Mientras estaba en JDays en Gotemburgo, asistí a una presentación sobre Apache Zeppelin. Es un cuaderno basado en web que permite el análisis interactivo de datos. Ya soporta muchos intérpretes como Spark, Markdown, Angular, Elastic y más. Realmente está bien integrado con Spark. Y Couchbase tiene un Conector de chispa. Y como la gente detrás de Zeppelin sabía que los usuarios de Spark querrían usar sus propias dependencias, lo hicieron realmente fácil. Fácil en el sentido de que no tienes que escribir un plugin. Pero tienes que tener la última versión.
Construir Apache Zeppelin
Última versión, es decir, creada a partir de las fuentes más recientes (aunque hay que admitir que no es "tan" fácil...). Bastante simple de construir, sin embargo, clonar el repoAsegúrese de tener las dependencias correctas (git, jdk, npm, libfontconfig, maven) y luego dentro del repositorio escriba mvn clean package -DskipTests -Pbuild-distr. Esto construirá el conjunto, ahora sería un buen momento para tomar un café (o tal vez jugar con el nuevo búsqueda de texto completo en Couchbase 4.5 si aún no lo ha hecho).
Al final usted debe tener la distribución construida forma fuente bajo ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/. Ahora para ejecutarlo simplemente escribe ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/bin/zeppelin-daemon.sh start. Si vas a http://localhost:8080/ deberías ver algo como esto:
Añadir la dependencia de Couchbase Spark Connector
Ahora el objetivo es añadir la dependencia correcta al intérprete de Spark. Un intérprete es la pieza de código para transformar el contenido de un pad en otra cosa. Así que repasa el Intérprete . Aquí debería ver la lista de intérpretes disponibles. Deberías poder editar el intérprete Spark simplemente haciendo clic en editar.
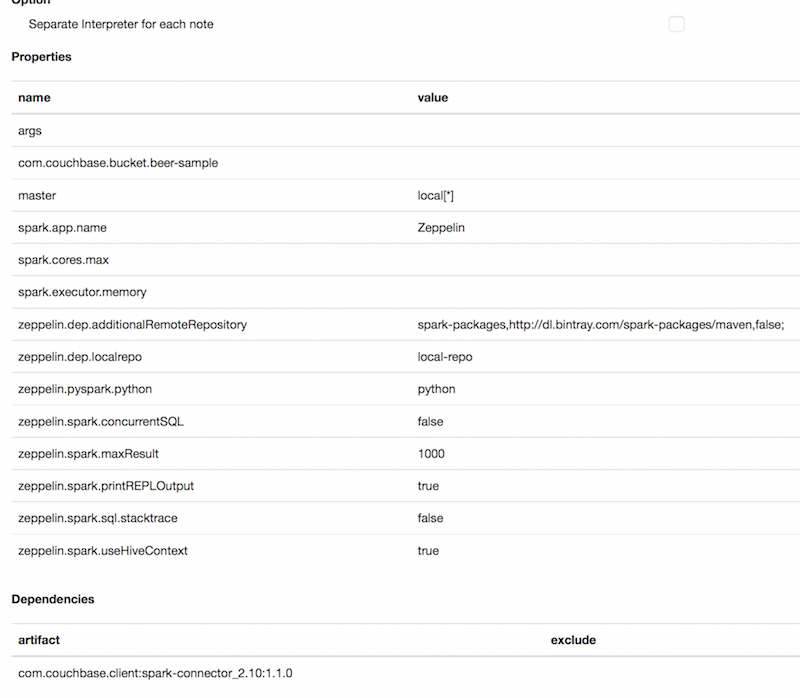
En este punto hay dos cosas que hacer. El primer paso obligatorio es añadir la dependencia al conector Spark de Couchbase. El segundo es añadir una propiedad para acceder al cubo de muestras de cerveza.
En Propiedades, añada com.couchbase.bucket.beer-muestra como nombre y algo como valor. Parece que hay un error en este momento que le prohíbe añadir una nueva propiedad vacía. Puedes edmás tarde.
En Dependencias, añada com.couchbase.client:spark-connector_2.10:1.1.0 en artefacto. No olvides hacer clic en los botones +.
Empezar a escribir Spark Pads
Estamos en un estado en el que podemos empezar a leer o escribir datos desde Couchbase. Siempre importo la muestra de cerveza, por alguna razón. Así que lo que podemos hacer es empezar a leer desde allí. Podemos crear fácilmente un DataFrame para todos los documentos de cerveza. Por defecto el método read.couchbase leerá del bucket por defecto. Así que para asegurarnos de que leemos de la muestra de cerveza creamos una simple opción Map que contiene el par k/v bucket/muestra de cerveza. Además, para asegurarnos de que sólo obtenemos Beer y no brewery, podemos añadir un filtro en el campo type. Estas son las dos primeras líneas que tienes que escribir en el pad para obtener un DataFrame que contenga todos los documentos de cerveza. Luego, si quieres usarlo con Spark SQL, todo lo que tienes que hacer es crear una tempTable a partir de ese DataFrame.
Para ello, pulse Cuaderno y Crear nueva nota. Entonces deberías ver un pad vacío donde puedes empezar a escribir algo de código Scala. También puedes copiar/pegar lo siguiente (pero recuerda que copiar/pegar es malo).
|
1 2 3 4 5 6 7 |
importar org.apache.chispa.sql.fuentes.EqualTo importar com.couchbase.chispa.sql._ val opciones = Mapa("cubo" -> "muestra de cerveza") val dataFrame = sqlc.leer.couchbase(schemaFilter = EqualTo("tipo", "cerveza"), opciones) dataFrame.registerTempTable("cerveza") |
Si ejecuta este párrafo, añadirá otra almohadilla de seguimiento. Por defecto el intérprete es 1TP1Parque. Si quieres usar otro intérprete, inicia la almohadilla con su nombre. Aquí quiero ejecutar consultas SQL de Spark. Así que empezaré el pad con %sql. En lugar de interpretar código Scala Spark como antes, interpreta directamente consultas Spark SQL.
|
1 2 3 4 5 6 7 |
%sql seleccione abv, cuente(1) valor de cerveza grupo por abv pedir por abv |
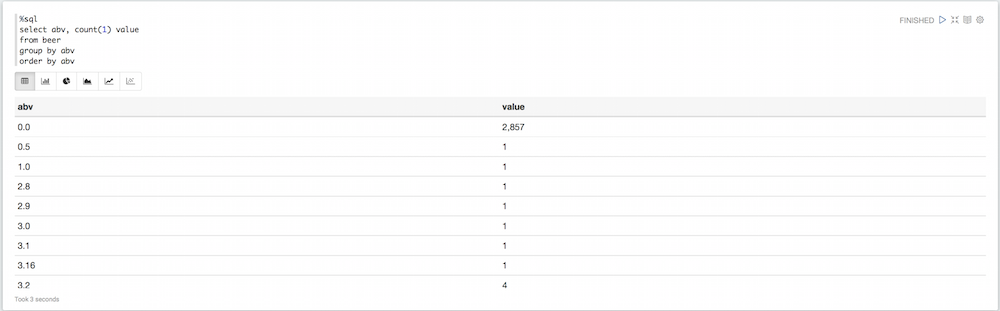
Si miras el diagrama, verás que hay muchos valores que no son necesariamente útiles. Algunas cervezas tienen un valor 0 por defecto para el abv, otras tienen un abv ridículamente alto. Podemos filtrar todo eso:
|
1 2 3 4 5 6 7 |
%sql seleccione abv, cuente(1) valor de cerveza donde abv > 0 y abv < 15 grupo por abv pedir por abv |
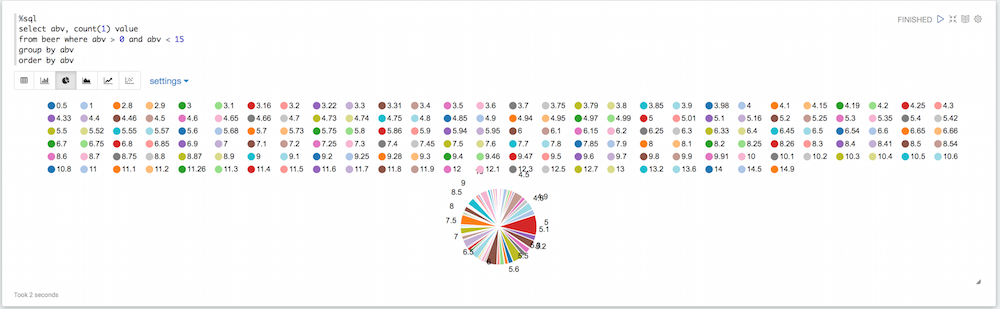
Ligeramente mejor, pero aún tenemos muchos valores de abv diferentes, así que podemos redondear así:
|
1 2 3 4 5 6 7 |
%sql seleccione redondo(abv,0) roundABV, cuente(1) valor de cerveza donde abv > 0 y abv < 15 grupo por abv pedir por abv |
Esto empieza a ser más fácil de leer. Agrupémoslos por categorías y eliminemos al mismo tiempo las categorías vacías:
|
1 2 3 4 5 6 7 |
%sql seleccione categoría, redondo(abv,0) roundABV, cuente(1) valor de cerveza donde abv > 0 y abv < 15 y categoría != "" grupo por abv, categoría pedir por abv |
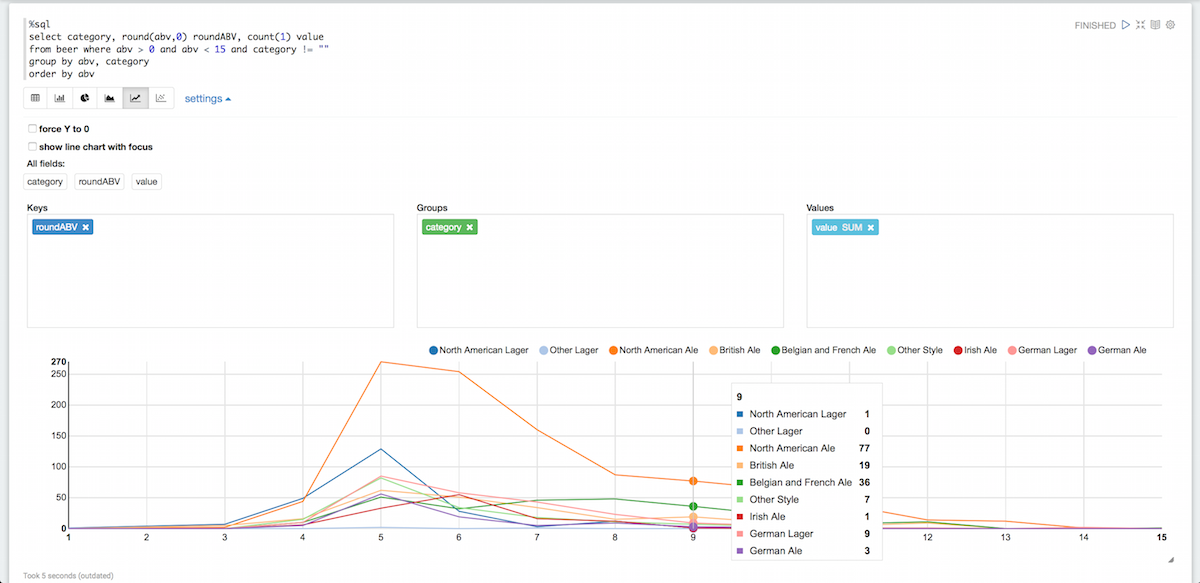
Hay por supuesto muchas otras cosas que puedes hacer con Zeppelin pero esto debería ser suficiente para empezar con Couchabse. Si quieres saber más sobre Zeppelin, puedes consultar su documentación aquíTambién tienen algunos buenos vídeos.