Con la aparición de tantos LLM, muchas empresas se están centrando en mejorar la velocidad de inferencia de los grandes modelos lingüísticos con hardware especializado y optimizaciones para poder ampliar las capacidades de inferencia de estos modelos. Una de estas empresas que está dando pasos de gigante en este ámbito es Groq.
En esta entrada de blog exploraremos Groq y cómo integrar las rápidas capacidades de inferencia LLM de Groq con Couchbase Vector Search para crear aplicaciones RAG rápidas y eficientes. También compararemos el rendimiento de diferentes soluciones LLM como OpenAI, Gemini y cómo se comparan con las velocidades de inferencia de Groq.
¿Qué es Groq?
Groq, Inc. es una empresa tecnológica estadounidense especializada en inteligencia artificial especialmente conocida por su desarrollo de la Unidad de Procesamiento del Lenguaje (LPU), un circuito integrado de aplicación específica (ASIC) diseñado para acelerar las tareas de inferencia de la IA. Está diseñado específicamente para mejorar Grandes modelos lingüísticos (LLM) con capacidades de inferencia de latencia ultrabaja. Las API de Groq Cloud permiten a los desarrolladores integrar LLM de última generación como Llama3 y Mixtral 8x7B en sus aplicaciones.
¿Qué significa esto para los desarrolladores? Significa que las API de Groq pueden integrarse sin problemas en aplicaciones que exigen procesamiento de IA en tiempo real con necesidades de inferencia rápida.
Cómo empezar con las API de Groq
Para aprovechar la potencia de las API de Groq, el primer paso es generar una clave de API. Se trata de un proceso sencillo que comienza con el registro en la consola de Groq Cloud.
Una vez que se haya registrado, vaya a la página Claves API sección. Aquí tendrá la opción de crear una nueva clave API.

La clave API le permitirá integrar grandes modelos lingüísticos de última generación como Llama3 y Mixtral en sus aplicaciones. A continuación, integraremos el modelo de chat de Groq con Cadena LangChain en nuestra aplicación.
Utilización de Groq como LLM
Puede aprovechar la API Groq como uno de los proveedores LLM en LangChain:
|
1 2 3 4 5 6 |
de langchain_groq importar ChatGroq llm = ChatGroq( temperatura=0.3, nombre_modelo="mixtral-8x7b-32768", ) |
Al instanciar el ChatGroq puedes pasar la temperatura y el nombre del modelo. Puedes echar un vistazo al modelos actualmente soportados en Groq.
Creación de aplicaciones RAG con Couchbase y Groq
El objetivo es crear una aplicación de chat que permita a los usuarios subir PDFs y chatear con ellos. Usaremos Couchbase Python SDK y Streamlit para facilitar la subida de PDFs a Couchbase VectorStore. Además, exploraremos cómo usar RAG para responder preguntas basadas en contexto a partir de PDFs, todo ello potenciado por Groq.
Puede seguir los pasos mencionados en este tutorial sobre cómo configurar una aplicación Streamlit RAG impulsada por Couchbase Vector Search. En este tutorial utilizaremos Gemini como LLM. Sustituiremos la implementación de Gemini por Groq.
Comparación del rendimiento de Groq
En este blog también comparamos el rendimiento de diferentes proveedores de LLM. Para ello hemos construido un desplegable para que el usuario pueda seleccionar qué proveedor LLM desea utilizar para la aplicación RAG. En este ejemplo estamos utilizando Gemini, OpenAI, Ollama y Groq como los diferentes proveedores LLM. Existe un amplia lista de proveedores de LLM compatibles con LangChain.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
st.barra lateral.subtítulo("Seleccione LLM") llm_choice = st.barra lateral.selectbox( "Seleccione LLM", [ "OpenAI", "Groq", "Géminis", "Ollama" ] ) si llm_choice == "Géminis": comprobar_variable_entorno("GOOGLE_API_KEY") llm = GoogleGenerativeAI( temperatura=0.3, modelo="models/gemini-1.5-pro", ) llm_without_rag = GoogleGenerativeAI( temperatura=0, modelo="models/gemini-1.5-pro", ) elif llm_choice == "Groq": comprobar_variable_entorno("GROQ_API_KEY") llm = ChatGroq( temperatura=0.3, nombre_modelo="mixtral-8x7b-32768", ) llm_without_rag = ChatGroq( temperatura=0, nombre_modelo="mixtral-8x7b-32768", ) elif llm_choice == "OpenAI": comprobar_variable_entorno("OPENAI_API_KEY") llm = ChatOpenAI( temperatura=0.3, modelo="gpt-3.5-turbo", ) llm_without_rag = ChatOpenAI( temperatura=0, modelo="gpt-3.5-turbo", ) elif llm_choice == "Ollama": llm = Ollama( temperatura=0.3, modelo = ollama_model, URL_base = ollama_url ) llm_without_rag = Ollama( temperatura=0, modelo = ollama_model, URL_base = ollama_url ) |
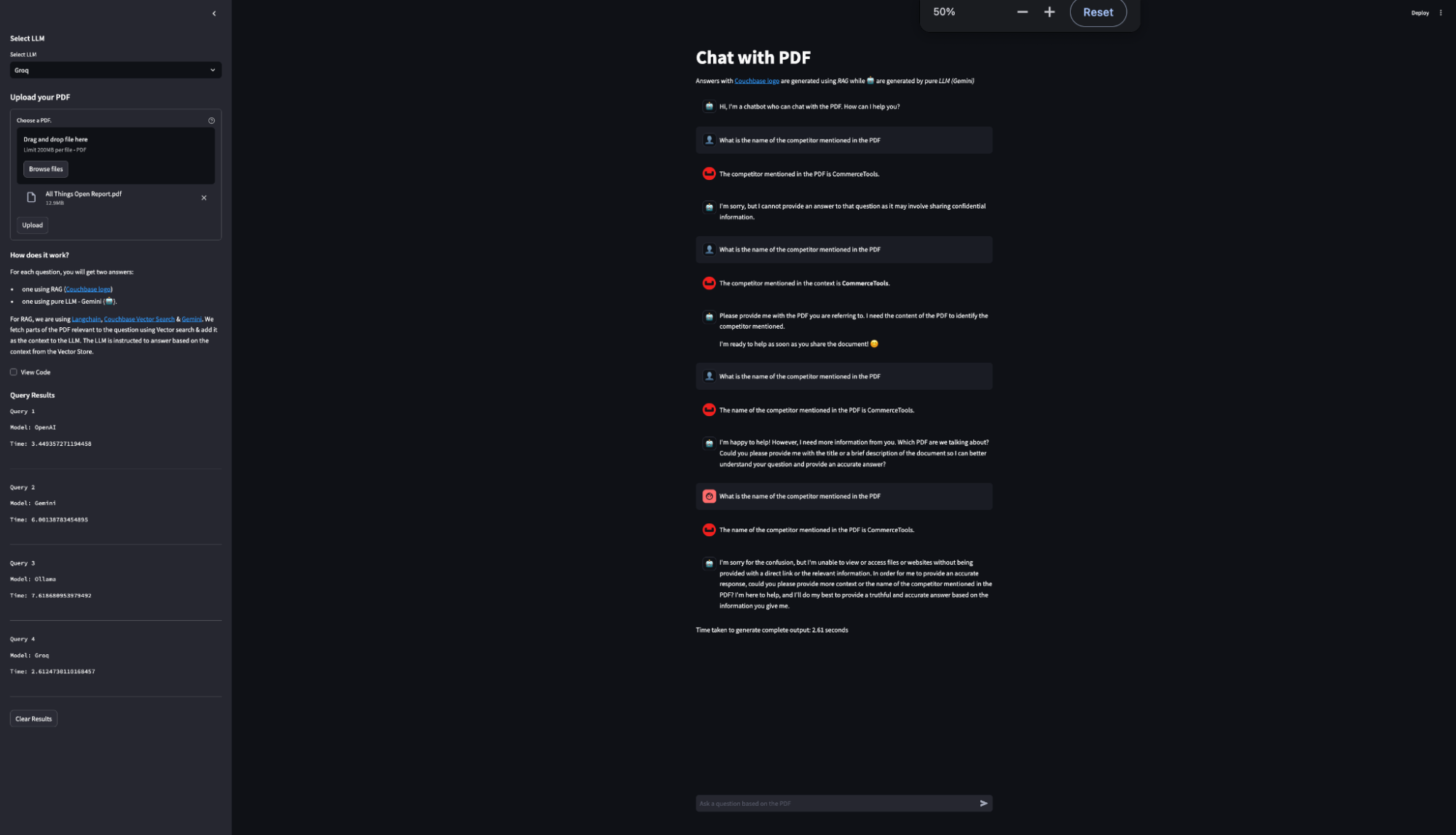
Para resaltar la rápida velocidad de inferencia de Groq, construimos una forma de calcular el tiempo de inferencia para la Respuesta LLM. Esto mide y registra el tiempo empleado para cada generación de respuesta. Los resultados se muestran en una tabla lateral, mostrando el modelo utilizado y el tiempo empleado para cada consulta comparando diferentes proveedores de LLM como OpenAI, Ollama, Gemini y Groq; a través de estas comparaciones, se encontró que el LLM de Groq proporcionaba consistentemente los tiempos de inferencia más rápidos. Esta comparativa de rendimiento permite a los usuarios ver la eficiencia de varios modelos en tiempo real.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
si pregunta := st.chat_input("Haga una pregunta basada en el PDF"): # Hora de inicio hora_inicio = tiempo.tiempo() # Mostrar mensaje de usuario en el contenedor de mensajes de chat st.mensaje_de_chat("usuario").rebajas(pregunta) # Añadir mensaje de usuario al historial de chat st.estado_sesión.mensajes.añadir( {"rol": "usuario", "contenido": pregunta, "avatar": "👤"} ) # Añadir marcador de posición para la transmisión de la respuesta con st.mensaje_de_chat("asistente", avatar=couchbase_logo): marcador_plaza_mensaje = st.vacío() # transmitir la respuesta del GAR trapo_respuesta = "" para trozo en cadena.flujo(pregunta): trapo_respuesta += trozo marcador_plaza_mensaje.rebajas(trapo_respuesta + "▌") marcador_plaza_mensaje.rebajas(trapo_respuesta) st.estado_sesión.mensajes.añadir( { "rol": "asistente", "contenido": trapo_respuesta, "avatar": couchbase_logo, } ) # stream la respuesta del LLM puro con st.mensaje_de_chat("ai", avatar="🤖"): marcador_plaza_mensaje_puro_llm = st.vacío() pure_llm_response = "" para trozo en cadena_sin_arrastre.flujo(pregunta): pure_llm_response += trozo marcador_plaza_mensaje_puro_llm.rebajas(pure_llm_response + "▌") marcador_plaza_mensaje_puro_llm.rebajas(pure_llm_response) st.estado_sesión.mensajes.añadir( { "rol": "asistente", "contenido": pure_llm_response, "avatar": "🤖", } ) # Fin de la temporización y cálculo de la duración hora_fin = tiempo.tiempo() duración = hora_fin - iniciar_tiempo # Visualizar el tiempo transcurrido st.escriba a(f"Tiempo empleado en generar la salida completa: {duración:.2f} segundos") st.estado_sesión.resultados_consulta.añadir({ "modelo": llm_choice, "tiempo": duración }) st.barra lateral.subtítulo("Resultados de la consulta") cabecera_tabla = "| Modelo | Tiempo (s) |\n| --- | --- |\n" # crear filas de tabla filas_tabla = "" para idx, resultado en enumerar(st.estado_sesión.resultados_consulta, 1): filas_tabla += f"| {result['modelo']} | {result['tiempo']:.2f} |\n" tabla = cabecera_tabla + tabla_filas st.barra lateral.rebajas(tabla, unsafe_allow_html=Verdadero) si st.barra lateral.botón("Resultados claros"): st.estado_sesión.resultados_consulta = [] st.experimental_rerun() |
Como se puede ver en los resultados, la velocidad de inferencia de Groq es la más rápida en comparación con los otros proveedores de LLM.
Conclusión
LangChain es un gran marco de código abierto que le proporciona una gran cantidad de opciones posibles para los almacenes de vectores, LLM de su elección para construir aplicaciones impulsadas por IA. Groq está a la vanguardia de ser uno de los motores de inferencia LLM más rápidos y se empareja bien con aplicaciones impulsadas por IA que necesitan inferencia rápida y en tiempo real. Así, con el poder de inferencia rápida de Groq y Couchbase Vector Search puedes construir aplicaciones RAG listas para producción y escalables.
-
- Empiece a utilizar Capella hoy mismogratis
- Más información búsqueda vectorial
