemos que crear un bucket. El esquema se asignará a un ámbito, así que un ámbito. Por último, cada una de las tablas se asignará a una colección del mismo nombre, por lo que habrá un total de tres colecciones.
Creación de cubos, ámbitos y colecciones:
Tenemos muchas opciones disponibles aquí. El SDK, REST API, Couchbase CLI (sin olvidar Couchbase shell), y Web GUI. Voy a utilizar la API REST, la belleza aquí es que podemos acceder a ella desde la línea de comandos, ¡y no hay necesidad de instalar nada! Para cualquier persona tímida de la interfaz REST, la documentación aquí explicará otros métodos alternativos.
Los pasos siguientes especificarán los comandos necesarios para configurar su cubo, ámbito y colecciones:
Ejecute los dos comandos siguientes para crear su cubo de datos y su ámbito:
|
1 2 |
curl -X POST -u Administrator:password https://127.0.0.1:8091/pools/default/buckets -d name=migration -d bucketType=couchbase -d ramQuotaMB=100 curl -X POST -u Administrator:password <a href="https://127.0.0.1:8091/pools/default/buckets/migration/collections">https://127.0.0.1:8091/pools/default/buckets/migration/collections</a> -d name=reference |
Ahora cree las tres colecciones a las que asignaremos los datos de nuestra tabla:
|
1 |
curl -u Administrator:password -X POST https://localhost:8091/pools/default/buckets/migration/collections/reference -d name=$TABLE_NAME |
Simplemente cambie la variable $TABLE_NAME según sea necesario para crear las colecciones de agentes, pedidos y clientes respectivamente.
(En el Apéndice encontrará enlaces a las páginas de documentación de estas API).
Con todo creado, dirígete a la sección Buckets y haz clic en el enlace "Scopes & Collections" junto al nombre del bucket que has creado, el mío se llama migration. Si expandes el ámbito que hemos creado, verás las tres colecciones que hemos creado.
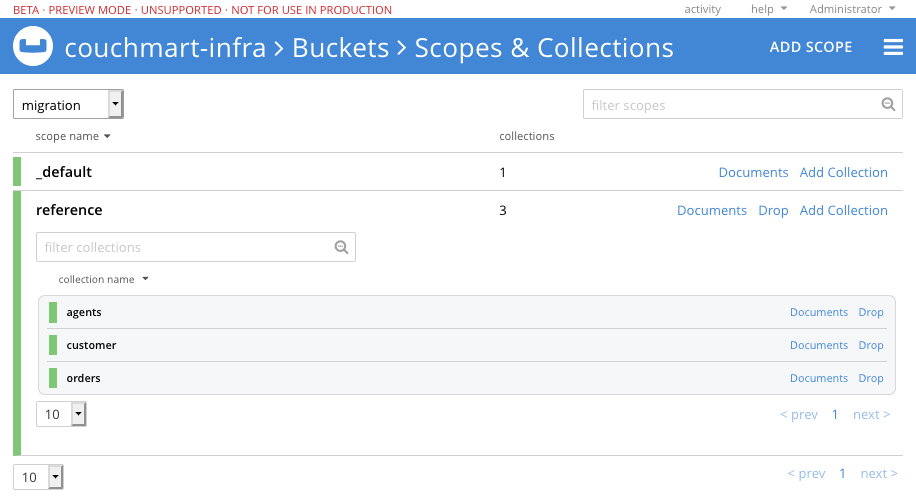
Extracción de datos de nuestro RDBMS
Ahora que tenemos nuestro cubo, ámbito y colecciones en su lugar, estamos listos para exportar nuestros datos relacionales. He escrito un guión corto que extrae los datos almacenados en la base de datos MySQL de ejemplo a TSV, que es felizmente soportado por nuestras herramientas de importación, o puede exportar los datos usted mismo. Si ya tiene la base de datos configurada, simplemente ejecute el script y cambie las variables para utilizar el nombre de usuario y la contraseña que configuró. Después de ejecutar el script, debería ver tres archivos .tsv creados que contienen los datos de cada tabla de la base de datos de ejemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/usr/bin/python3 import subprocess import json import re sql_commands='{ "commands": { "agents": "SELECT * FROM agents;", "customer": "SELECT * FROM customer", "orders": "SELECT * FROM orders;" } }' db_name = "sample" username = "root" password = "rootroot" sql_commands = json.loads(sql_commands) for command_name in sql_commands["commands"]: print("Running command: " + command_name) sql_statement = "--execute={0}".format(sql_commands["commands"][command_name]) command = subprocess.run(["/usr/local/mysql/bin/mysql", db_name, "--user={0}".format(username), "--password={0}".format(password), sql_statement], capture_output=True) with open(command_name+"_out.tsv", 'w') as command_output_file: command_without_trailing_white_space = re.sub(b" +\\t", b'\\t', command.stdout) command_output_file.write(command_without_trailing_white_space.decode('ascii')) |
Aquí tienes un ejemplo de la salida TSV, si sólo estás trabajando en la parte de importación, sigue adelante y utiliza esto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
AGENT_CODE AGENT_NAME WORKING_AREA COMMISSION PHONE_NO COUNTRY A007 Ramasundar Bangalore 0.15 077-25814763 A003 Alex London 0.13 075-12458969 A008 Alford New York 0.12 044-25874365 A011 Ravi Kumar Bangalore 0.15 077-45625874 A010 Santakumar Chennai 0.14 007-22388644 A012 Lucida San Jose 0.12 044-52981425 A005 Anderson Brisban 0.13 045-21447739 A001 Subbarao Bangalore 0.14 077-12346674 A002 Mukesh Mumbai 0.11 029-12358964 A006 McDen London 0.15 078-22255588 A004 Ivan Torento 0.15 008-22544166 A009 Benjamin Hampshair 0.11 008-22536178 |
Importación de datos a Couchbase
Nuestra herramienta de importación, cbimport, facilita enormemente la importación de datos en muchos formatos. Recientemente hemos implementado algunas funcionalidades de importación en nuestra web gui, haciendo el proceso aún más accesible. A continuación se muestra una captura de pantalla de nuestra herramienta de importación Web Gui. Para llegar aquí ingresa a la GUI Web de Couchbase, luego ve a "Documentos" -> "Importar".
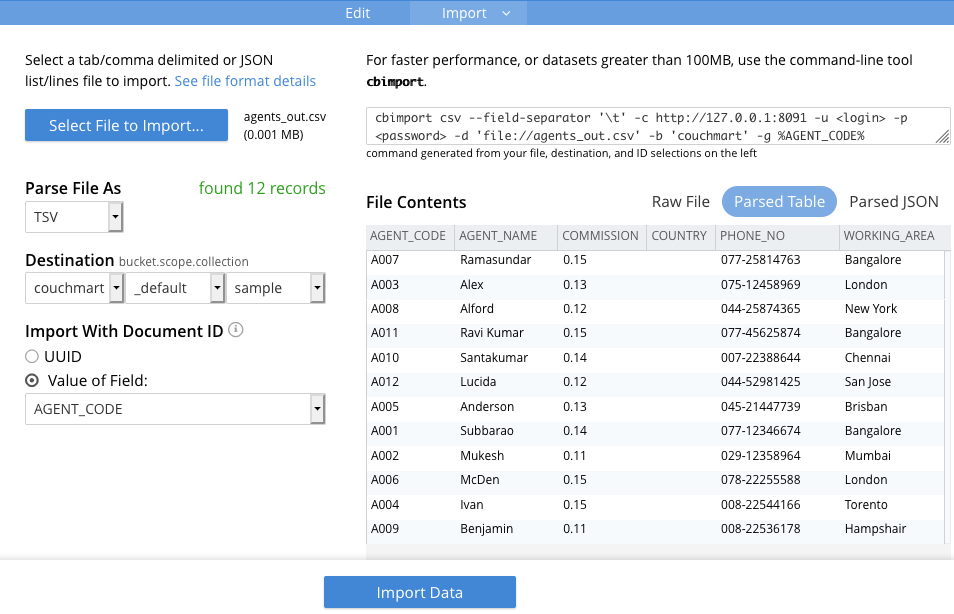
Aquí vamos a importar nuestros TSV utilizando el botón "Seleccionar archivo para importar", observe que al cargar un archivo, muchos campos se rellenan por usted. Eche un vistazo a los datos importados y asegúrese de que se corresponden con lo que espera teniendo en cuenta la estructura relacional anterior. Sólo tenemos que completar unos pocos pasos para importar nuestros datos.
En primer lugar, especifica una colección a la que importar los datos, por ejemplo, agents_out.tsv se asigna a la colección 'agents'. También vamos a hacer corresponder las filas individuales de nuestra base de datos relacional anterior con IDs de documentos en Couchbase, de nuevo esto se hace fácilmente con nuestra herramienta de importación utilizando la sección "Importar con ID de documento". A lo largo de mis importaciones de datos he utilizado la clave primaria de los datos relacionales como el ID del documento en Couchbase, esto es realmente útil ya que cada clave en una colección debe ser única. Por ejemplo, en el archivo agents_out.tsv he utilizado la clave primaria "AGENT_CODE". Realice este paso para cada uno de los .tsv; agentes, pedidos y clientes.
Y ahí lo tienen, para recapitular, hemos hecho lo siguiente:
- Exportación de los datos de nuestra base de datos heredada a TSV
- Creado un ámbito, y colecciones basadas en las tablas que estamos importando
- Importar los datos utilizando la herramienta de migración de datos a una colección específica, dentro de un ámbito.
Vale, ahora que tengo mis datos en Couchbase, ¿necesito aprender una nueva forma de consultar datos? Todo lo contrario, ¿por qué no te diriges a la GUI web de Couchbase, y consultas algunos de tus datos recién importados usando N1QL? Es compatible con SQL++ y, si alguna vez ha escrito una consulta SQL, se sentirá como en casa.La puerta está abierta, ¡entra! No sólo le facilitaremos la redacción de consultas, sino que incluso le ayudaremos a crear el índice adecuado con nuestro Servicio Index AdvisorSólo tiene que introducir la consulta que desea realizar y el asesor le sugerirá un índice. Incluso soportamos JOIN's:
|
1 2 3 4 |
SELECT orders.AGENT_CODE, orders.ORD_AMOUNT, agents.AGENT_NAME FROM `bigdata`.reference.orders as orders JOIN `bigdata`.reference.agents as agents ON orders.AGENT_CODE = meta(agents).id; |
Este es un gran comienzo en la dirección correcta para la transición de relacional a NoSQL, si quieres aprender más sobre el modelado de tus datos para sacar el máximo provecho de Couchbase, consulte nuestra guía de modelado de datos.
¿Quiere saber más sobre ámbitos y colecciones? Recomiendo el blog de Shivani
Apéndice:
- En el siguiente enlace se explica a los usuarios exactamente cómo configurar su base de datos de muestra.
- Contenedor Docker Couchbase
- 7.0 API REST - Documentación de creación de ámbitos
- 7.0 Documentación de creación de cubos de la API REST
- 7.0 API REST - Documentación de creación de colecciones