Este post ilustra el uso de Couchbase Analytics con el SDK de Couchbase Go. Couchbase Analytics es un nuevo servicio disponible en Couchbase Server 6.0, puedes leer más en https://docs.couchbase.com/server/6.0/analytics/introduction.html.
En este post vamos a utilizar un conjunto de datos del mundo real que es lo suficientemente grande como para no caber en la memoria (al menos en mi máquina local). Vamos a utilizar el Exportación CSV de la Conjunto de datos de trayectos en taxi ecológico en NYC en 2016. Se trata de un conjunto de datos de ~16,4 millones de registros con 23 campos por registro. Puede seguir el proceso y probar la aplicación clonando el proyecto aquío ejecute
go get github.com/chvck/gocb-taxi-analytics . También tendrá que ejecutar
go get ./... si has clonado el proyecto con git.
Como se trata de un archivo CSV, lo primero que hay que hacer es importarlo. Desafortunadamente, este conjunto de datos utiliza formatos de fecha y hora no estándar, por lo que necesitamos utilizar un pequeño script para convertirlos en algo más utilizable. Si has clonado el proyecto puede hacerlo con
|
1 |
go run main.go --reformat --csv /path/to/taxis.csv |
Esto creará un
2016_Green_Taxi_Trip_Data.csv en el directorio del proyecto. También he aprovechado esta oportunidad para cambiar las cabeceras CSV para hacerlas más amigables con JSON y también añadir un campo de tipo siempre establecido en verde (en caso de que más tarde quisiéramos añadir también el conjunto de datos de taxis amarillos). Durante la conversión también podríamos haber importado los datos pero ya tenemos una gran herramienta en cbimport que podemos utilizar. Cree un cubo llamado taxis con la evicción completa activada (en Advanced bucket settings - no estaremos ejecutando operaciones k/v por lo que el rendimiento k/v no importa tanto en este caso) y luego ejecutar:
|
1 |
cbimport csv --cluster couchbase://localhost -u user -p password -b taxis --infer-types -omit-empty -d file:///path/to/2016_Green_Taxi_Trip_Data.csv -l import.log -g green::%vendorID%::#MONO_INCR# |
Cada documento tendrá un identificador único como
green::1::1000 . Normalmente, estos dos pasos no serían necesarios, ya que nuestros datos ya estarían almacenados en Couchbase.
Antes de poder trabajar con Couchbase Analytics tienes que preparar un conjunto de datos que te permita consultarlos:
|
1 |
CREATE DATASET alltaxis ON taxis; |
Este conjunto de datos requiere algunos recursos. Si quieres experimentar con un conjunto de datos ligeramente más pequeño en un portátil con pocos recursos, puedes crear un conjunto de datos filtrado que solo rastreará un subconjunto de los documentos de tu cubo:
|
1 |
CREATE DATASET alltaxis ON taxis WHERE `vendorID` = 1; |
Así obtendrá un conjunto de datos de algo más de 3 millones de documentos.
Una vez que haya creado uno de los conjuntos de datos, deberá inicializarlo activando el procesamiento de conjuntos de datos con:
|
1 |
CONNECT LINK Local; |
Esto comenzará a rellenar el conjunto de datos que acaba de crear. Puede ver el progreso en la interfaz de usuario, en la columna de conjuntos de datos de la derecha, debajo del nombre del conjunto de datos. Puede seguir trabajando con el conjunto de datos mientras se construye, pero verá resultados diferentes cada vez que ejecute una consulta y la ejecución puede ser un poco más lenta.
Como vamos a hacer análisis de datos, merece la pena investigar un par de cosas. Creo que un buen punto de partida sería conocer el número de viajes en taxi a lo largo del año y poder aplicar varios filtros para ver cosas como las propinas frente a las tarifas.
La base que utilizaremos para nuestras consultas es:
|
1 |
SELECT DATE_PART_STR(pickupDate, "month") AS period, COUNT(*) as count FROM alltaxis GROUP BY DATE_PART_STR(pickupDate, "month") ORDER BY period; |
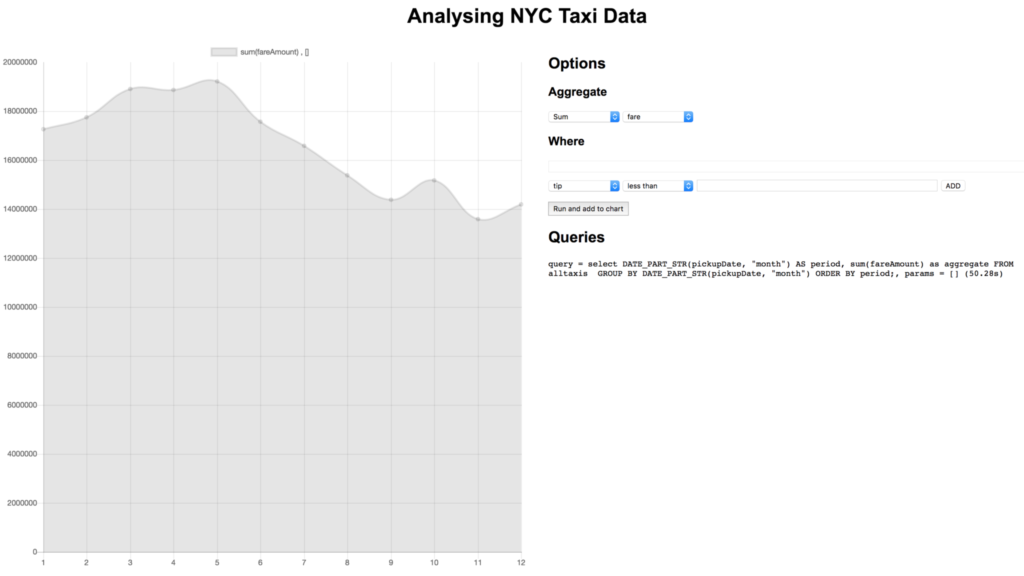
Esta consulta extrae el mes como un número (1-12) del archivo pickupDate y mostrando el número de desplazamientos en función del mes. La consulta muestra que marzo es el mes con más desplazamientos y noviembre el que menos. También se observa una tendencia a la baja a lo largo del año. Esperaba que el verano tuviera menos desplazamientos que el resto del año, así que ya he aprendido algo.
En mi máquina, esta consulta tarda unos 24 s en ejecutar el conjunto de datos completo. Ejecutando lo mismo contra el servicio de consulta operacional (a menudo referido simplemente como N1QL, pero ese es el lenguaje) con sólo un índice primario los tiempos se agotan desde la consola de consulta (600s). Podemos ver que para consultas ad hoc en grandes conjuntos de datos Couchbase Analytics es una buena opción, complementando el servicio de consulta operacional N1QL .
Consultas desde una aplicación Golang
Ahora que hemos configurado y comprobado que nuestro conjunto de datos de Analytics funciona, podemos utilizarlo a través del SDK de Go. En la ventana runServer función que tenemos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
var err error cluster, err = gocb.Connect(cbConnStr) if err != nil { panic("Error connecting to cluster:" + err.Error()) } cluster.Authenticate(gocb.PasswordAuthenticator{ Username: cbUsername, Password: cbPassword, }) _, err = cluster.OpenBucket("taxis", "") if err != nil { log.Fatal(err) } stop := make(chan os.Signal, 1) // Stop the server on interrupt signal.Notify(stop, os.Interrupt) srv, err := run() if err != nil { log.Fatal(err) } fmt.Println("Server running on", srv.Addr) <-stop log.Println("Stopping server") srv.Shutdown(nil) |
Esto crea una conexión con Couchbase Server y autentica usando el nombre de usuario y la contraseña (estas propiedades pueden ser personalizadas modificando las propiedades en la parte superior del main.go). A continuación abrimos una conexión a nuestro bucket. El resto de la función es el manejo del servidor web. Creamos un canal a la escucha de la señal de interrupción y cuando se dispara, cerramos el servidor http.
Es difícil visualizar y filtrar estos datos en la línea de comandos, por lo que en el código base vinculado hemos añadido una sencilla interfaz gráfica de usuario. El servidor web sirve la página de índice y expone un único punto final para recuperar datos dinámicos. Una vez más, para ejecutar esto utilice
go run main.go y puede acceder al frontend desde
https://localhost:8010 .
Nuestro manejador para el punto final de datos dinámicos tiene este aspecto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
func requestHandler(w http.ResponseWriter, r *http.Request) { opts, err := processQueryString(r.URL.Query()) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } q := `select DATE_PART_STR(pickupDate, "%s") AS period, %s as aggregate FROM alltaxis` q += ` %s GROUP BY DATE_PART_STR(pickupDate, "%s") ORDER BY period;` q = fmt.Sprintf(q, opts.Period, opts.Aggregate, opts.Where, opts.Period) query := gocb.NewAnalyticsQuery(q) results, err := cluster.ExecuteAnalyticsQuery(query, opts.Params) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } data, err := processResults(results) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } data.Where = fmt.Sprintf("%s %s, %v", opts.Aggregate, opts.Where, opts.Params) data.Query = fmt.Sprintf("query = %s, params = %v", q, opts.Params) data.TimeTaken = results.Metrics().ExecutionTime.Nanoseconds() js, err := json.Marshal(*data) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.WriteHeader(200) w.Header().Set("Content-Type", "application/json") w.Write(js) } |
Lo que podemos ver aquí es que procesamos la cadena de consulta para extraer el dónde (más parámetros, más sobre esto más adelante), el agregado y el periodo de tiempo. Creamos nuestra consulta como una cadena, incorporando estas propiedades y luego usamos NewAnalyticsQuery para crear un AnalyticsQuery . Para ejecutar la consulta se pasa a cluster.ExecuteAnalyticsQuery . A continuación, los resultados son procesados por processResults antes de enviar la respuesta http. Where , TimeTaken y Query también se añaden a la respuesta para que podamos mostrar lo que se ha consultado en el frontend.
Veamos cada una de estas partes con un poco más de detalle. Los parámetros where y aggregate se pasan desde el frontend ya formateados correctamente. La cadena de consulta podría ser algo como
?period=hour&month=5&day=14&aggregate=count(*)&where=fareAmount,>,15&where=tip,<,1
Lo que ocurre aquí es que el periodo dicta la granularidad de la consulta: un día, un mes o el año entero. Para el caso en que estemos consultando un día necesitamos saber también qué día y qué mes, los parámetros mes y día estarán presentes o no dependiendo del periodo. El agregado es la operación y el campo al que aplicar la operación. En lugar de count(*) podría ser SUM(tips) o AVG(fare) etc... Los parámetros where son las cláusulas where individuales a aplicar - se envían como matrices de la forma [campo, operador, valor].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
func whereTimePeriod(period string, query url.Values) string { where := "" if period == "day" { month := query["month"][0] if month == "1" { where = `pickupDate <= "2016-01-31 23:59:59"` } else if month == "12" { where = `pickupDate >= "2016-12-01 00:00:00"` } else { monthInt, _ := strconv.ParseFloat(month, 64) where = fmt.Sprintf(`pickupDate >= "2016-%02g-01T00:00:00" AND pickupDate <= "2016-%02g-31T23:59:59"`, monthInt, monthInt) } } else if period == "hour" { month := query["month"][0] monthInt, _ := strconv.ParseFloat(month, 64) day := query["day"][0] dayInt, _ := strconv.ParseFloat(day, 64) where = fmt.Sprintf(`pickupDate > "2016-%02g-%02gT00:00:00" AND pickupDate <= "2016-%02g-%02gT23:59:59"`, monthInt, dayInt, monthInt, dayInt) } return where } |
En whereTimePeriod genera la parte temporal de la cláusula where extrayendo el periodo de la cadena de consulta. Dependiendo del valor del parámetro periodo, se aplica una lógica diferente para construir la cláusula where, si se requiere el año completo, entonces se devuelve una cláusula where vacía.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
func processQueryString(queryString url.Values) (*queryOptions, error) { aggregate := queryString["aggregate"][0] period := "month" where := "" numParams := 0 var params []interface{} if len(queryString["period"]) > 0 { period = queryString["period"][0] where = whereTimePeriod(period, queryString) } for _, cond := range queryString["where"] { numParams++ condParts := strings.Split(cond, ",") if len(where) > 0 { where = fmt.Sprintf("%s AND %s %s $%d", where, condParts[0], condParts[1], numParams) } else { where = fmt.Sprintf("%s %s $%d", condParts[0], condParts[1], numParams) } val, err := strconv.Atoi(condParts[2]) if err != nil { return nil, err } params = append(params, val) } if len(where) > 0 { where = fmt.Sprintf("WHERE %s", where) } return &queryOptions{ Aggregate: aggregate, Where: where, Period: period, Params: params, }, nil } |
Una vez que la parte limitada en el tiempo se construye entonces cada uno de los parámetros where que el frontend ha proporcionado puede ser añadido. Puedes ver que en lugar de incluir los valores where usando formato de cadena estamos usando parámetros de consulta. Esta es una buena práctica para evitar inyecciones SQL.
Una vez ejecutada la consulta, el processResults se ejecuta la función
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
func processResults(results gocb.AnalyticsResults) (*calendarData, error) { var row map[string]interface{} var dateParts []float64 var aggregates []float64 for results.Next(&row) { if datePart, ok := row["period"]; ok { dateParts = append(dateParts, datePart.(float64)) aggregates = append(aggregates, row["aggregate"].(float64)) } } if err := results.Close(); err != nil { return nil, err } return &calendarData{ DateParts: dateParts, Aggregate: aggregates, }, nil } |
Itera sobre los resultados utilizando results.Next(&row) y, para cada resultado, extrae el periodo de tiempo al que corresponde el resultado en forma de número, es decir, la hora (0-23), el día (1-31) o el mes (1-12). También extrae el valor agregado que corresponde a ese periodo de tiempo. Al final hay una llamada a r esults.Close() que comprueba si hay errores para asegurarse de que todos los datos se han leído correctamente.
Utilizando el frontend podemos probar fácilmente diferentes agregados para diferentes campos, aplicar cláusulas where y profundizar en los datos para obtener una visión más granular de las cosas. Por ejemplo, probablemente queramos saber en qué mes generaron más dinero los taxis:
Profundicemos en ello haciendo clic en el punto correspondiente a mayo:
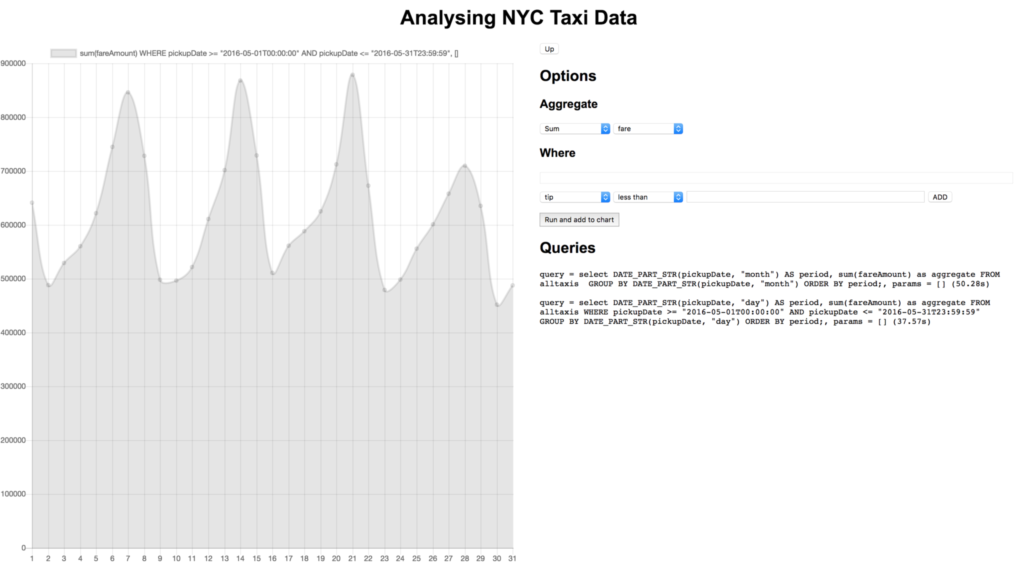
Parece que la mayor parte del dinero se genera los fines de semana, eso tiene sentido. Como hace buen tiempo en mayo y los fines de semana son los más populares, ¿quizá la mayoría de los viajes son de varios pasajeros que van juntos a ver los monumentos?
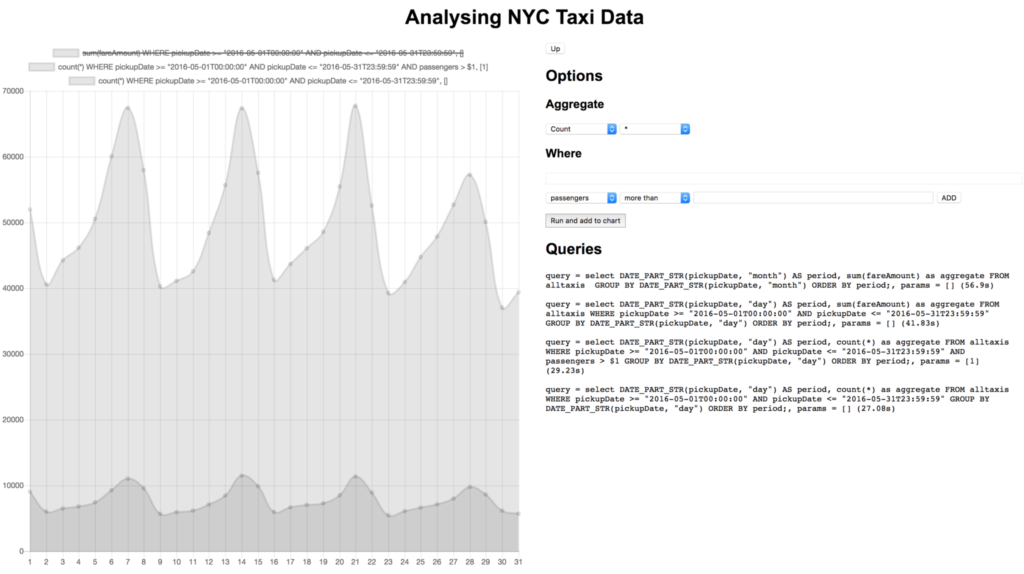
No lo parece. Podríamos hacer muchas otras comparaciones, como las tarifas frente a las propinas o el número de viajes frente al número de viajes sin propinas. Este conjunto de datos también contiene datos de localización, por lo que podríamos hacer cosas como crear mapas de calor de los lugares de recogida.
Conclusión
En este ejemplo, vimos cómo una simple consulta, que incluso podría ser ad-hoc, se puede utilizar para analizar rápidamente un conjunto de datos con una variedad de métricas, todo ello sin necesidad de la creación de índices. Couchbase Analytics añadirá esta gran capacidad a la plataforma Couchbase cuando esté disponible de forma general. Los desarrolladores Golang tienen acceso ahora a través de la beta 6.0.
Nos encantaría conocer su opinión. Por favor, descargar Couchbase Server 6.0 beta hoy y pruebe la versión actualizada de Análisis de Couchbase. Estaremos atentos a sus comentarios en www.couchbase.com/forums/ sobre cualquier tema, desde análisis hasta el SDK de Go.