Aaron Benton es un arquitecto experimentado especializado en soluciones creativas para desarrollar aplicaciones móviles innovadoras. Tiene más de 10 años de experiencia en desarrollo full stack, incluyendo ColdFusion, SQL, NoSQL, JavaScript, HTML y CSS. Aaron es actualmente Arquitecto de Aplicaciones para Shop.com en Greensboro, Carolina del Norte y es un Campeón de la comunidad Couchbase.

FakeIt Serie 1 de 5: Generación de datos falsos
Hay innumerables entradas de blog sobre modelado de datosy patrones de documentos. Todos estos posts dan una gran introducción a cómo estructurar y modelar tus documentos en Couchbase, pero ninguno de ellos te dice qué hacer a continuación. En esta serie de blogs vamos a responder a la pregunta, ¿qué hacer después de haber definido tu modelo de datos?
Modelo de usuario
Para esta serie vamos a trabajar con una aplicación de comercio electrónico greenfield. Como con la mayoría de las aplicaciones de comercio electrónico, nuestra aplicación va a tener usuarios, así que aquí es donde vamos a empezar.
Para empezar, hemos definido un modelo de usuario básico.
|
1 2 3 4 5 6 7 8 9 10 11 |
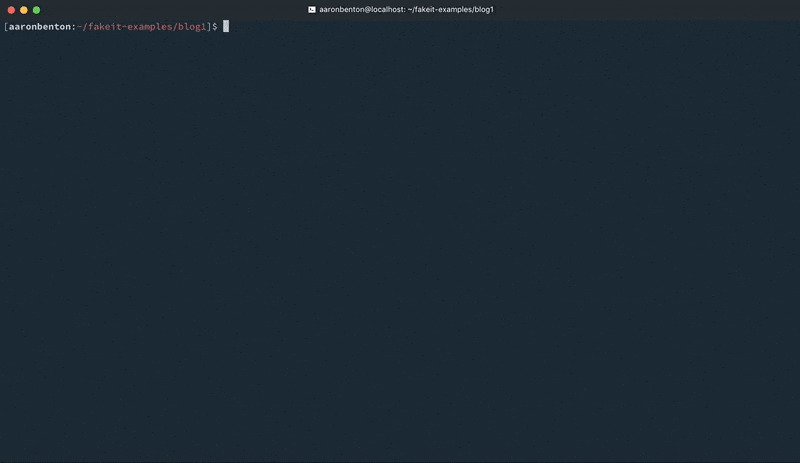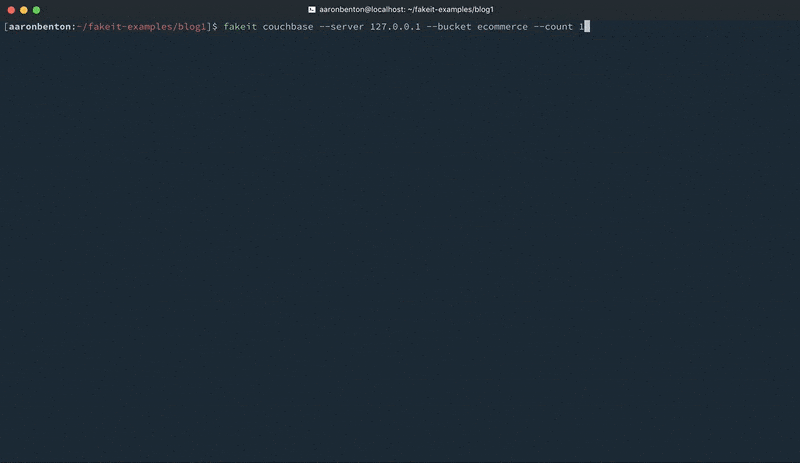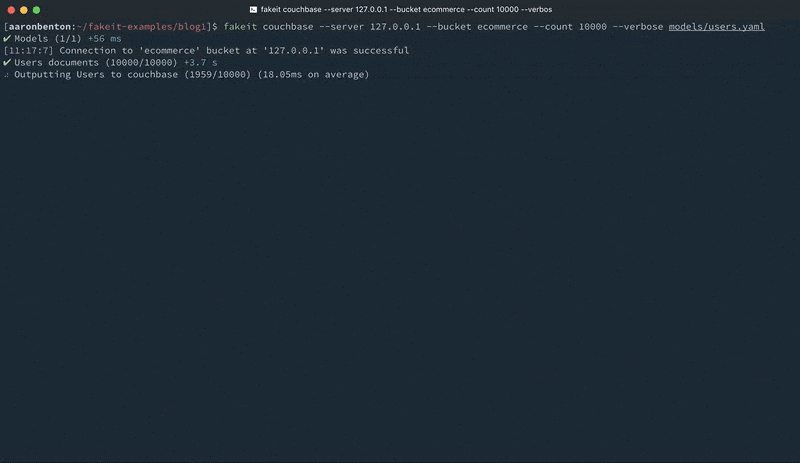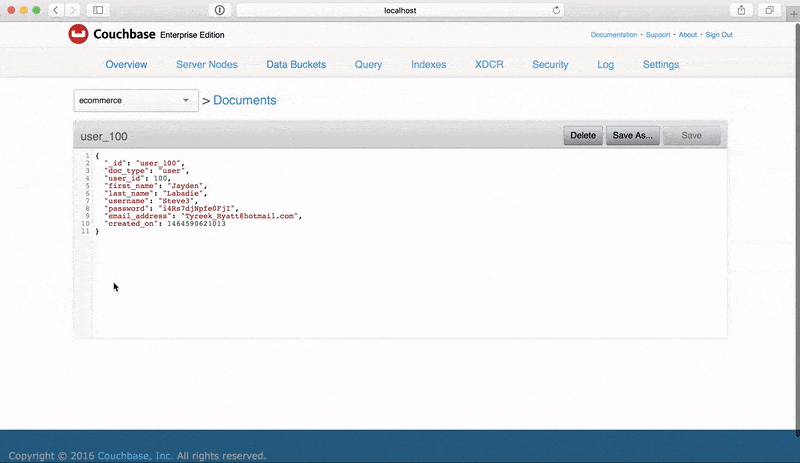
{ "_id": "user_0", "doc_type": "user", "user_id": 0, "first_name": "Mac", "last_name": "Carter", "username": "Salma.Ratke", "password": "DvA6YrMGtgsKKnG", "email_address": "Ludie74@hotmail.com", "created_on": 1457172796088 } |
Hemos hecho lo más difícil, que es definir nuestro modelo, pero ¿ahora qué?
- ¿Cómo representamos este modelo?
- ¿Cómo documentamos este modelo?
- ¿Se basa este modelo en datos de otros modelos?
- ¿Cómo se pueden generar datos a partir de este modelo?
- ¿Cómo podemos generar datos falsos o de prueba?
Por suerte para nosotros existe un proyecto NodeJS llamado FakeIt que pueda respondernos a todas estas preguntas. FakeIt es una utilidad de línea de comandos que genera datos falsos en formatos json, yaml, yml, cson o csv basados en modelos definidos en yaml. Los datos pueden generarse utilizando cualquier combinación de FakerJS, ChanceJS o funciones personalizadas. Los datos generados pueden ser emitidos en los siguientes formatos y destinos:
- json
- yaml
- cson
- csv
- Archivo Zip de archivos json, yaml, cson o csv
- Servidor Couchbase
- Servidor Couchbase Sync Gateway
Podemos definir un modelo FakeIt en YAML para representar nuestro modelo JSON. Esto nos proporciona un modelo documentado y tipado por datos que podemos comunicar cómo debe ser la estructura de nuestro modelo y para qué sirven las propiedades.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefixed "user_" and the users id doc_type: type: string description: The document type user_id: type: integer description: The users id first_name: type: string description: The users first name last_name: type: string description: The users last name username: type: string description: The users username password: type: string description: The users password email_address: type: string description: The users email address created_on: type: integer description: An epoch time of when the user was created |
Probablemente te estés diciendo, "Genial, he definido mi modelo en YAML pero ¿de qué me sirve?" Uno de los mayores problemas a los que se enfrentan los desarrolladores cuando empiezan a desarrollar es tener datos con los que trabajar. A menudo se pierde una cantidad exorbitante de tiempo creando documentos manualmente, escribiendo código para rellenar un cubo. Además, es posible que tenga un volcado de datos completo o parcial de su base de datos que tiene que ser importado.
Estos son lentos, tediosos y, en el caso de un volcado de datos, no proporcionan ninguna información o documentación sobre los modelos disponibles. Podemos añadir unas sencillas propiedades a nuestro modelo FakeIt que describan cómo debe generarse nuestro modelo, y a través de un único archivo podemos crear un sinfín de documentos aleatorios falsos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: `user_${this.user_id}` doc_type: type: string description: The document type data: value: user user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() |
Hemos añadido una propiedad de datos a cada una de las propiedades de nuestros modelos que describe cómo se debe generar ese valor. FakeIt soporta 5 formas diferentes de generar un valor:
- pre_build: para inicializar el valor
- construir: que construye un valor
- falso: Una cadena de plantilla FakerJS, por ejemplo {{internet.userName}}
- valor: Un valor estático a utilizar
- post_build: una función que se ejecuta después de establecer todas las propiedades del modelo
Estas funciones de compilación son un cuerpo de función JavaScript. A cada una de estas funciones se le pasan las siguientes variables que se pueden utilizar en el momento de su ejecución:
- documentos - Un objeto que contiene una clave para cada modelo cuyo valor es una matriz de cada documento que se ha generado
- globals - Un objeto que contiene cualquier variable global que pueda haber sido establecida por cualquiera de las funciones run o build
- inputs - Un objeto que contiene una clave para cada archivo de entrada utilizado cuyo valor es la versión deserializada de los datos de los archivos
- faker - Una referencia a FakerJS
- chance - Una referencia a ChanceJS
- document_index - Es un número que representa la posición del documento generado actualmente en el orden de ejecución
- require - Esta es la función require del nodo, le permite requerir sus propios paquetes. Para un mejor rendimiento requerir y seth ellos en la función pre_run.
Por ejemplo, si nos fijamos en la función de construcción de propiedades de nombre de usuario se vería así:
|
1 2 3 |
function (documents, globals, inputs, faker, chance, document_index, require) { return faker.internet.userName(); } |
Ahora que hemos definido cómo debe generarse nuestro modelo, podemos empezar a generar algunos datos falsos con él.
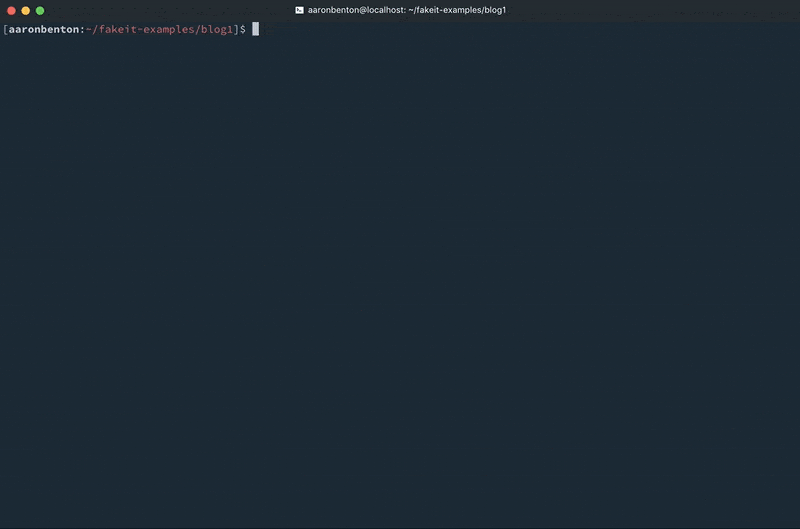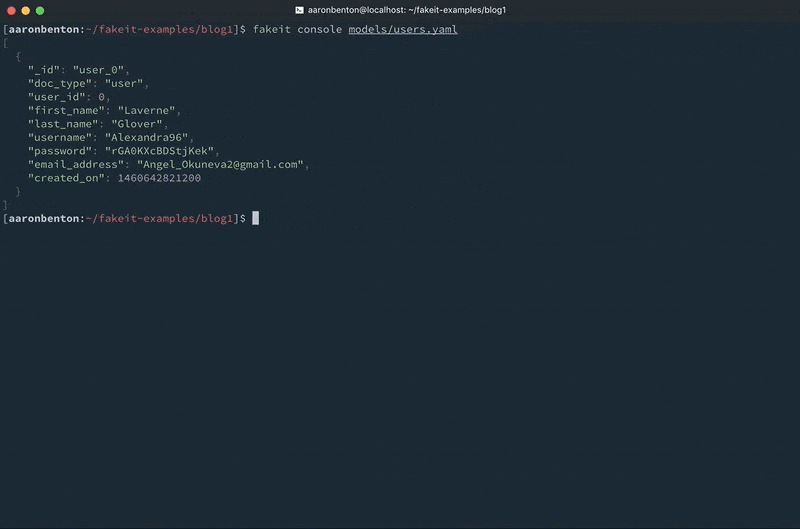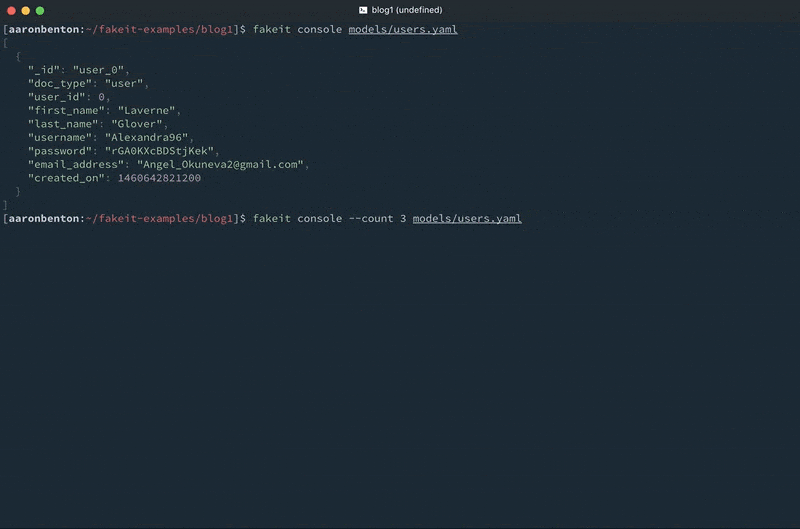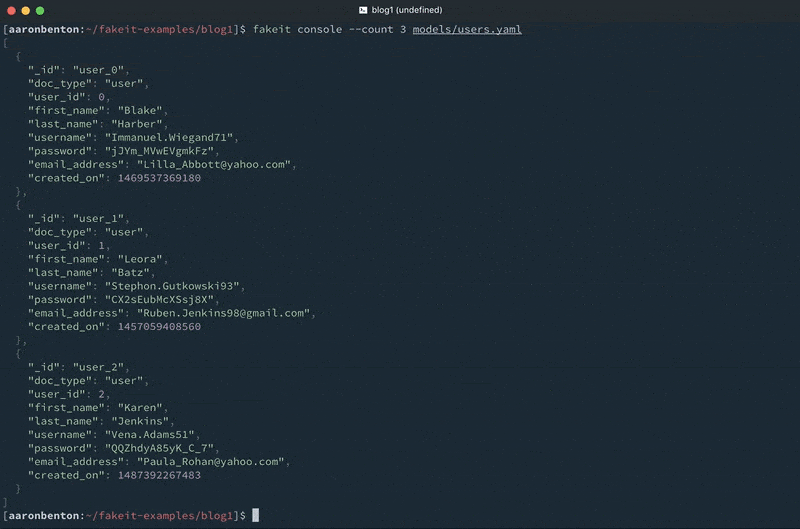
Con nuestro modelo de usuarios guardado en un archivo models/users.yaml, podemos enviar los datos directamente a la consola utilizando el comando
|
1 |
fakeit console models/users.yaml |
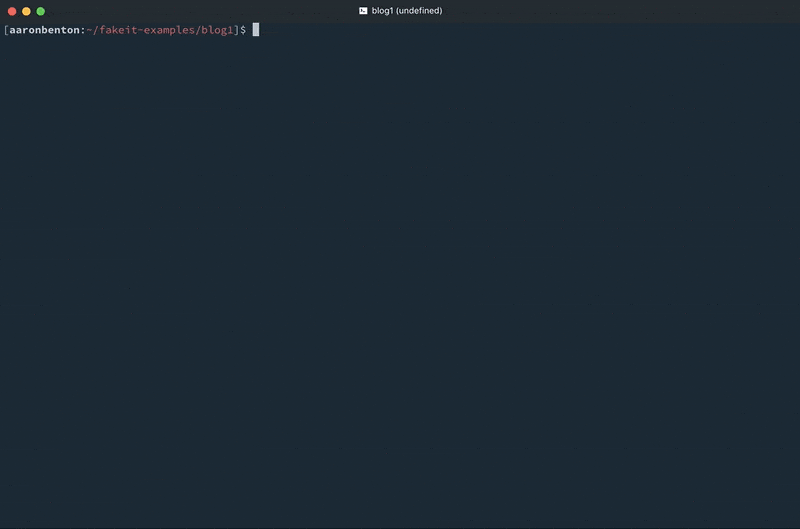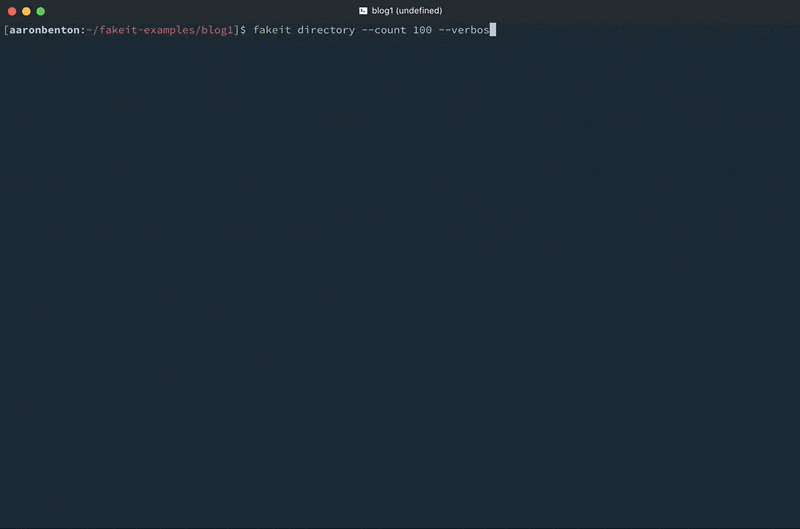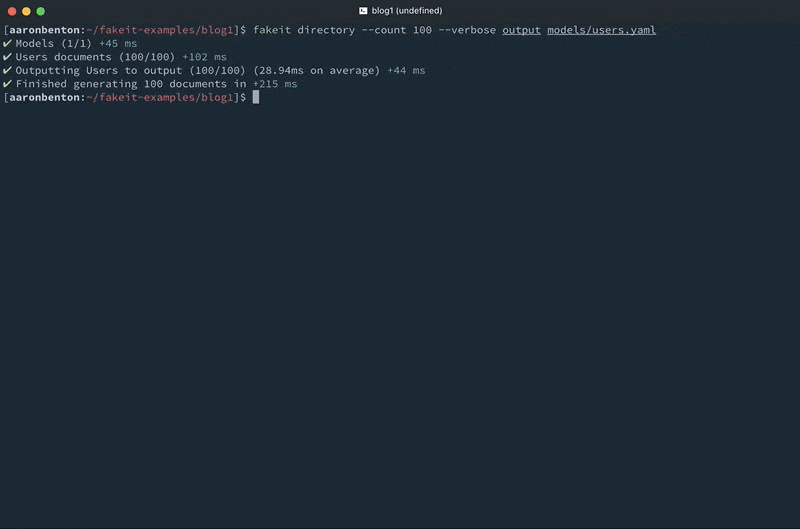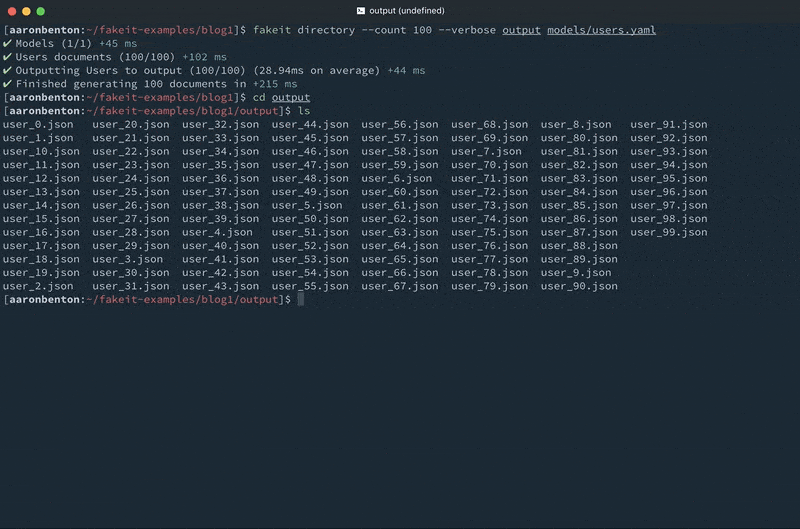
Usando este mismo modelo podemos generar 100 archivos JSON y guardarlos en un directorio llamado output/ usando el comando
|
1 |
fakeit directory –count 100 –verbose output models/users.yaml |
Además, podemos crear un archivo zip de 1.000 archivos JSON utilizando el comando:
|
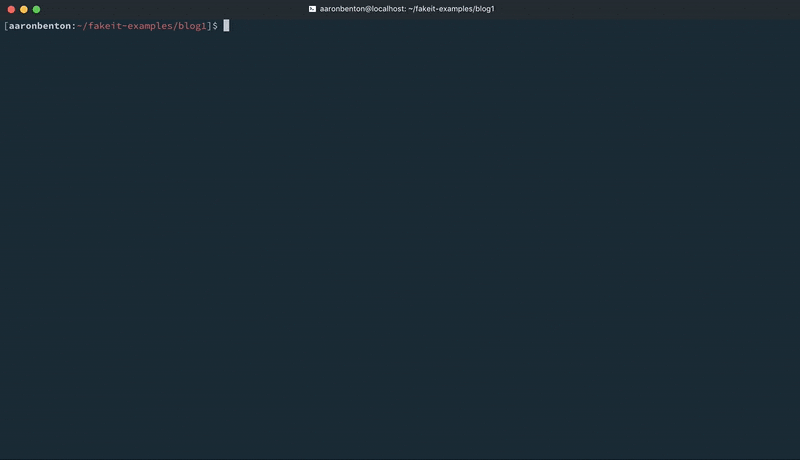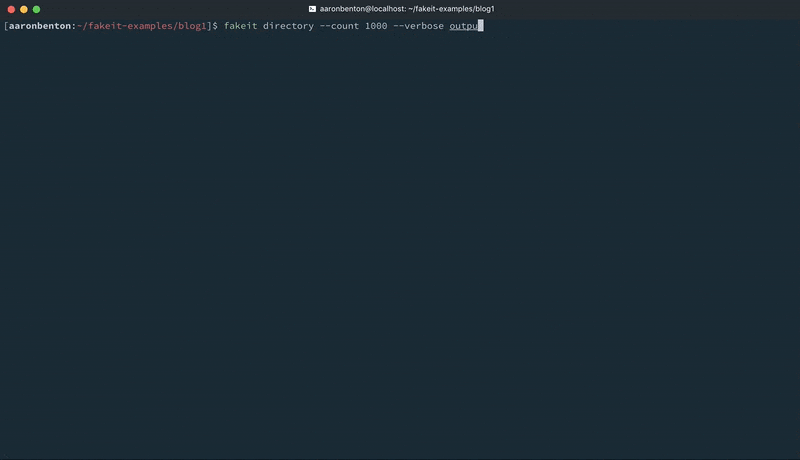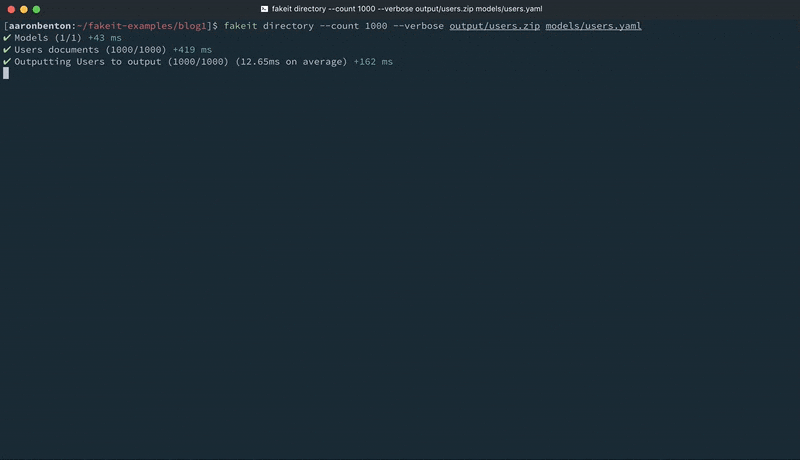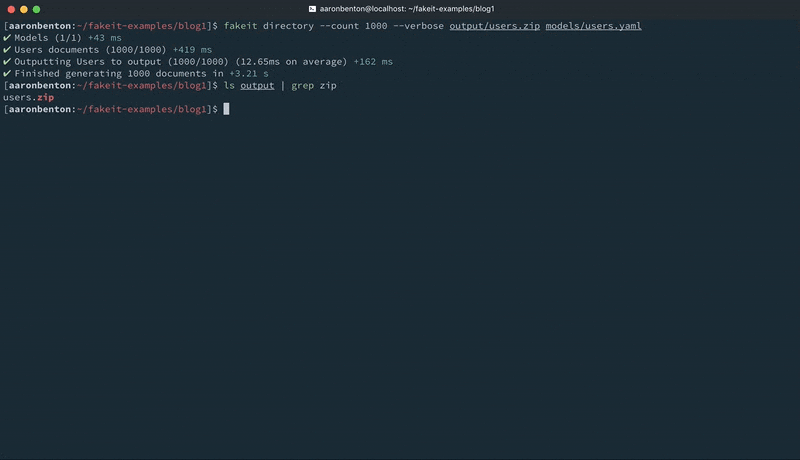
1 |
fakeit directory –count 1000 –verbose output/users.zip models/users.yaml |
Incluso podemos generar un único archivo CSV de nuestro modelo utilizando el siguiente comando:
|
1 |
fakeit directory –count 25 –format csv –verbose output/ models/users.yaml |
Esto creará un único archivo CSV cuyo nombre es el nombre del modelo, en este caso nombre: Usuarios con el archivo resultante llamado Usuarios.csv
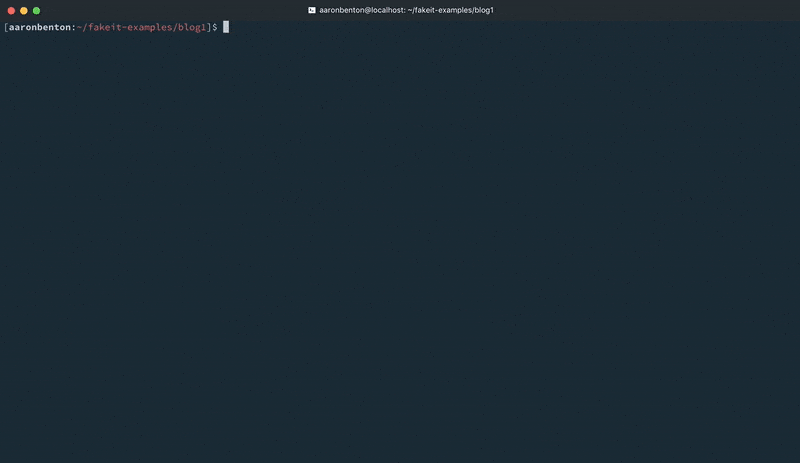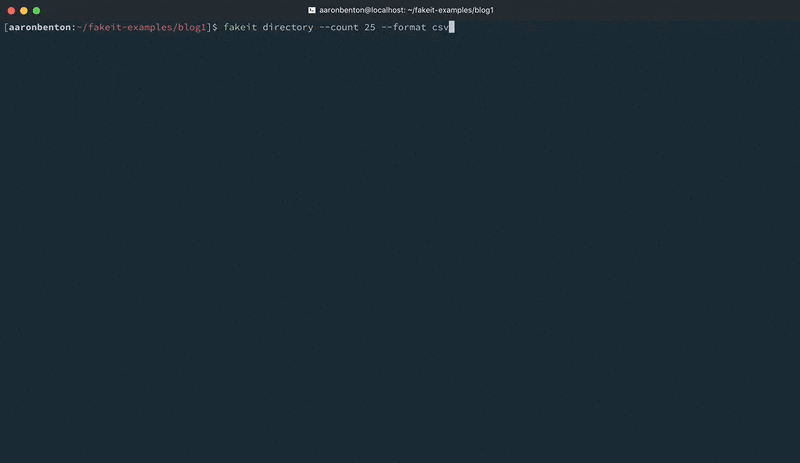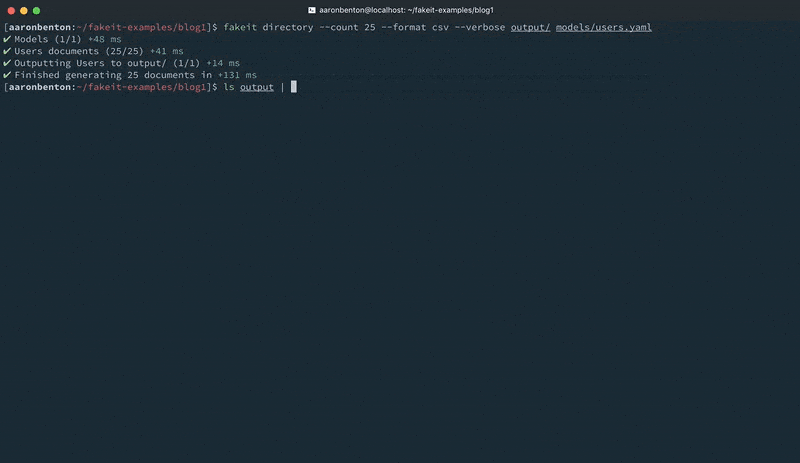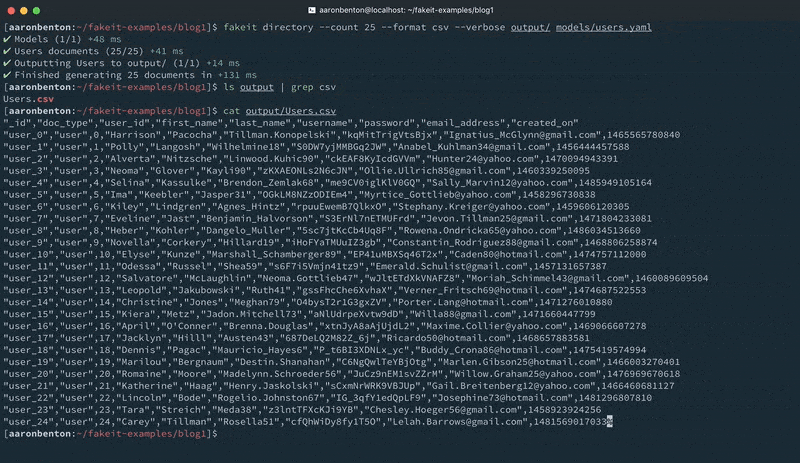
Tanto si utilizas archivos JSON, archivos Zip o archivos CSV, todos ellos pueden importarse a Couchbase Server utilizando las herramientas CLI cbdocloader (para archivos *.json y *.zip) o cbimport (para archivos *.json y *.csv)
Mientras que la generación de archivos estáticos es beneficioso, todavía hay el paso extra de tener que importarlos a Couchbase Server a través de las herramientas CLI disponibles. FakeIt también soporta Couchbase Server y Sync Gateway como destinos de salida. Podemos generar 10.000 documentos JSON a partir de nuestro modelo users.yaml, y enviarlos a un bucket llamado ecommerce en un Couchbase Server ejecutándose localmente usando el comando:
|
1 |
fakeit couchbase –server 127.0.0.1 –bucket ecommerce –count 10000 –verbose models/users.yaml |
Conclusión
Hemos visto cómo podemos representar el modelo JSON de un usuario usando YAML para documentar y describir cómo debe generarse un valor de propiedades. Ese único archivo users.yaml puede ser enviado a la consola, archivos JSON, archivo Zip de archivos JSON, archivos CSV, e incluso directamente a Couchbase. FakeIt es una herramienta fantástica para acelerar tu desarrollo y generar grandes conjuntos de datos de desarrollo. Puede guardar sus modelos FakeIt como parte de su código base para facilitar la repetición de conjuntos de datos por cualquier desarrollador.
FakeIt es una herramienta para facilitar el desarrollo y las pruebas de tu despliegue de Couchbase. Aunque puede generar grandes cantidades de datos, no es una verdadera herramienta de pruebas de carga. Hay herramientas CLI disponibles para pruebas de carga y dimensionamiento tales como cbc-pillowfight y cbworkloadgen
A continuación
- FakeIt Serie 2 de 5: Datos compartidos y dependencias
- FakeIt Series 3 de 5: Modelos Lean a través de definiciones
- FakeIt Series 4 de 5: Trabajar con datos existentes
- FakeIt Series 5 de 5: Desarrollo móvil rápido con Sync-Gateway

Este post forma parte del Programa de Escritura de la Comunidad Couchbase
[...] FakeIt Serie 1 de 5: Generando Datos Falsos aprendimos que FakeIt puede generar una gran cantidad de datos aleatorios basados en un solo archivo YAML y [...]
[...] hasta ahora en nuestra serie FakeIt hemos visto cómo podemos Generar Datos Falsos, Compartir Datos y Dependencias, y utilizar Definiciones para modelos más pequeños. Hoy vamos a ver [...]
[...] Serie FakeIt 1 de 5: Generación de datos falsos [...]
En Couchbase 5.0 y superiores, es necesario especificar un nombre de usuario y una contraseña para Couchbase.
Puede hacerlo añadiendo los parámetros -username (o -u) y -password (o -p) al comando "fakeit couchbase