Cuando se trata de aprendizaje automático, mucho es dicho y escrito sobre el entrenamiento de sus modelos ML. Pero igual de importante es donde almacenas esos modelos una vez que estás listo para servir predicciones en tiempo real.
La semana pasada analizamos cinco casos de uso de Couchbase con su sistema de predicción en tiempo real. Exploramos cómo Couchbase se utiliza para almacenar la entrada o características que más tarde se pasan a los modelos de aprendizaje automático (ML), los metadatos del modelo y las propias predicciones.
En este artículo, exploraremos cómo usar Couchbase Server para almacenar modelos ML entrenados.
Aprendizaje automático en línea y necesidad de un almacén rápido de modelos
Tradicionalmente, un modelo de aprendizaje automático se entrena offline en grandes cantidades de datos históricos y luego se despliega en producción para servir predicciones.
Sin embargo, la formación offline no siempre es posible. Por ejemplo, a veces las pequeñas startups pueden no tener acceso a grandes cantidades de datos de entrenamiento. También puede ser el caso en empresas establecidas en las que un equipo está empezando con un nuevo caso de uso de ML que no dispone de suficientes datos de entrenamiento. Como resultado, esperar a disponer de suficientes datos de entrenamiento repercute en el tiempo de comercialización de su producto.
Para solucionar este problema, algunas empresas utilizan aprendizaje automático en línea. En este enfoque, las empresas entrenan un modelo inicial utilizando pequeñas cantidades de datos, lo despliegan en producción y lo vuelven a entrenar gradualmente a medida que disponen de más datos. Una empresa puede necesitar desplegar miles de estos modelos en producción, cada uno para un caso de uso diferente.
Con el aprendizaje automático en línea, puede ser necesario actualizar los modelos con mucha frecuencia. Al mismo tiempo, se siguen realizando predicciones utilizando los nuevos modelos actualizados. Para almacenar los modelos de ML se necesita un almacén de datos de alto rendimiento y baja latencia de lectura y escritura.
Almacenamiento de modelos de aprendizaje automático en Couchbase
La plataforma de datos Couchbase satisface los requisitos de rendimiento del aprendizaje automático en línea. Su arquitectura que prioriza la memoria, con caché de documentos integrada, ofrece un alto rendimiento sostenido y una latencia constante por debajo del milisegundo.
Servidor Couchbase almacena cualquiera de tus modelos ML, ya sea en formato binario o JSON, de hasta 20MB de tamaño (es decir, el límite de documentos de Couchbase). Tus modelos se almacenan en buckets de Couchbase (o "Colecciones") y puedes acceder a ellos como a cualquier otro dato almacenado en Couchbase. Esto te facilita la gestión del ciclo de vida de los modelos ML, ya que los modelos se actualizan con una simple actualización clave-valor.
Formatos binario y JSON
Una ventaja de almacenar el modelo ML en formato binario es que no es necesario convertir de JSON a binario en el momento de hacer las predicciones. Los modelos binarios también tienen un tamaño menor.
Sin embargo, almacenar el modelo en formato JSON permite a los usuarios mirar dentro del modelo a través de varias interfaces de Couchbase. Esto puede ser útil para aquellos usuarios que se preocupan por la explicabilidad de la IA y no quieren que el modelo ML sea una caja negra.
Otra ventaja de almacenar el modelo en formato JSON es que el Servicio de consulta Couchbase o Servicio de búsqueda de texto completo pueden indexar y consultar el modelo. Couchbase Data Platform incluye todos estos servicios y elimina la necesidad de productos independientes.
Couchbase también cumple otros requisitos que un sistema ML de producción exige a su almacén de modelos, como alta disponibilidad, capacidad para escalar dinámicamente con el aumento de la carga de trabajo, acceso seguro a los datos y facilidad de gestión.
Formatos de modelos ML y ONNX
Existe una gran variedad de marcos de ML, como scikit-learn y TensorFlow, que ayudan a entrenar y desplegar modelos. Los científicos de datos suelen construir modelos utilizando el marco y el lenguaje con los que están más familiarizados, o eligen un marco más adecuado para el entrenamiento de modelos.
A veces, el modelo se despliega en producción utilizando el mismo lenguaje y marco que los utilizados durante la formación. Este enfoque facilita el uso. Sin embargo, el lenguaje o marco que mejor funciona para el entrenamiento puede no ser óptimo para hacer predicciones.
Es habitual que los usuarios conviertan el modelo entrenado a un marco diferente o lo reescriban en un lenguaje distinto. Intercambio abierto de redes neuronales (ONNX) es un popular formato de intercambio de modelos utilizado con este fin.
Los modelos entrenados en una variedad de marcos de trabajo populares pueden convertirse a ONNX. A continuación, puede exportar el modelo ONNX a otro marco más adecuado para su despliegue. También puede conservar el modelo en formato ONNX y desplegarlo en uno de los tiempos de ejecución compatibles, como el tiempo de ejecución ONNX de código abierto.
El tiempo de ejecución de ONNX es compatible con Linux, Windows y Mac, y dispone de bindings para varios lenguajes, como Python y Java. Visite consulte el tiempo de ejecución de ONNX para más detalles.
Serialización y deserialización de modelos ML
Los modelos entrenados suelen serializado y guardado en algún formato en un archivo y luego deserializado para restaurarlos y cargarlos durante el despliegue. Por ejemplo, pepinillo es un formato específico de Python que permite almacenar un modelo scikit-learn como un flujo de bytes.
Echemos un vistazo a cómo un modelo de aprendizaje automático puede ser entrenado, serializado y almacenado en Couchbase y luego recuperado, deserializado y utilizado para hacer predicciones.
Entrenaremos un modelo (a clasificador de máquina de vectores soporte (SVM)) para predecir el tipo de flor de iris en función de las dimensiones de su sépalo y sus pétalos. Utilizaremos la Conjunto de datos Iris para entrenar el modelo utilizando el marco scikit-learn. Este conjunto de datos contiene dimensiones de sépalos y pétalos de tres tipos diferentes de la flor del iris, con un total de 150 filas.
Uso de Couchbase como almacén de modelos ML: Formato Binario
Formación y flujo de trabajo de serialización
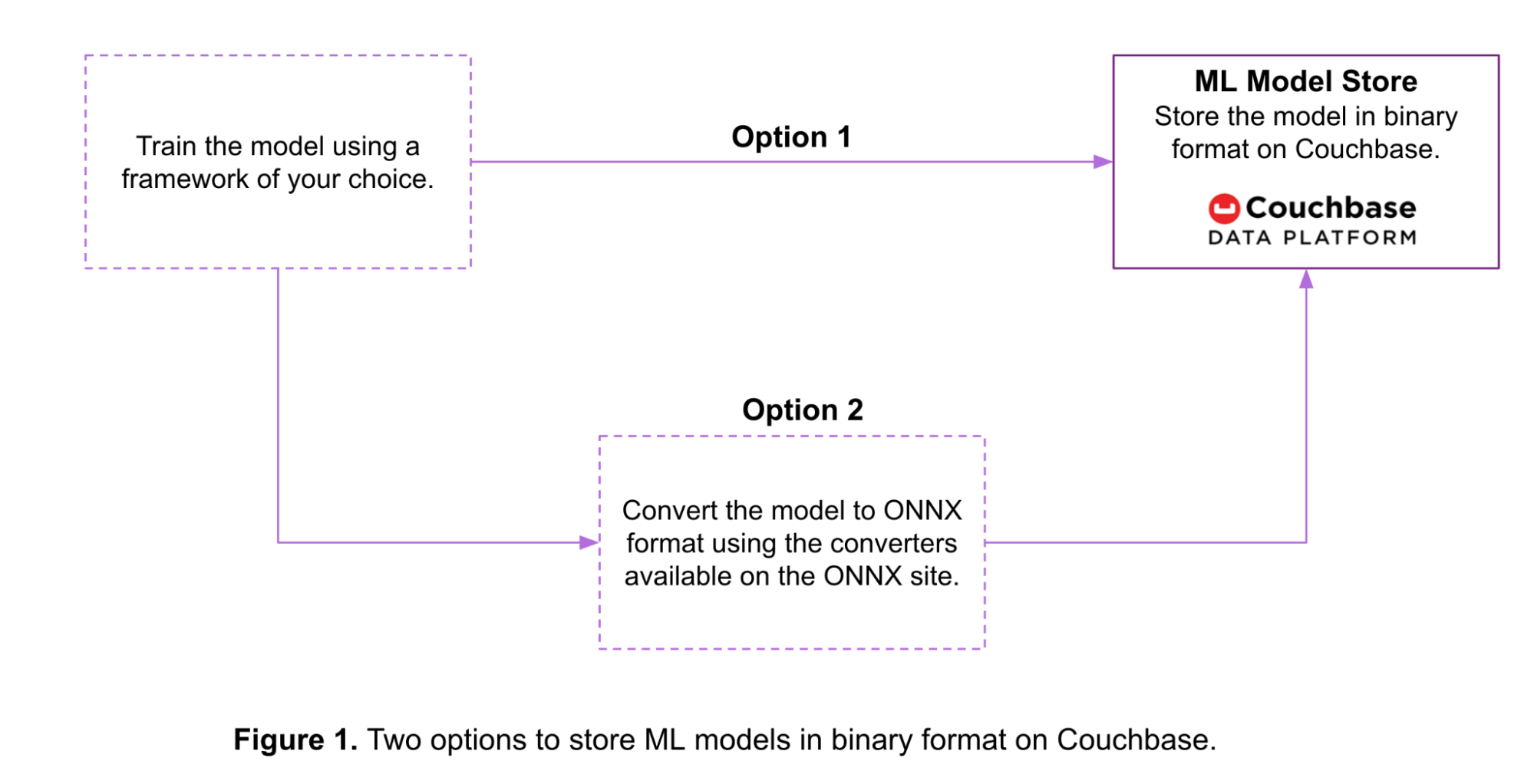
Como se muestra en la Figura 1, hay dos opciones para almacenar un modelo ML en formato binario en Couchbase:
- Opción 1: Los modelos entrenados en varios marcos de ML se convierten a un flujo de bytes utilizando herramientas proporcionadas por el propio marco. A continuación, los modelos se almacenan en ese formato en un bucket de Couchbase.
- Opción 2: Los modelos entrenados se convierten al formato ONNX antes de almacenarse en Couchbase. He aquí algunos ejemplos herramientas de conversión disponibles para varios marcos de ML.
A continuación se muestra un código de ejemplo para la Opción 2. En este ejemplo:
- Se entrena un clasificador SVM en el conjunto de datos del iris utilizando el marco scikit-learn.
- El modelo entrenado se convierte de scikit-learn al formato ONNX utilizando el conversor disponible aquí.
- El modelo ONNX se almacena en un bucket de Couchbase denominado
ModelRepositoryutilizando el SDK Python de Couchbase. Más información sobre los SDK de Couchbase disponibles aquí.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Step-1: Train a scikit-learn model from sklearn import svm from sklearn import datasets clf = svm.SVC() X, y = datasets.load_iris(return_X_y = True) clf.fit(X, y) # Step-2: Convert the scikit-learn model into ONNX format from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 4]))] onx = convert_sklearn(clf, initial_types = initial_type) # Step-3: Store the ONNX model in binary format in a # Couchbase Bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase import FMT_BYTES cluster = Cluster(host) authenticator = PasswordAuthenticator(user_name, password) cluster.authenticate(authenticator) modelBucket = cluster.open_bucket('ModelRepository') key = "iris.onnx" value = onx.SerializeToString() modelBucket.upsert(key, value, format = FMT_BYTES) |
Deserialización y flujo de trabajo de predicción
El sistema servidor de predicciones lee el modelo de Couchbase y genera la predicción (por ejemplo, el tipo de flor Iris).
Este es el código para leer el modelo almacenado en Couchbase en el ejemplo anterior.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Read the ONNX model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the previous example rv = modelBucket.get("iris.onnx") onnxModel = rv.value # Predict using ONNX runtime. import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
A continuación, este modelo se utiliza para generar una predicción utilizando el tiempo de ejecución ONNX. Las predicciones se generan sobre las tres primeras filas de la matriz de entrada X obtenida en el ejemplo anterior.
También es posible dividir el conjunto de datos en datos de entrenamiento y datos de prueba y generar predicciones sobre los datos de prueba.
Uso de Couchbase como almacén de modelos ML: Formato JSON
Formación y flujo de trabajo de serialización
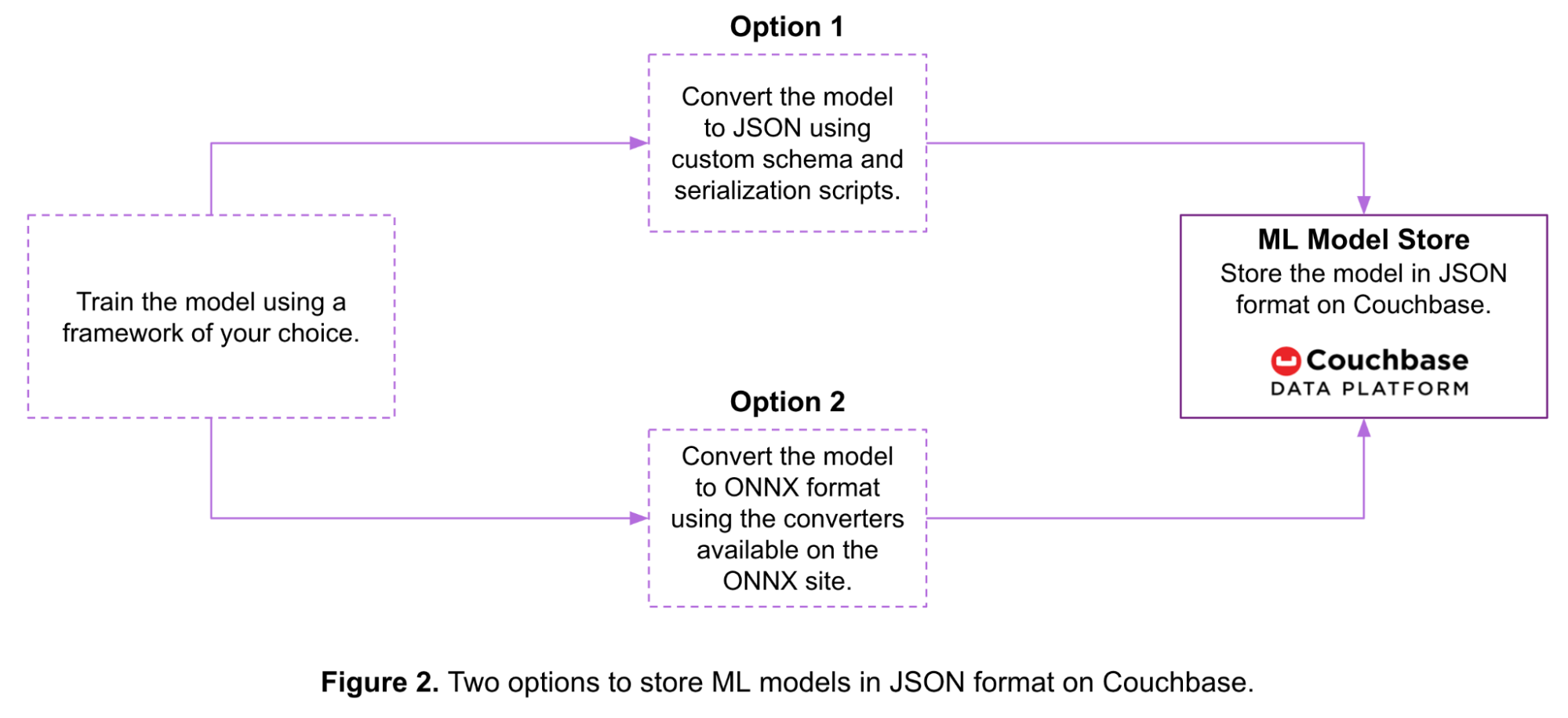
La Figura 2 muestra dos opciones para almacenar un modelo de machine learning como un documento JSON en Couchbase:
- Opción 1: Puedes serializar el modelo usando un esquema personalizado y scripts antes de almacenarlo en Couchbase.
- Opción 2: Puedes convertir el modelo al formato ONNX y luego almacenarlo en Couchbase.
A continuación se muestra un código de ejemplo para la Opción 2:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Steps 1 and 2 to train the model and convert it into the ONNX # format as well the steps to connect to a Couchbase bucket # are the same as the one in the earlier binary model example. # Step-3: Convert the ONNX model to JSON & store in a # Couchbase bucket from google.protobuf.json_format import MessageToJson import json key = "iris_json.onnx" value = json.loads(MessageToJson(onx)) modelBucket.upsert(key, value) |
Deserialización y flujo de trabajo de predicción
Este es el código de deserialización para leer el modelo almacenado en Couchbase en el ejemplo anterior. Este modelo se utiliza a continuación para generar una predicción utilizando el tiempo de ejecución ONNX.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Read the ONNX-JSON model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the earlier example rv = modelBucket.get("iris_json.onnx") # Convert the ONNX-JSON model to ONNX object from onnx import ModelProto from google.protobuf.json_format import Parse model = ModelProto() Parse(json.dumps(rv.value), model) onnxModel1 = model.SerializeToString() # Predict using ONNX runtime import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel1) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction1 = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
Aprendizaje automático en línea utilizando Couchbase como almacén de modelos de ML
Couchbase se puede utilizar para almacenar sus modelos de ML para el aprendizaje automático en línea.
La Figura 3 muestra el flujo para el aprendizaje y las predicciones en línea con modelos almacenados en la plataforma de datos Couchbase.
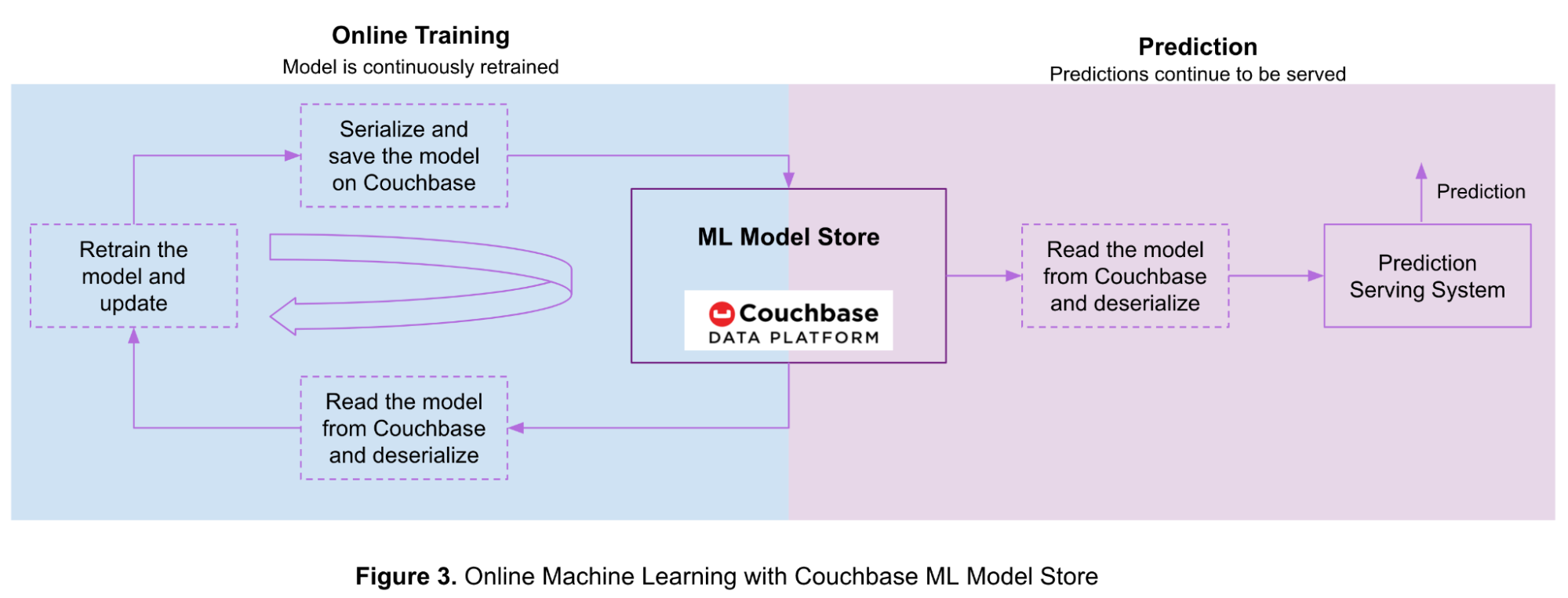
Primero se entrena el modelo offline con una pequeña cantidad de datos de entrenamiento, luego se serializa y se almacena en un bucket de Couchbase. A medida que se dispone de más datos, el modelo ML se actualiza continuamente mediante el aprendizaje en línea.
Los pasos para utilizar Couchbase para el aprendizaje automático en línea son los siguientes:
- Leer el modelo desde Couchbase y deserializarlo siguiendo los pasos mencionados en las secciones anteriores.
- Vuelve a entrenar el modelo con los nuevos datos de entrenamiento disponibles..
- Serializa el modelo actualizado y guárdalo en un bucket de Couchbase siguiendo los pasos descritos en las secciones anteriores.
- Vuelva al paso 1 a medida que disponga de más datos de entrenamiento.
Su sistema servidor de predicciones continúa sirviendo predicciones durante este proceso siguiendo estos pasos:
- Leer el modelo desde Couchbase y deserializarlo siguiendo los pasos mencionados en secciones anteriores.
- Generar predicción.
En el artículo de la semana pasada se describía la arquitectura de los sistemas de predicción más comunes: 5 casos de uso de sistemas de predicción en tiempo real con Couchbase.
Conclusión
Como se muestra en la figura 4, puede sustituir varios productos de almacenamiento de datos con la plataforma única Couchbase Data Platform. Este enfoque reduce la complejidad, la sobrecarga operativa y el coste total de propiedad (TCO).
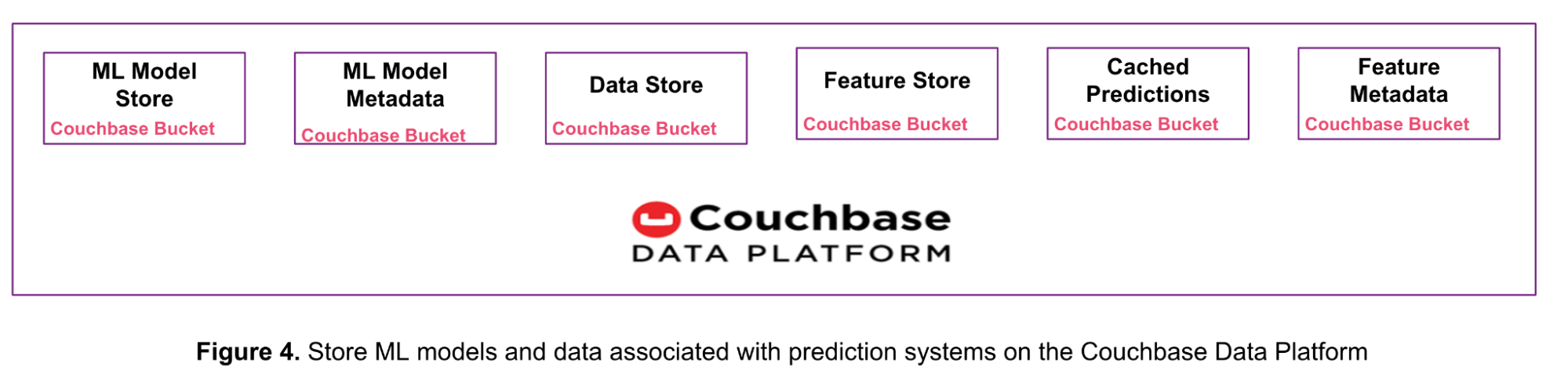
Ya vimos en este artículo cómo la plataforma de datos Couchbase almacena modelos ML de hasta 20 MB de tamaño y cómo se utiliza para el aprendizaje automático online.
La semana pasada analizamos 5 casos de uso de sistemas de predicción en tiempo real con Couchbase y aprendió cómo la plataforma de datos Couchbase puede almacenar datos de entrada sin procesar, características, predicciones, metadatos de características y metadatos de modelos.
Cada uno de estos tipos de datos puede almacenarse en un bucket o colección de Couchbase independiente. Una colección es un contenedor de datos dentro de un bucket para agrupar lógicamente elementos similares. Esta característica se introdujo con Couchbase Server 7.0. Consulte la documentación sobre Ámbitos y Colecciones en Couchbase para más información.
Próximos pasos
Si estás interesado en aprender más sobre machine learning y Couchbase, aquí tienes algunos pasos a seguir y recursos para empezar:
- Comience su prueba gratuita de Couchbase Cloud - no requiere instalación.
- Profundice en los detalles técnicos con este libro blanco: Couchbase bajo el capó: una visión general de la arquitectura.
- Explora la Consulta, Búsqueda de texto completo, Eventosy Analítica que ofrece Couchbase.
