¿Cómo hacer "algo" en N1QL?
En primer lugar, si no está familiarizado con N1QL le recomiendo que dedique unos minutos a nuestra formación gratuita sobre N1QL aquío simplemente jugar con él aquí.
En segundo lugar, como se trata de una pregunta amplia, repasemos algunas situaciones habituales:
Selecciona el id de un documento y todos sus atributos:
|
1 |
Select meta(t).id as id, t.* from `myBucket` t where type = 'someType' |
Cómo escribir un JOIN:
Vamos a consultar qué compañías vuelan desde el aeropuerto de San Francisco (SFO) a cualquier lugar del mundo utilizando la muestra de viajes:
|
1 2 3 4 5 6 7 |
SELECT airline.name, airline.callsign, route.destinationairport, route.stops, route.airline FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND route.sourceairport = "SFO" AND route.stops = 0 ORDER BY airline.name |
En ÚNASE A se parece a un JOIN SQL estándar, la única diferencia aquí es la cláusula EN TECLAS palabra clave, para leer más al respecto consulte este artículo que explica visualmente N1QL JOINs. Couchbase 5.5 también añadirá soporte para UNIONES ANSI
Cómo seleccionar elementos de un array:
Dados documentos como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ type: “person”, name: “John”, children: [ { “name”: “Pedro”, “age”: 8 }, { “name”: “George”, “age”: 11 } ] } |
Si queremos seleccionar a todos los niños de más de 10 años, podemos utilizar la función UNNEST palabra clave:
|
1 |
SELECT c.* FROM tutorial t UNNEST t.children c WHERE c.age > 10 |
¿Por qué mi consulta es lenta?
Probablemente su consulta no está afectando a ningún índice. Puede comprobarlo ejecutando su consulta con la función explique de la siguiente manera:
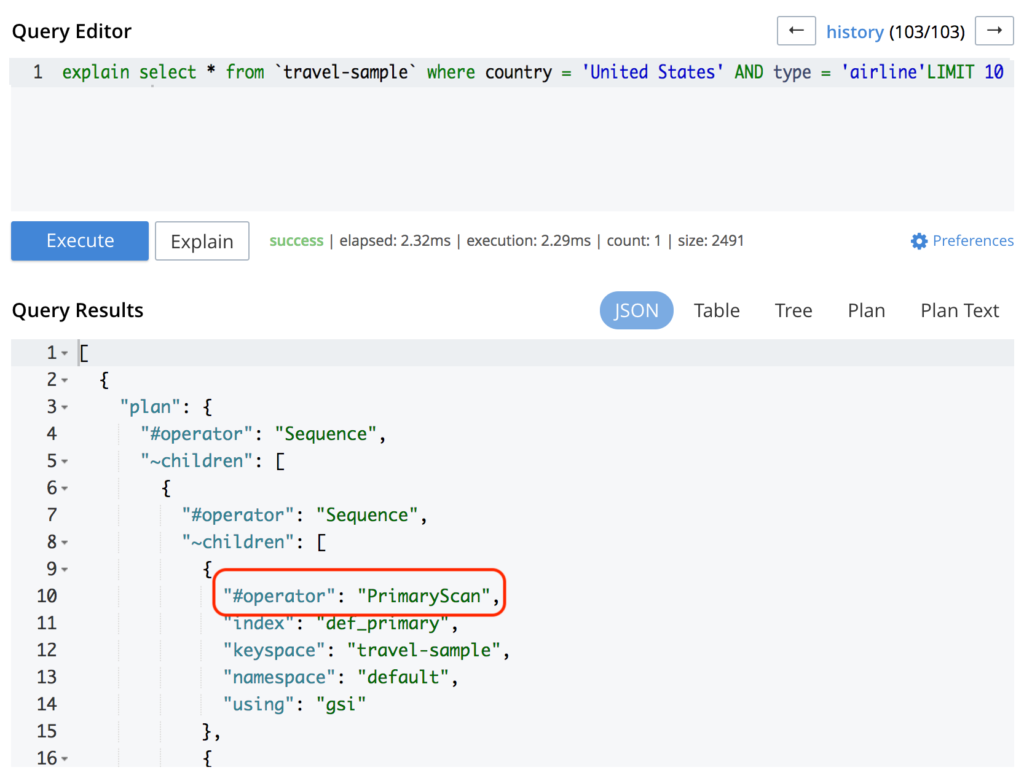
Como se puede ver en la imagen de arriba, la consulta está golpeando el PrimaryScan lo que significa que está utilizando el índice primario. La creación de un índice secundario resolverá potencialmente su problema:
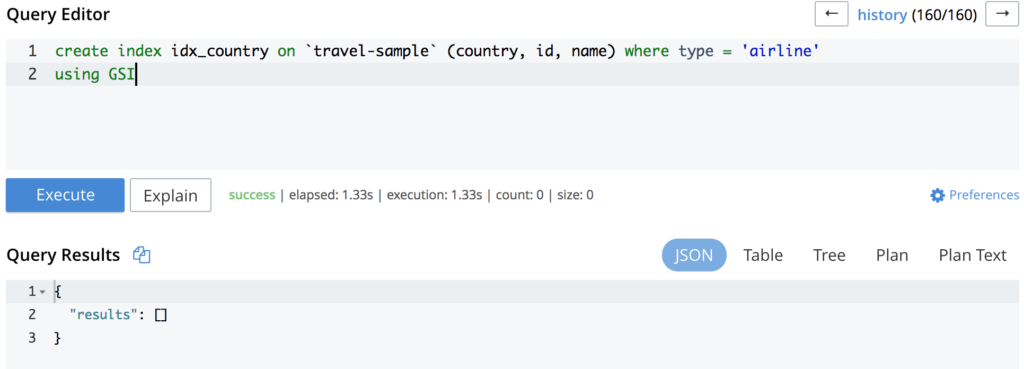
Ejecutando de nuevo la misma consulta se obtendrá algo parecido a:
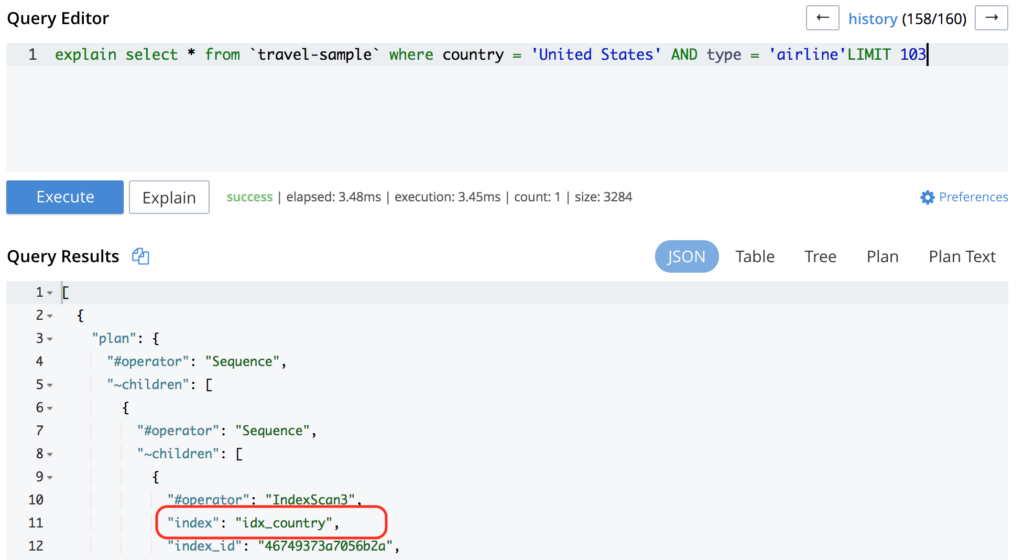
Si su consulta ya está golpeando un índice, pero todavía tiene un rendimiento pobre, es posible que desee añadir un índice más optimizado (como en este ejemplo). Si no está familiarizado con cómo crear un índice, consulte esta entrada del blog
¿Cómo paginar los resultados en N1QL?
Puede utilizar LÍMITE y OFFSET:
|
1 |
select * from `travel-sample` where country = 'United States' OFFSET 10 LIMIT 10 |
Echa un vistazo este tutorial para leer más al respecto. Además, si utiliza Spring Data, puede añadir un archivo Pageable al final de la definición del método:

Y luego, en su Servicio puede utilizar la función Petición de página objeto:
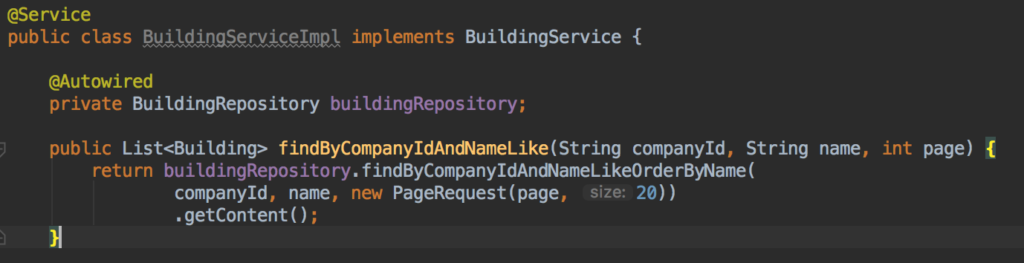
En mi consulta faltan resultados o los resultados son erróneos
Por defecto, Couchbase soporta leer después de escribir siempre que obtengas un documento por su clave, pero tus índices y vistas se actualizan de forma asíncrona a través del Protocolo de Cambio de Datos (DCP). Por lo tanto, si ejecutas una consulta justo después de una escritura, puede que se ejecute antes de que las vistas/índices hayan tenido la oportunidad de actualizarse.
Couchbase es todo velocidad, y nadie tiene tiempo de esperar hasta que todos los índices y vistas estén actualizados para enviar la respuesta al cliente de que una escritura se ha ejecutado con éxito.
Pero hay pocos escenarios donde una fuerte consistencia entre escrituras y tus consultas son realmente necesarias, para esos casos puedes especificar vía SDK que realmente quieres esperar hasta que el índice/vista que estás usando sea actualizado:

Para obtener más información sobre la coherencia del escaneado, consulte la página documentación oficial.
En mi experiencia personal, el único escenario en el que necesito coherencia entre escrituras y consultas es durante el pruebas de integración que es cuando realmente se insertan los datos y se consultan justo después.
Cómo crear/utilizar índices de matrices.
Se trata de un tema interesante, ya que indexación de matrices puede acelerar significativamente su rendimiento. Supongamos que tenemos la siguiente estructura de documento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
{ "address": "Capstone Road, ME7 3JE", "alias": null, "city": "Medway", "country": "United Kingdom", "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "directions": null, "email": null, "fax": null, … "id": 10025, "name": "Medway Youth Hostel", "pets_ok": true, "phone": "+44 870 770 5964", "price": null, "reviews": [ { "author": "Ozella Sipes", "content": "Some review here…”, "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } } ] } |
Ahora, si necesitamos consultar reseñas de hoteles, podríamos hacer algo como:
|
1 |
SELECT c.* FROM `travel-sample` t UNNEST t.reviews c where t.type == "hotel" limit 100 |
Así pues, el índice más sencillo para el reseñas matriz se se parecen a las siguientes:
|
1 |
CREATE INDEX idx ON `travel-sample` (reviews) WHERE type = "hotel"; |
Y luego, cuando ejecutamos la consulta, voilà:
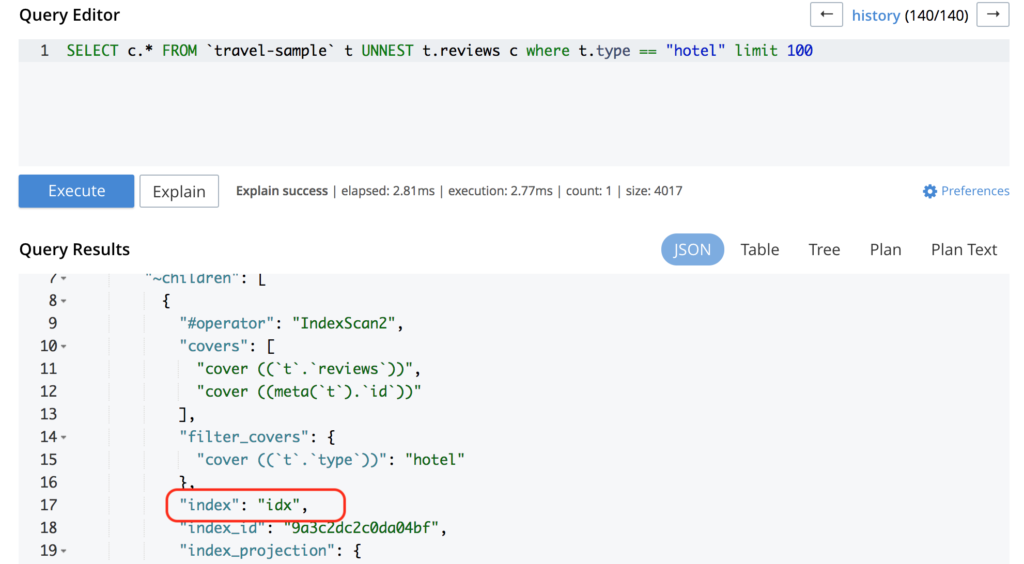
Está utilizando el índice creado recientemente.
Para más ejemplos, consulte la página documentación oficial o leer este excelente artículo sobre cómo optimizar los índices de las matrices.