Si has estado siguiendo las entradas anteriores en el blog de Couchbase, habrás visto contenido sobre Couchbase Shell última versión. Estoy probando diferentes cosas y hoy quería ver qué podía hacer con conjuntos de datos de series temporales.
Ingesta de datos de series temporales
Navegando por Kaggle, encontré datos de temperatura por Ciudad. Lo he descargado. Pesa unos 500Mb y eso lo hace difícil de manipular en su conjunto. Pero, por supuesto, es un archivo de texto por lo que fácilmente podemos echar un vistazo a la estructura de datos así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
> open GlobalLandTemperaturesByCity.csv | first 10 ╭───┬────────────┬────────────────────┬───────────────────────────────┬───────┬─────────┬──────────┬───────────╮ │ # │ dt │ AverageTemperature │ AverageTemperatureUncertainty │ City │ Country │ Latitude │ Longitude │ ├───┼────────────┼────────────────────┼───────────────────────────────┼───────┼─────────┼──────────┼───────────┤ │ 0 │ 1743-11-01 │ 6.07 │ 1.74 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 1 │ 1743-12-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 2 │ 1744-01-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 3 │ 1744-02-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 4 │ 1744-03-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 5 │ 1744-04-01 │ 5.79 │ 3.62 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 6 │ 1744-05-01 │ 10.64 │ 1.28 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 7 │ 1744-06-01 │ 14.05 │ 1.35 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 8 │ 1744-07-01 │ 16.08 │ 1.40 │ Århus │ Denmark │ 57.05N │ 10.33E │ │ 9 │ 1744-08-01 │ │ │ Århus │ Denmark │ 57.05N │ 10.33E │ ╰───┴────────────┴────────────────────┴───────────────────────────────┴───────┴─────────┴──────────┴───────────╯ |
|
1 2 3 |
> open GlobalLandTemperaturesByCity.csv | length 8599212 |
8599212 líneas, esto va a ser 8599211 documentos. Mi objetivo final es ver un gráfico de temperatura de varias ciudades a lo largo de los años. Para ello, primero voy a importar todo a un bucket de importación, luego transformaré los datos en series temporales.
Si importo esto ingenuamente, me da un doc por ciudad/grupo de meses. Así que la clave de mi documento será como Aarhus:1743-11-01. Digamos que sólo quiero subir la primera línea, debería tener este aspecto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
> open GlobalLandTemperaturesByCity.csv | first 1 | wrap content | insert id { |x| $"($x.content.City):($x.content.dt)" } ╭───┬───────────────────┬──────────────────╮ │ # │ content │ id │ ├───┼───────────────────┼──────────────────┤ │ 0 │ {record 7 fields} │ Århus:1743-11-01 │ ╰───┴───────────────────┴──────────────────╯ > open GlobalLandTemperaturesByCity.csv | first 1 | wrap content | insert id { |x| $"($x.content.City):($x.content.dt)" } |doc upsert ╭───┬───────────┬─────────┬────────┬──────────┬─────────╮ │ # │ processed │ success │ failed │ failures │ cluster │ ├───┼───────────┼─────────┼────────┼──────────┼─────────┤ │ 0 │ 1 │ 1 │ 0 │ │ capella │ ╰───┴───────────┴─────────┴────────┴──────────┴─────────╯ |
Y ahora que sé que funciona, vamos a cogerlo todo y a meterlo en el lote:
|
1 |
open GlobalLandTemperaturesByCity.csv | par-each -t 5 {|x| wrap content | insert id {$"($x.City):($x.dt)" } } | doc upsert |
He creado un serie en la que importo el resultado de una SELECCIONE agregación, obteniendo todas las fechas como marcas de tiempo y todas las Temperatura media como valor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
query ' INSERT INTO series(KEY _k, VALUE _v) SELECT a.City _k, {"City": a.City , "ts_start" : MIN(STR_TO_MILLIS(a.dt)), "ts_end" : MAX(STR_TO_MILLIS(a.dt)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.dt), a.AverageTemperature]) } _v FROM import a WHERE a.dt BETWEEN "1700-01-01" AND "2020-12-31" GROUP BY a.City; ' INSERT INTO series(KEY _k, VALUE _v) SELECT a.City _k, {"City": a.City , "ts_start" : MIN(STR_TO_MILLIS(a.dt)), "ts_end" : MAX(STR_TO_MILLIS(a.dt)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.dt), a.AverageTemperature]) } _v FROM import a WHERE SUBSTR(a.City,0,1) = "Z" AND a.dt BETWEEN "2010-01-01" AND "2020-12-31" GROUP BY a.City; |
Y ahora todos los datos están disponibles como series temporales. Digamos que quiero los datos de París, puedo utilizar la función _timeseries funcionar así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
> let ts_ranges = [946684800000,1375315200000]; query $"SELECT t._t time, t._v0 `value` FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city = \"Paris\" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \);" | reject cluster | to csv time,value 946684800000,3.845 949363200000,6.587000000000001 951868800000,7.872000000000001 954547200000,10.067 957139200000,15.451 959817600000,17.666 962409600000,16.954 965088000000,19.512 967766400000,16.548000000000002 970358400000,11.675999999999998 .... |
Para acelerar las cosas puedes crear el siguiente índice: CREATE INDEX ix1 ON series(Ciudad, ts_end, ts_start);
Obsérvese el uso de la ts_rangos al principio. Puede reutilizar fácilmente esos valores en una plantilla Cadena. Empiezan con un $ y las variables deben ir entre paréntesis como ($my_variable). Lo que también significa que ahora es necesario escapar del carácter paréntesis, así como de las comillas dobles.
Trazar series temporales
Hay una variedad de bibliotecas de trazado de terminales, aquí estoy usando youplot:
|
1 |
> let ts_ranges = [946684800000,1375315200000]; query $"SELECT t._t date, t._v0 `value` FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city = \"Paris\" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \);" | reject cluster | to csv | uplot line -d, --xlim 946684800000,1375315200000 --ylim -20,35 --title "global temperature in Paris" --xlabel date --ylabel temperature` |
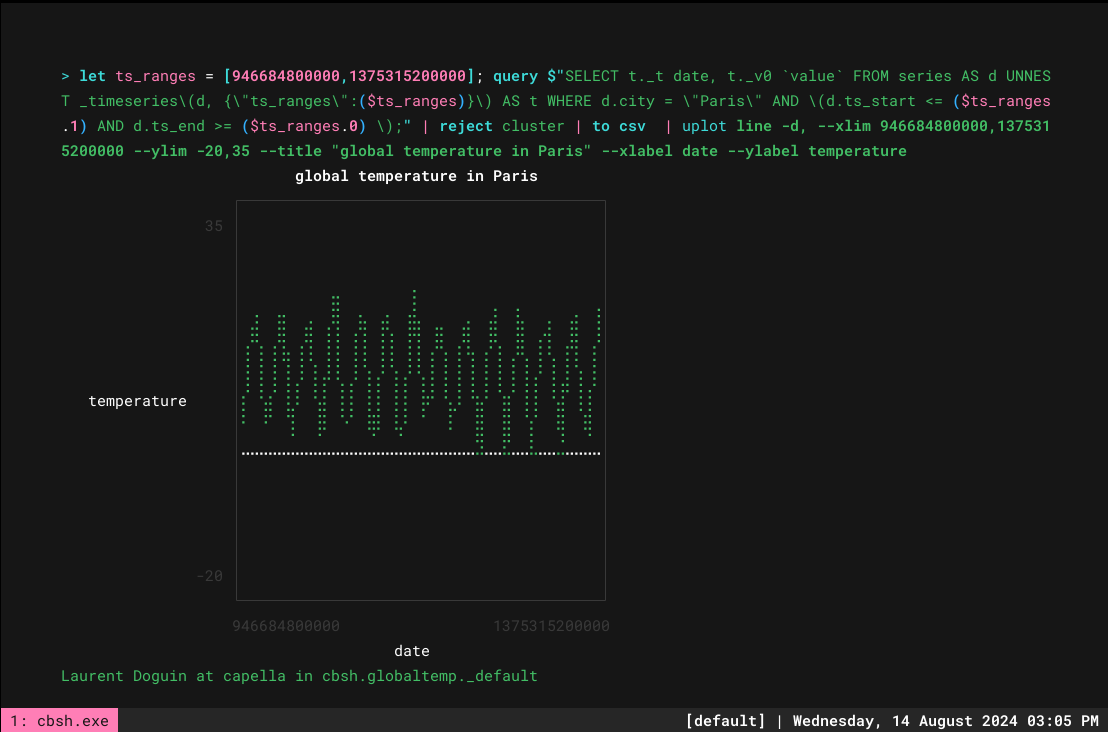
Todo esto está muy bien, pero lo ideal sería tener varias ciudades para poder compararlas. Cualquier columna CSV adicional se recoge automáticamente siempre que ejecute líneas youplot. Haciendo las cosas poco a poco, vamos a empezar con el apoyo de múltiples ciudades en la consulta. Así que un par de cambios aquí:
-
- agrupar los datos por tiempo
- añadiendo d.ciudad IN ($city) a la cláusula where. Esto funciona porque la matriz de ciudades es una cadena literal de una matriz JSON. Veamos la respuesta como un documento JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) \) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" | reject cluster | first |to json [ { "date": "2000-01-01", "$1": [ { "city": "Aba", "temp": 26.985000000000007 }, { "city": "Berlin", "temp": 1.3239999999999998 }, { "city": "London", "temp": 4.6930000000000005 }, { "city": "Paris", "temp": 3.845 } ] } ] |
Pero esto no se puede convertir en un CSV, incluso si se aplana todo de esta manera:
|
1 2 3 4 5 6 7 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) \) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first |flatten|flatten|to csv date,city,temp 2000-01-01,Aba,26.985000000000007 2000-01-01,Berlin,1.3239999999999998 2000-01-01,London,4.6930000000000005 2000-01-01,Paris,3.845 |
Así que podemos transformarlo en un objeto de esta manera: Objeto v.ciudad : v.temp FOR v IN ARRAY_AGG({"ciudad": d.ciudad, "temp":t._v0}) when v IS NOT MISSING END
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first | to json { "date": "2000-01-01", "$1": { "Aba": 26.985000000000007, "Berlin": 1.3239999999999998, "London": 4.6930000000000005, "Paris": 3.845 } } |
Que ahora se puede aplanar en un CSV:
|
1 2 3 4 5 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | first | flatten| to csv date,Aba,Berlin,London,Paris 2000-01-01,26.985000000000007,1.3239999999999998,4.6930000000000005,3.845 |
Y con eso estamos listos para trazar varias líneas:
|
1 |
> let ts_ranges = [946684800000,1375315200000]; let city = ['"Aba"','"Berlin"','"London"','"Paris"']; query $"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\) FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t WHERE d.city IN ($city) AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \) GROUP BY t._t ORDER BY t._t;" |reject cluster | flatten | to csv | uplot lines -H -d, --xlim 946684800000,1375315200000 --ylim -10,50 -w 50 --title "temperature per month" --xlabel date --ylabel temperature |
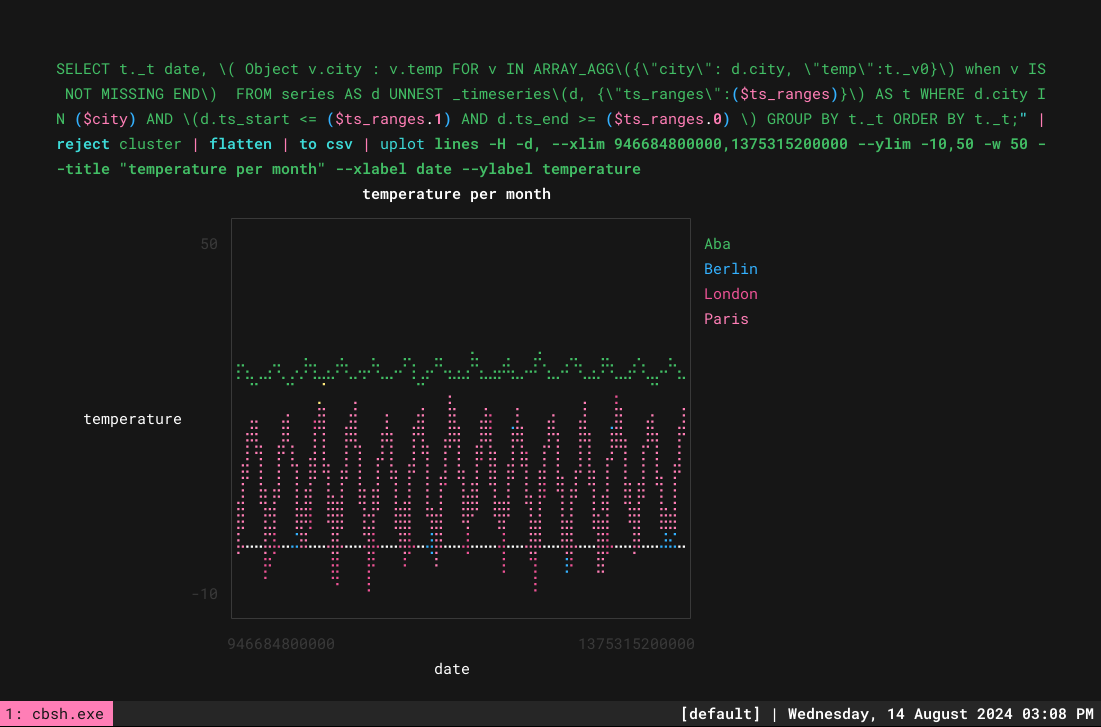
Para hacerlo más fácil, puedes utilizar funciones. Crea una .nu como temp.nucon el siguiente contenido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def tempGraph [$ts_ranges, $cities] { cb-env bucket cbsh cb-env scope globaltemp cb-env collection series let query = ($"SELECT t._t date, \( Object v.city : v.temp FOR v IN ARRAY_AGG\({\"city\": d.city, \"temp\":t._v0}\) when v IS NOT MISSING END\)" + $" FROM series AS d UNNEST _timeseries\(d, {\"ts_ranges\":($ts_ranges)}\) AS t " + $" WHERE d.city IN ($city) " + $" AND \(d.ts_start <= ($ts_ranges.1) AND d.ts_end >= ($ts_ranges.0) \)" + $" GROUP BY t._t ORDER BY t._t;" ) let csv = query $query |reject cluster | flatten | to csv $csv | uplot lines -H -d, --xlim 946684800000,1375315200000 --ylim -10,50 -w 50 --title "temperature per month" --xlabel date --ylabel temperature } |
Luego, si se abastece, es mucho más fácil de usar:
|
1 2 3 |
> source ./testingcbshell/temp.nu > tempGraph [946684800000,1375315200000] ['"Aba"','"Berlin"','"London"','"Paris"'] |
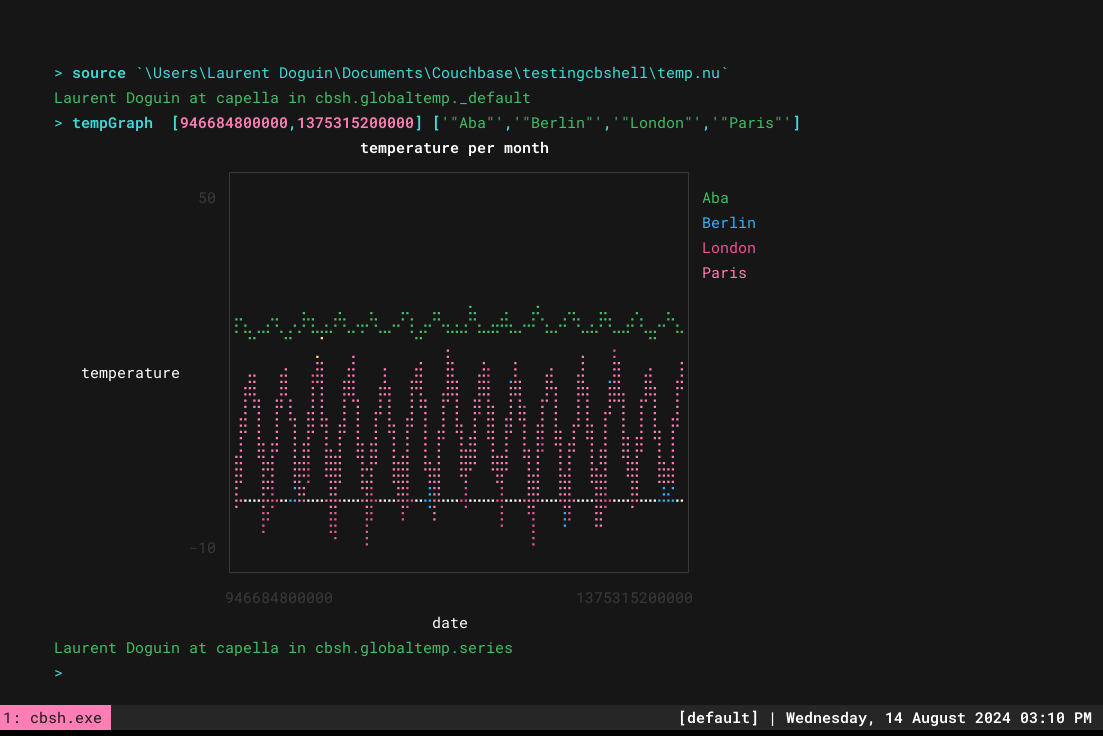
Espero que esto te haya dado una rápida visión general del soporte de series temporales de Couchbase, de la manipulación de datos de Couchbase Shell, y de cómo puedes usar otros comandos de shell como youplot para hacer las cosas más integradas e interesantes. Podría generar fácilmente un informe completo en varios formatos a partir de un Acciones de GitHub por ejemplo, ¡un sinfín de posibilidades!
-
- Leer más artículos sobre Shell de Couchbase.